泛型
泛型(Generics)是JDK1.5版本增加的技术,他可以帮助我们建立类型安全的集合。在使用了泛型的集合中,不必进行强制类型转换。JDK提供了支持泛型的编译器,将运行时的类型检查提前到了编译时执行,使代码可读性和安全性更高。
不使用泛型:
public static void main(String[] args) {
List myList = new ArrayList();
//准备对象
Cat c = new Cat();
Bird b = new Bird();
myList.add(c);
myList.add(b);
//遍历集合,调用特有方法
Iterator iterator = myList.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
if (obj instanceof Cat){
((Cat) obj).catchMouse();
}else {
((Bird)obj).flying();
}
}
}
在JDK1.5版本之前,我们通过Object类型来实现参数的“任意化”,但是“任意化”带来的代价是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
可以使用泛型 List<Animal> 指定集合中的数据类型 只允许存储Animal类型的数据
泛型使得集合中的数据更加统一了
在迭代器获取元素的时候也可以使用泛型:

因为在声明集合的时候使用了泛型:

而迭代器中的泛型和集合相同:

这样获取到的就是声明集合时指定的元素类型。
获取到的就是Animal类型的对象,因为我们想要求这个类只能对某些类型的数据进行操作,add/get方法都限制了只能对这些类型的数据进行操作
public static void main(String[] args) {
List<Animal> myList = new ArrayList<Animal>();
myList.add(new Bird());
myList.add(new Cat());
Iterator<Animal> iterator = myList.iterator();
while (iterator.hasNext()){
Animal animal = iterator.next();
animal.move();
}
}
泛型机制 只在程序编译阶段起作用,运行阶段不起作用
- 集合中存储的元素类型统一了
- 集合中取出的元素类型是泛型指定的类型,不需要进行大量的向下转型
缺点:导致集合中存储的元素缺乏多样性 ?
自动类型推断机制
JDK7.0 新特性,又称为钻石表达式
public static void main(String[] args) {
//new ArrayList<>() 尖括号中内容可以省略
ArrayList<Animal> myList = new ArrayList<>();
//遍历
Iterator<Animal> iterator = myList.iterator();
while(iterator.hasNext()){
Animal a = iterator.next();
a.move();
}
}
规定泛型使用 String ,方法的参数就只能是String
public class GenericTest03 <标识符随便写> {
public static void main(String[] args) {
GenericTest03<String> gt = new GenericTest03<>();
gt.doSome(); //此处只能是String
}
public void doSome(标识符随便写 a){
System.out.println(a);
}
}
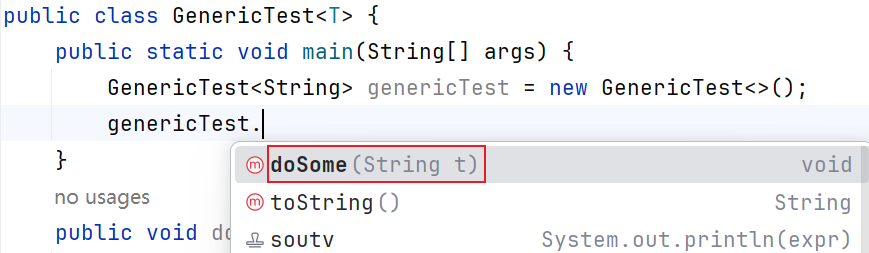
示例:
public interface Iterator<E>
假如规定ArrayList中存储的是Animal类型,其中Itr内部类的Iterator接口同时被指定该类型,next()返回的结果就是Animal类型:
E next();
有类定义如下:
class MyIterator<T>{
public T get(){
return null;
}
}
如果写了泛型没有使用:

该类的泛型就被替换为Object
泛型擦除
Java中的泛型是伪泛型,例如定义:ArrayList<String>,编译器只在添加元素时检查是不是String类型的数据,在集合中还是看作Object类型,并且在获取的时候会将Object类型的数据强转为String类型
Java源文件:
ArrayList<String> list = new ArrayList();
编译为class文件:
ArrayList list = new ArrayList();
这就叫做泛型的擦除。
注意:泛型不能写基本数据类型,因为集合中存储的所有元素都看作Object,而基本数据类型是不能转换为Object的,只能写包装类
可以使用反射绕过编译器的检查:
public class GenericClassDemo {
public static void main(String[] args) throws Exception {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
// 编译器会阻止
// list.add(333);
// 但泛型约束只存在于编译期,底层仍是Object,所以运行期可以往List存入任何类型的元素
Method addMethod = list.getClass().getDeclaredMethod("add", Object.class);
addMethod.invoke(list, 333);
// 打印输出观察是否成功存入Integer(注意用Object接收)
for (Object obj : list) {
System.out.println(obj);
}
//但是get该元素就会ClassCastException
}
}
泛型的擦除与补偿
泛型的出现提高了编译时的安全性,正因为编译时对添加的数据做了检查,则程序运行时才不会抛出类型转换异常。因此泛型本质上是编译时期的技术,是专门给编译器用的。
加载类的时候,会将泛型擦除掉(擦除之后的类型为Object类型),这个称为泛型擦除。
为什么要有泛型擦除呢?其本质是为了让JDK1.4和JDK1.5能够兼容同一个类加载器。在JDK1.5版本中,程序编译时期会对集合添加的元素进行安全检查,如果检查完是安全的、没有错误的,那么就意味着添加的元素都属于同一种数据类型,则加载类时就可以把这个泛型擦除掉,将泛型擦除后的类型就是Object类,这样擦除之后的代码就与JDK1.4的代码一致。
因为加载类的时候,会默认将类中的泛型擦除为Object类型,所以添加的元素就被转化为Object类型,同时取出的元素也默认为Object类型。而我们获得集合中的元素时,按理说取出的元素应该是Object类型,为什么取出的元素却是实际添加的元素类型呢?
这里又做了一个默认的操作,我们称之为泛型补偿。在程序运行时,通过获取元素时指定的实际类型进行强转,这就叫做泛型补偿(不必手动实现强制转换)。获得集合中的元素时,虚拟机会根据获得元素的实际类型进行向下转型,也就是会恢复获得元素的实际类型,因此我们就无需手动执行向下转型操作,从本质上避免了抛出类型转换异常。
如果获取元素时指定的实际类型是Object,就不需要转型了
泛型类
当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类。
public class Test<E>{
E e;
}
实现ArrarList的add和get方法:
class MyArrayList<E>{
Object[] objs = new Object[10];
int size;
public boolean add(E e){
/* if (size == objs.length)
objs = grow(); */ objs[size++] = e;
return true;
}
public E get(int index){
return (E) objs[index];
}
}
add方法要求只能存入指定泛型的元素,所以参数是E
ArrayList的get方法:

从集合中拿出元素的时候也要转换为泛型对应的类型
验证了:泛型只在向集合中存或从集合中取时有效,在集合内部还是将元素看作Object类型
泛型方法
方法中形参类型不确定时,可以使用类名后面定义的泛型。
如果一个类中只有一个方法的形参类型不确定,可以在方法申明上定义自己的泛型
格式:
public <T> void show(T t){}
[修饰符列表] <类型> 返回值类型 方法名(类型 变量名){}
在调用该方法时,T的类型才确定
练习:定义一个工具类:ListUtil,类中定义一个静态方法addAll,用来向指定集合中添加多个元素。
public class Generic_test {
public static void main(String[] args) {
ArrayList<Animal> animals = new ArrayList<>();
animals.add(new Cat());
animals.add(new Dog());
ListUtils.addAll(animals,new Cat(),new Dog(),new Object());
System.out.println(animals);
Animal animal = animals.get(animals.size() - 1);
System.out.println(animal); //ClassCastException
}
}
class ListUtils{
public static void addAll(List list,Object ... objs){
for (int i = 0; i < objs.length; i++) {
list.add(objs[i]); //编译完成后,add方法的参数被替换为Animal,为什么obj可以赋值给Animal?
}
}
}
为什么能存入?
这样做是不行的,获取到在第8行获取animal时,编译器认为取出的是Animal类型,但是实际上取出的是Object类型,ListUtils中addAll方法未对泛型进行限制,应该根据List的泛型来要求只能存入对应类型的元素
class ListUtils{
public static <E> void addAll(List<E> list,E ... es){
for (int i = 0; i < es.length; i++) {
list.add(es[i]);
}
}
}

方法调用时,泛型的类型,也就是参数的类型就被确定了
泛型接口
修饰符 interface 接口名<类型>{
}
public interface List<E>{
}
使用带有泛型的接口:
- 实现类给出具体类型

- 实现类延续泛型,创建对象时再确定具体的类型
泛型的继承和通配符
- 泛型不具备继承性,但是数据具备继承性

method方法指明了参数是 ArrayList<Animal>,但是ArrayList<Cat>不是它的子类,只有ArrayList 的子类可以传入,并且泛型要和指定泛型相同
假设有ArrayList的子类SubArrayList:
class SubArrayList extends ArrayList{
}
就可以传入这样的方法:

并不会报错:

练习:定义方法,形参是一个集合,集合中的数据类型不确定
public static <E> void method(ArrayList<E> list){
}
但是这样写有一个弊端,传递进去的可以是Animal、Car、Student等任意类型的数据
如果要求只能传递Animal及其子类,可以使用泛型的通配符
泛型的通配符:?表示不确定的类型,但是可以进行类型的限定:
? extends E:表示可以传递E或者E所有的子类类型? super E:表示可以传递E或者E所有的父类类型
注意:使用通配符不需要在方法的修饰符后再次声明
public static void method(ArrayList<? extends Animal> list){
}
表示现在的method方法中ArrayList的类型只能是Animal及其子类
public static void method(ArrayList<? super Animal> list){
}
表示现在的method方法中ArrayList的类型只能是Animal及其父类(Object)
应用场景:
- 如果在定义类、方法、接口时,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口。
- 如果类型不确定,但知道只能传递某个继承体系中的类型,就可以使用泛型的通配符
关键点:可以限定类型的范围。
泛型思考
上:特定化与泛型
在JDK1.5引入泛型之前,ArrayList采取的方式是:在内部塞入一个Object[] array。
public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {...}
public void remove(int index) {...}
public Object get(int index) {...}
}
如果用JDK1.5以前的ArrayList存储String类型,那么会有以下两个缺点(其实是问题的一体两面):
- 需要强制转型
- 强制转型容易出错
例如,代码必须这么写:
ArrayList list = new ArrayList();
list.add("Hello");
// 获取到Object,必须强制转型为String:
String first = (String) list.get(0);
为什么要强制转型?因为String是真正的类型,转型后才能使用String特有的方法,比如replace()。
OK,在确认必须强转的前提下,我们继续讨论。
强转会带来一个问题:很容易出现ClassCastException。
// JDK1.4可以这样做
list.add(new Integer(123));
// ERROR: ClassCastException:
String second = (String) list.get(1);
作为一种解决方法,JDK1.5之前的程序员可以为String类型单独编写一种ArrayList:
public class StringArrayList {
// 因为这种ArrayList只存String,所以不需要用Object[]兼容所有类型,只要String[]即可
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
这样一来,存入和取出都被限定为String,且不需要强制转型,因为编译器会强制检查放入的类型:
StringArrayList list = new StringArrayList();
list.add("Hello");
String first = list.get(0);
// 编译错误: 不允许放入非String类型:
list.add(new Integer(123));
问题暂时解决。
然而,新的问题是,如果要存储Integer,还需要为Integer单独编写一种ArrayList:
public class IntegerArrayList {
private Integer[] array;
private int size;
public void add(Integer e) {...}
public void remove(int index) {...}
public Integer get(int index) {...}
}
如果还有其他类型,就要编写各种各样特定类型的ArrayList:
- LongArrayList
- DoubleArrayList
- PersonArrayList
- ...
这是不可能的,光JDK的class就有成千上万个,而且还不算普通Java用户编写的类。
为了解决新的问题,我们必须把ArrayList变成一种模板。
什么是模板呢?以设计模式中的模板方法模式为例:
/**
* 验证码发送器
*
* @author qiyu
* @date 2020-09-08 19:38
*/
public abstract class AbstractValidateCodeSender {
/**
* 生成并发送验证码
*/
public void sendValidateCode() {
// 1.生成验证码
String code = generateValidateCode();
// 2.把验证码存入Session
// ....
// 3.发送验证码
sendCode();
}
/**
* 具体发送逻辑,留给子类实现:发送邮件、或发送短信都行
*/
protected abstract void sendCode();
/**
* 生成验证码
*
* @return
*/
public String generateValidateCode() {
return "123456";
}
}
对于上面的模板,我们可以有多种实现方式:
/**
* 短信验证码发送
*
* @author qiyu
* @date 2020-09-08 19:44
*/
public class SmsValidateCodeSender extends AbstractValidateCodeSender {
@Override
protected void sendCode() {
// 通过阿里云短信发送
}
}
/**
* QQ邮箱验证码发送
*
* @author qiyu
* @date 2020-09-08 19:45
*/
public class EmailValidateCodeSender extends AbstractValidateCodeSender {
@Override
protected void sendCode() {
// 通过QQ邮箱发送
}
}
所谓模板,就是“我能做的都给你做了,少量易变动的东西我留出来,你自己DIY去”。
同理,ArrayList<T>也是一种模板,能写的方法都给你写了,但变量类型我定不了,于是抽成类型参数:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
T可以是任何class类型,反正我已经帮你参数化了,你自己定。
这样一来,我们就实现了:只需编写一次模版,可以创建任意类型的ArrayList:
// 创建可以存储String的ArrayList:
ArrayList<String> strList = new ArrayList<>();
// 创建可以存储Float的ArrayList:
ArrayList<Float> floatList = new ArrayList<>();
// 创建可以存储Person的ArrayList:
ArrayList<Person> personList = new ArrayList<>();
因此,泛型类就是一种模板类,例如ArrayList<T>,然后使用者可以自己选择将模板填充为什么类型:
// 嘿嘿,我想把ArrayList<T>填充为ArrayList<String>,专门收纳String类型
ArrayList<String> strList = new ArrayList<>();
你可以理解为此时ArrayList内部自动被赋值成这样(编译器层面):
public class StringArrayList {
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
由编译器针对类型作检查:
strList.add("hello"); // OK
String s = strList.get(0); // OK,因为上面add()保证了只能添加String类型,所以无需强制转型
strList.add(new Integer(123)); // compile error!
Integer n = strList.get(0); // compile error!
这样一来,既实现了编写一次万能匹配,又能通过编译器保证类型安全:这就是泛型。
形式类型参数、实际类型参数
泛型是一种技术,而不是单指ArrayList<T>中的T。像ArrayList<T>的T,Map<K, V>中K和V,统称类型参数(Type Parameter),也叫形式类型参数,它只是泛型这个技术的组成部分。
使用泛型时,比如ArrayList<String>,T被替换为String,可以看做是对T的“赋值”,这里的String称为实际类型参数(actual type parameter)。
实际类型参数用来为形式类型参数赋值,把 ArrayList<T> 由泛化通用的模板变为特定类型的类。可以把泛型理解为:变量是对数据的抽取,泛型是对变量类型的抽取,抽取成类型参数,抽象层次更高。
举个例子,当你看到同事A写了以下代码:
// 获取教师列表
public List<User> listTeachers() {
return jdbcTemplate.execute("select * from t_user where user_type=1");
}
// 获取学生列表
public List<User> listStudents() {
return jdbcTemplate.execute("select * from t_user where user_type=2");
}
你肯定会下意识地建议他:哦,我的天哪,你应该把userType提取为方法参数:
public List<User> listUser(Integer userType) {
return jdbcTemplate.execute("select * from t_user where user_type=" + userType);
}
从某种程度来说,把SQL中的user_type=1、user_type=2提升为方法入参,就是为了通用性,解决了硬编码(hard code)问题。但在绝大部分初学者的认知里,对于:
- 1
- 2
- "a"
- "b"
他们往往只能达到以下层次:
- private Integer value
- private String value
对于Java这种语言来说,一个变量其实应该至少包含两部分(访问权限暂不讨论):
- 变量类型
- 变量值
大部分人只能想到抽取变量值,无法达到抽取变量类型的层次。那怎么才能达到抽取变量类型的层次呢?或者说,什么场景下需要抽取变量类型呢?
假设你有一天你发现同事A又在写bug:
public final class MapUtil {
// 私有构造
private MapUtil() { }
// 把userList转为userMap
public static Map<Long, User> listToMap(List<User> list) {
if (CollectionUtils.isEmpty(list)) {
return Collections.emptyMap();
}
Map<Long, User> userMap = Maps.newHashMap();
for (User user : list) {
userMap.put(user.getId, user);
}
return userMap;
}
// 把departmentList转为departmentMap
public static Map<Long, Department> listToMap(List<Department> list) {
if (CollectionUtils.isEmpty(list)) {
return Collections.emptyMap();
}
Map<Long, Department> departmentMap = Maps.newHashMap();
for (Department department : list) {
departmentMap.put(department.getId, department);
}
return departmentMap;
}
}
你看到上面的代码,又开始阴阳怪气地说:哦,我的天哪,你应该...
“闭上你的嘴,我TMD知道要用泛型!”,同事A愤怒地骂道。只见他在你面前飞快地重构MapUtil:
public final class MapUtil {
private MapUtil() { }
public static <V, K> Map<K, V> listToMap(List<V> list, Function<V, K> keyExtractor) {
if (CollectionUtils.isEmpty(list)) {
return Collections.emptyMap();
}
Map<K, V> res = Maps.newHashMap();
for (V v : list) {
K k = keyExtractor.apply(v);
if (k == null) {
continue;
}
res.put(k, v);
}
return res;
}
}
重构后的代码,和原先的两个方法在结构上几乎一模一样(忽略keyExractor这个函数式接口),只是变量类型换成了类型参数,即“对变量类型进行抽取”(所以在泛型里,List<T>中的T叫类型参数),而代码也更加通用了。
把变量类型抽取成类型参数T构造出模板代码,再通过实际类型参数赋值(比如ArrayList<T>变成ArrayList<User>),把类型特定化,最后配合编译器在编译期对相关操作的变量类型进行约束,这就是泛型。
抽取变量,我们早就习以为常,但抽取变量类型,却从未听说。这也是初学者觉得泛型抽象的根本原因
泛型是对引用类型的抽取,基本类型是无法抽取的
ArrayList与泛型
泛型是实现模板代码的一种手段
文章中经过一次次演化,我们的ArrayList最终变成了这样:
public class ArrayList<T> {
private T[] array; // 我们以为ArrayList<T>内部会有个T[] array
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
但泛型数组其实是非常特殊的,Java并不能直接实现泛型数组。ArrayList内部实际上仍然沿用了之前的Object[]。
那么,ArrayList为什么还能进行类型约束和自动类型转换呢?
下:泛型实现机制
要回答这个问题,我们必须了解Java的两个阶段:编译期、运行期。你可以理解为Java代码运行有4个要素:
- 源代码
- 编译器
- 字节码
- 虚拟机
也就是说,Java有两台很重要的机器,编译器和虚拟机。
在代码编写阶段,我们确实引入了泛型对变量类型进行泛化抽取,让类型是不特定的(不特定的即通用的),从而创造了通用的代码模板,比如ArrayList<T>:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
模板定好后,如果我们希望这个ArrayList只处理String类型,就传入类型参数,把T“赋值为”String,比如ArrayList<String>,此时你可以理解为代码变成了这样:
public class ArrayList<String> {
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
所以add(1)会编译报错。
但事实真的如此吗?
我们必须去了解泛型的底层机制。
泛型擦除与自动类型转换
我们来研究以下代码:
public class GenericDemo {
public static void main(String[] args) {
UserDao userDao = new UserDao();
User user = userDao.get(new User());
List<User> list = userDao.getList(new User());
}
}
class BaseDao<T> {
public T get(T t){
return t;
}
public List<T> getList(T t){
return new ArrayList<>();
}
}
class UserDao extends BaseDao<User> {
}
class User{
}
编译得到字节码:
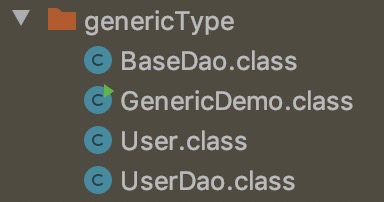
通过反编译工具,反编译字节码:
public class GenericDemo {
// 编译器会为我们自动加上无参构造器
public GenericDemo() {}
public static void main(String args[]) {
UserDao userDao = new UserDao();
/**
* 1.原先代码是 User user = userDao.get(new User());
* 编译器加上了(User),做了类型强转
*/
User user = (User)userDao.get(new User());
/**
* 2.List<User>的泛型被擦除了,只剩下List
*/
java.util.List list = userDao.getList(new User());
}
}
class BaseDao {
BaseDao() {}
// 编译器编译后的字节码中,其实是没有泛型的,泛型T底层其实是Object
public Object get(Object t) {
return t;
}
public List getList(Object t) {
return new ArrayList();
}
}
// BaseDao<User>泛型也没了
class UserDao extends BaseDao {
UserDao(){}
}
class User {
User() {}
}
反编译后我们很容易发现,其实所谓的泛型T在编译后就会消失,底层其实还是Object。既然泛型底层用Object接收,那么:
- 对于
ArrayList<String>,为什么add(Integer i)会编译报错? - 对于
ArrayList<String>,list.get(0)为什么不需要强制转型?
因为泛型本身是一种编译时的机制,是Java程序员和编译器之间的协议。
ArrayList<T>是已经编写好的代码模板,底层还是Object[]接收元素,但我们可以通过ArrayList<String>的语法形式,告诉编译器:“我希望你把这个ArrayList看做StringArrayList”。
换句话说,编译器会根据我们指定的实际类型参数(ArrayList<String>中的String),自动地在编译器做好语法约束:
ArrayList<String>的add(E e)只能传String类型ArrayList<String>的get(i)返回值一定是String(转换为和泛型相同的类型时编译后自动强转,无需我们操心)
在使用泛型作为参数的方法中,编译器强制要求该方法只能传入该类型的实现类;在使用泛型作为返回值的方法中,编译器会自动的转型
此时我们就可以解释前文中的问题:
练习:定义一个工具类:ListUtil,类中定义一个静态方法addAll,用来向指定集合中添加多个元素。
public class Generic_test {
public static void main(String[] args) {
ArrayList<Animal> animals = new ArrayList<>();
animals.add(new Cat());
animals.add(new Dog());
ListUtils.addAll(animals,new Cat(),new Dog(),new Object());
System.out.println(animals);
Animal animal = animals.get(animals.size() - 1); ////ClassCastException
System.out.println(animal);
}
}
class ListUtils{
public static void addAll(List list,Object ... objs){
for (int i = 0; i < objs.length; i++) {
list.add(objs[i]); //编译完成后,add方法的参数被替换为Animal,为什么obj可以赋值给Animal?
}
}
}
为什么能存入?
因为泛型实际上被擦除了,add(E e) 还是add(Object e) ,并不是我们所认为的add(String) ,在取出的时候,如果这样获取元素:
Animal animal = animals.get(animals.size() - 1); ////ClassCastException
System.out.println(animal);
出错的原因是,这行代码其实被翻译为:
Animal animal = (Animal)animals.get(animals.size() - 1); ////ClassCastException
System.out.println(animal);
这样一定会出错的,因为该位置的元素实际上是Object类型,但如果换一种方式:
Object animal = animals.get(animals.size() - 1);
System.out.println(animal);
反编译:
Object animal = animals.get(animals.size() - 1);
System.out.println(animal);
没有进行强制类型转换,自然也没有异常了。
基于上面的实验,我们可以得到以下4个结论:
- 泛型是JDK专门为编译器创造的语法糖,只在编译期,由编译器负责解析,虚拟机不知情
- 存入:普通类继承泛型类并给变量类型T赋值后,就能强制让编译器帮忙进行类型校验

- 取出:代码编译时,编译器底层会根据实际类型参数自动进行类型转换,无需程序员在外部手动强转

- 实际上,编译后的Class文件还是JDK1.5以前的样子,虚拟机看到的仍然是Object
ArrayList本身并没有任何改变,只是引入了外部的力量,这个力量能够对一些行为进行约束。换言之,Java在编译期引入了泛型检测机制,对容器的使用进行了强制约束,但容器本身并没有发生实质性的改变。
如何利用反射绕过编译器对泛型的检查:
public class GenericClassDemo {
public static void main(String[] args) throws Exception {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
// 编译器会阻止
// list.add(333);
// 但泛型约束只存在于编译期,底层仍是Object,所以运行期可以往List存入任何类型的元素
Method addMethod = list.getClass().getDeclaredMethod("add", Object.class);
addMethod.invoke(list, 333);
// 打印输出观察是否成功存入Integer(注意用Object接收)
for (Object obj : list) {
System.out.println(obj);
}
}
}
泛型与多态
经过上面的介绍,大家开始慢慢觉得泛型只和编译器有关,但实际上泛型的成功离不开多态。
上一篇我们已经解释了为什么需要代码模板(通用),现在我们来聊聊为什么能实现代码模板。
代码模板的定义是,整个类框架都搭建好了,只是不确定操作什么类型的对象(变量)。但它必须做到:无论你传什么类型,模板都能接收。
泛型固然强悍,既能约束入参,又能对返回值进行自动转换。但大家有没有想过,对于编译器的“智能转换”,其实是需要多态支持的。如果Java本身不支持多态,那么即使语法层面做的再好,无法利用多态接收和强转都是白搭。
所以代码模板的本质就是:用Object接收一切对象,用泛型+编译器限定特定对象,用多态支持类型强转。
大家拷贝下方代码本地运行一下:
/**
* @author qiyu
* @date 2020-09-09 00:02
*/
public class ObjectArray {
public static void main(String[] args) {
// objects其实就是对应ArrayList内部的Object[]
Object[] objects = new Object[4];
// 引入泛型后的两个作用:
// 1.入参约束:如果是ArrayList,那么入参约束会在一开始就确定,而下面的objects就惨多了,Integer/String都可以随意出入
objects[0] = 1;
objects[1] = 2;
objects[2] = "3";
objects[3] = "4";
// 2.自动类型转换:如果是ArrayList,由于入参已经被约束,那么返回值类型也随之确定,编译器会帮我们自动转换,无需显式地手动强转
Integer zero = (Integer) objects[0];
Integer one = (Integer) objects[1];
String two = (String) objects[2];
String three = (String) objects[3];
System.out.println(zero + " " + one + " " + two + " " + three);
}
}
上面的代码是对泛型底层运作的模拟。
当泛型完成了“编译时检查”和“编译时自动类型转换”的作用后,底层还是要多态来支持。
你可以理解为泛型有以下作用:
抽取代码模板:代码复用并且可以通过指定类型参数与编译器达成约定
类型校验:编译时阻止不匹配元素进入Object[]
类型强转:根据泛型自动强转(多态,向下转型)

