简述
CloudCanal 最近对于全周期数据流动进行了初步探索,打通了
Hive 目标端的实时同步,为实时数仓的构建提供了支持,这篇文章简要做下分享。
- 基于临时表的增量合并方式
- 基于 HDFS 文件写入方式
- 临时表统一 Schema
- 任务级的临时表
基于临时表的增量合并方式
Hive 目标端写入方式和 Doris
相似,需要在目标表上额外添加一个 __op(0:UPSERT,1:DELETE)字段作为标记位,实际写入时会先将源端的变更先写入临时表,最终合并到实际表中。
CloudCanal 的设计核心在于,每个同步表对应两张临时表,通过交替合并的方式,确保在一张临时表进行合并时,另一张能够接收新变更,从而提升同步效率和并发性。
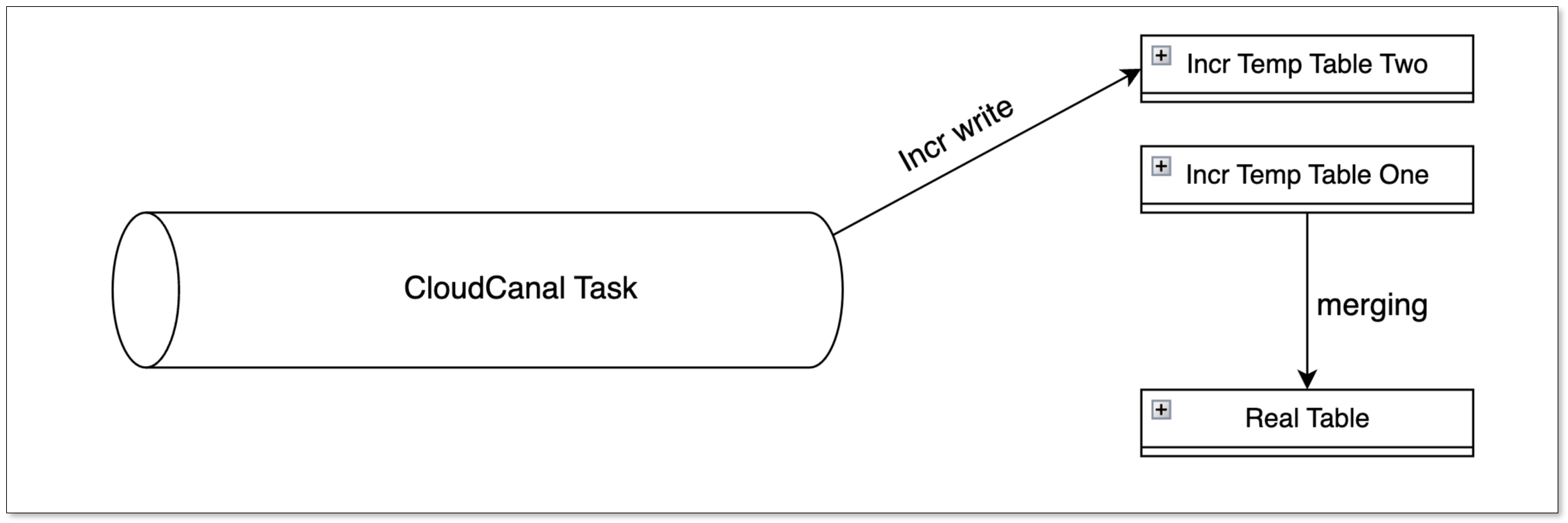
