https://plantegg.github.io/2023/04/16/%E6%AF%94%E8%BE%83%E4%B8%8D%E5%90%8CCPU%E4%B8%8B%E7%9A%84%E5%88%86%E6%94%AF%E9%A2%84%E6%B5%8B/
目的
本文通过一段对分支预测是否友好的代码来验证 branch load miss 差异,已经最终带来的 性能差异。同时在x86和aarch64 下各选几款CPU共5款进行差异性对比
CPU 情况
intel x86
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 1 Core(s) per socket: 24 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz Stepping: 4 CPU MHz: 2500.195 CPU max MHz: 3100.0000 CPU min MHz: 1000.0000 BogoMIPS: 4998.89 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 33792K NUMA node0 CPU(s): 0-23 NUMA node1 CPU(s): 24-47 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch ida arat epb invpcid_single pln pts dtherm spec_ctrl ibpb_support tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt avx512f avx512dq rdseed adx smap clflushopt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local cat_l3 mba |
hygon 7260
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 43 bits physical, 48 bits virtual CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 1 Core(s) per socket: 24 Socket(s): 2 NUMA node(s): 8 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 7260 24-core Processor Stepping: 1 Frequency boost: enabled CPU MHz: 1069.534 CPU max MHz: 2200.0000 CPU min MHz: 1200.0000 BogoMIPS: 4399.38 Virtualization: AMD-V L1d cache: 32K L1i cache: 64K L2 cache: 512K L3 cache: 8192K NUMA node0 CPU(s): 0-5 NUMA node1 CPU(s): 6-11 NUMA node2 CPU(s): 12-17 NUMA node3 CPU(s): 18-23 NUMA node4 CPU(s): 24-29 NUMA node5 CPU(s): 30-35 NUMA node6 CPU(s): 36-41 NUMA node7 CPU(s): 42-47 |
ARM 鲲鹏920
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #lscpu Architecture: aarch64 Byte Order: Little Endian CPU(s): 96 On-line CPU(s) list: 0-95 Thread(s) per core: 1 Core(s) per socket: 48 Socket(s): 2 NUMA node(s): 4 Model: 0 CPU max MHz: 2600.0000 CPU min MHz: 200.0000 BogoMIPS: 200.00 L1d cache: 64K L1i cache: 64K L2 cache: 512K L3 cache: 24576K NUMA node0 CPU(s): 0-23 NUMA node1 CPU(s): 24-47 NUMA node2 CPU(s): 48-71 NUMA node3 CPU(s): 72-95 Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm |
ARM M710
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #lscpu Architecture: aarch64 Byte Order: Little Endian CPU(s): 128 On-line CPU(s) list: 0-127 Thread(s) per core: 1 Core(s) per socket: 128 Socket(s): 1 NUMA node(s): 2 Model: 0 BogoMIPS: 100.00 L1d cache: 64K L1i cache: 64K L2 cache: 1024K L3 cache: 65536K NUMA node0 CPU(s): 0-63 NUMA node1 CPU(s): 64-127 Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma lrcpc dcpop sha3 sm3 sm4 asimddp sha512 sve asimdfhm dit uscat ilrcpc flagm ssbs sb dcpodp sve2 sveaes svepmull svebitperm svesha3 svesm4 flagm2 frint svei8mm svebf16 i8mm bf16 dgh |
ARM FT S2500
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | #lscpu Architecture: aarch64 Byte Order: Little Endian CPU(s): 128 On-line CPU(s) list: 0-127 Thread(s) per core: 1 Core(s) per socket: 64 Socket(s): 2 NUMA node(s): 16 Model: 3 BogoMIPS: 100.00 L1d cache: 32K L1i cache: 32K L2 cache: 2048K L3 cache: 65536K NUMA node0 CPU(s): 0-7 NUMA node1 CPU(s): 8-15 NUMA node2 CPU(s): 16-23 NUMA node3 CPU(s): 24-31 NUMA node4 CPU(s): 32-39 NUMA node5 CPU(s): 40-47 NUMA node6 CPU(s): 48-55 NUMA node7 CPU(s): 56-63 NUMA node8 CPU(s): 64-71 NUMA node9 CPU(s): 72-79 NUMA node10 CPU(s): 80-87 NUMA node11 CPU(s): 88-95 NUMA node12 CPU(s): 96-103 NUMA node13 CPU(s): 104-111 NUMA node14 CPU(s): 112-119 NUMA node15 CPU(s): 120-127 Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid |
测试代码
对一个数组中较大的一半的值累加:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | #include <algorithm> #include <ctime> #include <iostream> int main() { // 随机产生整数,用分区函数填充,以避免出现分桶不均 const unsigned arraySize = 32768; int data[arraySize]; for (unsigned c = 0; c < arraySize; ++c) data[c] = std::rand() % 256; //排序后数据有序,CPU可以准确预测到if的分支 std::sort(data, data + arraySize); //预先排序,也可以注释掉,注释掉表示随机乱序几乎无法预测 // 测试部分 clock_t start = clock(); long long sum = 0; for (unsigned i = 0; i < 100000; ++i) { // 主要计算部分,选一半元素参与计算 for (unsigned c = 0; c < arraySize; ++c) { if (data[c] >= 128) sum += data[c]; } } double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC; std::cout << elapsedTime << std::endl; std::cout << "sum = " << sum << std::endl; } |