但实际运行时,Object[]接收特定类型的元素,体现了多态,取出Object[]元素并强转,也体现了多态。
如果一段代码注定要报错,那么应该尽量提前到编译期,而且编译器自动转型比手动转型安全得多。
所以,泛型只是程序员和编译器的约定,程序员告诉编译器,我假定这个List只能存String,你帮我盯着点。对于存入的方法,如果不小心放错类型,就编译报错提醒我。对于取出的方法,编译时你根据我给的实际类型参数自动帮我类型转换。
泛型:其实一切都是确定的
对于初学者来说,他们惧怕泛型是因为泛型给人一种不确定的感觉。我们一起再来看看文章开头的问题:

但是在Java中,只有多态是不确定的。
泛型真的把对象类型弄成了变量吗
并没有,通过反编译大家也看到了,其实根本没有所谓的泛型类型T,底层还是Object,所以当我们new一个ArrayList时,JVM根本不会傻傻等着T被确定。T作为参数类型,只作用于编译阶段,用来限制存入和强转取出,JVM是感知不到的,它不关心这个对象将来是ArrayList<Integer>还是ArrayList<String>,仍然还是按JDK1.4以前的做法,底层准备好Object[],以便利用多态特性接收任意类型的对象。
更何况JVM实际new对象是在运行期,编译期的小把戏和它有什么关系?
所以对于泛型类本身来说,它的类型是确定的,就是Object或Object[]数组。
只是在用到泛型的地方,编译器会帮你进行存取的限制
在编译之后,类型参数T就是确定的
对象类型不确定导致JVM无法创建对象?
如果你指的是泛型类内部的对象类型,上面已经解释了,它的类型是确定的,就是Object或Object[]数组。
如果你指的是存入的元素类型,这个就更荒谬了:
List<User> list = new ArrayList<>();
list.add(new User());
我就是踏踏实实new了一个User对象,怎么会是不确定的呢?
所以泛型有什么是不确定的吗?没有。
实在要说的话,泛型的不确定性在于程序员要求编译器检查的类型是不确定的:
ArrayList<Integer>:嘿,编译器,帮我把元素限制为Integer类型ArrayList<String>:嘿,编译器,帮我把元素限制为String类型- ...
大家可以暂时把Java的运行环境理解为一颗双层巧克力球,第一层是编译器,第二层是JVM,泛型可以暂时简单理解为一种约束性过滤,但JVM本身在JDK1.5前后是没有太大区别。
泛型是对变量类型的抽取,从而让变量类型变成一种参数(type parameter),最终得到通用的代码模板,但这种所谓的类型不确定,只是为了方便套用各种对象类型进行语法校验,都是编译期的。
而编译期的不确定并不影响运行期对象的创建,因为容器的对象类型始终是Object,元素的类型是用户自己指定的,比如new User(),也是确定的。
一点补充
Oracle官方文档解释了为什么要用泛型,但没解释为什么不支持基本类型:

JDK1.0开始就有基本数据类型和引用类型,直到JDK1.5才引入泛型。而引用类型存在多态,基本数据类型没有多态,因为多态是面向对象的特征。
多态极大地扩展了Java的可玩性,但也有一些弊端。还是以ArrayList为例:
ArrayList是JDK1.2出来的,那会儿还没有泛型,而ArrayList想什么都能存,于是内部用的是Object[]。一个Object[]存了具体类型的元素,本身就构成多态,那么取出时就会面临类型强转的问题(不转就用不了实际类型的很多方法)。
存进去时Object obj = new User(),取出来没记住,转成(Cat)obj了,就强转异常了,于是JDK1.5引入了泛型,在编译期进行约束并帮我们自动强转。
可以说,本身泛型的引入就是为了解决引用类型强转易出错的问题,也就自然不会去考虑基本类型。
当然,网上也有这样解释的,说JDK1.5不仅引入泛型,还同时发布自动拆装箱特性,所以int完全可以用Integer代替,也就无需支持int。
大家猜猜Integer、Long这些包装类啥时候出来的?是不是和我一样以为是JDK1.5出来的?

其实即使本身JDK1.5没有引入自动拆装箱,用Integer这些包装类也能勉强糊弄事,手动把基本类型包装后丢进去就好了。
但是大家有没有想过,JDK1.5发布泛型的同时为什么还发布了自动拆装箱特性?虽然真实原因已经无法考究,但我猜测自动拆装箱引入的目的有两个:
- 简化代码
- 从某种意义上让泛型支持基本类型
泛型是依赖 编译器+泛型擦除 实现的,它底层还是用Object去接收各类数据。即使编译器在语法上让ArrayList<int>过去了,泛型擦除后int可就要被Object接收了。
所以问题就变成了,Java能不能做到
Object obj = 666;
很显然,不能。 引入了自动拆装箱后还真能!

所以JDK1.5以后,只要你敢把基本类型数据赋值给引用类型,JDK就毫不留情地帮你转成包装类,到头来还是引用类型。
从这个层面来讲,JDK1.5以后基本类型也“变成了”引用类型(基本运算除外),泛型写成ArrayList<int>还是ArrayList<Integer>已经没有什么差别,甚至从语义上来讲ArrayList<Integer>似乎比ArrayList<int>更自洽,坚持了“泛型是对引用类型变量的抽取”这一信条。
我个人观点是,Java已经尽自己最大的努力让泛型支持基本类型了。只不过它不是从语法上支持,而是从功能上支持。拒绝ArrayList<int>保证语义自洽的同时,通过list.add(1)配合自动拆装箱新特性,从功能上实现对基本类型的支持 。
但归根结底,Java泛型之所以无法支持基本类型,还是因为存在泛型擦除,底层仍是Object,而基本类型无法直接赋值给Object类型,导致JDK只能用自动拆装箱特性来弥补,而自动拆装箱会带来性能损耗。
只能说JDK也是不得已而为之吧。
泛型边界
之前讲述了泛型是什么以及有什么用:
- 作用于编译期,由编译器解析,是一种兼具类型约束和自动转型的代码模板
- 存入:约束存入的元素类型,将可能的类型错误提前到编译期
- 取出:编译自动转型,消除手动强转,极大降低ClassCastException的风险
泛型只是程序员和编译器的约定。
我们可以通过泛型告诉编译器自己的意图:
我现在假定这个List只能存String,你帮我盯着点,后面如果不小心放错类型,在编译期报错提醒我。
当然,要想编译器帮我们约束类型,就必须按人家的规矩办事。就好比Spring明明告诉你默认读取resources/application.yml,你非要把配置文件命名为resources/config.yml当然就报错啦。
而泛型也有一套自己的规则,我们必须遵守这些规则才能让编译器按我们的意愿做出约束。
今天我们来学习泛型通配符。
在讲述通配符的语法规则时,我会尽量给出自己的理解,让大家更容易接受它们。另外需要说明的是,在泛型相关的文章里我们总是以List元素存入、取出举例子,是因为容器类是我们接触最多的,这样更好理解。实际上对于泛型类、泛型方法都是适用的,并不一定要是容器类。
简单泛型
JDK1.5以后,我们全面跨入泛型时代。
假设现在有一个需求:设计一个print方法打印任意类型的List。
你想显摆一下刚学的泛型,于是这样设计:
public class GenericClassDemo {
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
print(integerList);
}
public static void print(List<Integer> list) {
// 打印...
}
}
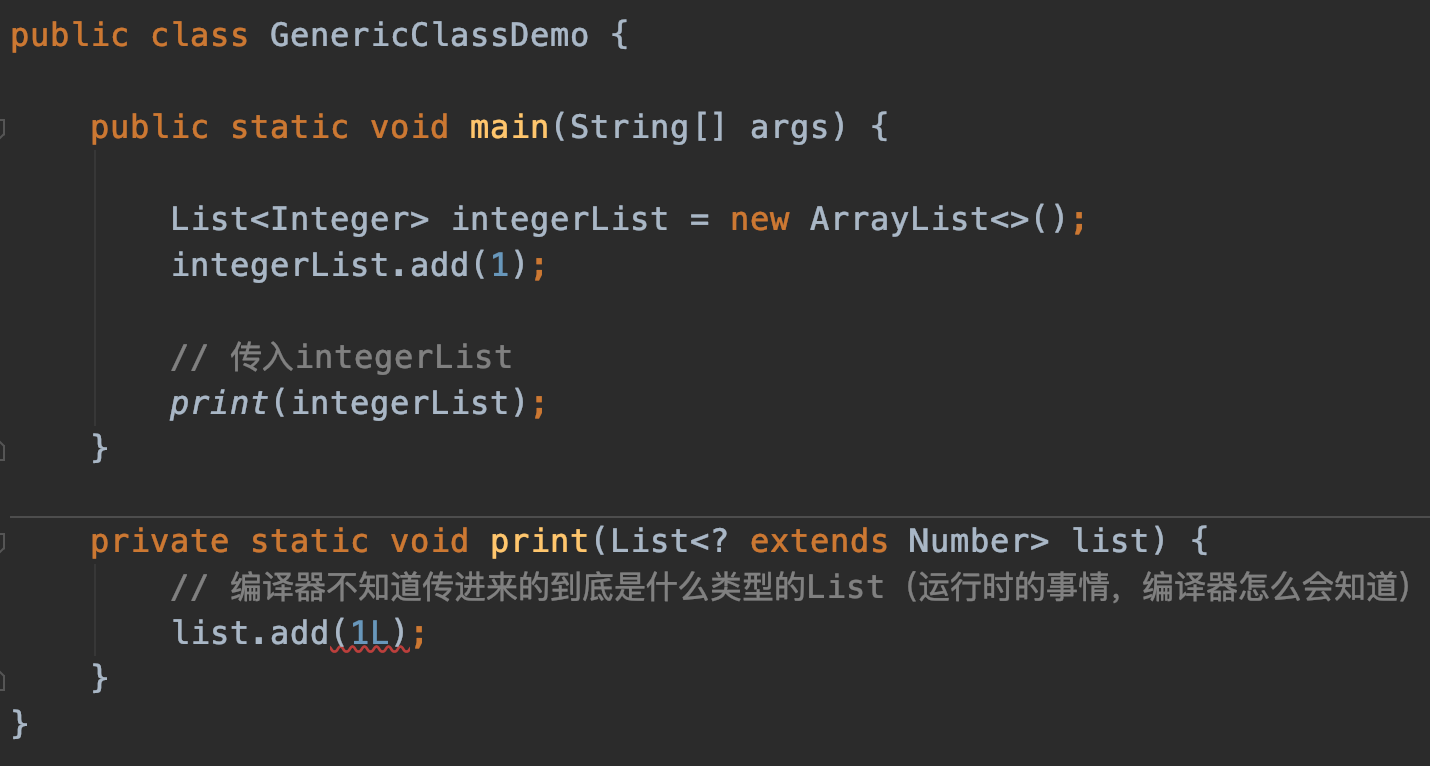
需求是打印任意类型的List。目前的print()只能接收List<Integer>,你传List<String>会报错:

你想了想,Object是所有对象的父类,我改成List<Object>吧:
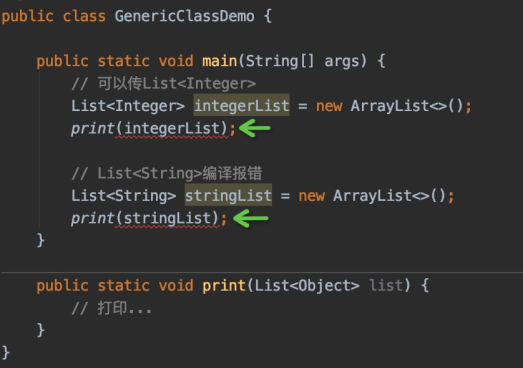
这下连List<Integer>都不行了。这是为什么呢?我们来分析一下原因。
实际编码时,常见的错误写法如下:
// 错误写法1:间接传递(通常发生在方法传参,比如将stringList传给print(List<Object> list))
List<String> stringList = new ArrayList<>();
List<Object> list = stringList;
// 错误写法2:直接赋值
List<Object> list = new ArrayList<String>();
list引用和实际指向的List容器类型必须一致(赋值操作左右两边的类型必须一致)。
JDK推荐的写法:
// 比较啰嗦的写法
List<String> list = new ArrayList<String>();
List<Object> list = new ArrayList<Object>();
// 省略写法,默认左右类型一致
List<String> list = new ArrayList<>();
List<Object> list = new ArrayList<>();
我们在前面已经了解到,泛型底层其实还是Object/Object[],所以上面的几种写法归根到底都是Object[]赋值给Object[],理论上是没有问题的。
那么我们不禁要问:既然底层都支持了,为什么编译器要禁止这种写法呢?
正向思考
首先,Object和String之间确实有继承关系,但List<Object>和List<String>没有,不能用多态的思维考虑这个问题(List和ArrayList才是继承/实现关系)
List<Object> list = new ArrayList<String>();
其次,讨论泛型时,大家应该尽量从语法角度分析。
左边List<Object>的意思是希望编译器帮它约束存入的元素类型为Object,而右边new ArrayList<String>()则希望约束存入的类型为String,此时就会出现两个约束标准,而它们却是对同一个List的约束,是自相矛盾的。
反向思考
如果上面的论述还是缺乏说服力,那么我们干脆假设List<Object> list = new ArrayList<String>()是合法的
先来看看数组是怎么处理类似问题的:
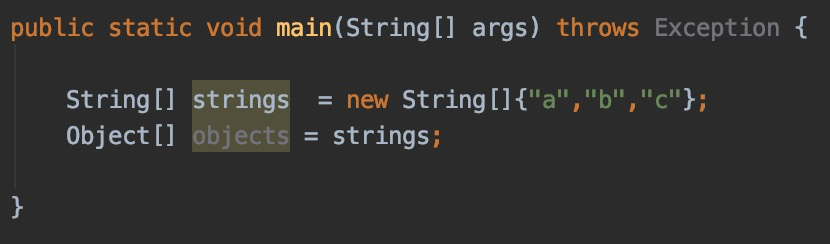
数组底层和泛型不同,泛型底层都是Object[]/Object[],而数组是真的分别创建了Object[]和String[],而且允许String[]赋值给Object[]。但这是它的弱点,给了异常可趁之机:
public static void main(String[] args) throws Exception {
// 直接往String[]存Integer会编译错误
String[] strings = new String[3];
strings[0] = "a";
strings[1] = "b";
strings[2] = 100; // COMPILE ERROR!
// 但数组允许String[]赋值给Object[]
Object[] objects = strings;
// 这样就能通过编译了,但运行期会抛异常:ArrayStoreException
objects[2] = 100;
}

数组允许String[]赋值给Object[],但却把错误被拖到了运行期,不容易定位。
同样的,如果泛型也允许这样的语法,那就和数组没区别了:
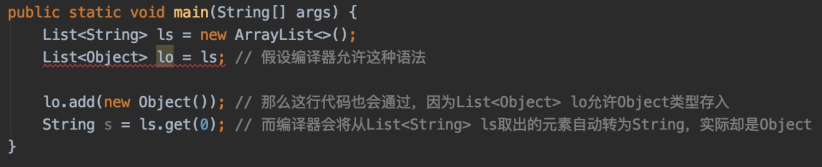
- 首先,ls.add(new Object())成功了,那就意味着之前
List<String>所做的约束都白费了,因为StringList中混入了别的类型 - 其次,编译器仍会按String自动转型,会发生ClassCastException
这么看来,泛型强制要求左右两边类型参数一致真是明智的举措,直接把错误扼杀在编译期。
泛型的指向和存取
在之前介绍泛型时,我们观察的维度只有存入和取出,实际上泛型还有一个很重要的约束:指向。为什么之前不提这个概念呢?因为之前接触的泛型都太简单了,比如List<String>只能指向List<String>,也就是泛型左右两边类型必须一致,没什么好讲的。
之前接触的是简单泛型,比如List<String> list = new ArrayList<String>(),左右的泛型类型必须一致
但是,观察如下代码:

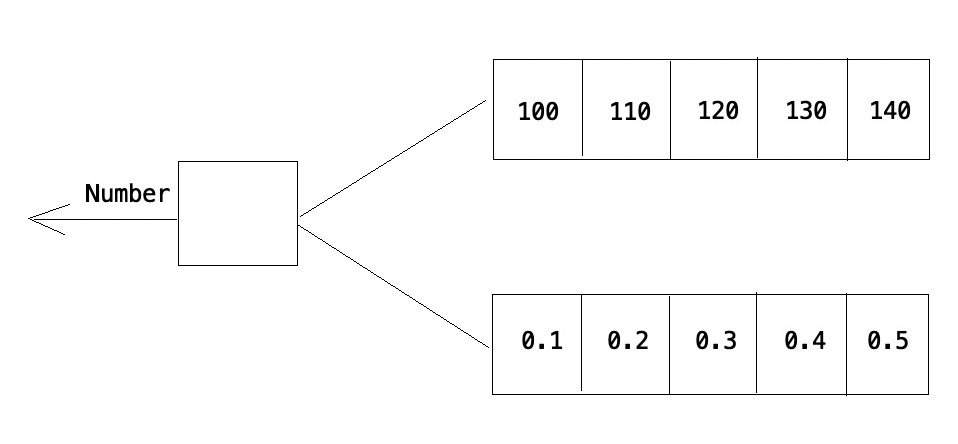
List<Number> 不只可以存入Number类型的数据,可以存入任何Number的子类,对于List<Number> 来说,反正取出时会向上转型为Number类型,很安全。
至此,我们完善了泛型最重要的两个概念:指向、存取。
对于简单泛型而言:
List<Number>指向:只能指向List<Number>,左右两边泛型必须一致(所以简单泛型解决不了print(List<???> list)的通用性问题)List<Number>存入:可以存入Integer/Long/BigDecimal...等Number子类元素List<Number>取出:自动按Number转(存在多态,不会报错)
后面学习通配符时,也请大家时刻保持清醒,多想想当前list可以指向什么类型的List,可以存取什么类型的元素。如果你觉得上面的推演太绕了,那么就记住:简单泛型的左右两边类型必须一致。
通配符
既然泛型强制要求左右两边类型参数必须一致,是否意味着永远无法封装一个方法打印任意类型的List?如何既能享受泛型的约束(防止出错),又能保留一定的通用性呢?
使用通配符就可以完成,我把List<T>、BaseDao<T>这样的称为简单泛型,把extends、super、?称为通配符。而简单泛型和通配符组合后又可以得到更为复杂的泛型,比如? extends T、? super T、?等。简而言之,通配符可以用来调节泛型的指向和存取之间的矛盾。
比如,有时我们需要list能指向不同类型的List(希望print()方法能接收更多类型的List)、有时我们又希望泛型能约束元素的存入和取出。但指向和存取往往不可兼得,具体要选用哪种泛型,需要根据实际情况做决定。
extends:上边界通配符
extends是上边界通配符,所以对于 List<? extends Number>,元素类型的天花板就是Number,右边List的元素类型只能比Number“低”。
List<? extends Number> list = new ArrayList<Integer>();
换句话说,List<? extends Number>只能指向List<Integer>、List<Long>等子类型List,不能指向List<Object>、List<String>。
记忆方法:
List<? extends Number> list = ...,把?看做右边List的元素(暂不确定,用?代替),? extends Number表示右边元素必须是Number的子类。
你可能会问:
之前简单泛型
List<Object>不能指向List<String>,怎么到了extends这就可以了。这不扯淡吗?
其实换个角度就是,Java规定简单泛型左右类型必须一致,但有些情况又要考虑通用性,所以又搞出了extends,允许List<? extends Number>指向子类型List。
之前我们假设过,如果允许简单泛型指向指向子类型List,那么存取会出问题:
现在extends通配符放宽了指向限制(List<? extends Human>允许指向List<Chinese>),是否意味着extends通配符也会发生强转错误呢?

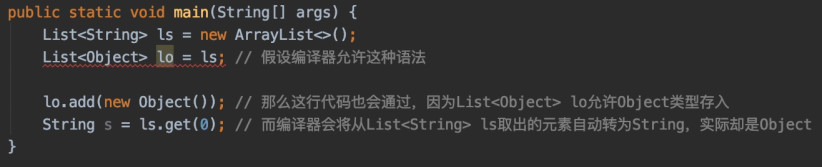
List<String> ls = new ArrayList<>();
List< ? extends Object> lo = ls;
lo.add(new Object()); //出错
//java: 不兼容的类型: java.lang.Object无法转换为capture#1, 共 ? extends java.lang.Object
ls.get(0);
jdk直接强制禁止进行存储
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
integerList.add(1);
List<Long> longList = new ArrayList<>();
longList.add(1L);
List<? extends Number> numberList = new ArrayList<>();
numberList = 随机指向integerList或longList等子类型List;
numberList.add(1); // 由于无法确定numberList指向哪个List,所以干脆禁止add(万一指向integerList,那么add(1L)就不合适了,取出时可能转型错误)
}
再举一个例子:
对于取出的情况:
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
integerList.add(1);
List<Long> longList = new ArrayList<>();
longList.add(1L);
List<? extends Number> numberList = integerList; // 不管numberList指向integerList还是longList
Number number = numberList.get(0); // 取出来的元素都可以转Number,因为Long/Integer都是它子类
}
看到这,我们应该有所体会:对于泛型而言,指向和存取是两个不同的方向,很难同时兼顾。要么指向放宽,存取收紧;要么指向收紧,存取放宽。
extends小结:
List<? extends Number>指向:Java允许extends指向子类型List,比如List<? extends Number>允许指向List<Integer>List<? extends Number>存入:禁止存入(防止出错)List<? extends Number>取出:由于指向的都是子类型List,所以按Number转肯定是正确的
相比简单泛型,extends虽然能大大提高指向的通用性,但为了防止出错,不得不禁止存入元素,也算是一种取舍。换句话说,print(List<? extends Number> list)对于传入的list只能做读操作,不能做写操作。
super:下边界通配符
super是下边界通配符,所以对于List<? super Integer>,元素类型的地板就是Integer,右边List的元素类型只能比Integer“高”。换句话说,List<? super Integer>只能指向List<Number>、List<Object>等父类型List。
记忆方法: List<? super Integer> list = ...,把?看做右边List的元素(暂不确定,用?代替),
? super Integer表示右边元素必须是Integer的父类。
super的特点是:
List<? super Integer>指向:只能指向父类型List,比如List<Number>、List<Object>List<? super Integer>存入:只能存Integer及其子类型元素List<? super Integer>取出:只能转Object
至此,我们发现Java同时满足了:
- extends:指向子类型List
- 简单泛型T:指向同类型List
- super:指向父类型List
说完指向问题,我们再来探讨一下存取问题。思路还是一样,既然Java允许List<? super Integer>指向List<Number>等父类型,那么如何防止存取出错呢?
假设存在class Human implement Swimming, Speaking,那么Swimming和Speaking都是Human的父类/父接口。由于List<? super Human>可以指向父类型List,要么指向SwimmingList,要么指向SpeakingList。

public static void main(String[] args) {
List<Swimming> swimmingList = new ArrayList<>();
// 假设加入了很多实现了Swimming接口的元素,比如Dolphin(海豚)
// swimmingList.add(dolphin)...
List<Speaking> speakingList = new ArrayList<>();
// 假设加入了很多实现了Speaking接口的元素,比如Parrot(鹦鹉)
// speakingList.add(parrot)...
List<? super Human> humanList = swimmingList / speakingList; // 指向随机的List
humanList.add(...) // 是否应该允许存入 Parrot(鹦鹉)?
}
此时对于List<? super Human>,是否应该允许加入 Parrot(鹦鹉)呢?答案是最好不要。因为humanList的指向是不确定的,如果刚好指向的是swimmingList,那么list.add(parrot)显然是不合适的。

只有存入Human及其子类才是安全的:

介绍完super的存入,最后聊聊super的取出。由于List<? super Human>可以指向任意Human父类型的List,可能是SwimmingList,也可能是SpeakingList。这意味取出的元素可能是Swimming,也可能是Speaking,是不确定的,所以用Swimming或Speaking都不太合适。

