LoRA训练主要基于:https://github.com/bmaltais/kohya_ss/tree/master开源代码,自带GUI,可以可视化训练
转载:https://zhuanlan.zhihu.com/p/640274202
Lora训练核心参数主要分为步数相关和速率、质量相关,接下来就展开讲讲。
步数相关
Image:训练集,原图质量越高,模型质量越好。
Repeat:学习次数。不是越高越好,太少的话模型学不透,太多可能导致模型固化,缺少天马行空的能力。
Epoch:循环次数。也不是学习越多、学习越久就更好,和repeat类似。
Batch size:并行数量。数值越高训练越快,但是太大会爆显存,根据自己的设备去调整。

数据集
首先训练集的准备是重中之重!!!如果仅仅是学习某个人体,物品的目标的话,一般最好不要有背景。如果需要学习一些小的细节,可以针对局部的区域进行裁剪曾广训练数据
比如,要尽量选择高清的图(几年前手机的前置自拍还是不要用了吧)
看一下对比,512*512的素材,像素清晰度也不一样。

然后是精准打标。
自动打标器肯定不能识别所有物体,需要手动去打标的进行修改,也可以采用chatGPT 相关开源大模型进行预打标。
有个小技巧:可以通过跑原tag检查模型训练效果,与原图越接近,说明tag越精准。

总结下训练集的要点:
- 原图分辨率越高越好,覆盖不同光影、不同角度。
- Tag除了AI自动打标外,还要手工调整、补充。
- 更好的原图,对学习参数的设置要求就会更高。
- 并不是图片越多越好。因为图片很多的时候,可能有很多重复的,影响训练方向。
关于batch
前两天我尝试训练的时候,就感觉到设置batch size为4或1时,同样的设置训练出来的效果不一样。
虽然大的batch size训练速度快,但也会导致收敛更加慢。因为学得更加快了,有点囫囵吞枣,就导致真正学到和素材很像的过程比较慢。
这种情况下,去调整epoch和学习率就好了,总的时间还是会比一张一张训练更快的。

总结:想要batch更大,就加大epoch数,增加学习率。
最后,训练时会根据repeat、epoch、batch size计算得到一个总步数:

速率、质量相关
Unet lr:unet网络的学习率
Text encoder lr:Text编码网络的学习率
Optimizer:优化器方法,不同优化器适用模式不一。
Dim:学习精度,精细度高,模型的细节更好。
调整学习率
通常调整unet学习率为1e-4,设置它之后会覆盖learning rate学习率的数值。text_encoder的学习率通常是unet的十分之一或二分之一左右。
视频里也只是针对新手初步讲了推荐数值,和现在默认数值一样。

关于dim,是输出的一个向量维度,维度越大,表示细节越多,但也不是越高越好,还要分对象去对待。
现在主要分为32、64、128三档,选用不同的大小,最后出来的模型大小也不一样:

果然,好用的主流模型,基本都是140M左右。
这里up总结了下DIM的数值推荐,出图精度很高的都得128往上。看来我要去调整一下,真人lora要设置成128了~

优化器选择
常用优化器:AdamW8bit、DAdaptation、Lion。看了下,程序默认的是AdamW8bit。
因为DAdaptation是一个可以自动调整学习率的优化器,所以可以用来测试一组素材它的最优学习率是什么。
这下知道前几天在知乎看的一个教程是什么意思了:
“青龙圣者的攻略,就是先用DAdaptation优化器跑模型(跑开头几分钟取到学习率就就可以停止了)、同时用TensorBoard监视训练日志,等到学习率一稳定,就记录下来,除以3之后换用Lion优化器跑。”
UP主也是差不多这么说的:使用DAdaptation时,需要把unet学习率设成1,text的学习率设成0.5,让它自动去跑,过一会就能获得一个最优学习率。接下来用AdamW8bit跑,或者Lion学习率调整为最优的1/3跑。