以上代码可以注释掉第15行,也就是不对代码排序直接累加,不排序的话 if (data[c] >= 128) 有50% 概率成立,排序后前一半元素if都不成立,后一半元素if都成立,导致CPU流水线很好预测后面的代码,可以提前加载运算打高IPC
测试结果
aarch64 鲲鹏920
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort 11.44 sum = 314931600000 470,740 branch-misses (59.99%) 29,716,627,485 bus-cycles # 2595.890 M/sec (60.03%) 96,469,435 cache-misses # 0.420 % of all cache refs (60.03%) 22,984,316,728 cache-references # 2007.791 M/sec (60.03%) 29,716,018,641 cpu-cycles # 2.596 GHz (65.02%) 83,666,813,837 instructions # 2.82 insn per cycle # 0.10 stalled cycles per insn (65.02%) 8,765,807,804 stalled-cycles-backend # 29.50% backend cycles idle (65.02%) 8,917,112 stalled-cycles-frontend # 0.03% frontend cycles idle (65.02%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 5 context-switches # 0.000 K/sec 11,447.57 msec cpu-clock # 1.000 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 132 minor-faults # 0.012 K/sec 132 page-faults # 0.012 K/sec 11,447.57 msec task-clock # 1.000 CPUs utilized 96,471,779 L1-dcache-load-misses # 0.42% of all L1-dcache accesses (65.02%) 22,985,408,745 L1-dcache-loads # 2007.886 M/sec (65.02%) 96,472,614 L1-dcache-store-misses # 8.427 M/sec (65.02%) 22,986,056,706 L1-dcache-stores # 2007.943 M/sec (65.02%) 184,402 L1-icache-load-misses # 0.00% of all L1-icache accesses (65.02%) 14,779,996,797 L1-icache-loads # 1291.104 M/sec (64.99%) 330,651 branch-load-misses # 0.029 M/sec (64.96%) 6,561,353,921 branch-loads # 573.166 M/sec (64.96%) 3,464,612 dTLB-load-misses # 0.02% of all dTLB cache accesses (64.96%) 23,008,097,187 dTLB-loads # 2009.868 M/sec (59.96%) 745 iTLB-load-misses # 0.00% of all iTLB cache accesses (59.96%) 14,779,577,851 iTLB-loads # 1291.067 M/sec (59.96%) #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./beforesort 30.92 sum = 314931600000 1,639,558,981 branch-misses (59.96%) 80,284,783,419 bus-cycles # 2595.949 M/sec (59.96%) 118,459,436 cache-misses # 0.356 % of all cache refs (59.96%) 33,285,701,200 cache-references # 1076.269 M/sec (59.96%) 80,283,427,379 cpu-cycles # 2.596 GHz (64.96%) 83,694,841,472 instructions # 1.04 insn per cycle # 0.11 stalled cycles per insn (64.98%) 8,849,746,372 stalled-cycles-backend # 11.02% backend cycles idle (64.99%) 8,064,207,583 stalled-cycles-frontend # 10.04% frontend cycles idle (65.00%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 10 context-switches # 0.000 K/sec 30,926.95 msec cpu-clock # 1.000 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 133 minor-faults # 0.004 K/sec 133 page-faults # 0.004 K/sec 30,926.95 msec task-clock # 1.000 CPUs utilized 118,445,576 L1-dcache-load-misses # 0.36% of all L1-dcache accesses (65.02%) 33,286,586,418 L1-dcache-loads # 1076.297 M/sec (65.03%) 118,441,599 L1-dcache-store-misses # 3.830 M/sec (65.04%) 33,286,751,407 L1-dcache-stores # 1076.302 M/sec (65.05%) 410,040 L1-icache-load-misses # 0.00% of all L1-icache accesses (65.05%) 51,611,031,810 L1-icache-loads # 1668.805 M/sec (65.04%) 1,639,731,725 branch-load-misses # 53.020 M/sec (65.03%) 7,520,634,791 branch-loads # 243.174 M/sec (65.02%) 3,536,061 dTLB-load-misses # 0.01% of all dTLB cache accesses (65.00%) 47,898,134,543 dTLB-loads # 1548.751 M/sec (59.99%) 2,529 iTLB-load-misses # 0.00% of all iTLB cache accesses (59.97%) 51,612,575,118 iTLB-loads # 1668.854 M/sec (59.96%) |
以上在相同CPU下数据对比可以看到核心差异是branch-load-misses和branch-misses,当然最终也体现在 IPC 数值上,排序后IPC更高不是因为数据有序取起来更快,而是因为执行逻辑更容易提前预测,也就是可以提前加载if代码到cache中。符合预期
aarch64 M710