那能不能强转为Human呢?答案是不行。假设humanList指向的是swimmingList,而swimmingList里存的是Shark、Dolphin、Human,此时list.get(0)得到的是 Shark implements Swimming,强转为Human显然不合适。

?:无界通配符
允许指向任何类:

- 由于指向的List不确定,并且这些List没有共同的子类,所以找不到一种类型的元素,能保证add()时百分百不出错,所以禁止存入。
- 由于指向的List不确定,并且这些List没有共同的父类(除了Object),所以只能用Object接收。
通配符的使用场景
泛型本身比较复杂,能把简单的T用熟练的已经不多,更别说用上通配符了。但从语法本身来说,通配符就是为了让赋值更具通用性。原先泛型赋值只能是同类型之间赋值,不利于抽取通用方法。而使用通配符后,就可以在一定程度上开放赋值限制。

?是开放限度最大的,可指向任意类型List,但在对List的方法调用上也是限制最大的,具体表现在:
- 入参和泛型相关的都不能使用(禁止存入)
- 返回值和泛型相关的都只能用Object接收(只能强转为Object)
extends和super指向性各砍了一半,分别指向子类型List和父类型List,但方法使用上又相对开放了一部分:
- extends不允许存入,但取出时类型稍微精确些,可以往边界类型转
- super允许存入子类型元素,但取出时只能转为Object
所以如果要用到通配符,需要结合业务考虑,如果你只是希望造一个方法,接收任意类型的List,且方法内不调用List的特定方法,那就用?。而对于extends和super的取舍,《Effective Java》提出了所谓的:PECS(Producer Extends Consumer Super)
- 频繁往外读取内容的(向外提供内容,所以是Producer),适合用
<? extends T>:extends返回值稍微精确些,对调用者友好 - 经常往里插入的(消耗数据,所以是Consumer),适合用
<? super T>:super允许存入子类型元素
给大家举一个JDK对通配符的使用案例:
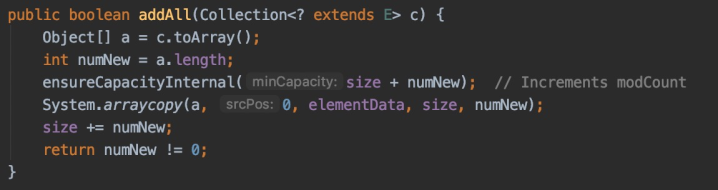
ArrayList中定义了一个addAll(Collection<? extends E> c)方法,我单独把这个方法拿出来:
class ArrayList<E> extends ... {
...
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
}
以Person为例,假设是List<Person> list = new ArrayList<>(),那么这个方法就变成了:
public boolean addAll(Collection<? extends Person> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
此时,addAll()只能接收Person集合或者它的Person子类的集合,比如Student extends Person:
List<Person> personList = new ArrayList<>();
List<Student> studentList = new ArrayList();
personList.addAll(studentList)
为什么会选择extends呢?还是PECS原则,因为allAll()很显然是消费者场景,我更关心对参数的具体操作,而不怎么关心返回值(就是boolean提示操作成功与否)。这也是我日常使用通配符时的一个思路,PECS确实很实用。
消费者场景下,就需要参数c去生产数据,c生产的数据都是E类型的,就可以供addAll消费
最后,很多人会以为 ? 等同于T,其实两者是有区别的。我们本质还是通过给T“赋值”来确定类型,只不过此时赋值给T的不再是某个具体的类型,而是某个“匹配规则”,帮助编译器确定向上、向下可以指向的List类型范围以及存取的元素类型限定。
总结
当你使用简单泛型时,首要考虑你想把元素规定为何种类型,顺便考虑子类型的存入是否会有影响(一般不会)。而如果要使用通配符,应该先考虑接收的范围,再考虑存取操作如何取舍(PECS原则)。
个人愚见是,通配符的出发点本来是为了解决指向问题,但开放指向后为了避免ClassCastException,不得已又对存取加了限制,实际开发时要灵活利用边界限制并结合实际需求选择合适的泛型。
泛型类
我们来回顾一下泛型类是怎么出现的。
话说JDK1.5以前,还没引入泛型时ArrayList大概是这样的:
public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {...}
public void remove(int index) {...}
public Object get(int index) {...}
}
它有这个最大的问题是:无法限制传入的元素类型、取出时又容易发生ClassCastException。最直观的做法是使用期望类型的元素数组,比如:
public class StringArrayList {
// 因为这种ArrayList只存String,所以不需要用Object[]兼容所有类型,只要String[]即可
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
但不可能为所有类型都编写专门的XxxArrayList,于是JDK就推出了泛型:抽取一种类模板,方法、变量都写好了,但变量的类型抽取成“形式类型参数”:
再配合编译器做约束:比如ArrayList<User>表示告诉编译器,帮我盯着点,我只存取User类型的元素。
简而言之,泛型类的出现就是为了“通用”,而且还能在编译期约束元素的类型。
泛型类的方法并不是泛型方法
以前使用Hibernate时,基本都会抽取BaseDao:
class BaseDao<T> {
public T get(T t) {
}
public boolean save(T t) {
}
}
方法里的T和类上的T是同一个,也正因为多个方法操作的POJO类型一致,所以才会被抽取到类上统一声明。
这个T具体是什么类型,或者说里面的get()、save()到底操作什么类型的POJO,取决于BaseDao到底被谁继承。比如:
class UserDao extends BaseDao<User> {
}
那么UserDao从BaseDao继承过来的get()、save()其实已经被约束为“只能操作User类型的元素”。

但要清楚,上面的get()、save()只是“泛型类的方法”,而不是所谓的“泛型方法”。
泛型方法
泛型类上的<T>其实是一种“声明”,如果把类型参数T也看做一种特殊的变量,那么<T>就是变量声明(不是我们一般概念中的变量声明,一个作用于运行期,一个作用于编译期)。
由于泛型类上已经声明了T,所以类中的字段、方法都可以自由使用T。但是当T被“赋值”为某种类型后,就会在编译器的帮助下形成一种强制类型约束,此时这个通用的代码模板也就不再通用了。因而你会发现,对于编译器而言UserDao extends BaseDao<User>里的方法只能操作User,CarDao extends BaseDao<Car>里的方法只能操作Car。
这好吗?一般来说,这很好,因为一个Dao操作的肯定是同一张表同一个对象,限定为某个类型反而能避免出错。但大家想想,如果不是BaseDao,而是一个工具类呢?BaseUtils提供通用的操作,
XxUtils extends BaseUtils<Xx>固然没问题,但如果XxUtils希望提供一个方法处理Yy怎么办?如果还想处理Zz呢?
比如希望提供一个工具方法,接收一个List类型参数,将List反转后输出。
问题的症结并不在于后期想要处理什么类型或者有多少种类型,而是T被过早确定了,从而早早地放弃了“可变性”。
因为对于泛型类的T来说,当UserDao继承BaseDao或者XxUtils继承BaseUtils时,T就被确定为User和Xx了,且已经拒绝了其他可能性,也就无法复用于其他类型。
那么,有没有办法延迟T的确定呢?
有,但泛型类的T已经没办法了,需要另辟蹊径,引入泛型方法。
和泛型类一样,泛型方法使用类型参数前也需要“声明”(<T>要放在返回值的前面):
public class DemoForGenericMethod {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("1", "2", "3", "4", "5"));
List<String> stringList = reverseList(list);
}
/**
* 一个普通类,也可以定义泛型方法(比如静态泛型方法)
* @param list
* @param <T>
* @return
*/
public static <T> List<T> reverseList(List<T> list) {
List<T> newList = new ArrayList<>();
for (int i = list.size() - 1; i >= 0; i--) {
newList.add(list.get(i));
}
return newList;
}
}
如果不使用泛型,得到的数组get元素都是Object,如果指定了固定的泛型类型,就只能对一种类型进行操作,所以要定义为T
泛型方法中T的确定时机是使用方法时。而泛型类的确定是使用泛型类创建对象时。
泛型方法和泛型类没有必然联系,你可以理解为这两个东西可以各自使用,也可以硬把它们凑在一块,不冲突:
class BaseDao<T> {
// 泛型类的方法
public T get(T t) {
}
/**
* 泛型方法,无返回值,所以是void。<E>出现在返回值前,表示声明E变量
* @param e
* @param <E>
*/
public <E> void methodWithoutReturn(E e) {
}
/**
* 泛型方法,有返回值。入参和返回值都是V。注意,即使这个方法也用E,也和上面的E不是同一个
* @param v
* @param <V>
* @return
*/
public <V> V methodWithReturn(V v) {
return v;
}
}
泛型类和泛型方法的使用场景
简单来说,一个类拥有多种同类型方法时使用泛型类,一个方法处理多种类型时使用泛型方法。
比如,在做数据访问层的时候,对一种类型的实体有一系列统一的访问方法,此时采用泛型类会比较合适,而对于
接口的统一结果封装则采用泛型方法比较合适,比如:
@Data
@NoArgsConstructor
public class Result<T> implements Serializable {
private Integer code;
private String message;
private T data;
private Result(Integer code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
private Result(Integer code, String message) {
this.code = code;
this.message = message;
this.data = null;
}
/**
* 带数据成功返回
* 请注意,虽然泛型方法也用了T,但和Result<T>里的没关系
* 这里之所以这么写,是因为实际开发时你们会见到很多这种“迷惑性”的写法,放出来作为“反例”,推荐最好使用其他符号,比如K
*
* @param data
* @param <T>
* @return
*/
public static <T> Result<T> success(T data) {
return new Result<>(ExceptionCodeEnum.SUCCESS.getCode(), ExceptionCodeEnum.SUCCESS.getDesc(), data);
}
}
又比如封装工具类,也非常常用:
public class ConvertUtil {
private ConvertUtil() {
}
/**
* 将List转为Map
*
* @param list 原数据
* @param keyExtractor Key的抽取规则
* @param <K> Key
* @param <V> Value
* @return
*/
public static <K, V> Map<K, V> listToMap(List<V> list, Function<V, K> keyExtractor) {
if (list == null || list.isEmpty()) {
return new HashMap<>();
}
Map<K, V> map = new HashMap<>(list.size());
for (V element : list) {
K key = keyExtractor.apply(element);
if (key == null) {
continue;
}
map.put(key, element);
}
return map;
}
}
静态方法无法使用泛型类的类型参数,换言之,静态方法如果想要使用泛型,只能是静态泛型方法,此时类型参数是自己声明的。
泛型与类的实例相关联,静态方法与类的实例无关。
Redis分布式锁
public interface RedisService {
// 省略其他方法...
/**
* 从队列取出消息
*
* @param queue 自定义队列名称
* @param timeout 最长阻塞等待时间
* @param timeUnit 时间单位
* @return
*/
Object popQueue(String queue, long timeout, TimeUnit timeUnit);
// 省略其他方法...
}

但如果使用泛型方法:
public interface RedisService {
// 省略其他方法...
/**
* 从队列取出消息
*
* @param queue 自定义队列名称
* @param timeout 最长阻塞等待时间
* @param timeUnit 时间单位
* @return
*/
<T> T popQueue(String queue, long timeout, TimeUnit timeUnit);
// 省略其他方法...
}

就不用强制转换了。
但这并不保险,只是骗过了编译器而已。你会发现你用任意类型接收都是不会编译报错的:

泛型数组
Java并不支持泛型数组,所以对于ArrayList,底层仍旧采用Object[]。但在日常开发中又确实可能遇到需要new T[]的场景。
public class Test {
public static void main(String[] args) {
Integer[] array = new Integer[]{2, 4, 5, 9, 7, 1, 1, 6};
Integer[] copyArray = copy(array);
}
private static <E> E[] copy(E[] array) {
// 创建同类型数组
E[] arrayTemp = ...
for (int i = 0; i < array.length; i++) {
arrayTemp[i] = array[i];
}
return arrayTemp;
}
}
和new T()一样,new T[]也是不合法的。
要想new T(),要么方法传入Class<T>,要么通过GenericType获取,最终要通过反射创建T对象(总之要明确Class对象)。那么对于T[],如何获取数组的元素类型呢?
JDK另外提供了所谓的ComponentType指代数组的元素类型:
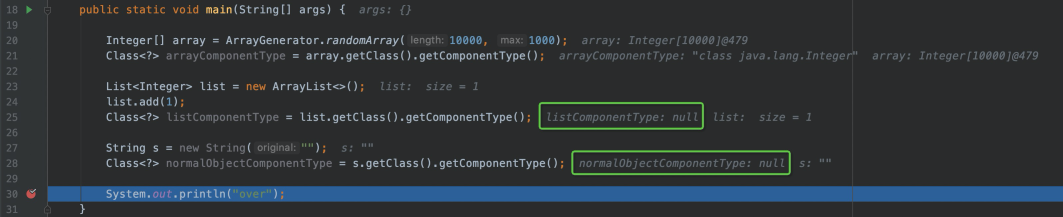
泛型机制对普通对象、容器对象都很好,唯独对数组苛刻了些,以至于我们回想泛型,基本都想不起数组和泛型有啥关系。这不,为了弥补对数组的亏欠,Java特别给数组搞了ComponentType,其他两个可没有哦。
好了,既然知道了数组元素的类型,那就可以创建对应类型的数组咯:
public class Test {
public static void main(String[] args) {
Integer[] array = new Integer[]{2, 4, 5, 9, 7, 1, 1, 6};
Integer[] copyArray = copy(array);
}
private static <E> E[] copy(E[] array) {
Class<?> componentType = array.getClass().getComponentType();
// 创建同类型数组
E[] arrayTemp = (E[]) Array.newInstance(componentType, array.length);
for (int i = 0; i < array.length; i++) {
arrayTemp[i] = array[i];
}
return arrayTemp;
}
}
newInstance方法:

其中的newArray是native修饰的
当然,实际开发中要想拷贝数组,有很多其他简单的方式,对于带有泛型参数 [[003-数组、排序、查找#Arrays.copyOf(int[] original,int newLength)|Arrays.copyOfRange]] 的方法来说,JDK的实现如下:

可以看到也是通过Array.newInstance()创建数组对象的。
泛型的应用
Lists是Google提供的工具类,返回一个List集合:
public final class Lists {
private Lists() {
}
@GwtCompatible(
serializable = true
)
public static <E> ArrayList<E> newArrayList() {
return new ArrayList();
}
}
此处定义了返回值的泛型,我们可以使用任意泛型进行接收
实际上,我们自定义一个方法:
ArrayList newArrayList(){
return new ArrayList();
}
即便没有声明泛型,我们也可以使用任意泛型进行接收:
List<String> arrayList = newArrayList();
也就是:
public void doSome() {
//并不会报错
List<String> arrayList = newArrayList();
}
public ArrayList newArrayList() {
return new ArrayList();
}
Lambda表达式
Lambda表达式是JDK1.8的一个新特性,可以取代大部分的匿名内部类操作,以便写出更优雅的代码,尤其是在集合的操作中,可以极大优化代码结构。
在之前的学习中,如果想对List集合进行降序排列,就需要使用匿名内部类来实现,代码比较繁琐:
// 方式一:使用匿名内部类来实现
List<Integer> list = Arrays.asList(3, 6, 1, 7, 2, 5, 4);
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println("排序后:" + list);
针对以上对List集合的的“降序”排序操作,除了使用匿名内部类来实现外,还可以使用Lambda表达式来实现,使用Lambda表达式的代码非常优雅,并且还非常的简洁,代码如下:
// 方式二:使用Lambda表达式来实现
List<Integer> list = Arrays.asList(3, 6, 1, 7, 2, 5, 4);
Collections.sort(list, (o1, o2) -> o2 - o1);
System.out.println("排序后:" + list);
引例
// Math.abs()是JavaScript的内置函数
let result = Math.abs(-10)
console.log('result=' + result)
// JavaScript允许将Function赋值给变量。注意,不能带(),否则就是方法调用
let func = Math.abs
// 更神奇的是,func变量拼上()就可以当方法调用了
console.log('result=' + func(-20))
// 其实,在JavaScript中不仅允许方法赋值,还允许直接传递Function
function sum(x, y, func) {
return func(x) + func(y)
}
result = sum(-10, -20, Math.abs)
console.log('result=' + result)
结果:
result=10
result=20
result=30
sandbox> exited with status 0
这种写法对于Java程序员来说第一感觉是“神奇”,紧接着能感受到JS的“轻巧”。
其实不仅是JS,Python也是如此:
# encoding: utf-8
# abs是Python的内置函数
result = abs(-1)
print(result)
# 定义add()方法,f显然是一个函数
def add(x, y, f):
return f(x) + f(y)
print(add(-1, -2, abs))
运行结果:
1
3
sandbox> exited with status 0
Python把上面的表达式称为高阶函数:
- 函数的参数可以是一个/多个函数
- 函数的返回值也可以是一个函数
在JS、Python等脚本语言的世界里,这种现象似乎很普遍,因为Function是那个世界的一等公民,而对于Java来说对象才是一等公民。比如,有时为了在A对象的方法中调用B对象的某个方法,我们不得不new一个B对象并把它作为参数传入:
class A {
public void methodA(B b) {
System.out.println("methodA is called");
b.methodB();
}
}
class B {
public void methodB() {
System.out.println("methodB is called");
}
}
在设计模式中,上面这种写法美其名曰:策略模式。
当然,广义上策略模式关注的是可替换的多种实现,狭义上可以理解为传递不同的方法。
幸运的是Oracle紧跟潮流,终于在2014年发布Java8并宣布支持Lambda表达式,弥补了Java函数式编程的遗憾。
出行案例
MyThread(模仿JDK的Thread,最大的区别是最终调用的还是主线程而不是异步线程)
public class MyThread {
public void run() {
System.out.println("去12306买了一张票");
System.out.println("坐火车...");
}
public void start() {
run();
}
}
public class Demo {
public static void main(String[] args) {
// new一个MyThread对象,调用start()
new MyThread().start();
}
}
上面的代码有个问题:要运行的代码在MyThread的run里面写死了,我只能坐火车,不能坐飞机。 分析:
我们知道,Java是面向对象的,一个事物一般可以最终抽象成 属性+方法。
属性代表你有什么,方法代表你能干什么。
在这个案例中,“坐火车”、“坐飞机”都是一个动作。按上面分析,应该是一个方法。我们要动态地传入一个动作,也就是要动态地传入一个方法。但是我们知道,在Java中只能传递数据(参数),不能传递方法。JS之所以可以传递function,是因为function本身是JS的一种数据类型。
抽取一下上面的观点:
Java只能传递规定的数据类型的数据,比如int型的age, String型的name, 引用类型的person。
对象包含属性和方法,而Java又可以传递person这样的引用类型。那么就完全可以传递一个对象(包含需要的方法),在内部调用对象的方法,这和直接传递方法是异曲同工的。
所以,我打算把“坐火车”、“坐飞机”这些交通策略单独抽取成一个个类,在new MyThread()的时候通过构造函数传递这些类的实例进去。
但同时可以预见,“坐火车”、“坐飞机”等等对象会非常多,MyThread的有参构造的形参类型需要形成多态。于是我写了一个MyRunnable接口,让每个策略类都去实现它(接口多态)。
public interface MyRunnable {
void run();
}
public class ByTrain implements MyRunnable {
@Override
public void run() {
System.out.println("去12306买了一张票");
System.out.println("坐火车...");
}
}
public class ByAir implements MyRunnable {
@Override
public void run() {
System.out.println("在某App上订了飞机票");
System.out.println("坐飞机...");
}
}
public class ByAir implements MyRunnable {
@Override
public void run() {
System.out.println("在某App上订了飞机票");
System.out.println("坐飞机...");
}
}
改写MyThread,接收不同的出行策略并调用方法:
public class MyThread {
// 成员变量
private MyRunnable target;
public MyThread() {}
// 构造方法,接收外部传递的出行策略
public MyThread(MyRunnable target) {
this.target = target;
}
// MyThread自己的run(),现在基本不用了
public void run() {
System.out.println("去12306买了一张票");
System.out.println("坐火车...");
}
// 如果外部传递了出行策略,就会调用该策略里的run()
public void start() {
if (target != null) {
target.run();
} else {
this.run();
}
}
}
Demo:
public class Demo {
public static void main(String[] args) {
ByTrain byTrain = new ByTrain();
new MyThread(byTrain).start();
ByAir byAir = new ByAir();
new MyThread(byAir).start();
}
}
尽管使用了策略模式,上面的代码还是有问题。如果后面还有“坐电瓶车”、“骑自行车”等出行方式,那么出行策略类就太多了,会发生所谓的“类爆炸”。我们可以使用匿名类的方式继续改进Demo:
public class Demo {
public static void main(String[] args) {
new MyThread(new MyRunnable() {
@Override
public void run() {
System.out.println("不用买票");
System.out.println("骑电瓶车...");
}
}).start();
}
}
到此为止这大概是JDK8之前我们能想到的最好的解决办法,不仅运用了策略模式,还使用匿名类的方式成功阻止了类的暴增。
但是,程序永远存在可优化的地方。于是,JDK8又帮我们向前迈进了一大步:
public class Demo {
public static void main(String[] args) {
new MyThread(() -> {
System.out.println("不用买票");
System.out.println("骑电瓶车...");
}).start();
}
}
非常简洁。
Java从诞生那天起,就是纯正的面向对象语言。而从1995年诞生至今,已经过去28年。期间程序届又诞生了很多优秀的语言。
长江后浪推前浪,一般来说后续的新语言在创建之初一定会吸取之前语言的教训,尽量规避之前的设计缺陷。所以,单从语言层面上讲,老的语言往往是没有优势的,甚至存在代码冗余,不够优雅等弊病。
Lambda表达式可以看做函数式编程的子集,但函数式编程绝对不是Java首创的,它只是看到别的语言用的挺好,自己也引入了而已。
Lambda表达式的本质
Lambda表达式,其实是一段可传递的代码。
更精确的描述是:Lambda表达式,其实是一段可传递的代码。它的本质是以类的身份,干方法的活。
public class Demo {
public static void main(String[] args) {
new MyThread(() -> System.out.println("哈哈哈")).start();
}
}
分析上面的代码,会发现new MyThread()这个构造方法原本需要传递一个MyRunnable接口的子类对象(匿名类对象)。 但我们反手就扔了一个Lambda表达式进去,它还真吃下去了。说明什么?
说明Lambda表达式在身份上与匿名类对象等价。
但是Lambda表达式这么一串代码扔进去后,实际干活的也就->后的System.out.println("哈哈哈")这段代码(可以看做一个方法,因为方法是对代码块的封装)。这又说明了什么?
说明Lambda表达式在作用上与方法等价。
再次回味上面的那句话:Lambda表达式,其实是一段可传递的代码。Lambda本质是以类的身份,干方法的活。
如果我们把方法看做行为,那么Lambda表达式其实就是把行为参数化(方法作为参数传递)。
Lambda表达式格式解析
public class Demo {
public static void main(String[] args) {
String str1 = "abc";
String str2 = "abcd";
int i = compareString(str1, str2, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
});
}
public static int compareString(String str1, String str2, Comparator<String> comparator) {
return comparator.compare(str1, str2);
}
}
以上的代码可以使用Lambda表达式优化:
由上文推导出Lambda表达式和匿名类对象等价,我们可以把Lambda表达式赋值给Comparator接口

可以看到,这段代码还有优化的空间;跳过赋值这一步,直接把整个Lambda传给compareString()方法:

还可以进行优化:

最终版本:

方法引用可以单纯地理解为可复用的Lambda(把其他类已经定义的方法作为Lambda),实际开发时依靠IDEA提示改进即可,并不需要我们记忆。

类名、方法名、形参类型、返回值类型、return关键字及方法体的{}都被省略了。
从语法格式来讲,Lambda表达式其实就是对一个方法掐头去尾,只保留形参列表和方法体。可以粗略认为:
Lambda表达式 = 形参列表 + 方法体
对于匿名内部类而言,类名、方法名真的没什么用。只有当一个方法需要被使用多次时,我们才需要为它命名,以便其他程序通过方法名重复调用。而匿名内部类的性质就是仅调用一次,所以名字对它来说是可有可无的。至于返回值与形参类型,Lambda都可以通过上下文推断,所以也可以省略:
// 基于上下文,很容易推算出返回值类型就是String。形参同理。
public someType get() {
return "Hello World!";
}
至于方法体的{}能不能省略,本质和if是否需要{}一样:
if(true)
System.out.println("可以省略{}");
if(true) {
int i = 1;
System.out.println("不可以省略{}");
}
至于是否需要return,看方法本身是否需要返回值。回顾上面的推演过程,能省略的都省略后就成了现在的Lambda表达式。
那实际使用Lambda表达式需要注意什么呢?
- 关注如何编写Lambda,需要实现什么样的逻辑
- 不要关注当前Lambda将会被如何调用,出现在代码的哪一块
比如:
public static void main(String[] args) {
// 原始数据
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3));
// filter()方法需要传入一个过滤逻辑
List<Integer> result = list.stream().filter(value -> value > 2).collect(Collectors.toList());
System.out.println(result);
}
如果你只是调用者,尽量不要去想filter()方法内部代码是怎么写的,只需考虑如何实现过滤规则:大于2,所以你只要写一个能判断value是否大于2的Lambda并传入即可(value->value>2 就是 入参->方法体)。
函数式编程思想
Java从诞生之日起就一直倡导“一切皆对象”,在Java语言中面向对象(OOP)编程就是一切,但是随着Pathon和Scala等语言的崛起和新技术的挑战,Java也不得不做出调整以便支持更加广泛的技术要求,即Java语言不但支持OOP还支持OOF(面向函数编程)。
JDK1.8引入Lambda表达式之后,Java语言也开始支持函数式编程,但是Lambda表达式不是Java语言最早使用的,目前C++、C#、Python、Scala等语言都支持Lambda表示。
- 面向对象的思想
- 做一件事情,找一个能解决这个事情的对象,然后调用对象的方法,最终完成事情。
- 函数式编程思想
- 只要能获得结果,谁去做的,怎么做的都不重要,重视的是结果,不重视实现过程。
在函数式编程语言中,函数被当成一等公民对待。在将函数当成一等公民的编程语言中,Lambda表达式的类型是函数,但是Lambda表达式却是一个对象,而不是函数,它们必须依附于一类特别的对象类型,也就是所谓的函数式接口。
简单点说,JDK1.8中的Lambda表达式就是一个函数式接口的实例,这就是Lambda表达式和函数式接口的关系。也就是说,只要一个对象是函数式接口的实例,那么该对象就可以使用Lambda表示来表示。
如何去理解函数式接口
能够使用Lambda表达式的一个重要依据是必须有相应的函数式接口,所谓的函数式接口,指的就是“一个接口中有且只能有一个抽象方法”。也就是说,如果一个接口只有一个抽象方法,那么该接口就是一个函数式接口。
如果我们在接口上声明了 @FunctionalInterface 注解,那么编译器就会按照函数式接口的定义来要求该接口,也就是该接口中有且只能定义一个抽象方法,如果该接口中定义了多个或0个抽象方法,则程序编译时就会报错。
【示例】定义一个函数式接口
@FunctionalInterface
public interface Flyable {
// 在函数式接口中,我们有且只能定义一个抽象方法
void showFly();
// 但是,可以定义任意多个默认方法或静态方法
default void show() {
System.out.println("JDK1.8之后,接口还可以定义默认方法和静态方法");
}
}
另外,从某种意义上来说,只要你保证你的接口中有且只有一个抽象方法,则接口中没有使用 @FunctionalInterface 注解来标注,那么该接口也依旧属于函数式接口。
在以下代码中,Flyable接口中没有使用@FunctionalInterface 注解,但是Flyable接口中只存在一个抽象方法,因此Flyable接口依旧属于函数式接口,那么使用Lambda表达式就可以表示Flyable 接口的实例,代码如下:
/**
* 没有使用@FunctionalInterface标注的接口
*/
public interface Flyable {
void showFly();
}
/**
* 测试类
*/
public class Test01 {
public static void main(String[] args) {
// 使用lambda表示来表示Flyable接口的实例
Flyable flyable = () -> {
System.out.println("小鸟自由自在的飞翔");
};
// 调用Flyable接口的实例的showFly()方法
flyable.showFly();
}
}
如果接口中有两个抽象方法:

Lambda表达式不能用了:

只能用匿名类对象,把两个方法都实现:

因为Lambda的本质是传递一个方法体,而MyRunnable此时有两个方法需要实现,那么你这个Lambda表达式到底是给哪个方法的呢?另一个又该怎么办呢?此时只能用匿名类对象,把两个方法都实现。
当然,我们还可以从另一个角度理解:Java8的Lambda都是基于上下文推导的,当一个接口只有一个方法时,推导结果是唯一确定的,但是方法不唯一时,无法推导得到唯一结果。
Lambda和匿名内部类
- 所需类型不同
- 匿名内部类:可以是接口,抽象类,具体类。
- Lambda表达式:只能是接口。
- 使用限制不同
- 如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。
- 如果接口中有多个抽象方法,则就只能使用匿名内部类,而不能使用Lambda表达式。
- 实现原理不同
- 匿名内部类:编译之后,会生成一个单独的.class字节码文件。
- Lambda表达式:编译之后,没有生成一个单独的.class字节码文件。
上面的案例一直在对比匿名内部类和Lambda,大家可能认为Lambda等同于匿名内部类,认为Lambda是匿名内部类的语法糖。但其实并不是。
public class Lambda {
public static void main(String[] args) {
// 在匿名内部类的外面定义一个String变量
final String str = "hello";
// 构造一个匿名内部类对象
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println(str);
System.out.println("this--->" + this);
}
/**
* hello
* this--->lambdatest.Lambda$1@482ad665
* */
};
new Thread(r).start();
}
}
注意,带$表示匿名内部类,比如LambdaTest$1表示LambdaTest中的匿名内部类,编译后会产生两个文件。

但如果把Runnbale换成Lambda表达式实现:
public void test(){ //不能在静态方法中使用this
final String str = "hello";
//lambda表达式
Runnable r = () -> {
System.out.println(str);
System.out.println("this--->" + this);
};
/**
* hello
* this--->lambdatest.Lambda@5e7e0ff3
* */
new Thread(r).start();
}
发现Lambda表达式方法体内部的this指向了LambdaTest,而且编译后也只有一个class文件。
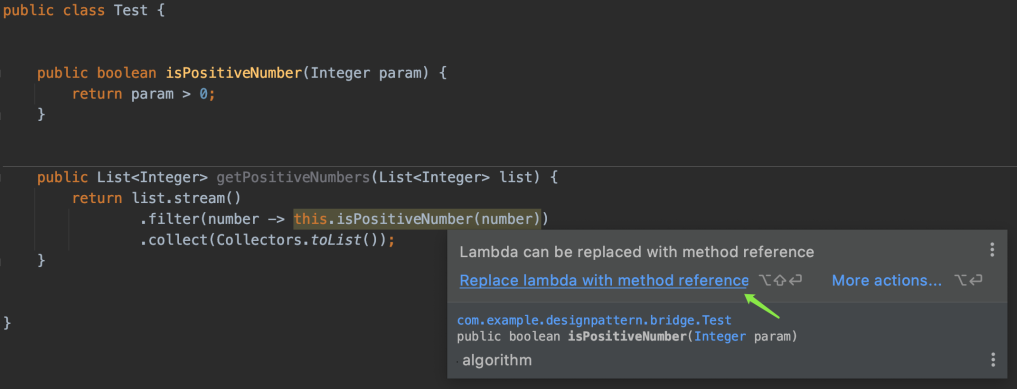
Lambda方法体外部并没有匿名内部类,当然只能指向LambdaTest。更准确地说,this是指向方法的调用者,是隐式传递的。从这个角度看,Lambda和匿名内部类本质上还是不同的。

以后编码时,再遇到这种编译错误就不会迷惑了:

改成Lambda表达式即可,因为Lambda表达式外层就是当前类的实例:

根据IDEA提示,做一下简化:

Lambda表达式的使用
Lambda表达式本质就是一个匿名函数,在函数的语法中包含返回值类型、方法名、形参列表和方法体等,而在Lambda表达式中我们只需要关心形参列表和方法体即可。
在Java语言中,Lambda表达式的语法为“(形参列表) -> {方法体}”,其中“->”为 lambda操作符或箭头操作符,“形参列表”为对应接口实现类中重写方法的形参列表,“方法体”为对应接口实现类中重写方法的方法体。
接下来,我们就以匿名内部类为例,从而将匿名内部类演化为Lambda表达式,代码如下:
List<Integer> list = Arrays.asList(3, 6, 1, 7, 2, 5, 4);
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println("排序后:" + list);
在以上的代码中,第5行是完成功能的核心代码,因此将此处的匿名内部类转换为Lambda表达式,我们只需要保留形式参数列表和方法体即可,对应代码:
List<Integer> list = Arrays.asList(3, 6, 1, 7, 2, 5, 4);
Collections.sort(list, (Integer o1, Integer o2) -> {
return o2 - o1;
});
System.out.println("排序后:" + list);
因此Lambda本质上就是去掉了一堆没有意义的代码,只留下核心的代码逻辑,从而让代码看起来更加的简洁且优雅。
Lambda表达式简化
- 形参类型可以省略,如果需要省略,则每个形参的类型都要省略。
- 如果形参列表中只存在一个形参,那么形参类型和小括号都可以省略。
- 如果方法体当中只有一行语句,那么方法体的大括号也可以省略。
- 如果方法体中只有一条return语句,那么大括号可以省略,且必须去掉return关键字。
闭包
在前文中的示例中:

我们可以看到,如果将str的final去掉并重新赋值,报错:lambda表达式中的变量应该是final的
这要从闭包现象开始解释,闭包 由英文 closure 翻译而来。
闭包 = 环境 + 控制
闭包分为:
- 闭包现象:两个函数嵌套,里层函数使用到外层函数的变量,就出现了闭包现象。
- 闭包函数:内层函数就是闭包函数
def f():
a = 5
def g():
print(a) # g函数就是闭包函数
return g
《js高级程序设计》里面说:闭包是函数,是一个可以访问其他函数作用域中变量的函数。
f函数并不能访问g函数里面的变量,只有内部函数可以访问外部函数的变量。类似于内部类可以直接访问外部类,而外部类并不能直接访问内部类的变量。
上文的示例:

return之后:

return的不仅仅是g函数,还带有外面的一层环境信息
def f():
a = 5
def visit():
print(a) # visit函数就是闭包函数
def add():
nolocal a
a += 1
return visit,add
g1 = f() # 拿到闭包
g1() # 5
如果调用多次:
def f():
a = 5
def visit():
print(a) # visit函数就是闭包函数
def add():
nolocal a
a += 1
return visit,add
add, v = f()
add()
v() # 2
add()
v() # 3
add()
v() # 4
v函数和add函数的环境共享了,对变量a的操作只能通过这两个函数来完成,这就是一种小的封装
改写g函数:
def f():
a = 5
def g():
nolocal a
a += 1
print(a)
return g
g1 = f()
g2 = f()
g1() # 2
g1() # 3
g1() # 4
g2() # 2
g2() # 3
g2() # 4
以上两个闭包中,a的值并不是同一个,类似于:

每次return都是将环境拷贝一份放出去了,这两个a是独立的a
如果外层环境中有多个变量,内层函数只使用了1个变量,闭包的环境也只有一个变量
如果是引用类型的变量,两个闭包指向的内存地址也是不同的,会对数组进行深拷贝。
Java中的闭包
但是在Java里我们看不到这样的结构,因为Java语法不允许直接的函数嵌套和跨域访问变量。
但是Java到处都是闭包,反而让我们感觉不到在使用闭包。因为Java的对象实际上就是一种闭包的结构。无论是闭包还是对象都是封装数据的一种手段。
class Add{
private int x = 2;
public int add(){
int y = 3;
return x + y;
}
}
看上去x在add作用域之外,但是通过Add类实例化的过程,变量x和数值2之间已经绑定了,而且和方法add都打包在了一起。add函数其实是通过this关键字来访问对象的成员字段的。
Java中内部类就是一个经典的闭包结构:
public class Outer{
private int x = 100;
private class Inner{
private y = 100;
public int innerAdd(){
return x + y;
}
}
}
下图就是上文代码的结构。内部类通过包含一个指向外部类的引用,做到自由访问外部环境类的所有字段,变相把环境中的自由变量封装到函数中,形成一个闭包。
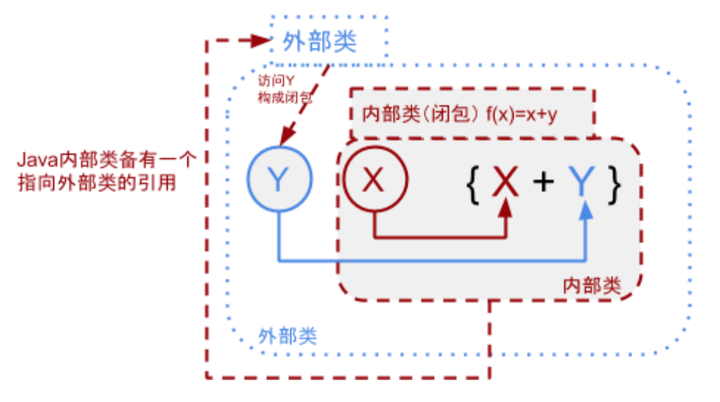
但Java匿名内部类做的比较尴尬。下面的例子中,getAnnoInner负责返回一个匿名内部类的引用。
interface AnnoInner{
int addXYZ();
}
public class Outer {
public AnnoInner getAnnoInner(final int x){
final int y = 100;
return new AnnoInner() {
int z = 100;
@Override
public int addXYZ() {
return x + y + z;
}
};
}
}
匿名内部类不能显式地声明构造函数,也不能向构造函数中传参数。不但返回的只是个AnnoInner接口,而且还没有和它外围环境getAnnoInner方法的局部变量x和y构成任何类的结构。但它的addXYZ方法却直接使用了x和y两个自由变量计算结果。这就说明,外部方法getAnnoInner事实上已经对内部类AnnoInner构成了一个闭包。
但是这里x和y都必须用final修饰,不可以修改。如果用一个changeY方法试图修改外部getAnnoInner里的成员变量y,编译不通过:不能对final变量y重新赋值。
原因在于,Java编译器支持了闭包,但支持的不完整。说支持了闭包,是因为编译器编译的时候对方法进行了修改,将外部环境方法的x和y,拷贝了一份到匿名内部类当中,代码如下图所示:
public class Outer {
public AnnoInner getAnnoInner(final int x){
final int y = 100;
return new AnnoInner() {
int copyX = x; //拷贝副本
int copyY = y; //拷贝副本
int z = 100;
@Override
public int addXYZ() {
return x + y + z;
}
};
}
}
Java编译器实现的是capture by value,并没有实现capture by reference。
- capture by value:值捕获,在需要创建闭包的地方把捕获的值拷贝一份到对象里即可。Java的匿名内部类和lambda表达式都是这样实现的。
- capture by reference:引用捕获,把捕获的局部变量hoist提升到对象里。C#的匿名函数(匿名委托/lambda表达式)就是这样实现的
而只有后者才能保持匿名内部类和外部环境变量保持同步。
但Java没有明确指出,既然内外不能同步,直接不允许修改外部环境的局部变量了。
几种不太常用的内部类形式,都有这个特性:方法的局部内部类等。
如果变量是不可变的,那么使用者无法感知值捕获和引用捕获的区别。
其他语言的捕获方式:
- C++ 11 允许显式指定捕获列表以及捕获方式,这样最清晰。
- JS只有引用捕获,要模拟值捕获的效果需要手动创建闭包和局部变量。
- C#对不可变量做值捕获,对普通局部变量做引用捕获;由于无法感知对不可变量做值捕获或引用捕获的区别,统一把这个行为描述为引用捕获更方便一点。
- Java虽然只实现了值捕获,但是又当又立不承认自己只做了值捕获,只允许捕获事实上不变量
- python的lambda实现的是引用捕获,但在lambda内不能对捕获的变量赋值,只能在原本定义那些变量的作用域中对其赋值。
但是Java只不允许改变被lambda表达式捕获的变量,并没有限制这些变量指向的对象状态是否能改变,要从lambda表达式向外传值的常见workaround之一就是用长度为1的数组。JDK内部有些代码就使用的这种方法。
其他关于匿名内部类定义final的回答:
1)从程序设计语言的理论上:局部内部类(即:定义在方法中的内部类),由于本身就是在方法内部(可出现在形式参数定义处或者方法体处),因而访问方法中的局部变量(形式参数或局部变量)是天经地义的.是很自然的
2)为什么JAVA中要加上一条限制:只能访问final型的局部变量?
3)JAVA语言的编译程序的设计者当然全实现:局部内部类能访问方法中的所有的局部变量(因为:从理论上这是很自然的要求),但是:编译技术是无法实现的或代价极高.
4)困难在何处?到底难在哪儿?
局部变量的生命周期与局部内部类的对象的生命周期的不一致性!
5)设方法f被调用,从而在它的调用栈中生成了变量i,此时产生了一个局部内部类对象inner_object,它访问了该局部变量i .当方法f()运行结束后,局部变量i就已死亡了,不存在了.但局部内部类对象inner_object还可能一直存在(只能没有人再引用该对象时,它才会死亡),它不会随着方法f()运行结束死亡。这时,出现了一个"荒唐"结果:局部内部类对象inner_object要访问一个已不存在的局部变量i!
6)如何才能实现?当变量是final时,通过将final局部变量"复制"一份,复制品直接作为局部内部中的数据成员.这样:当局部内部类访问局部变量时,其实真正访问的是这个局部变量的"复制品"(即:这个复制品就代表了那个局部变量).因此:当运行栈中的真正的局部变量死亡时,局部内部类对象仍可以访问局部变量(其实访问的是"复制品"),给人的感觉:好像是局部变量的"生命期"延长了.
那么:核心的问题是:怎么才能使得:访问"复制品"与访问真正的原始的局部变量,其语义效果是一样的呢?
当变量是final时,若是基本数据类型,由于其值不变,因而:其复制品与原始的量是一样.语义效果相同.(若:不是final,就无法保证:复制品与原始变量保持一致了,因为:在方法中改的是原始变量,而局部内部类中改的是复制品)
当变量是final时,若是引用类型,由于其引用值不变(即:永远指向同一个对象),因而:其复制品与原始的引用变量一样,永远指向同一个对象(由于是final,从而保证:只能指向这个对象,再不能指向其它对象),达到:局部内部类中访问的复制品与方法代码中访问的原始对象,永远都是同一个即:语义效果是一样的.否则:当方法中改原始变量,而局部内部类中改复制品时,就无法保证:复制品与原始变量保持一致了(因此:它们原本就应该是同一个变量.)
字节码层面测试
public interface MyInterface {
void doSomething();
}
public class TryUsingAnonymousClass {
public void useMyInterface() {
final Integer number = 123;
System.out.println(number);
MyInterface myInterface = new MyInterface() {
@Override
public void doSomething() {
System.out.println(number);
}
};
myInterface.doSomething();
System.out.println(number);
}
}
反编译匿名内部类:
class TryUsingAnonymousClass$1
implements MyInterface {
private final TryUsingAnonymousClass this$0;
private final Integer paramInteger;
TryUsingAnonymousClass$1(TryUsingAnonymousClass this$0, Integer paramInteger) {
this.this$0 = this$0;
this.paramInteger = paramInteger;
}
public void doSomething() {
System.out.println(this.paramInteger);
}
}
可以看到名为number的局部变量是作为构造方法的参数传入匿名内部类的(以上代码经过了手动修改,真实的反编译结果中有一些不可读的命名)。
如果Java允许匿名内部类访问非final的局部变量的话,那我们就可以在TryUsingAnonymousClass$1中修改paramInteger,但是这不会对number的值有影响,因为它们是不同的reference。这就会造成数据不同步的问题。
而Scala中的代码会编译为这样:
public final class TryUsingAnonymousClassInScala$$anonfun$1 extends AbstractFunction0.mcV.sp
implements Serializable {
public static final long serialVersionUID = 0L;
private final IntRef number$2;
public final void apply() {
apply$mcV$sp();
}
public void apply$mcV$sp() {
this.number$2.elem = 456;
Predef..MODULE$.println(BoxesRunTime.boxToInteger(this.number$2.elem));
}
public TryUsingAnonymousClassInScala$$anonfun$1(TryUsingAnonymousClassInScala $outer, IntRef number$2) {
this.number$2 = number$2;
}
}
可以看到number也是通过构造方法的参数传入的,但是与Java的不同是这里的number不是直接传入的,是被IntRef包装了一层然后才传入的。对number的值修改也是通过包装类进行的:this.number$2.elem = 456;
这样就保证了lambda表达式内外访问到的是同一个对象。
四个基本的函数式接口
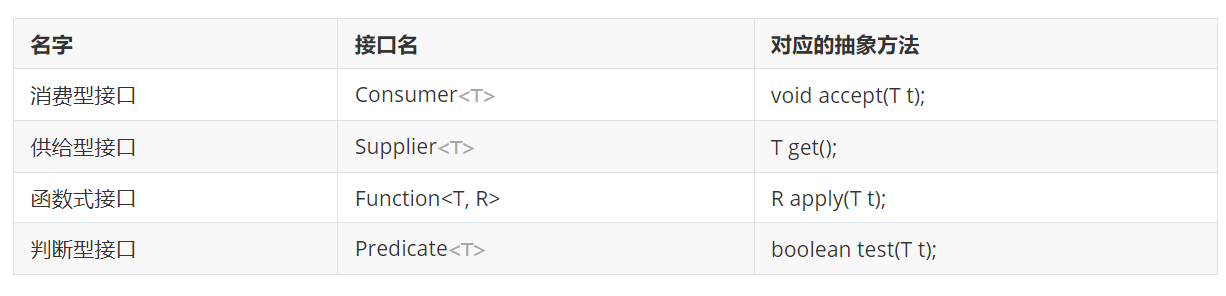
以上的函数式接口都在java.util.function包中,通常函数接口出现的地方都可以使用Lambda表达式,所以不必记忆函数接口的名字
接口多态与方法多态
多态,原本指的是接口下有多个子类实例可以指向接口引用,但由于函数式接口恰好仅有一个方法,此时接口多态等同于“方法多态”,即一个抽象方法拥有多个不同的具体实现。
接口多态
多态的精髓在于晚绑定:
PocketMon pocketMon = new Pikaqiu();
pocketMon.releaseSkill();
只看pocketMon.releaseSkill()你能猜出来技能是电击还是喷火吗?换一种形式呢?
Properties pro = new Properties();
FileInputStream in = new FileInputStream("pocketmon.properties");
pro.load(in);
PocketMon pocketMon = Class.forName(pro.getProperty("nextPocketMon")).newInstance();
pocketMon.releaseSkill();
完全看不出来了。
即使你打开pocketmon.properties看了是皮卡丘,运行时虚拟机看到的可能是我修改后的喷火龙。
这种现象其实很奇妙:明明代码都写死了,但虚拟机却无法提前确定具体会是哪只神奇宝贝在调用releaseSkill(),除非实际运行到这行代码。而这,正是得益于多态。
多态的原理,本质是还是JVM层面通过运行时查找方法表实现的。可以简单理解为,JVM在运行时需要去循环遍历这个方法对应的多态实现,选择与当前运行时对象匹配的方法进行调用。所以,从理论上来说,晚绑定的多态在性能上是不如早绑定的(直接写死,不用多态)。而多态是设计模式的灵魂,所以对于一些非常、非常、非常要求性能的场景来说,过于繁重的设计反而会降低性能。说白了,这世上就不存在多、快、好、省。
多态是“晚绑定”思想的体现:对于Java而言,方法的调用并不是编译时绑定,而是运行时动态绑定的,取决于引用具体指向的实例。
方法多态
这个概念在函数式接口的前提下是站得住脚的,而且有利于跳出面向对象,贴近函数式编程。
需求:要求写一个cook()方法,传入鸡翅和可乐,做出可乐鸡翅。
很多人可能下意识地就把代码写死了:
public static CokaChickenWing cook(Chicken chicken, Coka coka){
1.放油、放姜;
2.放鸡翅;
3.倒可乐;
4.return CokaChickenWing;
}
但是,网上也有人说应该先倒可乐再放鸡翅,每个人的口味不同,做法也不同。有没有办法把这两步延迟确定呢?让调用者自己来安排到底是先倒可乐还是先放鸡翅。
可以这样:
public static CokaChickenWing cook(Chicken chicken, Coka coka, function twoStep){
1.放油、放姜;
2~3.twoStep();
4.return CokaChickenWing;
}
想法很好:既然这两步不确定,那么就由调用者来决定吧,让调用者自己传进来。
我们知道Java是不能直接传递方法的,但利用策略模式可以解决这个问题。
定义一个接口:
interface TwoStep {
void excute();
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
这里twoStep.excute()是确定的吗?
没有。方法里的参数放在栈帧中的局部变量表里,必须是程序执行到该方法时,方法才入栈,分配相应内存与数据,所以是不能提前确定的。
所以twoStep.excute()充其量只是先替“某些操作占个坑”,后面再确定。
什么时候确定呢?
main(){
TwoStep twoStep = new TwoStep(){
@Override
public void excute(){
2.先放鸡翅
3.再倒可乐
}
}
// 或者
TwoStep twoStep = () -> {2.先放鸡翅;3.再倒可乐}
// 调用cook时确定(运行时)
cook(chicken, coka, twoStep);
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
学习过Lambda表达式就可以换一种写法:
main(){
// 调用cook时确定 方案1
cook(chicken, coka, () -> 2.先放鸡翅,3.再倒可乐);
// 调用cook时确定 方案2
cook(chicken, coka, () -> 2.先倒可乐,3.再放鸡翅);
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
这就是所谓的“方法多态”:通过函数式接口把形参的坑占住,后续传入不同的Lambda实现各自逻辑。
晚绑定和模板方法设计模式
在设计模式中策略模式和模板方法看起来有点像,但其实不一样。策略模式使用接口占坑,然后传入实际对象调用需要的方法,而模板方法模式是用抽象方法占坑,粒度其实小一些。
晚绑定最典型的应用就是模板方法模式:抽象类确定基本的算法骨架,把不确定的、变化的部分做成抽象方法剥离出去,由子类来实现。
还是以发送验证码为例:
/**
* 验证码发送器
*
* @author qiyu
* @date 2020-09-08 19:38
*/
public abstract class AbstractValidateCodeSender {
/**
* 生成并发送验证码
*/
public void sendValidateCode() {
// 1.生成验证码
String code = generateValidateCode();
// 2.把验证码存入Session
// ....
// 3.抽象方法占坑,用于发送验证码
sendCode();
}
/**
* 具体发送逻辑,留给子类实现:发送邮件、或发送短信都行
*/
protected abstract void sendCode();
/**
* 生成验证码
*
* @return
*/
public String generateValidateCode() {
return "123456";
}
}
对于上面的模板,我们可以有多种实现方式,以便把sendCode()这个坑填上:
/**
* 短信验证码发送
*
* @author qiyu
* @date 2020-09-08 19:44
*/
public class SmsValidateCodeSender extends AbstractValidateCodeSender {
@Override
protected void sendCode() {
// 通过阿里云短信发送
}
}
/**
* QQ邮箱验证码发送
*
* @author qiyu
* @date 2020-09-08 19:45
*/
public class EmailValidateCodeSender extends AbstractValidateCodeSender {
@Override
protected void sendCode() {
// 通过QQ邮箱发送
}
}
内部迭代与外部迭代
外部迭代
简单理解外部迭代就是由用户来决定”做什么“和”怎么做“的操作。比如下面代码中”做什么“(把大写转成小写)与”怎么做“(通过 Iterator 遍历)是由用户来决定的。
List<String> example = Arrays.asList(new String[]{"A", "B", "C"});
// 遍历List,把大写转成小写
Iterator<String> iterator = example.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toLowerCase());
}