Hive 提供了两种合并方式:INSERT OVERWRITE(所有版本均支持),MERGE INTO(Hive 2.2.0 之后支持且需要是 ACID 表)
-- INSERT OVERWRITE 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
-- MERGE INTO 语法
MERGE INTO <target table > AS T USING < source expression / table > AS S
ON <boolean expression1>
WHEN MATCHED [AND <boolean expression2>] THEN
UPDATE SET <set clause list>
WHEN MATCHED [AND <boolean expression3>] THEN
DELETE
WHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
任务级的临时表
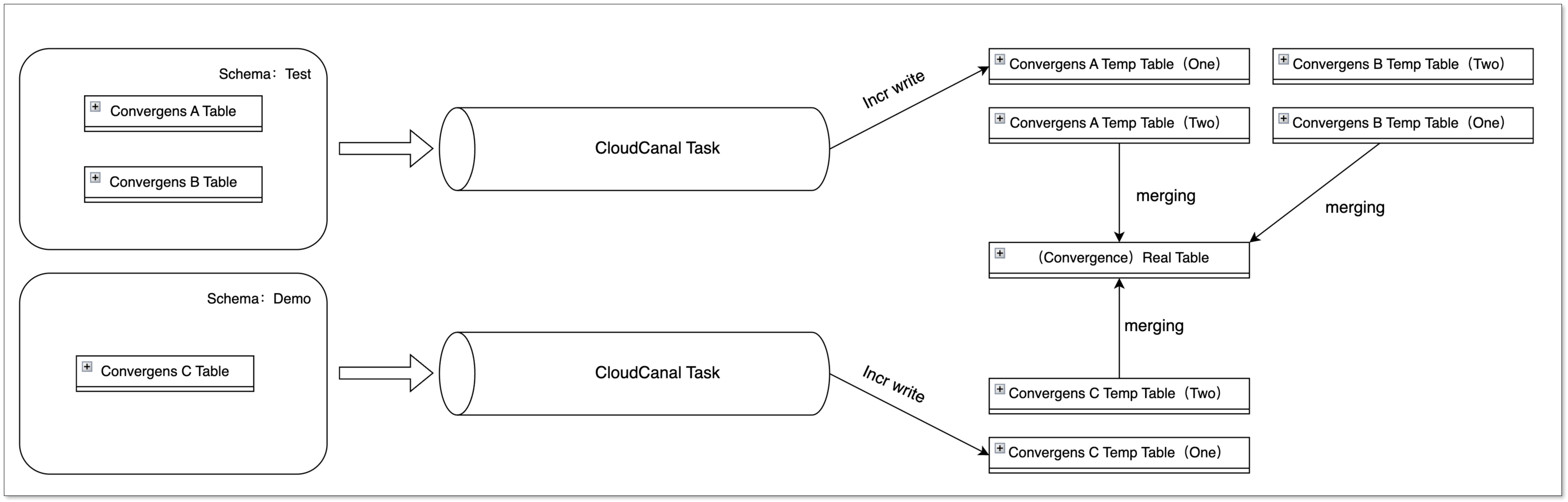
在大数据场景下,多表汇聚的情况十分普遍,CloudCanal 在构建临时表时,利用源端的订阅 Schema Table 信息,创建不同的临时表。
通过这种方式,无论是相同或不同的任务、相同或不同的 Schema(源端)、相同或不同的 Table(源端),都能将数据写入不同的临时表,最终合并到同一个实际表中,互相之间不会产生影响。
基于 HDFS 文件的写入方式
Hive 是建立在 Hadoop 体系上的数据仓库,而实际的数据存储在 HDFS 中。
如果直接通过 HQL 将增量数据写入 Hive,Hive 会将 HQL 转化为 MR Job,由于每一个 MR Job 处理速度相对较慢,这将导致增量性能极其差。