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort 8.20237 sum = 314931600000 912,836 branch-misses (29.86%) 22,560,165,604 bus-cycles # 2748.461 M/sec (29.91%) 205,068,961 cache-misses # 0.892 % of all cache refs (29.96%) 22,998,186,284 cache-references # 2801.824 M/sec (30.01%) 22,559,518,941 cpu-cycles # 2.748 GHz (35.03%) 77,068,271,833 instructions # 3.42 insn per cycle # 0.06 stalled cycles per insn (35.08%) 4,892,933,264 stalled-cycles-backend # 21.69% backend cycles idle (35.13%) 1,103,203,963 stalled-cycles-frontend # 4.89% frontend cycles idle (35.13%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 17 context-switches # 0.002 K/sec 8,208.29 msec cpu-clock # 1.000 CPUs utilized 3 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 227 minor-faults # 0.028 K/sec 227 page-faults # 0.028 K/sec 8,208.30 msec task-clock # 1.000 CPUs utilized 205,384,990 L1-dcache-load-misses # 0.89% of all L1-dcache accesses (35.13%) 22,997,494,522 L1-dcache-loads # 2801.739 M/sec (35.13%) 66,804 L1-icache-load-misses # 0.00% of all L1-icache accesses (35.13%) 15,486,704,750 L1-icache-loads # 1886.715 M/sec (30.12%) 76,066 LLC-load-misses # 0.00% of all LL-cache accesses (30.09%) 0 LLC-loads # 0.000 K/sec (30.03%) 672,231 branch-load-misses # 0.082 M/sec (29.98%) 9,844,109,024 branch-loads # 1199.288 M/sec (29.93%) 107,198 dTLB-load-misses # 0.00% of all dTLB cache accesses (29.89%) 22,998,647,232 dTLB-loads # 2801.880 M/sec (29.84%) 9,497 iTLB-load-misses # 0.08% of all iTLB cache accesses (29.81%) 11,755,825 iTLB-loads # 1.432 M/sec (29.82%) 8.210235171 seconds time elapsed #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./beforesort 16.8872 sum = 314931600000 1,229,182,485 branch-misses (29.93%) 46,401,675,872 bus-cycles # 2747.200 M/sec (29.95%) 206,116,950 cache-misses # 0.546 % of all cache refs (29.97%) 37,773,036,315 cache-references # 2236.343 M/sec (30.01%) 46,410,071,081 cpu-cycles # 2.748 GHz (35.03%) 77,083,625,280 instructions # 1.66 insn per cycle # 0.06 stalled cycles per insn (35.07%) 1,961,071,890 stalled-cycles-backend # 4.23% backend cycles idle (35.11%) 4,988,241,014 stalled-cycles-frontend # 10.75% frontend cycles idle (35.11%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 1,100 context-switches # 0.065 K/sec 16,890.39 msec cpu-clock # 0.997 CPUs utilized 7 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 229 minor-faults # 0.014 K/sec 229 page-faults # 0.014 K/sec 16,890.69 msec task-clock # 0.997 CPUs utilized 205,761,970 L1-dcache-load-misses # 0.54% of all L1-dcache accesses (35.09%) 37,832,336,945 L1-dcache-loads # 2239.854 M/sec (35.06%) 207,158 L1-icache-load-misses # 0.00% of all L1-icache accesses (35.04%) 41,944,228,741 L1-icache-loads # 2483.298 M/sec (30.00%) 135,144 LLC-load-misses # 0.00% of all LL-cache accesses (29.97%) 0 LLC-loads # 0.000 K/sec (29.97%) 1,232,325,180 branch-load-misses # 72.960 M/sec (29.96%) 14,776,289,690 branch-loads # 874.827 M/sec (29.96%) 177,790 dTLB-load-misses # 0.00% of all dTLB cache accesses (29.97%) 37,839,288,998 dTLB-loads # 2240.266 M/sec (29.95%) 46,301 iTLB-load-misses # 0.00% of all iTLB cache accesses (29.94%) 12,631,307,441 iTLB-loads # 747.833 M/sec (29.92%) 16.943678377 seconds time elapsed |
M710上排序与否和鲲鹏差不多,但是 M710比 鲲鹏要快一些,差别只要有主频高一点点(6%),另外M710编译后的指令数量也略少(8%)。
最大的差别是没有排序的话 branch-load-misses(1,232,325,180)/branch-loads(14,776,289,690) 比例只有鲲鹏的50%,导致整体 IPC 比鲲鹏高不少(1.66 VS 1.04)
如果是排序后的数据来看 M710比鲲鹏好40%,IPC 好了20%,iTLB-loads 差异特别大
aarch64 FT S2500
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses ./aftersort 16.63 sum = 314931600000 1,298,873 branch-misses # 0.078 M/sec (37.49%) 34,893,306,641 bus-cycles # 2096.049 M/sec (37.51%) 211,447,452 cache-misses # 0.913 % of all cache refs (37.53%) 23,154,909,673 cache-references # 1390.921 M/sec (37.54%) 34,891,766,353 cpu-cycles # 2.096 GHz (43.79%) 83,918,069,835 instructions # 2.41 insns per cycle (43.79%) 0 alignment-faults # 0.000 K/sec 102 context-switches # 0.006 K/sec 16647.131540 cpu-clock (msec) 35 cpu-migrations # 0.002 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 384 minor-faults # 0.023 K/sec 384 page-faults # 0.023 K/sec 16647.178560 task-clock (msec) # 1.000 CPUs utilized 211,277,069 L1-dcache-load-misses # 0.91% of all L1-dcache hits (43.79%) 23,168,806,437 L1-dcache-loads # 1391.756 M/sec (43.77%) 211,376,611 L1-dcache-store-misses # 12.697 M/sec (43.75%) 23,172,492,978 L1-dcache-stores # 1391.977 M/sec (43.73%) 6,060,438 L1-icache-load-misses # 0.364 M/sec (43.72%) 23,283,174,318 L1-icache-loads # 1398.626 M/sec (37.48%) 1,201,268 branch-load-misses # 0.072 M/sec (37.47%) 6,626,003,512 branch-loads # 398.026 M/sec (37.47%) 4,417,981 dTLB-load-misses # 0.265 M/sec (37.47%) 58,242 iTLB-load-misses # 0.003 M/sec (37.47%) #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses ./beforesort 39.8 sum = 314931600000 1,641,714,982 branch-misses # 41.244 M/sec (37.50%) 83,450,971,727 bus-cycles # 2096.514 M/sec (37.51%) 209,942,920 cache-misses # 0.625 % of all cache refs (37.51%) 33,584,108,027 cache-references # 843.724 M/sec (37.51%) 83,446,991,284 cpu-cycles # 2.096 GHz (43.76%) 83,872,213,462 instructions # 1.01 insns per cycle (43.75%) 0 alignment-faults # 0.000 K/sec 165 context-switches # 0.004 K/sec 39804.395840 cpu-clock (msec) 104 cpu-migrations # 0.003 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 728 minor-faults # 0.018 K/sec 728 page-faults # 0.018 K/sec 39804.626860 task-clock (msec) # 1.000 CPUs utilized 209,884,485 L1-dcache-load-misses # 0.62% of all L1-dcache hits (43.75%) 33,591,847,895 L1-dcache-loads # 843.918 M/sec (43.75%) 209,796,158 L1-dcache-store-misses # 5.271 M/sec (43.75%) 33,595,628,139 L1-dcache-stores # 844.013 M/sec (43.75%) 5,575,802 L1-icache-load-misses # 0.140 M/sec (43.75%) 68,272,798,305 L1-icache-loads # 1715.198 M/sec (37.50%) 1,642,653,627 branch-load-misses # 41.268 M/sec (37.50%) 6,846,418,902 branch-loads # 172.001 M/sec (37.50%) 4,162,728 dTLB-load-misses # 0.105 M/sec (37.50%) 57,375 iTLB-load-misses # 0.001 M/sec (37.50%) |
Intel x86 8163
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./aftersort 9.77 sum = 314931600000 6,541,060,672 branch-instructions # 669.204 M/sec (10.72%) 727,847 branch-misses # 0.01% of all branches (14.30%) 241,730,862 bus-cycles # 24.731 M/sec (17.88%) 275,443 cache-misses # 44.685 % of all cache refs (21.45%) 616,413 cache-references # 0.063 M/sec (25.03%) 24,186,369,646 cpu-cycles # 2.474 GHz (28.60%) 29,491,804,977 instructions # 1.22 insns per cycle (32.18%) 24,198,780,299 ref-cycles # 2475.731 M/sec (35.75%) 0 alignment-faults # 0.000 K/sec 16 context-switches # 0.002 K/sec 9774.393202 cpu-clock (msec) 8 cpu-migrations # 0.001 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 490 minor-faults # 0.050 K/sec 490 page-faults # 0.050 K/sec 9774.396556 task-clock (msec) # 1.001 CPUs utilized 74,078,676 L1-dcache-load-misses # 1.64% of all L1-dcache hits (189256748561.94%) 4,515,522,850 L1-dcache-loads # 461.975 M/sec (189237344482.16%) 3,798,032 L1-dcache-stores # 0.389 M/sec (189217941721.85%) 1,077,146 L1-icache-load-misses # 0.110 M/sec (189198537875.18%) 89,144 LLC-load-misses # 74.54% of all LL-cache hits (189179139811.86%) 119,586 LLC-loads # 0.012 M/sec (189159737036.24%) 3,450 LLC-store-misses # 0.353 K/sec (189140342885.02%) 105,021 LLC-stores # 0.011 M/sec (7.15%) 458,465 branch-load-misses # 0.047 M/sec (10.73%) 6,557,558,579 branch-loads # 670.891 M/sec (14.30%) 733 dTLB-load-misses # 0.00% of all dTLB cache hits (17.87%) 12,039,967,837 dTLB-loads # 1231.786 M/sec (21.44%) 104 dTLB-store-misses # 0.011 K/sec (25.01%) 7,040,783 dTLB-stores # 0.720 M/sec (28.58%) 763 iTLB-load-misses # 62.80% of all iTLB cache hits (28.56%) 1,215 iTLB-loads # 0.124 K/sec (28.55%) 168,588 node-load-misses # 0.017 M/sec (28.55%) 131,578 node-loads # 0.013 M/sec (28.55%) 4,484 node-store-misses # 0.459 K/sec (7.14%) 42 node-stores # 0.004 K/sec (7.14%) #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./beforesort 29.52 sum = 314931600000 6,565,036,614 branch-instructions # 222.370 M/sec (10.72%) 1,599,826,737 branch-misses # 24.37% of all branches (14.29%) 730,977,010 bus-cycles # 24.760 M/sec (17.86%) 920,858 cache-misses # 48.057 % of all cache refs (21.43%) 