内部迭代
- 如果我们使用
Stream来操作集合的话可以这样写。
List<String> example = Arrays.asList(new String[]{"A", "B", "C"});
example.stream().forEach(e -> System.out.println(e.toLowerCase()));
Stream操作的是集合的流。

内部迭代我们只需要提供”做什么“,把”怎么做“的任务交给了 JVM。
使用内部迭代可以带来的好处:
- 用户只需要关注问题,无需关注如何解决问题的细节。
- 使得
JVM可以利用短路、并行等对性能的提升变成可能
StreamAPI 设计分析
Lambda底层原理其实是自动生成一个私有静态方法,并实现函数式接口,然后在函数式接口实现类的方法中调用这个私有静态方法。会有一些反编译操作。
模拟filter()
/**
* 新建Predicate接口
*
* @param <T>
*/
@FunctionalInterface
interface Predicate<T> {
/**
* 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现
*
* @param t
* @return
*/
boolean test(T t);
}
/**
* Predicate接口的实现类,泛型规定只处理Person
*/
class PredicateImpl implements Predicate<Person> {
/**
* 判断逻辑是:传入的person是否age>18,是就返回true
*
* @param person
* @return
*/
@Override
public boolean test(Person person) {
return person.getAge() > 18;
}
}
@Data
@AllArgsConstructor
class Person {
private String name;
private Integer age;
}
测试:
public class MockStream {
public static void main(String[] args) {
Person bravo = new Person("bravo", 18);
// 1.具体实现类,调用它的test()方法
Predicate<Person> predicate1 = new PredicateImpl();
// test()内部代码是:bravo.getAge() > 18
myPrint(bravo, predicate1); // false
// 2.匿名类,调用它的test()方法
Predicate<Person> predicate2 = new Predicate<Person>() {
@Override
public boolean test(Person person) {
return person.getAge() < 18;
}
};
myPrint(bravo, predicate2); // false
// 3.Lambda表达式,调用它的test()方法。
// 按照Lambda表达式的标准,只要你是个函数式接口,那么就可以接收Lambda表达式
Predicate<Person> predicate3 = person -> person.getAge() == 18;
myPrint(bravo, predicate3); // true
}
public static void myPrint(Person person, Predicate<Person> filter) {
if (filter.test(person)) {
System.out.println("true");
} else {
System.out.println("false");
}
}
}
myPrint(Person person, Predicate<Person> filter)的精髓是,用Predicate函数式接口先行占坑。我们无需关注Predicate传入myPrint()后将被如何调用,只要关注如何实现Predicate,又由于Predicate只有一个test()方法,所以最终我们只需关注如何实现test()方法。
而实现test()的诀窍在于,盯牢它的入参和出参。它有一个入参(待测试目标),而返回值是一个boolean(测试结果)。
// 1.普通的方法
public boolean test(Person p) {
// 啥逻辑都没有,直接返回true,你也可以按照实际业务写,比如p.age>18
return true;
}
// 2.Lambda形式
p -> return true;
之前提到过,在函数式接口的前提下,接口多态可以直接看作是方法多态,那么Filter#test()其实就是抽象方法占坑,实现类、匿名类或者Lambda表达式就可以指向它。就像之前说的,不管你先放鸡翅还是先倒可乐,我先用twoStep()占坑,你后面确定了自己传进来
上面3个例子,重要的不是结论,而是想揭露一个事实
不论具体实现类、匿名类还是Lambda表达式,其实做的事情本质上是一样的:
1.先让函数式接口占坑
2.自己后续调用时制定映射规则,规则可以被藏在具体类、匿名类中,或者Lambda表达式本身
有了上面的铺垫,我们来仔细看看之前山寨Stream API对filter()的实现:
class MyList<T>{
private List<T> list = new ArrayList<>();
// 1.外部调用add()添加的元素都会被存在list
public boolean add(T t) {
return list.add(t);
}
/**
* 过滤方法,接收过滤规则
* @param predicate
* @return
*/
public List<T> filter(Predicate<T> predicate){
List<T> filteredList = new ArrayList<>();
for (T t : list) {
// 2.把规则应用于list
if (predicate.test(t)) {
// 3.收集符合条件的元素
filteredList.add(t);
}
}
return filteredList;
}
}
-
filter(Predicate predicate)方法需要一个过滤规则,但这个规则不能写死,所以随便搞了一个接口占坑
-
具体的过滤规则被延迟到传入具体类实例或Lambda时才确定
你可以理解为就是对策略模式的应用,但函数式接口更喜欢接收Lambda表达式,代码更加简洁。
Predicate接口已经提前占好坑位,而Lambda们则是去填坑。对于filter()这个案例而言,它需要外界传入具体的“判断器”,然后filter()内部让元素挨个排队去做检查,检查通过就加入filteredList,然后一起返回。

不关注Predicate接口接收的是谁(匿名对象/具体实现/Lambda),只关心它能干什么(方法)。这也是面向对象和函数式编程的思维差异
模拟map()
再模拟一个map()。因为实际编程中,个人认为filter()和map()是最常用的,希望大家能理解它们的“原理”。
/**
* 定义一个Function接口
* 从接口看Function<E, R>中,E(Enter)表示入参类型,R(Return)表示返回值类型
*
* @param <E> 入参类型
* @param <R> 返回值类型
*/
@FunctionalInterface
interface Function<E, R> {
/**
* 定义一个apply()方法,接收一个E返回一个R。也就是把E映射成R
*
* @param e
* @return
*/
R apply(E e); //方法调用时,R被确定。
}
/**
* Function接口的实现类,规定传入Person类型返回Integer类型
*/
class FunctionImpl implements Function<Person, Integer> {
/**
* 传入person对象,返回age
*
* @param person
* @return
*/
@Override
public Integer apply(Person person) {
return person.getAge();
}
}
public class MockStream {
public static void main(String[] args) {
Person bravo = new Person("bravo", 18);
// 1.具体实现类,Function<Person, Integer>中,Person是入参类型,Integer是返回值类型
Function<Person, Integer> function1 = new FunctionImpl();
myPrint(bravo, function1);
// 2.匿名类
Function<Person, Integer> function2 = new Function<Person, Integer>() {
@Override
public Integer apply(Person person) {
return person.getAge();
}
};
myPrint(bravo, function2);
// 3.Lambda表达式 person(入参类型) -> person.getAge()(返回值类型)
Function<Person, Integer> function3 = person -> person.getAge();
myPrint(bravo, function3);
}
public static void myPrint(Person person, Function<Person, Integer> mapper) {
System.out.println(mapper.apply(person));
}
}
目前为止应该还蛮好理解的。
之前我们在MyList中写了个filter()方法并用Predicate接口占了坑,它接收一个“过滤器”来过滤元素。而现在,map()方法用Function接口占坑,它需要接收一个“转换器”来帮元素“变身”:
class MyList<T> {
private List<T> list = new ArrayList<>();
public boolean add(T t) {
return list.add(t);
}
/**
* 把MyList中的List<T>转为List<R>
* 不要关注Function<T, R>接口本身,而应该关注apply()
* apply()接收T t,返回R t。具体实现需要我们从外面传入,这里只是占个坑
*
* @param mapper
* @param <R>
* @return
*/
public <R> List<R> map(Function<T, R> mapper) {
List<R> mappedList = new ArrayList<>();
for (T t : list) {
// mapper通过apply()方法把T t 变成 R t,然后加入到新的list中
mappedList.add(mapper.apply(t));
}
return mappedList;
}
}
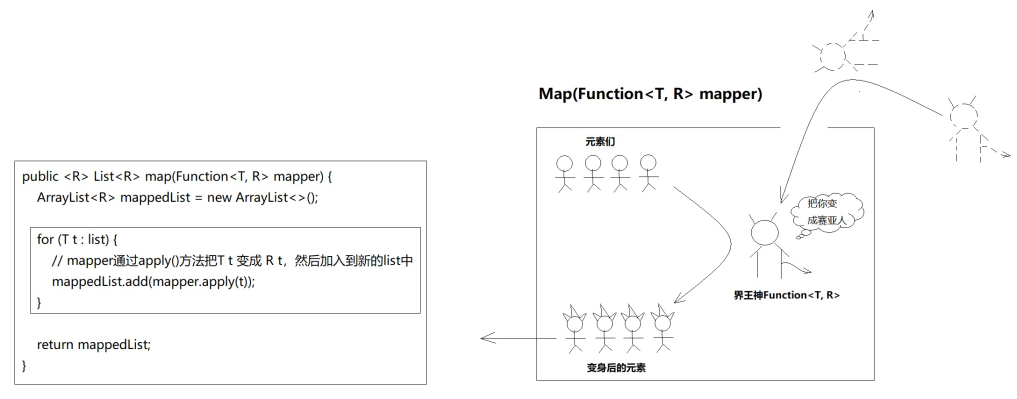
无论filter(Predicate predicate)还是map(Function mapper),其实就是接口占坑、Lambda填坑的过程,其中函数式接口只有唯一方法,所以可以直接把接口多态看做方法多态。比如Predicate只有一个抽象方法boolean test(),那么你写一个符合的具体实现即可:一个入参,返回值为boolean。
以后但凡遇到函数式接口占坑的,只要关注入参和出参即可:
Person ==> {坑} ==> boolean
很明显,入参是Person,出参是Integer。那Person类型怎么变成Integer类型呢?填坑的方案并不唯一,你可以编写任意逻辑,比如:
Person ==> {person -> person.getAge()} ==> Integer
当然,你也可以传递person.getAge()+1。总之,坑已经占好了,注意一下入参和出参满足条件即可。
方法引用
方法引用和匿名对象、lambda表达式等价
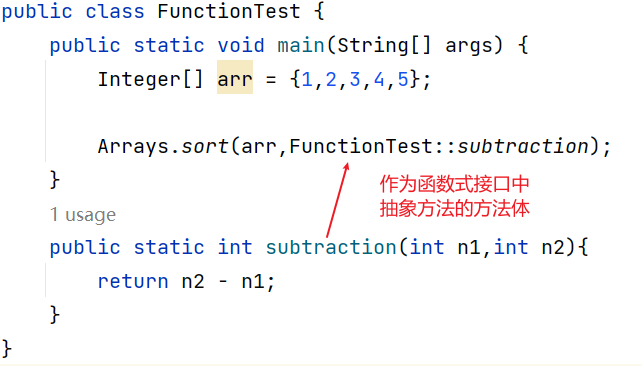
方法引用就是将已有的方法拿过来用,可以作为函数式接口中抽象方法的方法体。
如果一个Lambda表达式只是调用某个方法,就可以使用方法引用。
有如下要求:
- 引用处必须是函数式接口
- 被引用的方法必须是已经存在的
- 被引用的方法的形参和返回值需要和抽象方法保持一致
- 被引用的方法功能满足当前的需求
现有如下代码:

假设现在有写好的代码:

就可以替换为:
::就是方法引用符
方法引用的分类
flowchart LR 1.引用静态方法 2.引用成员方法 --> 1.引用其他类的成员方法 & 2.引用本类的成员方法 & 3.引用父类的成员方法 3.引用构造方法 4.其他调用方式 --> 1.使用类名引用成员方法 & 2.引用数组的构造方法引用静态方法
类名::静态方法
Integer::parseInt
练习:集合中有字符串类型数字,要求将其转换为int类型
List<String> list = Arrays.asList("1", "2", "3", "4");
list.stream().map(Integer::parseInt).forEach(System.out::println);
map的参数:函数式接口Function,消费T类型,生产R类型;方法的形参和返回值需要与抽象方法的形参和返回值保持一致。
方法的功能是把形参的字符串转换为整数
引用成员方法
对象::成员方法
其他类: 其他类对象::方法名
本类: this::方法名
父类: super::方法名
以上的都是在成员方法中引用其他成员方法,静态方法里没有super和this,只能创建对象
练习1:集合中有一些名字,按照要求过滤数据
有成员方法:
class StringTool{
public boolean startWithWordAndSizeEqualsThree(String s){
return s.startsWith("张") && s.length() == 3;
}
}
- 在其他类引用这个其他类的成员方法
public static void main(String[] args) {
List<String> list = Arrays.asList("张三丰", "张无忌", "张无", "赵敏");
list.stream().map(new StringTool()::stringJudge).forEach(System.out::println);
}
- 在子类引用这个成员方法:
class StringToolSub extends StringTool{
public void doSome(){
List<String> list = Arrays.asList("张三丰", "张无忌", "张无", "赵敏");
list.stream().map(super::stringJudge).forEach(System.out::println);
}
}
因为public修饰的成员方法是可以被继承的,所以此处也可以使用this
- 在本类中引用这个成员方法
class StringTool{
public boolean stringJudge(String s){
return s.startsWith("张") && s.length() == 3;
}
public void doSome(){
List<String> list = Arrays.asList("张三丰", "张无忌", "张无", "赵敏");
list.stream().map(this::stringJudge).forEach(System.out::println);
}
}
引用构造方法
引用构造方法是为了创建对象
类名::new
Student::new
List<String> list = Arrays.asList("张三丰-15", "张无忌-20", "张无-25", "赵敏-30");
需要在构造方法里对流中的每一个字符串进行处理
class Person{
private String name;
private Integer age;
public Person(String str) {
this(str.split("-")[0],Integer.parseInt(str.split("-")[1]));
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
List<String> list = Arrays.asList("张三丰-15", "张无忌-20", "张无-25", "赵敏-30");
list.stream().map(Person::new).forEach(System.out::println);
其他方式调用
类名引用成员方法
类名::成员方法
String::substring
练习:集合中的字符串,要求变成大写之后输出
list.stream().map(s -> s.toUpperCase()).forEach(System.out::println);
但是这样也可以这样调用:
List<String> list = Arrays.asList("abc", "def", "ghi", "jkm");
list.stream().map(String::toUpperCase).forEach(System.out::println);
toUpperCase方法:
public String toUpperCase(String this) {
return toUpperCase(Locale.getDefault());
}
在调用时,正常情况下:
String s = "abc";
s.toUpperCase();
虚拟机在调用成员方法时,会隐含的将s引用赋值给隐含参数this,所以此时stream流中的每一个元素都赋值给参数this了,这样就可以通过类名来引用成员方法。
这里有两个问题:
- 成员方法需要使用对象调用
- 参数列表没有保持一致
这里遵守的是另一套规则:
- 如果某个Lambda表达式只是调用一个实例方法,并且参数列表中第一个参数作为方法的主调,后面的所有参数都是作为实例方法的入参,就可以使用类名引用实例方法
抽象方法形参:
- 第一个参数:表示被引用方法的调用者,决定了可以引用哪些类中的方法
在Stream流中,第一个参数一般都表示流里面的每一个数据。
假设流里面的数据是字符串,那么使用这种方式进行方法引用,只能引用Srting类中的方法 - 第二个参数到最后一个参数:与被引用方法的形参保持一致,如果没有第二个参数,表示被引用的方法是无参的成员方法
也就是说明,流中的参数可以调用自身的成员方法,但是成员方法的形参需要与流的其他形参保持一致
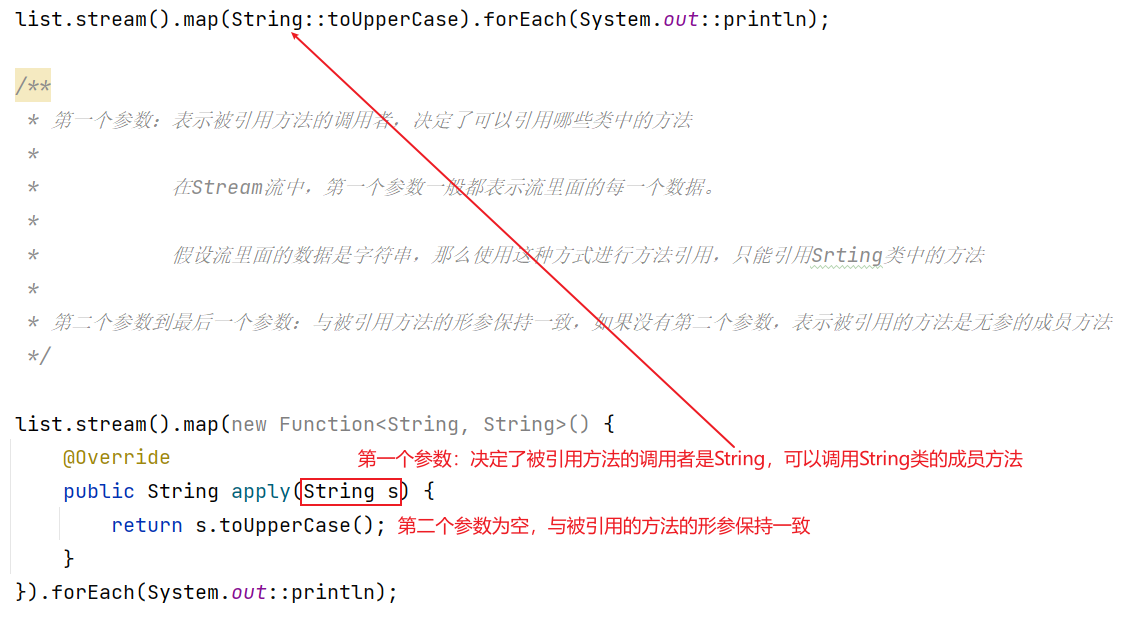
也就是拿着流中的每一个数据,调用String类的toUpperCase方法
引用数组构造方法
数据类型[]::new
int[]::new
List<Integer> list = Arrays.asList(1, 2, 3, 4);
list.stream().toArray(Integer[]::new);
练习
集合中存储:"张三,23"类的字符串,收集到Person类型的数组中
class Person{
private String name;
private Integer age;
public Person(String str) {
this(str.split(",")[0],Integer.parseInt(str.split(",")[1]));
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
List<String> list = Arrays.asList("张三,23", "张三,23", "张三,23", "张三,23");
Person[] persons = list.stream().map(Person::new).toArray(Person[]::new);
System.out.println(Arrays.toString(persons));
创建集合添加Person对象,只获取姓名放在数组中
class Person{
private String name;
private Integer age;
public Person(String str) {
this(str.split(",")[0],Integer.parseInt(str.split(",")[1]));
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
List<Person> list = List.of(new Person("张三,23"),new Person("张三,23"));
String[] names = list.stream().map(Person::getName).toArray(String[]::new);
System.out.println(Arrays.toString(names));
创建集合添加Person对象,把name和age拼接为:张三-23的字符串,放入数组
List<Person> list = List.of(new Person("张三,23"),new Person("张三,23"));
String[] persons = list.stream()
.map(person -> person.getName() + "-" + person.getAge()).toArray(String[]::new);
System.out.println(Arrays.toString(persons));
也可以重写Person的toString方法,引用这个toString
Lambda表达式与方法引用
引例
public class MethodReferenceTest {
private static final List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person(19));
list.add(new Person(18));
list.add(new Person(20));
}
public static void main(String[] args) {
System.out.println(list);
// sort()方法是List本身就有的,主要用来排序
list.sort((p1, p2) -> p1.getAge() - p2.getAge());
System.out.println(list);
}
@Data
@AllArgsConstructor
static class Person {
private Integer age;
}
}
结果
排序前:
[MethodReferenceTest.Person(age=19), MethodReferenceTest.Person(age=18), MethodReferenceTest.Person(age=20)]
排序后:
[MethodReferenceTest.Person(age=18), MethodReferenceTest.Person(age=19), MethodReferenceTest.Person(age=20)]
把上面的案例稍作改动:
public class MethodReferenceTest {
private static final List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person(19));
list.add(new Person(18));
list.add(new Person(20));
}
public static void main(String[] args) {
System.out.println(list);
// 改动2:既然Person内部有个逻辑一样的方法,就用它来替换Lambda
list.sort(Person::compare);
System.out.println(list);
}
@Data
@AllArgsConstructor
static class Person {
private Integer age;
// 改动1:新增一个方法,逻辑和之前案例的Lambda表达式相同
public static int compare(Person p1, Person p2) {
return p1.getAge() - p2.getAge();
}
}
}
从Lambda到方法引用
/**
* 从匿名对象 到Lambda 再到方法引用
*
* @author qiyu
*/
public class MethodReferenceTest {
public static void main(String[] args) {
String str1 = "abc";
String str2 = "abcd";
// 方式1:匿名对象
Comparator<String> comparator1 = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
};
compareString(str1, str2, comparator1);
// 方式2:过渡为Lambda表达式
Comparator<String> comparator2 = (String s1, String s2) -> {
return s1.length() - s2.length();
};
compareString(str1, str2, comparator2);
// 方式2的改进版:省去赋值操作,直接把整个Lambda表达式作为参数丢进去
compareString(str1, str2, (String s1, String s2) -> {
return s1.length() - s2.length();
});
// 方式2的最终版:把变量类型和return也去掉了,因为Java可以自动推断
compareString(str1, str2, (s1, s2) -> s1.length() - s2.length());
// 方式3:换种比较方式,本质和方式2是一样的,不信你去看看String#compareTo()
Comparator<String> comparator3 = (s1, s2) -> s1.compareTo(s2);
// 方式4:IDEA提示有改进的写法,最终变成了方法引用
compareString(str1, str2, String::compareTo);
// 完美。
}
/**
* 传递Comparator,对str1和str2进行比较
*
* @param str1
* @param str2
* @param comparator
*/
public static void compareString(String str1, String str2, Comparator<String> comparator) {
System.out.println(comparator.compare(str1, str2));
}
}
我们在学习Lambda时,把它和匿名类作比较。因为匿名类和Lambda处理的逻辑是一样的,所以就用Lambda简化了匿名类:

同样的,如果项目中已经定义了相同逻辑的方法,我们为什么还要再写一遍呢?即使Lambda表达式再怎么简洁,终究还是要手写好几行代码。
所以,JDK在Lambda表达式的基础上又提出了方法引用的概念,允许我们复用当前项目(或JDK源码)中已经存在的且逻辑相同的方法。
比如上面那个例子中的:
// 方式3:换种比较方式,本质和方式2是一样的
Comparator<String> comparator3 = (s1, s2) -> s1.compareTo(s2);
// 方式4:IDEA提示有改进的写法,最终变成了方法引用
compareString(str1, str2, String::compareTo);
String::compareTo看起来形式有点诡异,但这只是一种语法而已,习惯就好了,关键是明白它代表什么意思。Java8引入::符号,用来表示方法引用。所谓的方法引用,就是把方法搬过来使用。那么,String::compareTo把哪个类的什么方法搬过来了呢?
一般来说,String类定义的compareTo方法的正常使用方式是这样的:
public class MethodReferenceTest {
public static void main(String[] args) {
String str = "hello";
String anotherStr = "world";
int difference = str.compareTo(anotherStr);
}
}
作为更高阶的Lambda表达式,方法引用也能作为参数传递,于是就有了:
public class MethodReferenceTest {
public static void main(String[] args) {
String str = "hello";
String anotherStr = "world";
// 匿名内部类
Comparator<String> comparator = new Comparator<String>() {
@Override
public int compare(String str, String anotherStr) {
return str.compareTo(anotherStr);
}
};
// 方法引用。上面的str.compareTo(anotherStr)不就是String::compareTo吗!!
Comparator<String> newComparator = String::compareTo;
compareString(str, anotherStr, newComparator);
}
/**
* 传递Comparator,对str1和str2进行比较
*
* @param str1
* @param str2
* @param comparator
*/
public static void compareString(String str1, String str2, Comparator<String> comparator) {
System.out.println(comparator.compare(str1, str2));
}
}
总之,Java8的意思就是:
兄弟,如果已经存在某个方法能完成你的需求,那么你连Lambda表达式都别写了,直接引用这个方法吧。
但我个人更推荐Lambda表达式,原因有两个:
- 对初学者而言,Lambda表达式语义更清晰、更好理解
- Lambda表达式细粒度更小,能完成更精细的需求
第一点,你懂的。
第二点,请容许我来证明一下。
Lambda表达式VS方法引用
/**
* MyPredict是模拟Predict
* MyInteger是模拟Integer
* <p>
* 本次测试的目的旨在说明:Lambda毕竟是手写的,自由度和细粒度要高于方法引用。
*
* @author sunting
*/
public class MethodAndLambdaTest {
public static void main(String[] args) {
// 1.匿名对象
MyPredict myPredict1 = new MyPredict() {
@Override
public boolean test(int a, int b) {
return a - b > 0;
}
};
boolean result1 = myPredict1.test(1, 2); // false
// 2.从匿名对象过渡到Lambda表达式
MyPredict myPredict2 = (a, b) -> a - b > 0;
myPredict2.test(1, 2); // false
// 3.MyInteger#compare()的方法体和上面的Lambda表达式逻辑相同,可以直接引用
MyPredict myPredict3 = MyInteger::compare;
myPredict3.test(1, 2); // false
// 4.Lambda说,你想模仿我?想得美!老子要DIY一下比较规则(a减b 变成了 b减a)
MyPredict myPredict4 = (a, b) -> b - a > 0;
myPredict4.test(1, 2); // true
// 5.看到这,方法引用不服气,也想DIY一把
MyPredict myPredict5 = MyInteger::compare;
// ???,没法DIY,MyInteger::compare是把整个方法搬过来,不能修改内部的逻辑
}
}
interface MyPredict {
boolean test(int a, int b);
}
class MyInteger {
public static boolean compare(int a, int b) {
return a - b > 0;
}
}
方法引用,其实就是把现成的某个方法拿来替代逻辑相似的Lambda表达式。
但Lambda表达式由(a, b) -> a - b > 0 变为 (a, b) -> b - a > 0 ,说明Lambda逻辑已经变了,此时原先的方法引用就不匹配了,不能再用了。此时我们最自然的想法应该是从现成的项目中找到逻辑和(a, b) -> b - a > 0相同的另一个方法,然后把那个方法引用过来,而不是想着改变原来的MyInteger::Compare,那不是你的方法,你也只是借用而已!!
所以,我们给MyInteger加一个方法吧:
class MyInteger {
public static boolean compare(int a, int b) {
return a - b > 0;
}
public static boolean anotherCompare(int a, int b) {
return b - a > 0;
}
}
这样,方法引用的逻辑又和Lambda匹配了:
public class MethodAndLambdaTest {
public static void main(String[] args) {
MyPredict myPredict2 = (a, b) -> a - b > 0;
myPredict2.test(1, 2); // false
MyPredict myPredict3 = MyInteger::compare;
myPredict3.test(1, 2); // false
MyPredict myPredict4 = (a, b) -> b - a > 0;
myPredict4.test(1, 2); // true
// MyInteger::anotherCompare的逻辑和上面的Lambda才是匹配的
MyPredict myPredict5 = MyInteger::anotherCompare;
myPredict5.test(1, 2); // true
}
}
interface MyPredict {
boolean test(int a, int b);
}
class MyInteger {
public static boolean compare(int a, int b) {
return a - b > 0;
}
public static boolean anotherCompare(int a, int b) {
return b - a > 0;
}
}
再看一个Stream API的例子:
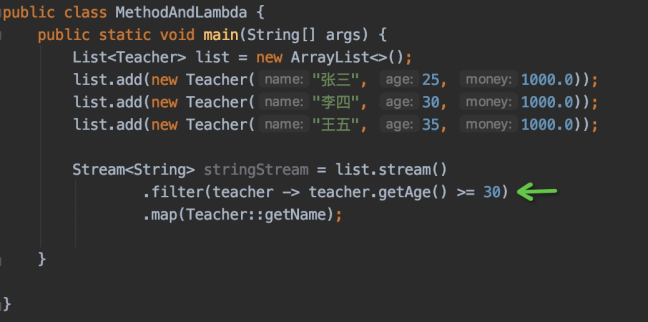
filter此时需要的逻辑是:年龄大于等于30岁的teacher。
你能从现有项目中找到逻辑为“年龄大于等于30岁的teacher”的方法吗?
答案是没有。
你最多只能调用Teacher::getAge(),但是这个方法引用的逻辑是“获取老师的年龄”,而不是“是否大于等于30岁”,两者逻辑不同,无法替换。
那能不能使用 Teacher::getAge()>=30 呢?

答案是不能。
首先,filter()的参数要么是Lambda表达式,要么是方法引用,不能是方法引用+语句,不伦不类。
其次,也是最重要的,你可以认为Teacher::getAge表示
public Integer getAge(){
return this.age;
}
中的return this.age;,它是一个语句。我们可以对表达式叠加判断,比如 a-b ,我们可以继续叠加变成 a-b+c。但是 int d = a-b+c; 已经没办法再叠加了,因为 int d = a-b+c; >= 30 是不可接受的!
处理办法也简单,就是找一个相同逻辑的方法并引用它。假设存在以下方法:
public boolean isBiggerThan30(){
return this.age >= 30;
}
那就可以写成:
list.stream().filter(Teacher::isBiggerThan30);
后话
关于方法引用其实还可以展开说,比如可以分为:
- 静态方法引用(Integer::compare)
- 实例方法引用(this::getName、user::getName)
- 构造器方法引用(User::new)
总体来说,方法引用(包括构造器引用)的前提是,函数式接口的方法对应的参数列表和返回值 与 引用类定义的方法的参数列表和返回值 一致。这样说可能比较绕,这里举一个demo:
public class StreamConstructorTest {
public static void main(String[] args) {
// 下面4个语句都是Person::new,却能赋值给不同的函数式接口
// 原因是:每个函数式接口都能从Person类中找到对应的方法(参数列表一致),从而完成方法引用
PersonCreatorNoConstruct person1 = Person::new;
// 大家可以尝试把Person中Age构造函数注释,那么下面的赋值语句会提示错误,因为此时不存在只有一个age参数的构造器!
PersonCreatorWithAge person2 = Person::new;
PersonCreatorWithName person3 = Person::new;
PersonCreatorAllConstruct person4 = Person::new;
}
public interface PersonCreatorNoConstruct {
// 对应Person无参构造
Person create();
}
public interface PersonCreatorWithAge {
// 对应Person的age构造函数
Person create(Integer age);
}
public interface PersonCreatorWithName {
// 对应Person的name构造函数
Person create(String name);
}
public interface PersonCreatorAllConstruct {
// 对应Person的全参构造函数
Person create(Integer age, String name);
}
@Getter
@Setter
static class Person {
private Integer age;
private String name;
public Person() {
}
public Person(Integer age) {
this.age = age;
}
public Person(String name) {
this.name = name;
}
public Person(Integer age, String name) {
this.age = age;
this.name = name;
}
}
}
public class MethodReferenceTest {
public static void main(String[] args) {
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
String str1 = "abc";
String str2 = "abcd";
//这里不太明白为什么可以直接用string的compareTo的方法引用
//compareString方法第三个参数要求的是Comparator类型的对象,以Lambda表达式来讲 它接受的对象对应实现的方法要求的是两个入参。
//而String::compareTo方法只有一个入参,所以这里不太明白为什么可以直接用string的compareTo的方法引用
compareString(str1, str2, String::compareTo);
}
public static void compareString(String str1, String str2, Comparator<String> comparator) {
System.out.println(comparator.compare(str1, str2));
}
}
java.lang.String#compareTo只接收一个入参。但是,Comparator接口的compare()方法接收两个入参。因此,当使用方法引用时,需要将第一个入参传递给this。在本例中,this指向String对象。因此,方法引用String::compareTo等效于Lambda表达式(this, o) -> this.compareTo(o)。
函数式接口
以Predicate为例,之前在分析山寨Stream API时,我们已经不知不觉使用过函数式接口:

// 1.用Lambda表达式实现Predicate接口的抽象方法test(),并赋值给函数式接口
Predicate<User> ifHigherThan180 = user -> user.getHeight()>180;
// 2.作为参数传入filter(Predicate<T> ifHigherThan180),filter()会在内部调用test()用来判断
ifHigherThan180.test(user);
总的来说,就是把方法A(Lambda)传给方法B(filter),然后在方法B内部调用方法A完成一些操作:
public void methodB(method a) {
// 操作1
// 调用method a
// 操作3
}
我们可以理解为Java8支持传递方法(之前只能传递基本数据类型和引用类型),也可以按原来面向对象的思维将Lambda理解为“特殊的匿名对象”。
为什么函数式接口重要
之前只是向大家介绍了函数式接口的定义:
有且仅有一个抽象方法的接口(不包括默认方法、静态方法以及对Object方法的重写)
就我个人学习体会来看,函数式接口虽然不难,但作为参数类型出现时,经常会让初学者感到无所适从,甚至不知道该传递什么。比如Stream API中就大量使用了函数式接口接收形参:

CompletableFuture中也大量使用了函数式接口:

不知道大家是否曾经在调用filter()、supplyAsync()等方法时感到迷茫,起码我刚接触Java8时,每次调用这些方法都力不从心,不知道该传什么进去,也不知道Lambda表达式该怎么写。
如果你问我函数式接口难吗,我大概率会告诉你,它本身很简单。但如果你问我函数式接口重要吗,我会告诉你,它非常非常重要,能否熟练使用Java8的诸多新特性(Stream、CompletableFuture等)取决于你对函数式接口的熟悉程度。
函数式接口类型
根据方法的出入参类型不同,各种排列组合后,其实有很多种类型,最常用的有以下4种函数式接口:
public class FunctionalInterfaceTest {
/**
* 给函数式接口赋值的格式:
* 函数式接口 = 入参 -> 出参/制造出参的语句
*
* @param args
*/
public static void main(String[] args) {
FunctionalInterface1 interface1 = str -> System.out.println(str);
FunctionalInterface2 interface2 = () -> {
return "abc";
};
FunctionalInterface3 interface3 = str -> Integer.parseInt(str);
FunctionalInterface4 interface4 = str -> str.length() > 3;
}
/**
* 消费型,吃葡萄不吐葡萄皮:有入参,无返回值
* (T t) -> {}
*/
interface FunctionalInterface1 {
void method(String str);
}
/**
* 供给型,无中生有:没有入参,却有返回值
* () -> T t
*/
interface FunctionalInterface2 {
String method();
}
/**
* 映射型,转换器:把T转成R返回
* T t -> R r
*/
interface FunctionalInterface3 {
int method(String str);
}
/**
* 特殊的映射型:把T转为boolean
* T t -> boolean
*/
interface FunctionalInterface4 {
boolean method(String str);
}
}
正因为各自出入参不同,导致Lambda表达式的写法也不同。
函数式接口作用
实际开发中,出入参类型的排列组合是有限的,所以JDK干脆内置了一部分函数式接口。一般来说,我们只需熟练掌握以下4大核心函数式接口即可:
- 消费型接口
Consumer<T>void accept(T t) - 供给型接口
Supplier<T>T get() - 函数型接口
Function<T, R>R apply(T t) - 断定型接口
Predicate<T>boolean test(T t)
其实是对各个方法的抽象类型
什么JDK要在Java8这个版本引入函数式接口,并且提供这么多内置接口呢?
其实这些接口本不是给我们用的,而是JDK自己要用。
之前的filter和map方法模拟:
/**
* 新建Predicate接口
*
* @param <T>
*/
@FunctionalInterface
interface Predicate<T> {
/**
* 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现
*
* @param t
* @return
*/
boolean test(T t);
}
// Function接口 略...
同样的,我和Java8一样,也把Predicate接口作为形参类型(详见myPrint方法):
public class MockStream {
public static void main(String[] args) {
Person bravo = new Person("bravo", 18);
// 1.匿名对象,调用它的test()方法
Predicate<Person> predicate1 = new Predicate<Person>() {
@Override
public boolean test(Person person) {
return person.getAge() < 18;
}
};
myPrint(bravo, predicate1); // false
// 2.Lambda表达式,调用它的test()方法。
// 按照Lambda表达式的标准,只要你是个函数式接口,那么就可以接收Lambda表达式
Predicate<Person> predicate2 = person -> person.getAge() == 18;
myPrint(bravo, predicate2); // true
}
public static void myPrint(Person person, Predicate<Person> filter) {
if (filter.test(person)) {
System.out.println("true");
} else {
System.out.println("false");
}
}
}
JDK之所以要在Java8内置那么多函数式接口,本质原因和我的山寨Stream API一样,是为了配合Java8的各种API。单独发布Stream API和CompletableFuture是不现实的,它们的方法形参都依赖函数式接口呢。
Java8函数式接口的作用和我们自定义的Predicate接口一样:
- 接收Lambda表达式/方法引用
- 占坑
或者说,这两个作用是一体两面的。
如何克服面向对象的思维惯性
对于函数式接口,上面已经讲得很多了,本身很简单,没什么好介绍的。这里主要聊一聊初学者应该如何习惯函数式接口传参的方式,以及关注点应该放哪里。换句话说,帮助初学者克服面向对象的思维惯性,学会用函数式编程的思维去使用Java8的诸多特性。
还是以Predicate为例,它唯一的抽象方法是:
boolean test(T t);
很多Java程序员会对这种传参形式感到眩晕,因为我们的潜意识一直无法摆脱面向对象的影响。当你看到getHealthPerson(List<User> users, Predicate<User> filter)时,你的大脑会告诉你Predicate是一个接口,所以应该传一个匿名对象给它。然后你的大脑自己也懵了,因为它突然发现光看Predicate接口,根本不知道该实现什么方法,甚至连入参和返回值都不清楚,怎么手写Lambda?
但之前介绍Python的函数时,我们很自然就接受了:
# encoding: utf-8
# abs是Python的内置函数
result = abs(-1)
print(result)
# 定义add()方法,f显然是一个函数
def add(x, y, f):
return f(x) + f(y)
print(add(-1, -2, abs))
因为相比Python这些原本就支持函数式编程的语言来说,形参就是函数,不需要用接口做中间层过渡!而对于Stream这种面向对象世界中的异类,Java程序员还没准备好如何接纳它,看到接口形参第一时间想到的还是传匿名对象,突然要改成Lambda确实有点棘手,因为我们对接口内部的方法及出入参一概不知!
- 每个函数式接口就一个方法,记住那个方法的出入参,看到接口就写对应方法的Lambda
这里主要讲讲如何记忆函数式接口的方法。一定要注意,函数式接口的方法名字不重要,重要的是出入参:
- 消费型接口
Consumer<T>void accept(T t) 例:x -> System.out.println(x) - 供给型接口
Supplier<T>T get() 例:() -> - 函数型接口
Function<T, R>R apply(T t) 例:user -> user.getAge(),T是入参,R是出参 - 断定型接口
Predicate<T>boolean test(T t) 例:user -> user.getAge() > 18
记住了接口对应的出入参,Lambda就好办了,其实传递的都是:
接口声明 = 入参 -> 出参/制造出参的语句
不信你可以重新看看上面给出的例子,比如Function:user -> user.getAge(),就是把User user映射为Integer age,user是入参,user.getAge()是制造出参的语句。又比如Predicate:user -> user.getAge()>18,user是入参,user.getAge()>18就是制造出参的语句,因为boolean test(T t)需要返回boolean。
所以要习惯函数式接口传参,最重要的是记住该接口对应的方法的出入参,然后编写Lambda时套用模板:
接口声明 = 入参(有无入参?) -> 出参/制造出参的语句(有无出参?什么类型?)
虽然我们还没正式学习Stream API,但已经可以试着写写啦:
public class FunctionalInterfaceTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6));
/**
* Predicate:特殊映射,只断是非 Function:T t --> f(x) --> boolean
* Function:映射 Function:T t --> f(x) --> R r
*/
list.stream().filter().map().collect(Collectors.toList());
// Supplier,无源之水(S),却滔滔不绝,没有入参,却可以get()
CompletableFuture<Object> completableFuture = CompletableFuture.supplyAsync();
// Consumer,黑洞,吃(C)葡萄不吐葡萄皮,入参拿过来就是一顿操作,不返回
completableFuture.thenAccept();
}
}
函数式接口与类型推断
之前在《Lambda表达式》中,我举过一个例子
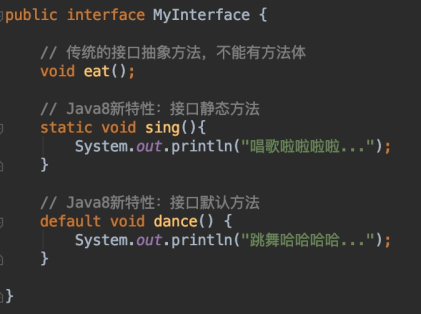
当接口内只有一个抽象方法时,可以使用Lambda表达时给接口赋值:
MyInterface interface = () -> System.out.println("吃东西");
但如果函数式接口内有多个方法抽象方法,就无法传递Lambda表达式:
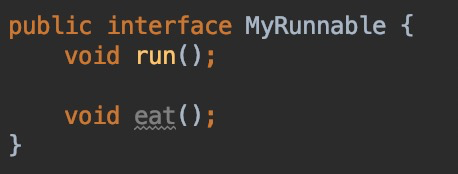

此时只能传入匿名对象分别实现两个抽象方法:
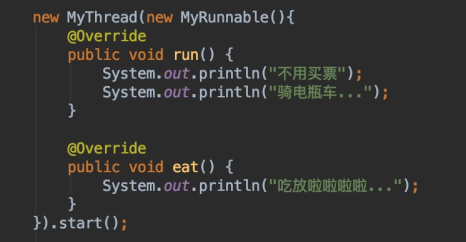
学完这一章,相信大家会有更深刻的理解:
public void run()和public void eat()如果只看出入参,其实是一样的,所以编译时无法自动推断。
由于本章节一直在强调函数式接口传参,所以这里再给出一个例子:
public class FunctionalInterfaceTest {
public static void main(String[] args) {
// Ambiguous method call
lambdaMethod(() -> System.out.println("test"));
}
/**
* 方法重载
*
* @param param1
*/
public static void lambdaMethod(Param1 param1) {
param1.print();
}
/**
* 方法重载
*
* @param param2
*/
public static void lambdaMethod(Param2 param2) {
param2.print();
}
/**
* 函数式接口1
*/
interface Param1 {
void print();
}
/**
* 函数式接口2
*/
interface Param2 {
void print();
}
}

原因也是一样的,Lambda只关注方法的出入参,所以在进行类型推断时,interface Param1和interface Param2是一样的,编译器无法替我们决定实现哪一个接口,解决办法是使用匿名对象。
如果说《Lambda表达式》中举的例子是方法级别的推断冲突,那么上面的例子讲的就是接口级别的推断冲突,但归根结底就一句话:Lambda上下文推断只看出入参,无论是接口名还是方法名,都不重要!
所以,学习函数式接口最重要的就是记住出入参的格式!!
参照附:ConvertUtil.java
小试牛刀
实际开发中,经常会看到这样的写法:
public void XxMethod(){
// ...
List<Long> iidList = new ArrayList<>();
List<Long> eventList = new ArrayList<>();
if(items != null && items.size > 0) {
for(Item item : items){
iidList.add(item.getId());
eventList.add(item.getEvent());
}
}
// ...
}
public void XxMethod(){
// ...
List<Long> iidList = new ArrayList<>();
List<Long> eventList = new ArrayList<>();
List<xxx> xxxList = new ArrayList<>();
...
//对iidList和eventList和其他List的其他操作
if(items != null && items.size > 0) {
for(Item item : items){
iidList.add(item.getId());
eventList.add(item.getEvent());
xxxList.add(...);
....
}
}
// ...
}
这里能用ConvertUtil的resultToList()吗?
答案是,不能。resultToList()一次只处理一个List,而上面一次循环可能处理N个List。所以我们能做的,只是抽取循环的操作,具体循环里做什么,每个List可能不同,不好抽取。
有了上面的经验,我们完全可以再给ConvertUtil封装个方法:
/**
* foreach,内部判空
*
* @param originList 需要遍历的List
* @param processor 需要执行的操作
* @param <T>
*/
public static <T> void foreachIfNonNull(List<T> originList, Consumer<T> processor) {
if (originList == null || originList.isEmpty()) {
return;
}
for (T originElement : originList) {
if (originElement != null) {
processor.accept(originElement);
}
}
}
public void XxMethod(){
// ...
List<Long> iidList = new ArrayList<>();
List<Long> eventList = new ArrayList<>();
ConvertUtil.foreachIfNonNull(items, item -> {
iidList.add(item.getId());
eventList.add(item.getEvent());
})
// ...
}
上面相当于自己实现了foreach。你可能会想,为什么不直接用Stream API或者直接List.foreach()?原因在于它们都要额外判断非空,否则可能引发NPE。
实际上这个操作也是可以完全抽取的,只是利用了前文中泛型擦除的特性:
public static <T,R> void add(List<T> baseList, List[] lists, Function<T,R> ... functions){
for (T t : baseList) {
for (int i = 0; i < lists.length; i++) {
lists[i].add(functions[i].apply(t));
}
}
}
虽然存入的时候按照Object存入(实际上也是利用了这个特性才能完成这个操作),取出的时候因为声明的泛型可以转换为对应的类型
最后留个思考题:自己实现groupBy()。
public static <T, K> Map<K, List<T>> groupBy(List<T> originList, Function<T, K> keyExtractor) {
HashMap<K, List<T>> hashMap = new HashMap<>();
for (T t : originList) {
if (t != null){
K key = keyExtractor.apply(t);
if (hashMap.get(key) == null) {
ArrayList<T> tList = new ArrayList<>();
tList.add(t);
hashMap.put(key,tList);
}else {
hashMap.get(key).add(t);
}
}
}
return hashMap;
}
如果分组后,我要的不是Map(City, List(User)),而是Map(City, List(username))呢?你能基于上面的方法进行改造吗?
public static <T,K,R> Map<K, List<R>> groupBy(List<T> originList, Function<T, K> keyExtractor, java.util.function.Function<T,R> mapper) {
HashMap<K, List<R>> hashMap = new HashMap<>();
for (T t : originList) {
if (t != null){
K key = keyExtractor.apply(t);
if (hashMap.get(key) == null) {
ArrayList<R> rList = new ArrayList<>();
rList.add(mapper.apply(t));
hashMap.put(key,rList);
}else {
hashMap.get(key).add(mapper.apply(t));
}
}
}
return hashMap;
}
Stream
获取Stream流
获取Stream流:
| 获取方式 | 方法名 | 说明 |
|---|---|---|
| 单列集合 | default Stream<E> stream() |
Collection接口的默认方法 |
| 双列集合 | 无 | 无法直接使用Stream流 |
| 数组 | public static <T> Stream<T> stream(T[] array) |
Arrays工具类中的静态方法 |
| 一堆零散数据 | public static <T> Stream<T> of(T ...values) |
Stream接口中的静态方法 |
单列集合
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"a","b","c","d","e");
//获取流并将集合中的数据放上去
Stream<String> stream1 = list.stream();
//使用终结方法打印
stream1.forEach(s -> System.out.println(s));
双列集合
HashMap<String,Integer> hm = new HashMap<>();
hm.put("aaa",111);
hm.put("bbb",222);
hm.put("ccc",333);
hm.put("ddd",444);
hm.keySet().stream().forEach(s->{
System.out.println(s + " : " + hm.get(s));
});
hm.entrySet().stream().forEach(e ->{
System.out.println(e.getKey() + " : " + e.getValue());
});
数组
int[] arr = {1,2,3,4,5,6,7,8,9,10};
String[] strs = {"a","b","c"};
Arrays.stream(arr).forEach(s-> System.out.println(s));
Arrays.stream(strs).forEach(s-> System.out.println(s));
零散数据
//stream流中元素是Integer类型
Stream.of(1,2,3,4,5).forEach(s-> System.out.println(s));
//stream流中元素是String类型
Stream.of("1","2","3","4","5").forEach(s-> System.out.println(s));
//stream流中元素是Serializable类型
Stream.of(1, 3, "a").forEach(s-> System.out.println(s));
不建议使用Stream.of方法创建数组的Stream流,引用数据类型的数组没有问题,基本数据类型的数组就会出现以下问题:
//引用类型数组
String[] strs = {"a","b","c"};
//Stream.of获取引用类型的数组没有问题,输出:abc
Stream.of(strs).forEach(System.out::print);
//基本类型数组
int[] ints = {1,2,3};
//Stream.of获取基本类型的数组出现问题,输出:[I@21e360a
Stream.of(ints).forEach(System.out::print);
对于基本类型数组,Stream.of会将整个数组当作一个元素放在Stream流上。
接口默认、静态方法
之前学习函数式接口时,曾经提到过Java8新出的接口静态方法、默认方法:

为什么Java8要引入静态方法和默认方法呢?
原因可能有多种,但其中一种肯定是为了“静默升级”。打开Collection接口:

这下明白了吧,list.stream().filter()...用的这么爽,其实都直接继承自顶级父接口Collection。
这和引入default有啥关系呢?
试想一下,要想操作Stream必须先获取Stream,获取流的方法理应放在Collection及其子接口、实现类中。但如果作为抽象方法抽取到Collection中,那么原先的整个继承链都会产生较大的震动:
JDK官方要从Collection接口沿着继承链向下都实现一遍stream()方法。这还不是最大的问题,最致命的是全球各地保不齐就有人直接实现了Collection,比如MyArrayList啥的,此时如果贸然往Collection增加一个抽象方法,那么当他们升级到JDK1.8后就会立即编译错误,强制他们自己实现stream()...
所以JDK的做法是,把获取Stream的一部分方法封装到StreamSupport类,另一部分封装到Stream类,StreamSupport用来补足原先的集合体系,比如Collection,然后引入default方法包装一下,内部调用StreamSupport完成偷天换日。而得到Stream后的一系列filter、map操作是针对Stream的,已经封装在Stream类中,和原来的集合无关。
所以,StreamSupport+default就是原先集合体系和Stream之间的“中介”:
调用者-->Collection-->StreamSupport+default-->Stream

