微调框架概述
模型的微调有多种方式,对于入门的来说,一般都是基于官方的文档微调;最近发现很多开源库,其目的就是支持应用多种微调策略来微调模型,简化模型的微调门槛。比如 ChatGLM-Efficient-Tuning、LLaMA-Factory。其架构逻辑如下: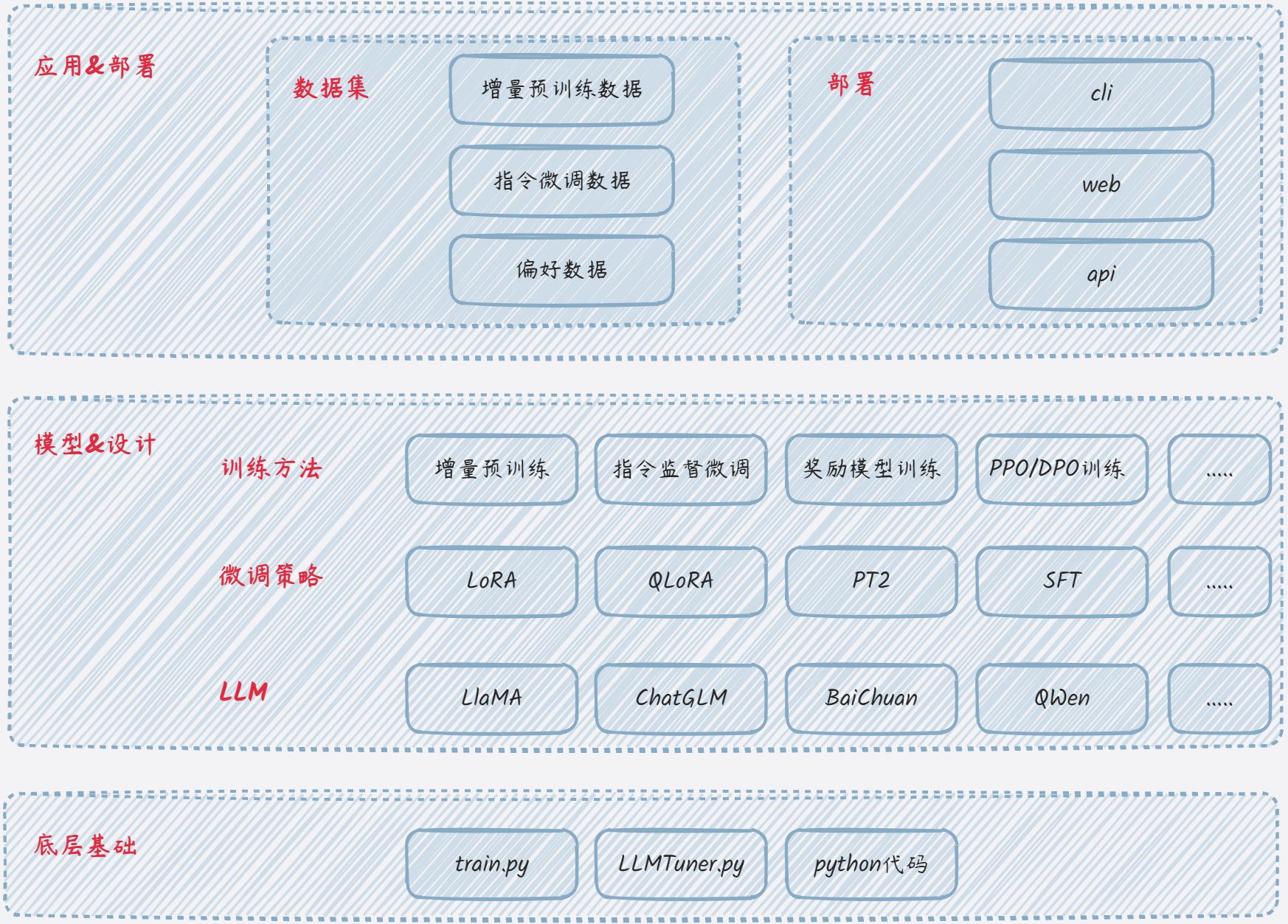
最近试玩了这两个框架,个人觉得蛮好的,先不说实际的调试效果,这取决于多种因素,总的来说还是很方便快捷的。方便快捷的基于多种微调策略调试LLM;同时支持多种数据集类型。
LLaMA-Factory
这个开源库相比较其余的库,更全面,更方便。有如下几点我是比较喜欢的。
- 训练方法
- 如图,多种训练方法都支持,很全面。不过这里的预训练,我理解为是增量预训练;即准备大量的文本数据训练。
- 支持全参数、部分参数、LoRA等策略微调。
- 降低门槛,一键训练。对于学习来说,可以增加知识面及使用。

- 数据集
- 支持多种数据集:增量预训练数据集、指令微调数据集、偏好数据集;在官方文档都是有说明的。
- 每次微调前,我都需要斟酌数据集的准备、格式等;但开源库已经准备的很齐全而且各种场景的数据格式都有,直接参考即可;比如单轮对话、多轮对话、指令格式等等。这就极大的方便了数据集的准备。
- 其它
- 当然还有分布式训练、web界面操作等等
ChatGLM-Finetuning
Finetuning 是专门基于GLM系列的微调库,我个人也试用,还是很方便快速的,而且文档比较清晰,只是在部署时比较简陋,但对于要学习了解微调及LLM一些原理来说,还是很适合入门钻研的。
应用
目前绝大多数的大模型都是基于基座模型(GLM、QWen、LlaMa、BaiChuan)等微调训练而来,不过实现的逻辑却是有多种,要么基于官方的微调文档,要么基于开源微调库实现。CareGPT 就是基于开源微调库LLaMA-Factory实现的医疗领域大模型。其架构设计如下:
在其架构设计中,有两个部分比较值得关注:
- 微调框架的集成
- 通过集成了微调框架,调用底层具备的能力,准备多种格式的数据集微调模型。
- 数据开放
- 基于开源医疗数据集,准备增量预训练预料、指令监督预料、SFT预料等等;扩充基座模型的领域知识能力。
总结
基于个人使用及学习的角度,介绍了微调框架的概述及其应用。在这里面的道道还是蛮多的,有一定的大模型知识再基于这些库去做参考去做应用,将极大的降低LLM的应用门槛。更有甚者可以了解底层的实现逻辑。
标签:基于,训练,模型,微调,开源,聊聊,数据 From: https://www.cnblogs.com/chinasoft/p/18076505