1,916,178 cache-references # 0.065 M/sec (25.00%) 73,123,904,158 cpu-cycles # 2.477 GHz (28.57%) 29,618,485,912 instructions # 0.41 insns per cycle (32.14%) 73,152,861,566 ref-cycles # 2477.828 M/sec (35.72%) 0 alignment-faults # 0.000 K/sec 26 context-switches # 0.001 K/sec 29522.972689 cpu-clock (msec) 13 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 593 minor-faults # 0.020 K/sec 593 page-faults # 0.020 K/sec 29522.976661 task-clock (msec) # 1.001 CPUs utilized 76,164,025 L1-dcache-load-misses # 1.68% of all L1-dcache hits (62596004730.92%) 4,521,935,099 L1-dcache-loads # 153.167 M/sec (62593882213.79%) 1,170,288 L1-dcache-stores # 0.040 M/sec (62591759384.11%) 2,975,318 L1-icache-load-misses # 0.101 M/sec (62591281765.29%) 178,510 LLC-load-misses # 66.98% of all LL-cache hits (62591281765.30%) 266,514 LLC-loads # 0.009 M/sec (62591281765.18%) 6,841 LLC-store-misses # 0.232 K/sec (62591578887.87%) 335,369 LLC-stores # 0.011 M/sec (7.15%) 1,600,893,693 branch-load-misses # 54.225 M/sec (10.72%) 6,565,516,562 branch-loads # 222.387 M/sec (14.29%) 33,070 dTLB-load-misses # 0.00% of all dTLB cache hits (17.87%) 12,043,088,689 dTLB-loads # 407.923 M/sec (21.44%) 180 dTLB-store-misses # 0.006 K/sec (25.01%) 2,359,365 dTLB-stores # 0.080 M/sec (28.58%) 9,399 iTLB-load-misses # 849.82% of all iTLB cache hits (28.58%) 1,106 iTLB-loads # 0.037 K/sec (28.58%) 439,052 node-load-misses # 0.015 M/sec (28.58%) 367,546 node-loads # 0.012 M/sec (28.58%) 7,539 node-store-misses # 0.255 K/sec (7.15%) 1,736 node-stores # 0.059 K/sec (7.14%) |
从 x86 和 aarch 对比来看,x86 编译后的指令数是 aarch 的35%,ARM 是精简指令,数量多比较好理解。主频2.5 GHz 较 M710低了11%。
IPC 差异比较大,有一部分是因为 ARM 精简指令本来有较高的 IPC。
从排序前的差异来看除了指令集外导致 IPC 较高的原因主要也是 branch-load-misses(1,232,325,180)/branch-loads(14,776,289,690) 比 intel的 1,602,020,038/6,568,921,480, 也就是 M710的 branch miss 率比 intel 低了一倍。
排序后去掉了 branch miss 差异,M710 比 intel 快了 10%,只要是因为主频的差异
on 8269 3.2GHz
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #perf stat -e branch-instructions,branch-misses,cpu-cycles,instructions,branch-load-misses,branch-loads,task-clock,cpu-clock ./beforesort 22.96 sum = 314931600000 Performance counter stats for './beforesort': 6,573,626,859 branch-instructions # 286.177 M/sec (83.33%) 1,602,898,541 branch-misses # 24.38% of all branches (83.33%) 73,189,204,878 cpu-cycles # 3.186 GHz (66.67%) 29,627,520,323 instructions # 0.40 insns per cycle (83.33%) 1,602,848,454 branch-load-misses # 69.779 M/sec (83.33%) 6,572,915,651 branch-loads # 286.146 M/sec (83.33%) 22970.482491 task-clock (msec) # 1.001 CPUs utilized 22970.482557 cpu-clock (msec) |
hygon 7260
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | #perf stat -e branch-instructions,branch-misses,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort 10.9479 sum = 314931600000 9,848,123,830 branch-instructions # 898.161 M/sec (26.26%) 496,734 branch-misses # 0.01% of all branches (26.30%) 713,235 cache-misses # 0.336 % of all cache refs (26.34%) 212,455,257 cache-references # 19.376 M/sec (26.37%) 27,277,461,559 cpu-cycles # 2.488 GHz (26.41%) 32,785,270,866 instructions # 1.20 insn per cycle # 0.58 stalled cycles per insn (26.43%) 19,069,766,918 stalled-cycles-backend # 69.91% backend cycles idle (26.43%) 6,560,109 stalled-cycles-frontend # 0.02% frontend cycles idle (26.42%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 1,086 context-switches # 0.099 K/sec 10,964.61 msec cpu-clock # 0.999 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 154 minor-faults # 0.014 K/sec 154 page-faults # 0.014 K/sec 10,964.91 msec task-clock # 0.999 CPUs utilized 206,294,123 L1-dcache-load-misses # 1.14% of all L1-dcache hits (26.38%) 18,083,269,173 L1-dcache-loads # 1649.217 M/sec (26.35%) 205,499,292 L1-dcache-prefetches # 18.742 M/sec (26.31%) 749,548 L1-icache-load-misses # 8.67% of all L1-icache hits (26.27%) 8,643,478 L1-icache-loads # 0.788 M/sec (26.25%) 305,577 branch-load-misses # 0.028 M/sec (26.25%) 9,850,674,490 branch-loads # 