CloudCanal 在进行数据写入的时候,选择的是绕过 Hive 这层,直接写入 HDFS 文件系统。
目前支持 HDFS 文件格式:Text、Orc、Parquet。
临时表统一 Schema
基于临时表构建的增量方式,如果临时表分散在不同的 Schema 中,将给 DBA 的管理带来不便。
为了简化管理,CloudCanal 将所有临时表构建在统一的 Schema 下,并允许用户自定义其临时表路径。
示例
准备 CloudCanal
- 下载安装 CloudCanal 私有部署版本
添加数据源
-
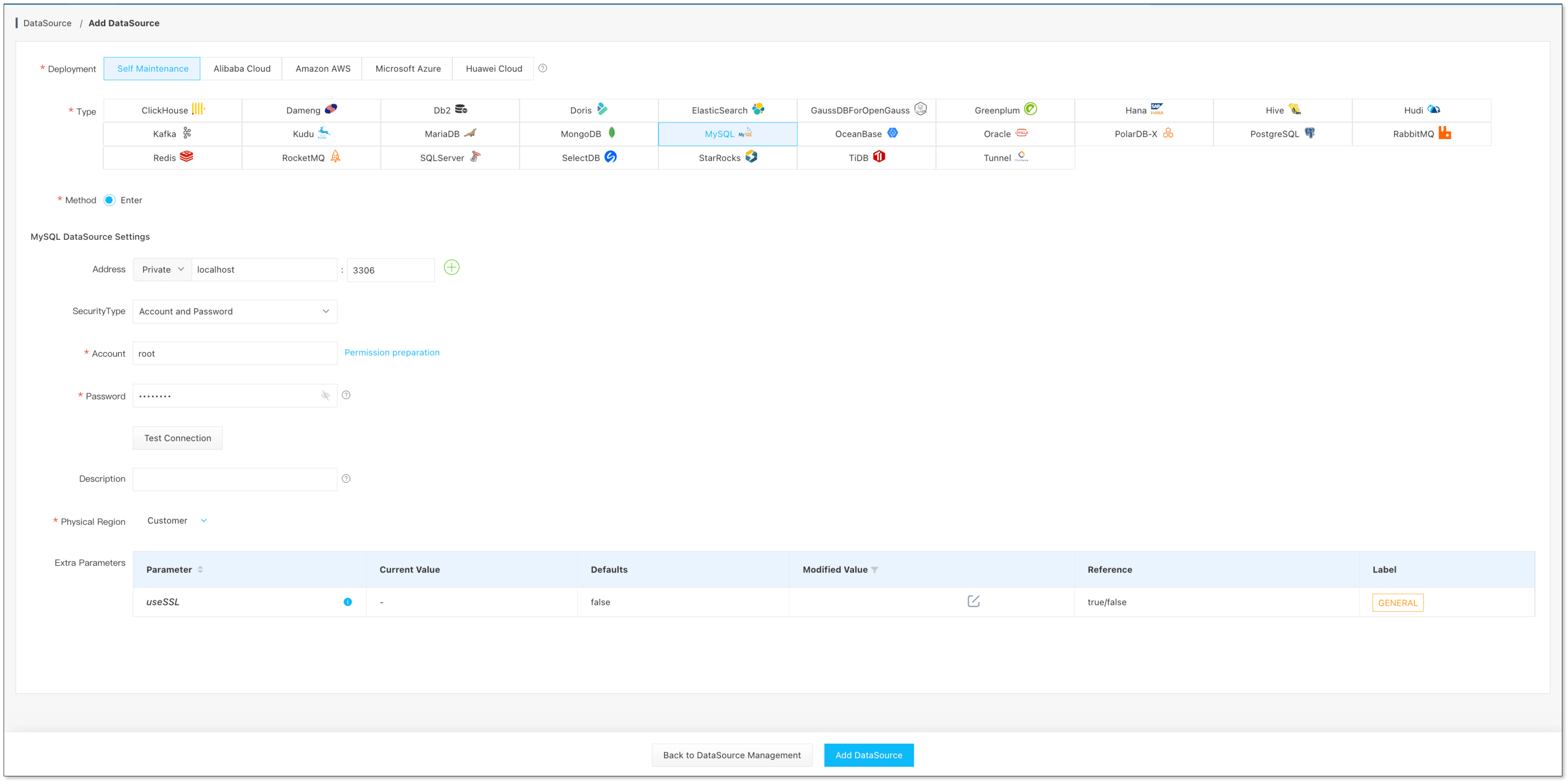
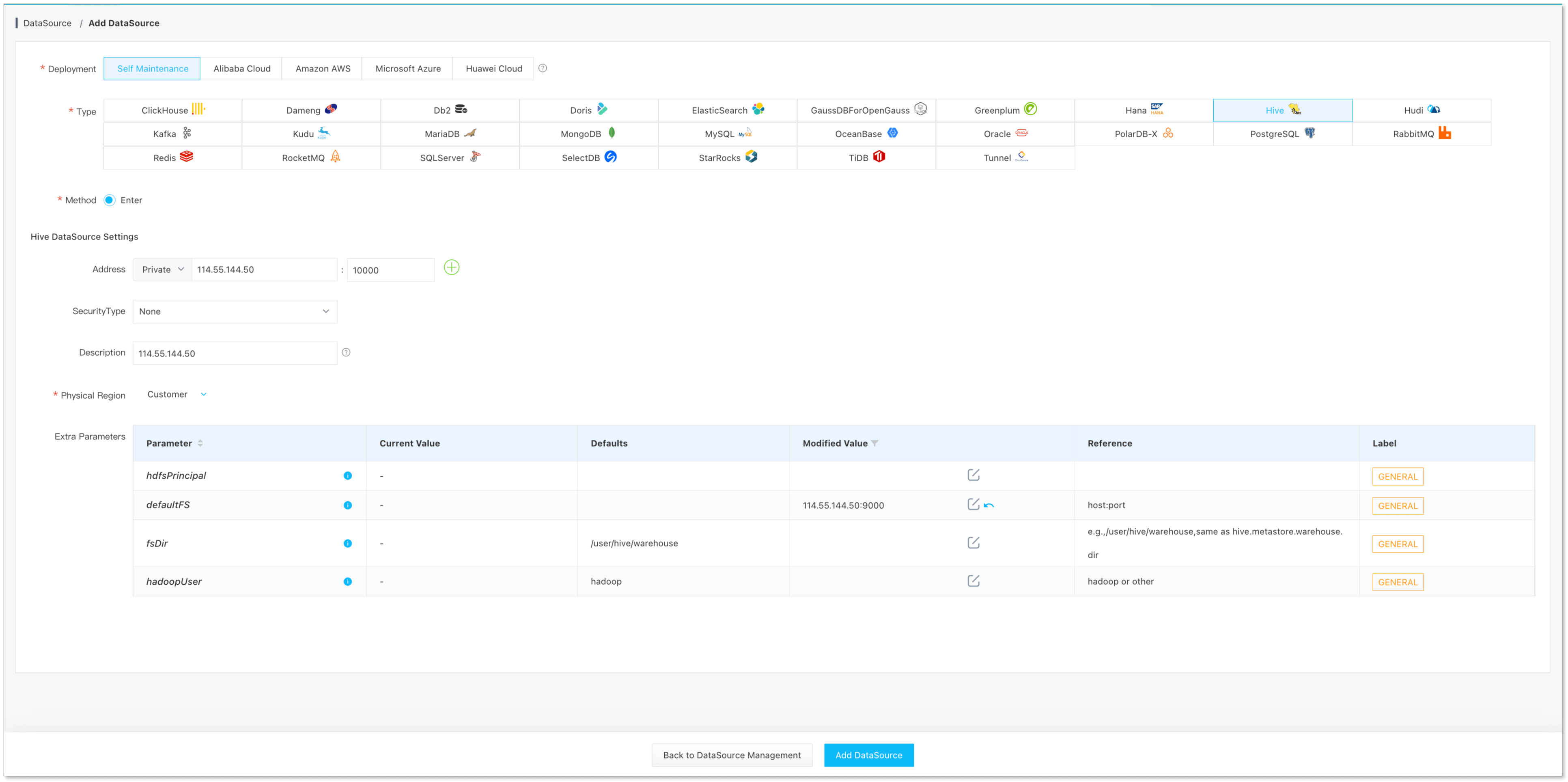
数据源管理 -> 添加数据源, 添加 MySQL、Hive
创建同步任务
-