总之,引入接口默认方法和静态方法后,接口越来越像一个类。从某个角度来说,这种做法破坏了Java的单继承原则。Java原本的特点是“单继承、多实现”,假设接口A和接口B都有methodTest(),那么class Test implements interfaceA, interfaceB时,就不得不考虑使用哪个父接口的methodTest()方法。JDK的做法是,编译时强制子类覆盖父接口同名的方法。
Stream API
我们最常用的集合其实来自两个派系:Collection和Map,实际开发时使用率大概是这样的:
- ArrayList:50%
- HashMap:40%
- 其他:10%
而用到Stream的地方,占比就更极端了:
- List:90%
- Set:5%
- Map:5%
对于一般人来说,只要学好List的Stream用法即可。
认识几个重要的接口与类
Stream的方法众多,不要期望能一次性融会贯通,一定要先了解整个API框架。有几个很重要的接口和类:
- Collection
- Stream
- StreamSupport
- Collector
- Collectors
Collection
之前介绍过了,为了不影响之前的实现,JDK引入了接口默认方法,并且在Collection中提供了一系列将集合转为Stream的方法:

要想使用Stream API,第一步就是获取Stream,而Collection提供了stream()和parallelStream()两个方法,后续Collection的子类比如ArrayList、HashSet等都可以直接使用顶级父接口定义好的默认方法将自身集合转为Stream。
Collection:定义stream()/parallelStream()
|--List
|--ArrayList:list.stream().filter().map().collect(...)
|--LinkedList:list.stream().filter().map().collect(...)
|--Vector
|--Set
|--HashSet
|--TreeSet
Stream
Java的集合在设计之初就只是一种容器,用来存储元素,内部并没有提供处理元素的方法。更多时候,我们其实是使用集合提供的遍历方法,然后手动在外部进行判断并处理元素。
Stream是什么呢?简单来说,可以理解为更高级的Iterator,把集合转为Stream后,我们就可以使用Stream对元素进行一系列操作
平时使用的filter()、map()、sorted()、collect()都来自:
方法太多了,记忆时需要带点技巧,比如分类记忆。
常用的有两种分类方法:
- 终止/中间操作
- 短路/非短路操作
前一种分类和我们关系大一些,所以我们按终止、中间操作分类记忆。
所谓中间操作和终止操作,可以粗略地理解为后面还能不能跟其他的方法。比如filter后面还可以跟map等操作,那么filter就是中间操作,而collect后返回的就是元素了,而不是流,无法继续使用。就好比一缕山泉,经过小草、小花、竹林,还是一缕水,但到了你的锅里煮成一碗粥,就没法继续使用了。
思维导图占位
还有几个不是特别常用的操作就不放在思维导图里了,这里简要介绍一下。比如,除了Collection接口中定义的stream()和parallelStream(),Stream也定义了创建流的方法(不常用):

还有一个合并流的方法(知道即可):
StreamSupport
没啥好介绍的,一般不会直接使用StreamSupport,Collection接口借助它实现了stream()和parallelStream()。
collect()、Collector、Collectors
直接演示:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("甲", 18, "杭州", 999.9));
list.add(new Person("乙", 19, "温州", 777.7));
list.add(new Person("丙", 21, "杭州", 888.8));
list.add(new Person("丁", 17, "宁波", 888.8));
}
public static void main(String[] args) {
List<Person> result = list.stream()
.filter(person -> person.getAge() > 20)
.collect(Collectors.toList());
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
collect()是用来收集处理后的元素的,它有两个重载的方法:
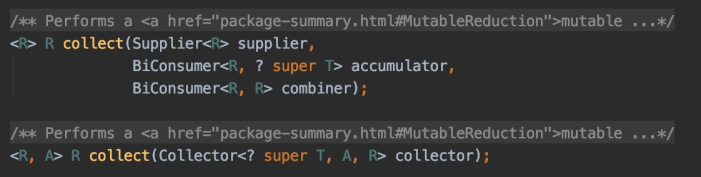
我们暂时只看下面那个,它接收一个Collector对象,而我们一般不会自己去new Collector对象,因为JDK给我提供了Collectors,可以调用Collectors提供的方法返回Collector对象:

所以collect()、Collector、Collectors三者的关系是:
collect()通过传入不同的Collector对象来明确如何收集元素,比如收集成List还是Set还是拼接字符串,而通常我们不需要自己实现Collector接口,只需要通过Collectors获取。
这倒颇有点像Executor和Executors的关系,一个是线程池接口,一个是线程池工具类。
如何高效学习Stream API
和几个重要接口、类混个脸熟后,我们来谈谈如何高效学习Stream API。很多同学应该已经被上面的内容吓到了,不要怕,通过后面的实操,整个知识脉络很快就会清晰起来。但还是那句话,一开始不要扣细节,先抓主干

初学者如果对stream的流式操作感到陌生,可以暂时理解为外部迭代(实际不是这样的,后面会大家一起观察):

特别注意reduce():

特别适合做累加、累乘啥的。
铺垫结束,接下来我们通过实战来正式学习Stream API。学习其他技术都可以追求理论深度,唯独Stream API就是一个字:干!
基础操作
map/filter
先来个最简单:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 我们先学中间操作
// 1.先获取流(不用管其他乱七八糟的创建方式,记住这一个就能应付95%的场景)
Stream<Person> stream = list.stream();
// 2.过滤得到年纪大于18岁的(filter表示过滤【得到】符合传入条件的元素,而不是过滤【去除】)
Stream<Person> filteredByAgeStream = stream.filter(person -> person.getAge() > 18);
// 3.只要名字,不需要整个Person对象(为什么在这个案例中,filter只能用Lambda,map却可以用方法引用?)
Stream<String> nameStream = filteredByAgeStream.map(Person::getName);
// 4.现在返回值是Stream<String>,没法直接使用,帮我收集成List<String>
List<String> nameList = nameStream.collect(Collectors.toList());
// 现在还对collect()为什么传递Collectors.toList()感到懵逼吗?
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
sorted()
试着加入sorted()玩一下。
在此之前,我们先来见见一位老朋友:Comparator。这个接口其实早在JDK1.2就有了,但当时只有两个方法:
- compare()
- equals()
JDK1.8通过默认方法的形式引入了很多额外的方法,比如reversed()、comparing()等。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// JDK8之前:Collections工具类+匿名内部类。Collections类似于Arrays工具类,我经常用Arrays.asList()
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之前:List本身也实现了sort()
list.sort(new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之后:Lambda传参给Comparator接口,其实就是实现Comparator#compare()。注意,equals()是Object的,不妨碍
list.sort((p1,p2)->p1.getName().length()-p2.getName().length());
// JDK8之后:使用JDK1.8为Comparator接口新增的comparing()方法
list.sort(Comparator.comparingInt(p -> p.getName().length()));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
大家不好奇吗?sort()需要的是Comparator接口的实现,调用Comparator.comparingInt()怎么也可以?

传入一个转换器,将key转换为Integer,不传入比较规则的都是按照升序排列的
重点:Comparator.comparingXxx()返回的也是Comparator,comparingXxx()方法其实都来源于comparing方法:

该方法接收一个比较器,在比较器中比较两个经过mapper转换的数据,比较的规则就是compare方法的方法体,例如:
Comparator<Object> comparing =
Comparator.comparing(person -> ((Person) person).getAge(), (age1, age2) -> age1 - age2);
所以上文中对List按照年龄升序排列也可以写为:
list.sort(Comparator.comparing(Function.identity(),Comparator.comparingInt(Person::getAge)));
OK,铺垫够了,来玩一下Stream#sorted(),看看和List#sort()有啥区别。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 直接链式操作
List<String> nameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(nameList);
// 我想按姓名长度排序
List<String> sortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNameList);
// 你:我擦,说好的排序呢?
// Stream:别扯淡,你告诉我排序规则了吗?(默认自然排序)
// 明白了,那就按照长度倒序吧(注意细节啊,str2-str1才是倒序)
List<String> realSortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted((str1, str2) -> str2.length() - str1.length())
.collect(Collectors.toList());
System.out.println(realSortedNameList);
// 优化一下:我记得在之前那张很大的思维导图上看到过,sorted()有重载方法,是sorted(Comparator)
// 上面Lambda其实就是调用sorted(Comparator),用Lambda给Comparator接口赋值
// 但Comparator还供了一些方法,能返回Comparator实例
List<String> optimizeNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
System.out.println(optimizeNameList);
// 又是一样的套路,Comparator.reverseOrder()返回的其实是一个Comparator!!
// 但上面的有点投机取巧,来个正常点的,使用Comparator.comparing()
List<String> result1 = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.comparing(t -> t, (str1, str2) -> str2.length() - str1.length()))
.collect(Collectors.toList());
System.out.println(result1);
// 我去,更麻烦了!!
// 不急,我们先来了解上面案例中Comparator的两个参数
// 第一个是Function映射,就是指定要排序的字段,由于经过上一步map操作,已经是name了,就不需要映射了,所以是t->t
// 第二个是比较规则
// 我们把map和sorted调换一下顺序,看起来就不那么别扭了
List<String> nameList = list.stream()
.filter(person -> person.getAge() > 18)
.sorted(Comparator.comparing(Person::getName,(str1,str2) -> str2.length() - str1.length()))
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(nameList);
//但是想实现倒序排列,还可以这样做:
List<String> result2 = list.stream()
.filter(person -> person.getAge() > 18)
.sorted(Comparator.comparing(Person::getName, String::compareTo).reversed())
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result2);
// 为什么Comparator.comparing().reversed()可以链式调用呢?
// 上面说了哦,因为Comparator.comparing()返回的还是Comparator对象~
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
需要注意的是:
Comparator.comparing(Person::getName, String::compareTo)
进行升序排列,如果要降序可以自定义,或者可以在升序排列后再链式调用reverse方法,该方法:

会将当前元素反转
limit/skip
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
List<String> result = list.stream()
.filter(person -> person.getAge() > 17)
// peek()先不用管,它不会影响整个流程,就是打印看看filter操作后还剩什么元素
.peek(person -> System.out.println(person.getName()))
.skip(1)
.limit(2)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
结果
==== 过滤后的元素有3个 ====
i
am
iron
==== skip(1)+limit(2)后的元素 ====
[am, iron]
collect
collect()是最重要、最难掌握、同时也是功能最丰富的方法。
最常用的4个方法:Collectors.toList()、Collectors.toSet()、Collectors.toMap()、Collectors.joining()
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 最常用的4个方法
// 把结果收集为List
List<String> toList = list.stream().map(Person::getAddress).collect(Collectors.toList());
System.out.println(toList);
// 把结果收集为Set
Set<String> toSet = list.stream().map(Person::getAddress).collect(Collectors.toSet());
System.out.println(toSet);
// 把结果收集为Map,前面的是key,后面的是value,如果你希望value是具体的某个字段,可以改为toMap(Person::getName, person -> person.getAge())
Map<String, Person> nameToPersonMap =
list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
// 把结果收集起来,并用指定分隔符拼接
String result = list.stream().map(Person::getAddress).collect(Collectors.joining("~"));
System.out.println(result);
}
}
关于collect收集成Map的操作,有一个小坑需要注意:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("iron", 17, "宁波", 888.8));
}
public static void main(String[] args) {
Map<String, Person> nameToPersonMap =
list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
}
}
尝试运行上面的代码,会观察到如下异常:
Exception in thread "main" java.lang.IllegalStateException: Duplicate key Person
这是因为toMap()不允许key重复,我们必须指定key冲突时的value解决策略(比如,保留已存在的value)
public static void main(String[] args) {
Map<String, Person> nameToPersonMap =
list.stream()
.collect(Collectors.toMap(Person::getName, person -> person, (preValue, nextValue) -> preValue));
System.out.println(nameToPersonMap);
}
如果你希望key覆盖,可以把(preKey, nextKey) -> preKey)换成(preKey, nextKey) -> nextKey)。
你可能会在同事的代码中发现另一种写法:
public static void main(String[] args) {
Map<String, Person> nameToPersonMap =
list.stream().collect(Collectors.toMap(Person::getName, Function.identity());
System.out.println(nameToPersonMap);
}
Function.identity()其实就是v->v:

但它依然没有解决key冲突的问题,而且对于大部分人来说,相比person->person,Function.identity()的可读性不佳。
聚合:max/min/count
max/min
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 匿名内部类的方式,实现Comparator,明确按什么规则比较(所谓最大,必然是在某种规则下的最值)
//Optional<Integer> maxAge =
// list.stream().map(Person::getAge).max((age1,age2) -> age1 - age2);
Optional<Integer> maxAge =
list.stream().map(Person::getAge).max(Comparator.comparingInt(age -> age));
System.out.println(maxAge.orElse(0));
Optional<Integer> max = list.stream().map(Person::getAge).max(Integer::compareTo);
System.out.println(max.orElse(0));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
count
public static void main(String[] args) {
long count = list.stream().filter(person -> person.getAge() > 18).count();
System.out.println(count);
}
去重:distinct
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
long count = list.stream().map(Person::getAddress).distinct().count();
System.out.println(count);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
所谓“去重”,就要明确怎样才算“重复”。那么,distinct()是基于什么标准呢?
还是那两样:hashCode()和equals(),所以记得重写这两个方法(一般使用Lombok的话问题不大)。
distinct()提供的去重功能比较简单,就是判断对象重复。如果希望实现更细粒度的去重,比如根据对象的某个属性去重,可以参考:分享几种 Java8 中通过 Stream 对列表进行去重的方法
forEach
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 遍历操作,接收Consumer
list.stream().forEach(System.out::println);
// 简化,本质上不算同一个方法的简化
list.forEach(System.out::println);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
需要的就是一个Consumer参数
高阶操作
两部分内容:
- 深化一下collect()方法,它还有很多其他玩法
- 介绍flatMap、reduce、匹配查找、peek、forEach等边角料
collect高阶操作
聚合
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 演示用collect()方法实现聚合操作,对标max()、min()、count()
* @param args
*/
public static void main(String[] args) {
// 方式1:匿名对象
Optional<Person> max1 = list.stream().collect(Collectors.maxBy(new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getAge() - p2.getAge();
}
}));
System.out.println(max1.orElse(null));
// 方式2:Lambda
Optional<Person> max2 =
list.stream().collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println(max2.orElse(null));
// 方式3:方法引用
Optional<Person> max3 =
list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge)));
System.out.println(max3.orElse(null));
//Optional<Person> max1 =
//list.stream().collect(Collectors.maxBy(Comparator.comparing(Person::getSalary,Double::compareTo)));
// 方式4:IDEA建议直接使用 max(),不要用 collect(Collector)
Optional<Person> max4 = list.stream().max(Comparator.comparingInt(Person::getAge));
System.out.println(max4.orElse(null));
// 特别是方式3和方式4,可以看做collect()聚合和max()聚合的对比
// 剩下的minBy和counting
Optional<Person> min1 =
list.stream().collect(Collectors.minBy(Comparator.comparingInt(Person::getAge)));
Optional<Person> min2 = list.stream().min(Comparator.comparingInt(Person::getAge));
Long count1 = list.stream().collect(Collectors.counting());
Long count2 = list.stream().count();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
分组
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 按字段分组
* 按条件分组
*
* @param args
*/
public static void main(String[] args) {
// GROUP BY address
Map<String, List<Person>> groupingByAddress =
list.stream().collect(Collectors.groupingBy(Person::getAddress));
System.out.println(groupingByAddress);
// GROUP BY address, age
Map<String, Map<Integer, List<Person>>> doubleGroupingBy = list.stream()
.collect(Collectors.groupingBy(Person::getAddress, Collectors.groupingBy(Person::getAge)));
System.out.println(doubleGroupingBy);
// 简单来说,就是collect(groupingBy(xx)) 扩展为 collect(groupingBy(xx, groupingBy(yy))),嵌套分组
// 解决了按字段分组、按多个字段分组,我们再考虑一个问题:有时我们分组的条件不是某个字段,而是某个字段是否满足xx条件
// 比如 年龄大于等于18的是成年人,小于18的是未成年人
Map<Boolean, List<Person>> adultsAndTeenagers = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 18));
System.out.println(adultsAndTeenagers);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
提一句,collect()方法是最为丰富的,可以搭配Collector玩出很多花样,特别是经过各种嵌套组合。本文末尾留了几道思考题,大家到时可以试着做做。
统计
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 统计
* @param args
*/
public static void main(String[] args) {
// 平均年龄
Double averageAge = list.stream().collect(Collectors.averagingInt(Person::getAge));
System.out.println(averageAge);
// 平均薪资
Double averageSalary = list.stream().collect(Collectors.averagingDouble(Person::getSalary));
System.out.println(averageSalary);
// 其他的不演示了,大家自己看api提示。简而言之,就是返回某个字段在某个纬度的统计结果
// 有个更绝的,针对某项数据,一次性返回多个纬度的统计结果:总和、平均数、最大值、最小值、总数,但一般用的很少
IntSummaryStatistics allSummaryData = list.stream().collect(Collectors.summarizingInt(Person::getAge));
long sum = allSummaryData.getSum();
double average = allSummaryData.getAverage();
int max = allSummaryData.getMax();
int min = allSummaryData.getMin();
long count = allSummaryData.getCount();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
flatMap
总的来说,就是flatMap就是把多个流合并成一个流:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9, new ArrayList<>(Arrays.asList("成年人", "学生", "男性"))));
list.add(new Person("am", 19, "温州", 777.7, new ArrayList<>(Arrays.asList("成年人", "打工人", "宇宙最帅"))));
list.add(new Person("iron", 21, "杭州", 888.8, new ArrayList<>(Arrays.asList("喜欢打篮球", "学生"))));
list.add(new Person("man", 17, "宁波", 888.8, new ArrayList<>(Arrays.asList("未成年人", "家里有矿"))));
}
public static void main(String[] args) {
Set<String> allTags =
list.stream().flatMap(person -> person.getTags().stream()).collect(Collectors.toSet());
System.out.println(allTags);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
// 个人标签
private List<String> tags;
}
}
对于每个Person对象中的tags,如果没有flatMap,想要合并去重会比较麻烦。
对比map和flatMap:


flatMap传入的Function要求返回值是Stream<? extends R>而不是R,所以上面写的是:

map是将对象的类型转换,flatMap是将对象的成员属性变为流,集合中的多个流合并为一个流。
去重也可以:
List<String> allTags = list.stream().flatMap(person -> person.getTags().stream()).distinct().toList();
System.out.println(allTags);
总之,当你遇到List中还有List,然后你又想把第二层的List都拎出来集中处理时,就可以考虑用flatMap(),先把层级打平,再统一处理。
peek()

它接受一个Consumer,一般有两种用法:
- 设置值
- 观察数据
设置值的用法:
public class StreamTest {
public static void main(String[] args) {
list.stream().peek(person -> person.setAge(18)).forEach(System.out::println);
}
}
也就是把所有人的年龄设置为18岁。
peek这个单词本身就带有“观察”的意思。

简单来说,就是查看数据,一般实际开发很少用,但可以用来观察数据的流转:
public class StreamTest {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(1, 2, 3);
stream.peek(v-> System.out.print(v+","))
.map(value -> value + 100)
.peek(v-> System.out.print(v+","))
.forEach(System.out::println);
}
}
结果
1,101,101
2,102,102
3,103,103
有没有感到好奇?
用图表示的话,就是这样:

通过peek,我们观察到每一个元素都是逐个通过Stream流的。
为了看得更清楚些,重新写个demo:
public static void main(String[] args) {
Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.filter(v -> v >= 2)
.peek(v -> System.out.print(v + ","))
.filter(v -> v >= 3)
.forEach(System.out::println);
//1,2,2,3,3,3
//4,4,4
}
结果
1,2,2,3,3,3
4,4,4
这打印,怎么这么诡异?
其实不诡异,元素确实是逐个通过的:

一个元素如果中途被过滤,就不会继续往下,换下一个元素。最终串起来,就会打印:
1,2,2,3,3,3
4,4,4
大家思考一下,真正的Stream和我们之前山寨的Stream,遍历时有何不同?能画图解释一下吗?
元素一个个通过关卡
元素一起通过一个个关卡
匹配、查找
findFirst
public static void main(String[] args) {
Optional<Integer> first = Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.findFirst();
}
结果:
1,
只要第一个,后续元素不会继续遍历。找到的元素在Optional中
findAny
public static void main(String[] args) {
Optional<Integer> any = Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.findAny();
}
结果:
1,
findFirst和findAny几乎一样,但如果是并行流,结果可能不一致:

并行流颇有种“分而治之”的味道(底层forkjoin线程池),将流拆分并行处理,能较大限度利用计算资源,提高工作效率。但要注意,如果当前操作对顺序有要求,可能并不适合使用parallelStream。比如上图右边,使用并行流后返回的可能是4而不是1。
关于findFirst()和findAny()有没有人觉得这方法很傻逼?其实是我demo举的不对,通常来说应该是一堆filter操作任取一个等场景下使用。比如list.stream().filter(student->student.getAge()>18).findFirst(),即符合条件的任选一个。
allMatch
public static void main(String[] args) {
boolean b = Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.allMatch(v -> v > 2);
}
结果
1,
由于是要allMatch,第一个就不符合,那么其他元素也就没必要测试了。这是一个短路操作。
就好比:
if(0>1 && 2>1){
// 2>1 不会被执行,因为0>1不成立,所以2>1被短路了
}
noneMatch
public static void main(String[] args) {
boolean b = Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.noneMatch(v -> v >= 2);
}
结果
1,2,
和allMatch一样,它期望的是没有一个满足,而2>=2已经false,后面元素即使都大于2也不影响最终结果:noneMatch=false,所以也是个短路操作。
anyMatch
略
reduce
略,实际开发没用过,大家可以在熟悉上面的用法后再去了解,否则可能比较乱。
Stream API的效率问题
代码见附件:StreamTimeTest.java
大家把测试案例拷贝到本地test包下运行看看,相信心中有判断。虽然上面的案例中没有测试list.stream.filter().map.dictinc()等连环操作,但结果应该差不多。
但我想说的是,绝大部分时候代码的可读性应该优先于性能,况且Stream API性能并不差。和传统代码相比,Stream API让程序员专注于实现的步骤而不是细节,大大提高了代码的可读性。
Integer minPrice = itemSkuPriceTOS.stream()
.sorted(Comparator.comparingLong(ItemSkuPriceTO::getPrice)) // 先正序排列
.findFirst() // 找到第一个,也就是价格最低的item
.map(ItemSkuPriceTO::getPrice) // 得到item的价格
.orElse(0); // 兜底处理
如果你习惯了Stream API,上面的代码在可读性上会比用for循环实现好得多,所以能用Stream API的尽量用Stream API吧。毕竟上面测试用了1000w数据差距也就几十毫秒,更别说实际项目中可能就几十条了。
Stream API练习
实验数据:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("iron", 17, "宁波", 888.8));
}
public static void main(String[] args) {
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}
}
map
获取所有的Person的名字
List<String> personNames = list.stream().map(Person::getName).collect(Collectors.toList());
System.out.println(personNames);
获取一个List,每个元素的内容为:{name}来自{address}
List<String> nameFromAddress = list.stream().map(person -> person.getName() + "来自" + person.getAddress()).collect(Collectors.toList());
System.out.println(nameFromAddress);
filter
过滤出年龄大于等于18 并且 月薪大于等于888.8 并且 来自杭州的Person
// 一般写法(这个filter,完全就是强迫别人花时间从头到尾阅读你代码里的细节,而且毫无提示!)
public static void main(String[] args) {
List<Person> personList = list.stream()
.filter(person -> (person.getAge() >= 18 && person.getSalary() > 888.8 && "杭州".equals(person.getAddres()))
.collect(Collectors.toList());
System.out.println(personList);
}
// 较好的写法:当我们需要给filter()、map()等函数式接口传递Lambda参数时,逻辑如果很复杂,最好抽取成方法,优先保证可读性
public static void main(String[] args) {
List<Person> personList = list.stream()
.filter(StreamTest::isRichAdultInHangZhou) // 改为方法引用,见名知意,隐藏琐碎的细节
.collect(Collectors.toList());
System.out.println(personList);
}
/**
* 是否杭州有钱人
*
* @param person
* @return
*/
private static boolean isRichAdultInHangZhou(Person person) {
return person.getAge() >= 18
&& person.getSalary() > 888.8
&& "杭州".equals(person.getAddres());
}
统计
获取年龄的min、max、sum、average、count。
很多人看到这个问题,会条件反射地想到先用map()把Person降到Age纬度,然后看看有没有类似min()、max()等方法,思路很合理。
然后会发现:map()后只提供了max()、min()和count()三个方法(且max、min需要传递Comparator对象),没有average()和sum()。
为什么会设计得这么“麻烦”且看起来这么不合理呢?
Stream作为接口,首要任务是保证方法通用性。由于Stream需要处理的元素是不确定的,这次是Integer,下次可能是String,甚至是自定义的Person,所以要使用Stream计算min、max时,必须告诉它“怎样才是最大”、“怎样才是最小”,具体到代码里就是策略模式,需要我们传入比较规则,也就是Comparator对象。
这其实是很合理的,比如当我们把两个人进行比较时,其实都是基于某一个/某一组评判标准的,比如外貌方面,我比吴彦祖帅,或者从身高来看,我比姚明高。所有的比较结果,必须在某一个比较规则之下才成立、才有意义。
至于sum()和average(),Stream干脆没定义...这又是为什么?你想想,如果map()后得到的是name,对于字符类型来说sum()和average()是没有意义的,因为你也说不出一串名字的平均值代表着什么。也就是说sum()和average()不是通用的,不应该定义在Stream接口中。
一句话,Stream接口只提供了通用的max()、min()、count(),而且要自己指定Comparator(策略模式)。
但是,如果你能确定元素的类型,比如int、long啥的,那么可以选择对应的mapToInt()、mapToLong()等方法得到具体类型的Stream:


比如得到IntStream后,多了几个方法:

转为具体类型的Stream有以下好处:
- 不用传递Comparator,你都mapToInt()了,那么元素的类型也就确定了,比较的规则自然也确定了(自然数比较)
- 额外新增sum()、average(),因为对于数字类型来说,求和、求平均是有意义的
也就是说,如果你要操作的数据刚好是int、long、double,那么不妨转为IntStream、LongStream、DoubleStream,api会得到相应的增强!
总结:
如果你想要做通用的数据处理,直接使用map()等方法即可,此时返回的是Stream,提供的都是通用的操作。但如果要统计的数据类型恰好是int、long、double,那么使用mapToXxx()方法转为具体的Stream类型后,方法更多更强大,处理起来更为方便!