898.394 M/sec (26.25%) 6,736 dTLB-load-misses # 6.85% of all dTLB cache hits (26.25%) 98,327 dTLB-loads # 0.009 M/sec (26.25%) 114 iTLB-load-misses # 78.62% of all iTLB cache hits (26.25%) 145 iTLB-loads # 0.013 K/sec (26.25%) #perf stat -e branch-instructions,branch-misses,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./beforesort 23.3648 sum = 314931600000 9,843,358,378 branch-instructions # 421.186 M/sec (26.26%) 1,156,804,801 branch-misses # 11.75% of all branches (26.28%) 754,542 cache-misses # 0.351 % of all cache refs (26.29%) 215,234,724 cache-references # 9.210 M/sec (26.31%) 58,274,116,562 cpu-cycles # 2.493 GHz (26.33%) 32,850,416,330 instructions # 0.56 insn per cycle # 0.06 stalled cycles per insn (26.34%) 1,838,222,200 stalled-cycles-backend # 3.15% backend cycles idle (26.34%) 1,187,291,146 stalled-cycles-frontend # 2.04% frontend cycles idle (26.34%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 2,326 context-switches # 0.100 K/sec 23,370.23 msec cpu-clock # 0.999 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 150 minor-faults # 0.006 K/sec 150 page-faults # 0.006 K/sec 23,370.97 msec task-clock # 0.999 CPUs utilized 207,451,839 L1-dcache-load-misses # 0.82% of all L1-dcache hits (26.34%) 25,180,673,249 L1-dcache-loads # 1077.451 M/sec (26.34%) 205,669,557 L1-dcache-prefetches # 8.800 M/sec (26.34%) 1,725,971 L1-icache-load-misses # 8.12% of all L1-icache hits (26.34%) 21,265,604 L1-icache-loads # 0.910 M/sec (26.34%) 1,157,454,249 branch-load-misses # 49.526 M/sec (26.34%) 9,843,015,406 branch-loads # 421.171 M/sec (26.33%) 22,287 dTLB-load-misses # 7.08% of all dTLB cache hits (26.31%) 314,618 dTLB-loads # 0.013 M/sec (26.29%) 445 iTLB-load-misses # 44.95% of all iTLB cache hits (26.28%) 990 iTLB-loads # 0.042 K/sec (26.26%) |
hygon 在这两个场景中排序前比 intel 好了 20%,IPC 好30%,但是指令数多了10%,最关键的也是因为hygon的 branch-load-misses 率较低。
排序后 hygon 略慢10%,主要是指令数多了将近10%。
如果直接将 intel 下 编译好的二进制放到 hygon 下运行,完全可以跑通,指令数也显示和 intel 一样了,但是总时间较在hygon下编译的二进制没有变化
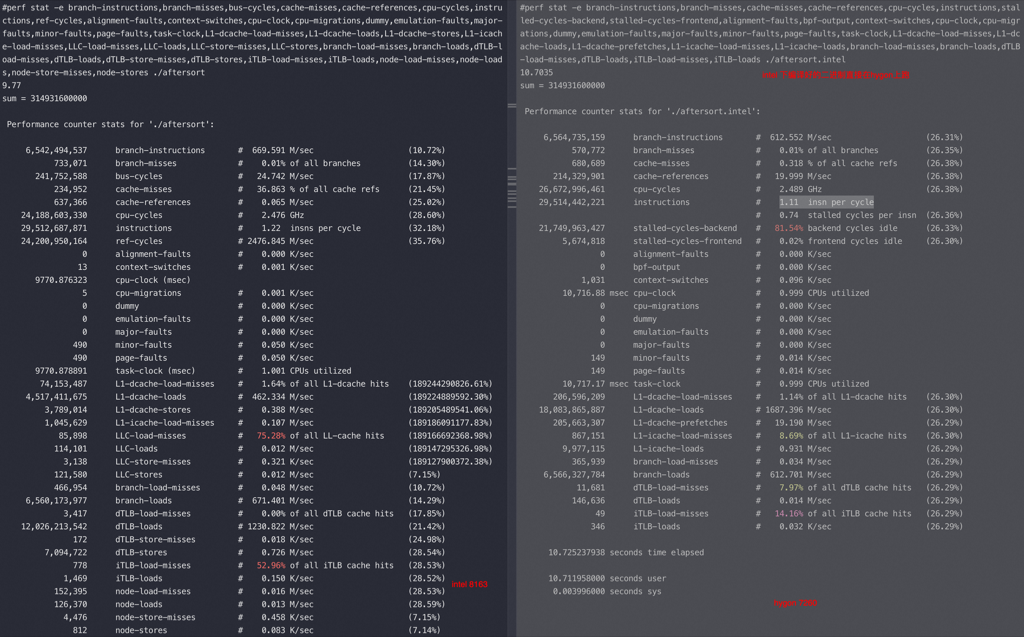
开启 gcc O3 优化
intel 8163
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./beforesort 2.94 sum = 314931600000 3,268,501,946 branch-instructions # 1109.263 M/sec (10.74%) 226,833 branch-misses # 0.01% of all branches (14.33%) 72,998,727 bus-cycles # 24.774 M/sec (17.90%) 89,636 cache-misses # 34.026 % of all cache refs (21.47%) 263,434 cache-references # 0.089 M/sec (25.03%) 7,301,839,495 cpu-cycles # 2.478 GHz (28.59%) 26,180,809,574 instructions # 3.59 insns per cycle (32.16%) 7,304,150,283 ref-cycles # 2478.880 M/sec (35.73%) 0 alignment-faults # 0.000 K/sec 10 context-switches # 0.003 K/sec 2946.550492 cpu-clock (msec) 7 cpu-migrations # 0.002 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 370 minor-faults # 0.126 K/sec 370 page-faults # 0.126 K/sec 2946.552985 task-clock (msec) # 1.001 CPUs utilized 73,550,829 L1-dcache-load-misses # 8.97% of all L1-dcache hits (627063379426.55%) 820,264,255 L1-dcache-loads # 278.381 M/sec (627063379426.55%) 6,301 L1-dcache-stores # 0.002 M/sec (627063379426.52%) 344,639 L1-icache-load-misses # 0.117 M/sec (627063379426.51%) 70,181 LLC-load-misses # 84.80% of all LL-cache hits (630745019998.59%) 82,757 LLC-loads # 0.028 M/sec (630529428492.86%) 592 LLC-store-misses # 0.201 K/sec (630313967916.99%) 33,362 LLC-stores # 0.011 M/sec (7.17%) 153,522 branch-load-misses # 0.052 M/sec (10.75%) 3,263,884,498 branch-loads # 1107.696 M/sec (14.33%) 274 dTLB-load-misses # 0.00% of all dTLB cache hits (17.90%) 2,179,821,780 dTLB-loads # 739.787 M/sec (21.47%) 8 dTLB-store-misses # 0.003 K/sec (25.04%) 12,708 dTLB-stores # 0.004 M/sec (28.61%) 59 iTLB-load-misses # 52.68% of all iTLB cache hits (28.60%) 112 iTLB-loads # 0.038 K/sec (28.59%) 5,919 node-load-misses # 0.002 M/sec (28.59%) 1,648 node-loads # 0.559 K/sec (28.58%) 560 node-store-misses # 0.190 K/sec (7.15%) 14 node-stores # 0.005 K/sec (7.14%) #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./aftersort 2.95 sum = 