实证数据
然后作者开始用实证数据举例。
1、关于不同repeat的设置:
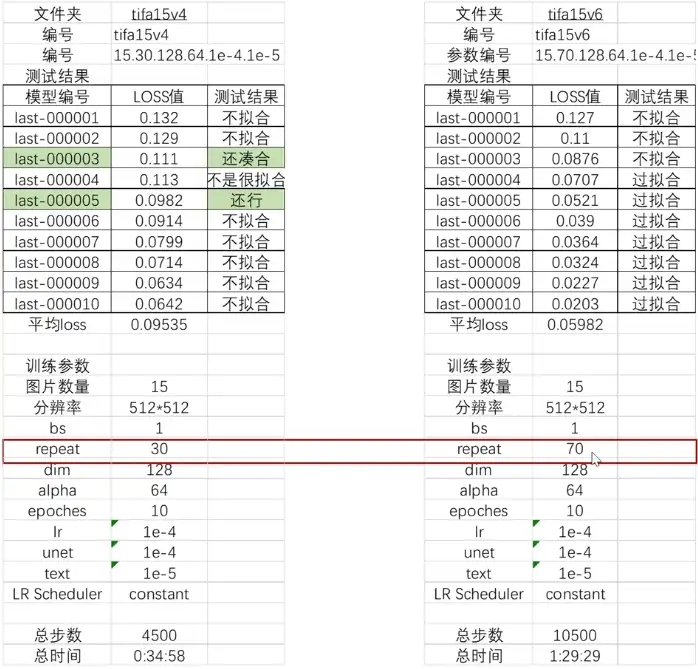
说说我学到的知识:
作者训练15张图,repeat设置成30,epoch为10,batch为1,居然没有学好。调整repeat到70就过拟合了。
这就尴尬了啊,我15张图像的repeat是5,epoch为20,batch也是1,就过拟合了。奥!看到dim我明白了~应该是因为我用的是32的dim,而UP用的128的dim,这个确实要花更多的时间去训练。
128dim的repeat参数设置get√。
2、关于总repeat一样,但是repeat设置和epoch不一样的情况:
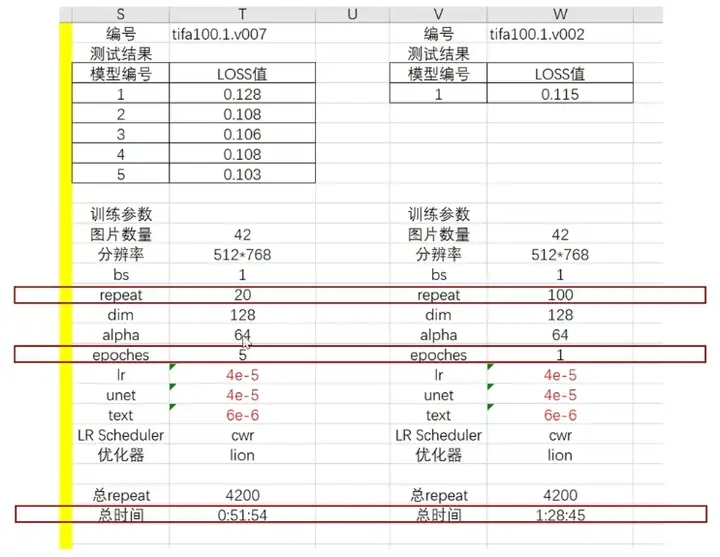
先看时间,如果只学习一个epoch,但是重复学100次,它的时间居然要比前面多出半个多小时。
多的epoch可以得到相对更低的loss,且比单一epoch的方案,训练更快。
而且,可以根据轮次保存多个模型的呀,所以还是不要设置太少的轮次了,不然可能错过比较好的结果。
repeat与epoch的平衡设置get√。
3、关于学习率的设置:
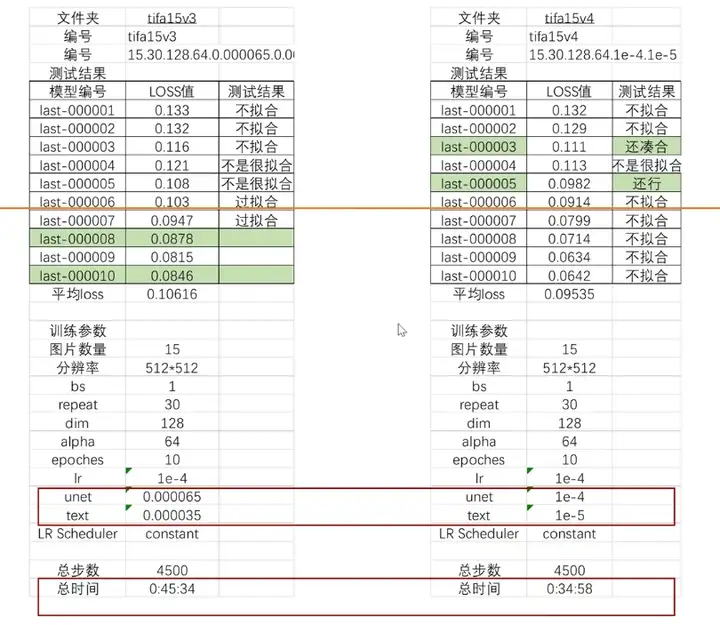
看右边,高的学习率训练更快,收敛更快,在第5轮即得到了不错的模型。
不过也给了我一个启示,就是中间的模型可能是拟合的,后面的模型不一定是过拟合,也可能是不拟合。
最后UP给新手一些建议:

(1)图像数量先不用太多,不然会消耗更多的时间。
(2)二次元的repeat不需要太多,而实物和人物需要更多细节,需要更高的repeat。
(3)epoch先用10,看一下loss,说是人物loss到0.08左右,二次元0.05左右就可以。从上面有个图也能看出,loss不是越低越好。
(4)unet学习率1e-4。如果loss下不去,就提高学习率;如果loss太低或者没有得到一个特别像的模型,可能是设置高了,再降低些试试。
(5)dim,直接上128就完事。还有个alpha参数,建议是128的一半,不要超过dim。
(6)loss通常0.08左右是最优的,不过也比较玄学,还是用xyz图表测一下。
成功lora模型的参数设定
chinesedolllikeness
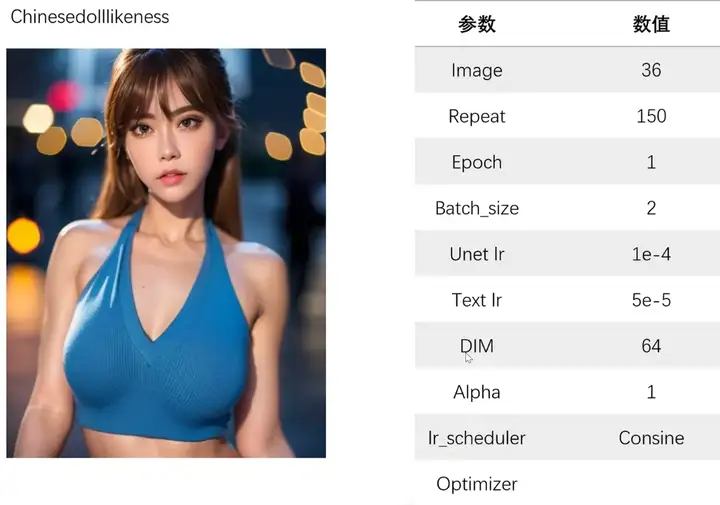
居然只用了38张~repeat150,epoch为1,这是有多自信!
AESPA Karina

repeat只有7,比较像二次元的训练模式。
小人书连环画
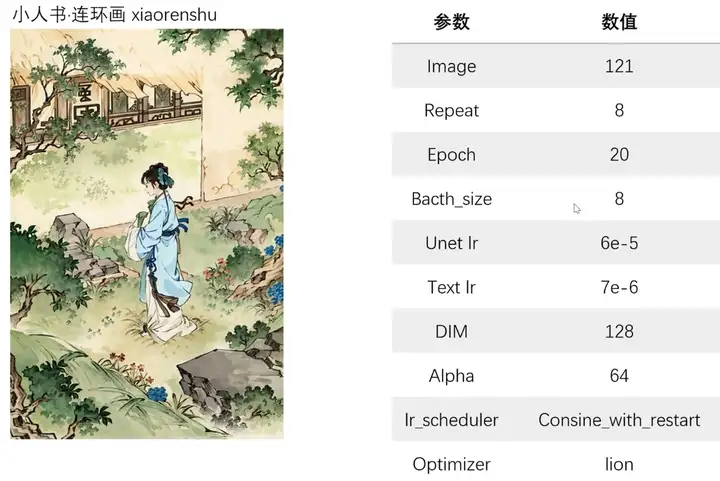
repeat为8,epoch为20,非常标准的二次元训练参数。
☆大家可以根据成功模型的经验,进行模型的训练。
上述笔记总结到视频的1个小时左右,后面有些是实操内容,不好描述,可以亲自去参考一下。
[全网最细lora模型训练教程]这时长?你没看错。还教不会的话,我只能说,师弟/妹,仙缘已了,你下山去吧!_哔哩哔哩_bilibili
标签:repeat,训练,模型,batch,学习,epoch,lora,参数设置 From: https://www.cnblogs.com/hansjorn/p/18075082