看到这,大家应该知道这道题这么解了,就不贴代码了。特别注意下最后那个summaryStatistics():五合一。
其实,关于统计的方法,Stream共提供了3大类API,后面会总结。有时选择太多也是一种罪过,难怪有些人会感到混乱。
查找
查找其实分为两大类操作:
- 查找并返回目标值,以findFirst()为代表
- 告诉我有没有即可,无需返回目标值,以anyMatch()为代表
public static void main(String[] args) {
Optional<Person> personMatch = list.stream()
.filter(person -> "宁波".equals(person.getAddress())) // 经过一些筛选,看看有没有符合条件的元素
.findFirst();
personMatch.ifPresent(System.out::println); // 不了解Optional的同学,可以去看后面关于Optional的章节
}
public static void main(String[] args) {
// 但有时候你并不关心符合条件的是哪个或哪些元素,只想知道有没有,此时anyMatch()更合适,代码会精炼很多
boolean exists = list.stream().anyMatch(person -> "宁波".equals(person.getAddress()));
}
其他3个方法:findAny()、noneMatch()、allMatch()就不介绍了。
collect()
最牛逼的一个方法,当你想要实现某种操作却一时找不到具体方法时,一般都是在collect()里,因为它玩法实在太多了!
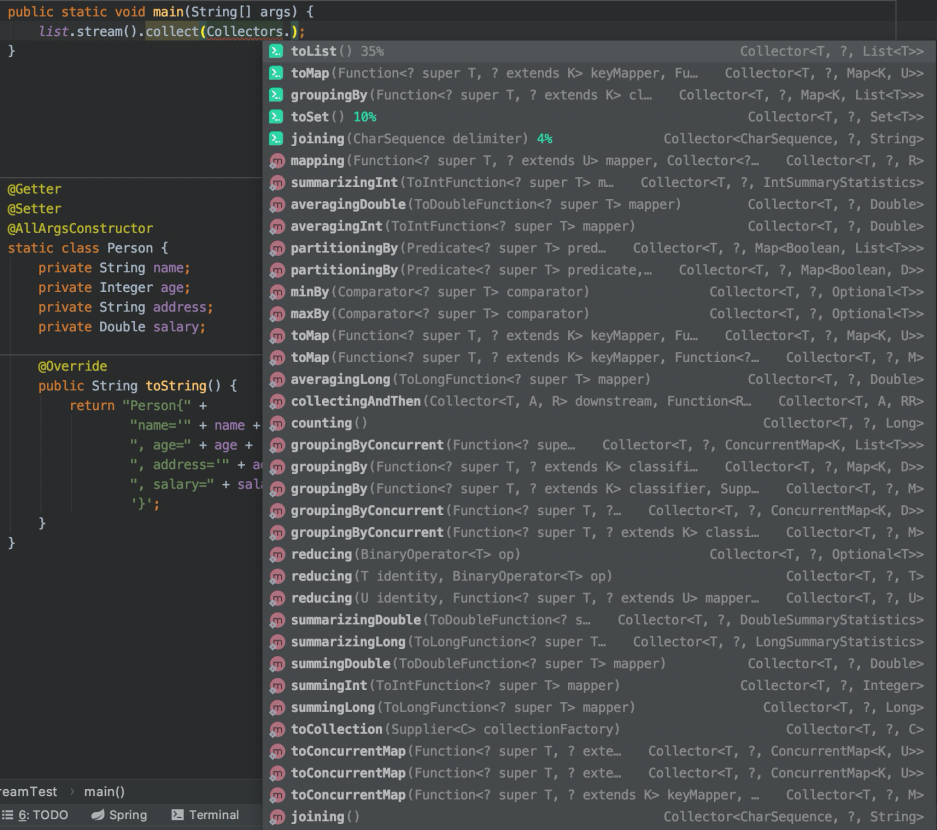
List转List:Collectors.toList()
所谓List转List,一般指的是原List经过filter()、sorted()、map()、limit()等一顿操作后,最终还是以List的形式返回。
public static void main(String[] args) {
List<String> top2Adult = list.stream()
.filter(person -> person.getAge() >= 18) // 过滤得到年龄大于等于18岁的人
.sorted(Comparator.comparingInt(Person::getAge)) // 按年龄排序
.map(Person::getName) // 得到姓名
.limit(2) // 取前两个数据
.collect(Collectors.toList()); // 得到List<String> names
System.out.println(top2Adult);
}
问一个问题:Collectors.toList()默认返回的是ArrayList,如何指定返回LinkedList或其他类型呢?答案见下方练习题。
List转Map:Collectors.toMap()
list转map,一般来说关注两个点:
- 转化后,你要以什么作为key,以什么作为value
- 出现key冲突时怎么解决(保留旧的值还是覆盖旧的值)
public static void main(String[] args) {
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName, // 以name作为key
person -> person, // person->person表示保留整个person作为value
(pre, next) -> pre // (pre, next) -> pre)表示key冲突时保留旧值
));
System.out.println(personMap);
}
// 如果你只需要person的部分数据作为value,比如address
public static void main(String[] args) {
Map<String, String> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Person::getAddress,
(pre, next) -> pre
));
System.out.println(personMap);
}
有时你会见到同事这样写:
public static void main(String[] args) {
// Function.identity() 本质上等于 person->person
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Function.identity()
));
System.out.println(personMap);
}
// Function接口定义的方法
static <T> Function<T, T> identity() {
return t -> t;
}
Function.identity()只是person->person的另类写法,易读性并不好,而且并没有指定key冲突策略:

所以,即使使用Function.identity(),仍需要手动指定key冲突策略:
public static void main(String[] args) {
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Function.identity(), // 看起来很酷,其实就是v->v,甚至不如v->v直观
(pre, next) -> pre
));
System.out.println(personMap);
}
List转Set:Collectors.toSet()
主要目的是利用Set的特性去重。以最常用的HashSet为例,你是否清楚为什么用HashSet存储自定义对象时,要求重写hashCode()和equals()?
因为HashSet本质还是HashMap,只不过HashSet的value是空,只利用了key(HashSet是单列集合,而HashMap是双列集合)。



使用却很简单:
public static void main(String[] args) {
// String、Integer这些类本身重写了hashCode()和equals(),可以直接toSet()
Set<String> names = list.stream().map(Person::getName).collect(Collectors.toSet());
System.out.println(names);
// 如果你要对自定义的对象去重,比如Person,那么你必须重写hashCode()和equals()
Set<Person> persons = list.stream().collect(Collectors.toSet());
System.out.println(persons);
// 一般来说,用到Collectors.toSet()之前,也是filter()等一顿操作,最后希望去重。像上面那样单纯地想得到Set,可以简单点
Set<Person> anotherPersons = new HashSet<>(list);
System.out.println(anotherPersons);
}
@Getter
@Setter
// 利用Lombok的注解,如果有条件建议手写。Lombok默认把所有字段加入计算,但实际上你可能只需要计算id和name就能确定唯一性
@EqualsAndHashCode
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
去重
和Collectors.toSet()一样,但凡要去重,最关键的就是“怎么判断两个对象是否相同”,于是必须明确“怎样才算相同”。在Java中通常有两种做法:
- 重写hashCode()和equals()
- 指定Comparator(比较器)
Java8以后Stream API专门提供了distinct()方法用来去重,底层就是根据元素hashCode()和equals方法判断是否相同,然后再去重。
public static void main(String[] args) {
// 如果不重写Person的hashCode()和equals(),去重无效!!!
List<Person> persons = list.stream().distinct().collect(Collectors.toList());
System.out.println(persons);
}
你可能感到诧异:不对啊,我平时工作就是这么去重的。其实你平时的写法是这样的:
public static void main(String[] args) {
// Integer、String这些基础包装类已经重写了hashCode()和equals()
List<String> personNameList = list.stream().map(Person::getName).distinct().collect(Collectors.toList());
System.out.println(personNameList);
}
有时我们的判断标准是,只要某些字段相同就去重(比如name),该怎么做呢?(注意,我希望的是按name去重,但最终得到的还是PersonList,而不是PersonNameList,所以上面的方法行不通)
第一种办法,仍然重写hashCode()和equals(),但只选择需要的字段(比如你只根据name作为判断标准)。

public static void main(String[] args) {
List<Person> persons = list.stream().distinct().collect(Collectors.toList());
System.out.println(persons);
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
// IDEA自动生成的
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return name.equals(person.name);
}
// IDEA自动生成的
@Override
public int hashCode() {
return Objects.hash(name);
}
// 不用理会,只是方便打印观察
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}
但这个方法有个缺点,如果这个Pojo不止你一个人用,直接重写hashCode()和equals()可能会影响到别人。
另外hashSet、hashMap这种底层是hash结构的容器,在去重时也会依赖hashCode()和equals()。比如你希望根据name去重,而name是String类型,本身是重写了hashCode()和equals()的,那么可以根据name先去重。比如我们可以利用HashMap完成去重(HashSet同理):
public static void main(String[] args) {
// 先通过Map去重,只保留key不同的对象。
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName, // 用person.name做key,由于key不能重复,即根据name去重
p -> p, // map的value就是person对象本身
(pre, next) -> pre // key冲突策略:key冲突时保留前者(根据实际需求调整)
));
// 然后收集value即可(特别注意,hash去重后得到的person不保证原来的顺序)
List<Person> peoples = new ArrayList<>(personMap.values());
System.out.println(peoples);
}
使用linkedHashSet即可保证顺序,使用collectingAndThen就可以将其转变为List集合
可能还有其他方法,但顶多形式看起来不一样,个人认为底层思路都是一样的:hashCode()和equals()。
介绍完hashCode()和equals()这个派系以后,我们再来说说Comparator,尤其是对于TreeSet这样的容器:
public static void main(String[] args) {
// 先把元素赶到TreeSet中(根据Comparator去重),然后再倒腾回ArrayList
List<Person> list = list.stream().collect(
Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
ArrayList::new
)
);
}
在创建集合时通过Supplier<C> collectionFactory 指定创建出一个集合
在TreeSet的构造方法中可以指定比较器,该比较器决定了TreeSet的排序规则
上面介绍的几种方式,去重后顺序会打乱。关于去重后如何保持元素顺序,网上有很多方法:
https://www.cnblogs.com/better-farther-world2099/articles/11905740.html
要做到去重并保持顺序,光靠Stream似乎有点无能为力,也显得比较啰嗦。还记得之前封装的ConvertUtil吗?不妨往里面再加一个方法:
/**
* 去重(保持顺序)
*
* @param originList 原数据
* @param distinctKeyExtractor 去重规则
* @param <T>
* @param <K>
* @return
*/
public static <T, K> List<T> removeDuplication(List<T> originList, Function<T, K> distinctKeyExtractor) {
LinkedHashMap<K, T> resultMap = new LinkedHashMap<>(originList.size());
for (T item : originList) {
K distinctKey = distinctKeyExtractor.apply(item);
if (resultMap.containsKey(distinctKey)) {
continue;
}
resultMap.put(distinctKey, item);
}
return new ArrayList<>(resultMap.values());
}
总的来说,去重通常有两类做法:要么通过重写hashCode和equals,要么传入Comparator(Comparable接口也行)。
其实也是借助了LinkedHashMap的特性来完成排序
分组
Stream的分组有两类操作:
- 字段分组
- 条件分组

先看字段分组。所谓的groupingBy(),和MySQL的GROUP BY很类似,比如:
public static void main(String[] args) throws JsonProcessingException {
// 简单版
Map<String, List<Person>> result = list.stream().collect(Collectors.groupingBy(Person::getAddress));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
得到的结果类似于:
{
"温州": [
{
"name": "am",
"age": 19,
"address": "温州",
"salary": 777.7
}
],
"宁波": [
{
"name": "iron",
"age": 17,
"address": "宁波",
"salary": 888.8
}
],
"杭州": [
{
"name": "i",
"age": 18,
"address": "杭州",
"salary": 999.9
},
{
"name": "iron",
"age": 21,
"address": "杭州",
"salary": 888.8
}
]
}
总的来说,groupingBy()的最终结果是Map,key是分组的字段,value是属于该分组的所有元素集合,默认是List。
为什么我说默认是List呢?因为我们还可以自行指定将分组元素收集成到什么容器中,比如Set:
public static void main(String[] args) throws JsonProcessingException {
// groupingBy()还可以传入第二个参数,指定如何收集元素
Map<String, Set<Person>> result = list.stream()
.collect(Collectors.groupingBy(Person::getAddress, Collectors.toSet()));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
如果你期望得到的是各个城市的年龄构成呢?比如:
{
"温州": [
19
],
"宁波": [
17
],
"杭州": [
18,
21
]
}
做法是,可以把Collectors.toSet()替换成Collectors.mapping(Function mapper,Collector),然后进行嵌套:
public static void main(String[] args) throws JsonProcessingException {
// 进阶版版
Map<String, List<Integer>> result = list.stream().collect(Collectors.groupingBy(
Person::getAddress, // 以Address分组
Collectors.mapping(Person::getAge, Collectors.toList())) // mapping()的做法是先映射再收集
);
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
其他过于复杂的api就不再介绍了,太多了反而会乱。实际开发时,如果遇到某个场景,可以自行百度,一般都能解决问题。总之要记住,collect()里面经常可以通过“套娃”操作完成复杂的需求。
有了这么好用的groupingBy(),为啥还需要partitioningBy()呢?因为groupingBy()也是有局限性的,它不能自定义“分组条件”。比如,如果你的分组条件是:
- 年龄大于18岁 && 来自杭州 的分为一组
- 其他的分为另一组
那么groupingBy()就无能为力了。
此时,支持自定义分组条件的partitioningBy()就派上用场:
public static void main(String[] args) throws JsonProcessingException {
// 简单版
Map<Boolean, List<Person>> result =
list.stream().collect(Collectors.partitioningBy(StreamTest::condition));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
// 年龄大于18,且来自杭州
private static boolean condition(Person person) {
return person.getAge() > 18
&& "杭州".equals(person.getAddress());
}
{
"false": [
{
"name": "i",
"age": 18,
"address": "杭州",
"salary": 999.9
},
{
"name": "am",
"age": 19,
"address": "温州",
"salary": 777.7
},
{
"name": "iron",
"age": 17,
"address": "宁波",
"salary": 888.8
}
],
"true": [
{
"name": "iron",
"age": 21,
"address": "杭州",
"salary": 888.8
}
]
}
partitioningBy()也返回Map,但key是true/false,因为条件分组的依据要么true、要么false。partitioningBy()也支持各种嵌套,大家自己尝试即可。
排序
说到排序,大家最先想到的是Stream API中的sorted(),共有两个方法,其中一个支持传入Comparator:

排序的前提是比较,而只要涉及到比较,就必须明确比较的标准是什么。
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}
大家猜猜上面代码的运行结果是什么?
答案是:ClassCastException。
在学习Java基础时,我们了解到,如果希望进行对象间的比较:
- 要么对象实现Comparable接口(对象自身可比较)
- 要么传入Comparator进行比较(引入中介,帮对象们进行比较)
就好比你和朋友进行100米比赛,要么你们自己计时,要么请个裁判。而上面sorted()既然没有传入Comparator,那么Person要实现Comparable接口:
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}
@Getter
@Setter
@EqualsAndHashCode
@AllArgsConstructor
static class Person implements Comparable<Person> {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
// 定义比较规则
@Override
public int compareTo(Person anotherPerson) {
return anotherPerson.getAge() - this.getAge();
}
}
sorted()容易采坑而且语义不够明确,个人建议使用sort(Comparator),显式地传入比较器:
public class ComparatorTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, 170));
list.add(new Person("am", 19, 180));
list.add(new Person("am", 20, 180));
list.add(new Person("iron", 19, 181));
list.add(new Person("iron", 19, 179));
list.add(new Person("man", 17, 160));
list.add(new Person("man", 16, 160));
}
public static void main(String[] args) {
// 先按身高降序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge).reversed());
System.out.println(list);
// 先按身高升序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高降序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).reversed().thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高升序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparing(Person::getAge, Comparator.reverseOrder()));
System.out.println(list);
/**
* 大家可以理解为Comparator要实现排序可以有两种方式:
* 1、comparingInt(keyExtractor)、comparingLong(keyExtractor)... + reversed()表示倒序,默认正序
* 2、comparing(keyExtractor, Comparator.reverseOrder()),不传Comparator.reverseOrder()表示正序
*
* 第四个需求如果采用reversed(),似乎达不到效果,反正我没查到。
* 个人建议,单个简单的排序,无论正序倒序,可以使用第一种,简单一些。但如果涉及多个联合排序,建议使用第二种,语义明确不易搞错。
*
* 最后,上面是直接使用Collection的sort()方法,请大家自行改成Stream中的sorted()实现一遍。
*/
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private Integer height;
}
}
截取
对于List的截取,可能大家都习惯用List.subList(),但它有个隐形的坑:对截取后的List进行元素修改,会影响原List(除非你就希望改变原List)。
究其原因,subList()并非真的从原List截取出元素,而是偏移原List的访问坐标罢了,SubList的get方法:

比如你要截取(5, 6),那么下次你get(index),我就直接返回5+index给你,看起来好像真的截取了。
另外,这个方法限制太大,用起来也麻烦,比如对于一个不确定长度的原List,如果你想做以下截取操作:list.subList(0, 5)或者list.subList(2, 5),当原List长度不满足List.size()>=5时,会抛异常。为了避免误操作,你必须先判断size:
if(list != null && list.size()>=5) {
return list.subList(2, 5);
}
较为简便和安全的做法是借助Stream(Stream一个很重要的特性是,不修改原数据,而是新产生一个流):
public static void main(String[] args) {
List<String> list = Lists.newArrayList("a", "b", "c", "d");
List<String> limit3 = list.stream().limit(3).collect(Collectors.toList());
// 超出实际长度也不会报错
List<String> limit5 = list.stream().limit(5).collect(Collectors.toList());
List<String> range3_4 = list.stream().skip(2).limit(2).collect(Collectors.toList());
// 超出实际长度也不会报错
List<String> range3_5 = list.stream().skip(2).limit(3).collect(Collectors.toList());
System.out.println(limit3 + " " + limit5 + " " + range3_4 + " " + range3_5);
}
多用Stream
Stream有个很重要的特性,常常被人忽略:Stream操作并不改变原数据。这个特性有什么用呢?
假设有两个List,AList和BList。AList固定10个元素,BList元素长度不固定,0~10个。
要求:
要把AList和BList合并,BList的元素在前,合并后的List不能有重复元素(过滤AList),且不改变两个List原有元素的顺序。
你可以先思考一下怎么处理。
之前介绍过List转Map然后利用Key去重的方法,但转Map后元素顺序可能会打乱,为了保证顺序,你可能会选择双层for:
for (int i = aList.size() - 1; i >= 0; i--) {
for (Item bItem : bList) {
// 注意,思考一下aItem.get(i)有没有问题
if (Objects.equals(bItem.getItemId(), aList.get(i).getItemId())) {
aList.remove(i);
}
}
}
// bList在前
bList.addAll(aList);
当aList.remove(i)以后,第二层for又执行aList.get(i)就有可能造成数组越界异常,比如aList.remove(9),移除第10个元素,但第二层for在下一轮还是aList.get(9),此时aList其实只有9个元素。改进的写法可以是这样:
for (int i = aList.size() - 1; i >= 0; i--) {
// 在第一层for取出aItem,且只取一次
Item aItem = aList.get(i);
for (Item bItem : bList) {
if (Objects.equals(bItem.getItemId(), aItem.getItemId())) {
aList.remove(i);
}
}
}
// bList在前
bList.addAll(aList);
但这样不够直观,而且下次再有类似需求,可能还是心惊胆战。此时使用Stream可以编写出更为安全、易读的代码:
Map<String, Item> bItemMap = ConvertUtil.listToMap(bList, Item::getItemId);
// 对aList去重(收集bList中没有的元素)
aList = aList.stream().filter(aItem -> !bItemMap.contains(aItem.getItemId())).collect(Collectors.toList());
// bList在前
bList.addAll(aList);
当然,List其实也提供了取并集、差集的方法,只不过上面的做法会更通用一些,但这不是重点。这里主要是想提醒大家,对于原数组的增删改操作一不小心会带来意想不到的问题,比如数组越界、并发修改异常等,此时用Stream往往是更安全的做法。
总结
- filter()、map()如果逻辑过长,最好抽取函数
- IntStream、LongStream、DoubleStream在统计方面比Stream方法更丰富,更好用
- collect()是最强大的,但一般掌握上面6种情景问题不大
- 去重的原理是利用hashCode()和equals()来确定两者是否相同,无论是自定义对象还是String、Integer等常用内置对象,皆是如此
- 排序的原理是,要么自身实现Comparable接口,要么传入Comparator对象,总之要明确比较的规则
- 平时可能觉得skip()、limit()用不到,但需要截取List或者内存分页时,可以尝试一下
- 尽量用Stream代替List原生操作,代码健壮性和可读性都会提升一个台阶
- flatMap
public class FlatMapTest {
/**
* 需求:
* 1.要求返回所有的key,格式为 list<Long> 提示:keyset
* 2.要求最终返回所有value,格式为 List<Long> 提示:flatMap(),Function需要啥你就转成啥
*
* @param args
*/
public static void main(String[] args) {
Map<Long, List<Long>> map = new HashMap<>();
map.put(1L, new ArrayList<>(Arrays.asList(1L, 2L, 3L)));
map.put(2L, new ArrayList<>(Arrays.asList(4L, 5L, 6L)));
}
}
List<Long> keys = map.keySet().stream().toList();
System.out.println(keys);
List<Long> values = map.keySet().stream().flatMap(key -> map.get(key).stream()).toList();
System.out.println(values);
//更好的方法
List<Long> valueList = map.values().stream().flatMap(Collection::stream).collect(Collectors.toList());
- 分组统计:
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
1.要求分组统计出各个城市的年龄总和,返回格式为 Map<String, Integer>。
Map<String, Integer> ageSumByCity = list.stream().collect(Collectors
.groupingBy(Person::getAddress,
Collectors.mapping(Function.identity(), Collectors.summingInt(Person::getAge))));
System.out.println(ageSumByCity);
2.要求得到Map<城市, List<用户工资>>
Map<String, List<Double>> salaryListByCity = list.stream()
.collect(Collectors.groupingBy(Person::getAddress,
Collectors.mapping(Person::getSalary, Collectors.toList())));
System.out.println(salaryListByCity);
- 实际开发遇到的问题:处理优惠券信息

public class CouponTest {
public static void main(String[] args) throws JsonProcessingException {
List<CouponResponse> coupons = getCoupons();
// TODO 对优惠券统计数量
//1. 不使用Stream,直接new HashMap操作
//2. hashMap + stream
List<CouponResponse> coupons = getCoupons();
coupons.stream()
.collect(Collectors.toMap(CouponResponse::getId, couponResponse -> {
CouponInfo couponInfo = new CouponInfo();
couponInfo.setId(couponResponse.getId());
couponInfo.setName(couponResponse.getName());
couponInfo.setNum(1);
couponInfo.setCondition(couponResponse.getCondition());
couponInfo.setDenominations(couponResponse.getDenominations());
return couponInfo;
},(pre,next) ->{
pre.setNum(pre.getNum() + 1);
return pre;
}));
}
private static List<CouponResponse> getCoupons() {
return Lists.newArrayList(
new CouponResponse(1L, "满5减4", 500L, 400L),
new CouponResponse(1L, "满5减4", 500L, 400L),
new CouponResponse(2L, "满10减9", 1000L, 900L),
new CouponResponse(3L, "满60减50", 6000L, 5000L)
);
}
@Data
@AllArgsConstructor
static class CouponResponse {
private Long id;
private String name;
private Long condition;
private Long denominations;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
static class CouponInfo {
private Long id;
private String name;
private Integer num;
private Long condition;
private Long denominations;
}
}