314931600000 3,255,184,180 branch-instructions # 1102.320 M/sec (10.74%) 791,180 branch-misses # 0.02% of all branches (14.35%) 73,001,075 bus-cycles # 24.721 M/sec (17.93%) 520,140 cache-misses # 82.262 % of all cache refs (21.52%) 632,298 cache-references # 0.214 M/sec (25.11%) 7,309,286,959 cpu-cycles # 2.475 GHz (28.69%) 26,120,077,275 instructions # 3.57 insns per cycle (32.28%) 7,316,568,954 ref-cycles # 2477.649 M/sec (35.86%) 0 alignment-faults # 0.000 K/sec 10 context-switches # 0.003 K/sec 2953.027151 cpu-clock (msec) 3 cpu-migrations # 0.001 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 370 minor-faults # 0.125 K/sec 370 page-faults # 0.125 K/sec 2953.029425 task-clock (msec) # 1.001 CPUs utilized 73,778,174 L1-dcache-load-misses # 8.94% of all L1-dcache hits (625801033059.49%) 825,038,324 L1-dcache-loads # 279.387 M/sec (625693600466.98%) 6,137 L1-dcache-stores # 0.002 M/sec (625693600466.94%) 339,275 L1-icache-load-misses # 0.115 M/sec (625693600466.87%) 7,611 LLC-load-misses # 52.34% of all LL-cache hits (625693600466.22%) 14,542 LLC-loads # 0.005 M/sec (625693600466.18%) 975 LLC-store-misses # 0.330 K/sec (625718826721.74%) 28,542 LLC-stores # 0.010 M/sec (7.17%) 150,256 branch-load-misses # 0.051 M/sec (10.75%) 3,260,765,171 branch-loads # 1104.210 M/sec (14.33%) 84 dTLB-load-misses # 0.00% of all dTLB cache hits (17.91%) 2,177,927,665 dTLB-loads # 737.523 M/sec (21.48%) 0 dTLB-store-misses # 0.000 K/sec (25.05%) 12,502 dTLB-stores # 0.004 M/sec (28.62%) 10 iTLB-load-misses # 5.62% of all iTLB cache hits (28.61%) 178 iTLB-loads # 0.060 K/sec (28.60%) 14,538 node-load-misses # 0.005 M/sec (28.59%) 1,527 node-loads # 0.517 K/sec (28.62%) 2,339 node-store-misses # 0.792 K/sec (7.18%) 0 node-stores # 0.000 K/sec (7.14%) |
可以看到 O3 优化后是否排序执行时间差不多,并且都比没有 O3 前的快几倍,指令数较优化前基本不变。
最明显的是排序前的 branch-load-misses 几乎都被优化掉了,这也导致 IPC 从0.41 提升到了3.59
aarch64 M710
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./beforesort 1.19468 sum = 314931600000 178,045 branch-misses (29.84%) 3,290,281,574 bus-cycles # 2748.321 M/sec (29.84%) 204,017,139 cache-misses # 24.768 % of all cache refs (29.84%) 823,700,482 cache-references # 688.024 M/sec (29.84%) 3,290,247,311 cpu-cycles # 2.748 GHz (34.85%) 5,730,855,778 instructions # 1.74 insn per cycle # 0.26 stalled cycles per insn (34.85%) 1,485,014,712 stalled-cycles-backend # 45.13% backend cycles idle (35.03%) 980,441 stalled-cycles-frontend # 0.03% frontend cycles idle (35.08%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 2 context-switches # 0.002 K/sec 1,197.20 msec cpu-clock # 1.000 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 140 minor-faults # 0.117 K/sec 140 page-faults # 0.117 K/sec 1,197.20 msec task-clock # 1.000 CPUs utilized 205,399,817 L1-dcache-load-misses # 25.00% of all L1-dcache accesses (35.08%) 821,607,081 L1-dcache-loads # 686.276 M/sec (35.08%) 10,361 L1-icache-load-misses # 0.00% of all L1-icache accesses (35.08%) 1,150,511,080 L1-icache-loads # 961.004 M/sec (30.07%) 6,275 LLC-load-misses # 0.00% of all LL-cache accesses (30.07%) 0 LLC-loads # 0.000 K/sec (30.07%) 103,368 branch-load-misses # 0.086 M/sec (30.07%) 821,524,106 branch-loads # 686.206 M/sec (30.07%) 15,315 dTLB-load-misses # 0.00% of all dTLB cache accesses (30.07%) 821,589,564 dTLB-loads # 686.261 M/sec (30.07%) 1,084 iTLB-load-misses # 0.07% of all iTLB cache accesses (30.07%) 1,613,786 iTLB-loads # 1.348 M/sec (29.89%) #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort 1.1949 sum = 314931600000 656,175 branch-misses (29.91%) 3,293,615,450 bus-cycles # 2748.397 M/sec (29.91%) 203,683,518 cache-misses # 24.631 % of all cache refs (29.91%) 826,934,774 cache-references # 690.046 M/sec (29.91%) 3,293,560,111 cpu-cycles # 2.748 GHz (34.92%) 5,732,241,288 instructions # 1.74 insn per cycle # 0.29 stalled cycles per insn (34.91%) 1,645,938,192 stalled-cycles-backend # 49.97% backend cycles idle (35.00%) 1,757,056 stalled-cycles-frontend # 0.05% frontend cycles