选择源端 MySQL 和目标端 Hive,同步的 Schema 和 Table,高级参数含义参考 MySQL -> Hive

-
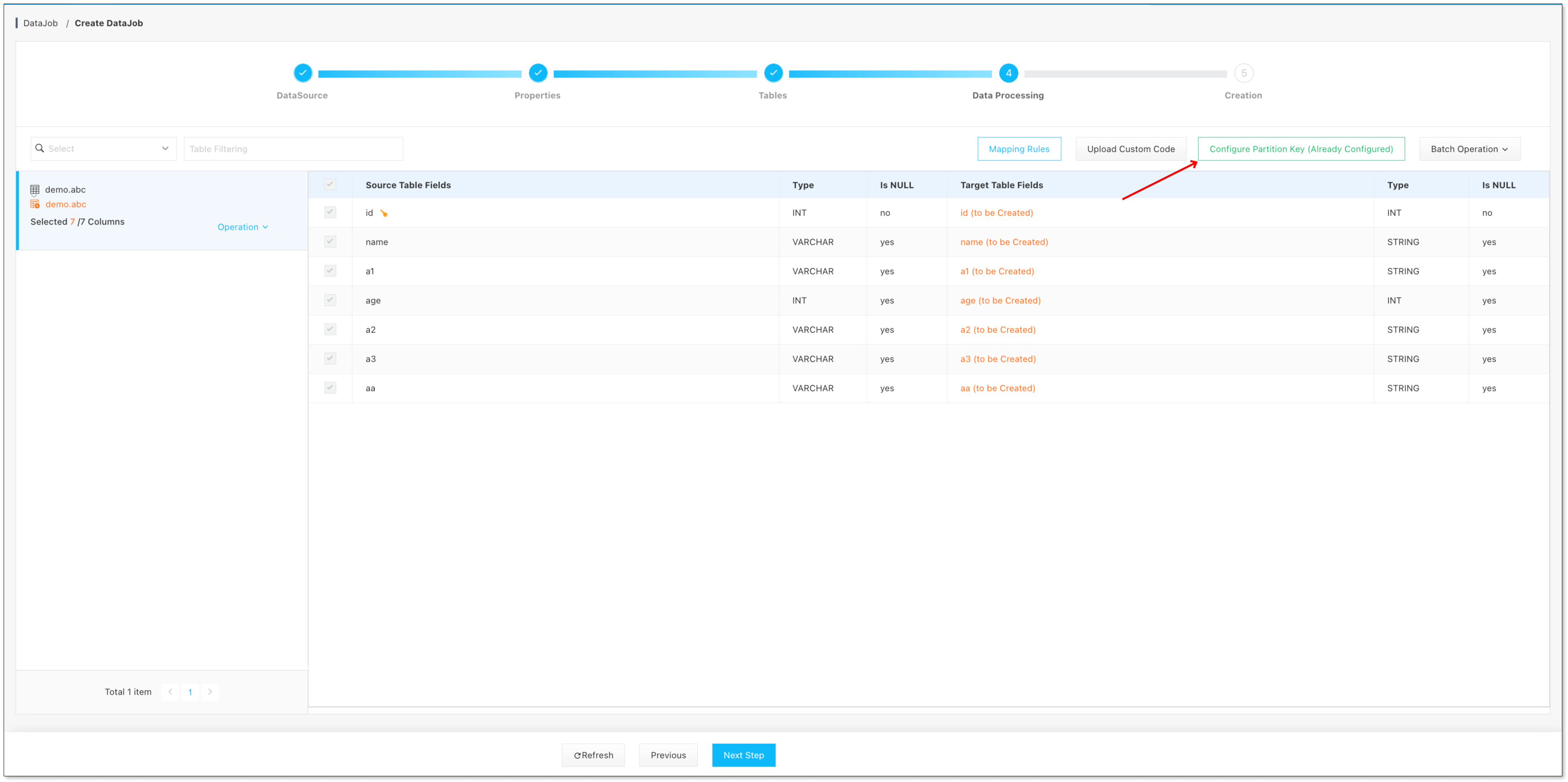
任务创建第四步,点击 配置分区键
-
选择 分区键类型 以及 HDFS 文件类型
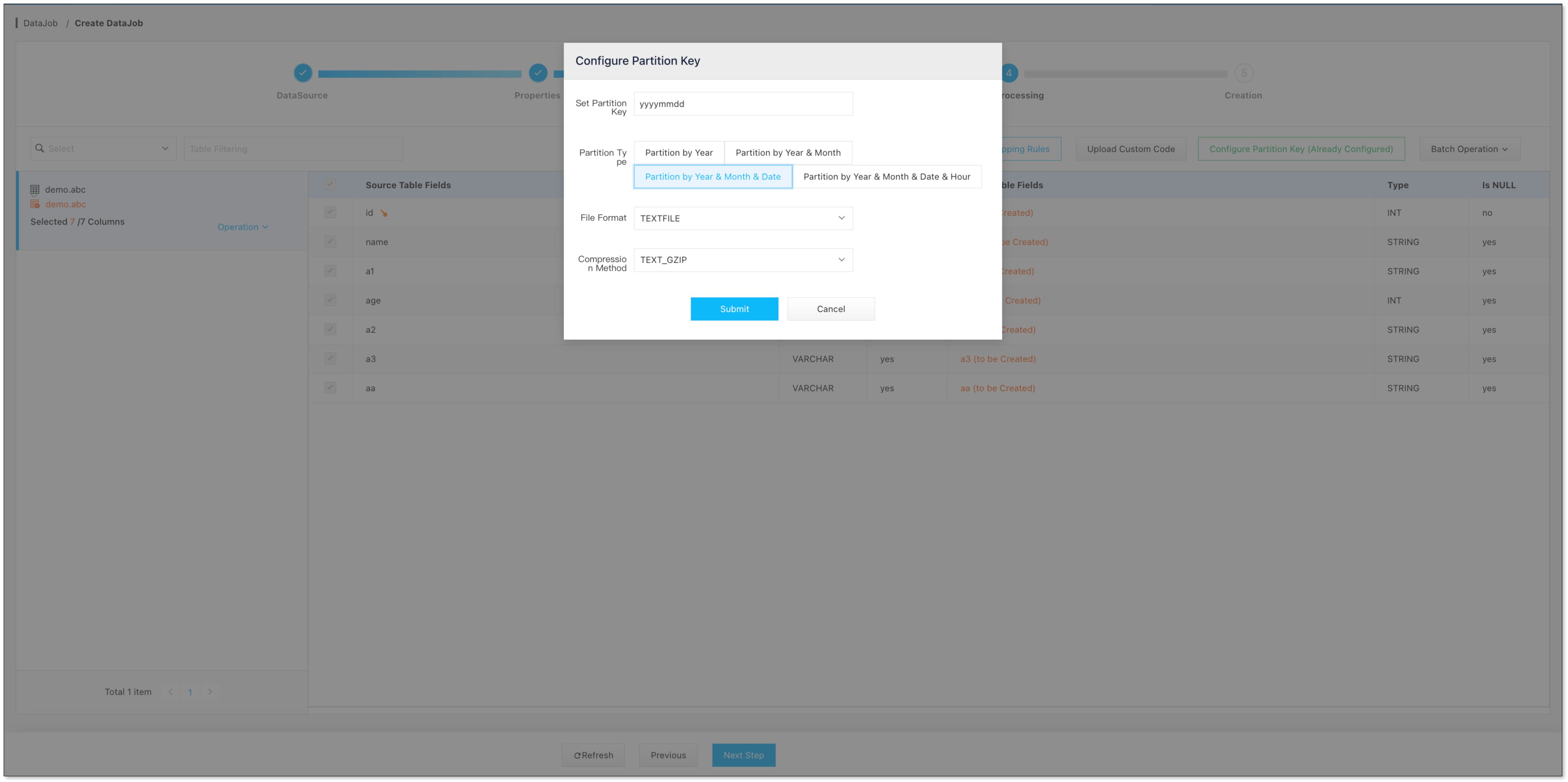
-
点击下一步,创建任务即可
未来方向
文件 Append 写入方式
目前 HDFS 文件写入处理,是每批数据写到一个文件中,并不会处理历史数据文件,更加合理的方式是基于历史文件进行 Append
追加,写满之后再切换为下一个文件。
提供参数优化 MR 处理速度
目前 CloudCanal 并没有提供参数入口用于优化 MR 处理速度,而是自动使用用户所配置的,未来 CloudCanal 将提供一个参数入口用于用户自定义每一个
MR Job 的处理并行度等优化参数。
支持 MERGE INTO 合并方式
目前 CloudCanal 仅支持 INSERT OVERWRITE 的合并方式,这种方式更为通用,而 MERGE INTO 此种合并方式速度更快,但限制较多,未来
CloudCanal 也会支持此种合并方式。
支持自定义分区键
目前 CloudCanal 仅支持按照日期选择分区键,目前暂时不支持更多分区键的选择,未来 CloudCanal 会提供更多分区键的选择。
总结
本篇文章简单介绍 CloudCanal 对于全生命周期的数据流动的初步探索,并通过 MySQL -> Hive 示例介绍其使用。
标签:数仓,CloudCanal,HDFS,临时,写入,Hive,Schema From: https://www.cnblogs.com/clougence/p/18047006/hive_dst_change_data_capture_writer