idle (35.05%) 0 alignment-faults # 0.000 K/sec 0 bpf-output # 0.000 K/sec 2 context-switches # 0.002 K/sec 1,198.38 msec cpu-clock # 1.000 CPUs utilized 0 cpu-migrations # 0.000 K/sec 0 dummy # 0.000 K/sec 0 emulation-faults # 0.000 K/sec 0 major-faults # 0.000 K/sec 137 minor-faults # 0.114 K/sec 137 page-faults # 0.114 K/sec 1,198.38 msec task-clock # 1.000 CPUs utilized 205,557,180 L1-dcache-load-misses # 25.00% of all L1-dcache accesses (35.05%) 822,366,213 L1-dcache-loads # 686.233 M/sec (35.04%) 12,708 L1-icache-load-misses # 0.00% of all L1-icache accesses (35.05%) 987,422,733 L1-icache-loads # 823.967 M/sec (30.04%) 6,234 LLC-load-misses # 0.00% of all LL-cache accesses (30.04%) 0 LLC-loads # 0.000 K/sec (30.04%) 103,635 branch-load-misses # 0.086 M/sec (30.04%) 822,357,251 branch-loads # 686.226 M/sec (30.04%) 13,961 dTLB-load-misses # 0.00% of all dTLB cache accesses (30.04%) 822,374,897 dTLB-loads # 686.241 M/sec (30.04%) 709 iTLB-load-misses # 0.05% of all iTLB cache accesses (30.04%) 1,562,083 iTLB-loads # 1.303 M/sec (29.96%) |
可以看到在M710上开启 O3 优化后是否排序执行时间差不多,并且都比没有 O3 前
的快几倍,最明显的是指令数只有之前的7%。另外就是排序前的 branch-load-misses 几乎都被优化掉了,虽然这里 IPC 提升不大但主要在指令数的减少上。
O3意味着代码尽可能展开,更长的代码意味着对 L1i(以及 L2和更高级别)高速缓存的压力更高。这会导致性能降低。更短的代码可以运行得更快。幸运的是,gcc 有一个优化选项可以指定此项。如果使用-Os,则编译器将优化代码大小。使用后,能够增加代码大小的哪些优化将被禁用。使用此选项通常会产生令人惊讶的结果。特别是循环展开和内联没有实质优势时,那么此选项将是一个很好的选择。
分支预测原理介绍
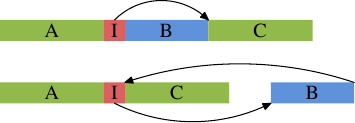
如上图的上面部分代表通常情况下的简单代码布局。如果区域 B(这里是内联函数 inlfct 生成的代码)经常由于条件 I 被跳过,而不会执行,处理器的预取将拉入很少使用的包含块 B 的高速缓存行。使用块重新排序可以改变这种局面,改变之后的效果可以在图的下半部分看到。经常执行的代码在内存中是线性的,而很少执行的代码被移动到不会损害预取和 L1i 效率的位置。
Linux内核流水线优化案例
在Linux Kernel中有大量的 likely/unlikely
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | //ip 层收到消息后,如果是tcp就调用tcp_v4_rcv作为tcp协议的入口 int tcp_v4_rcv(struct sk_buff *skb) { ... if (unlikely(th->doff < sizeof(struct tcphdr) / 4)) goto bad_packet; //概率很小 if (!pskb_may_pull(skb, th->doff * 4)) goto discard_it; //file: net/ipv4/tcp_input.c int tcp_rcv_established(struct sock *sk, ...) { if (unlikely(sk->sk_rx_dst == NULL)) ...... } //file: include/linux/compiler.h #define likely(x) __builtin_expect(!!(x),1) #define unlikely(x) __builtin_expect(!!(x),0) |
__builtin_expect 这个指令是 gcc 引入的。该函数作用是允许程序员将最有可能执行的分支告诉编译器,来辅助系统进行分支预测。(参见 https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html)
它的用法为:__builtin_expect(EXP, N)。意思是:EXP == N的概率很大。那么上面 likely 和 unlikely 这两句的具体含义就是:
- builtin_expect(!!(x),1) x 为真的可能性更大 //0两次取反还是0,非0两次取反都是1,这样可以适配builtin_expect(EXP, N)的N,要不N的参数没法传
- __builtin_expect(!!(x),0) x 为假的可能性更大
当正确地使用了__builtin_expect后,编译器在编译过程中会根据程序员的指令,将可能性更大的代码紧跟着前面的代码,从而减少指令跳转带来的性能上的下降。让L1i中加载的代码尽量有效紧凑
这样可以让 CPU流水线分支预测的时候默认走可能性更大的分支。如果分支预测错误所有流水线都要取消重新计算。
如果程序员利用这些宏,然后使用 -freorder-blocks 优化选项,则 gcc 将对块进行重新排序,如原理解图所示。该选项在 -O 2中启用,但在-Os 中禁用。还有另一种对块进行重新排序的选项(-freorder-blocks-and-partition ),但是它的用处有限,因为它不适用于异常处理。
总结
不排序的代码(分支极难预测正确)运行数据对比:
| branch-load-misses/branch-loads | instructions | IPC | 耗时(秒) | 排序后耗时(秒) | |
|---|---|---|---|---|---|
| 鲲鹏920 | 21.7% | 83,694,841,472 | 1.04 | 30.92 | 11.44 |
| M710 | 8.3% | 77,083,625,280 | 1.66 | 16.89 | 8.20 |
| Intel 8163 | 24.4% | 29,618,485,912 | 0.41 | 29.52 | 9.77 |
| hygon 7260 | 11.8% | 32,850,416,330 | 0.56 | 23.36 | 10.95 |
| FT S2500 | 24% | 83,872,213,462 | 1.01 | 39.8 | 16.63 |
排序后的代码(分支预测容易)运行数据对比:
| instructions | instructions(排序前) | IPC | 耗时(秒) | |
|---|---|---|---|---|
| 鲲鹏920 | 83,666,813,837 | 83,694,841,472 | 2.82 | 11.44 |
| M710 | 77,068,271,833 | 77,083,625,280 | 3.42 | 8.20 |
| Intel 8163 | 29,491,804,977 | 29,618,485,912 | 1.22 | 9.77 |
| hygon 7260 | 32,785,270,866 | 32,850,416,330 | 1.20 | 10.95 |
| FT S2500 | 83,918,069,835 | 83,872,213,462 | 2.41 | 16.63 |
- 所有 CPU 都期望对分支预测友好的代码
- 分支预测重点关注 perf branch-load-misses/branch-loads
- aarch64 较 x86_64 指令数是2.6倍,同时对流水线更友好,也就是 IPC 更高(2.6倍),测试代码单线程、无锁
- M710的分支预测正确率是鲲鹏920、intel的3倍,hygon 是鲲鹏 、intel的分支预测率的2倍
- 10% 的分支load miss 会带来一倍的性能差异
- gcc O3 优化效果很明显,代价就是代码展开后很大,容易造成icache不够,对小段测试代码效果最好,实践不一定
- 测试代码只是极简场景,实际生产环境更复杂,也就是预测效果不会这么明显