在进行数据分析时,数据无量纲化处理是一个关键步骤,通过合理地选择和应用无量纲化方法,可以使数据更加规范化和标准化,从而提高数据分析的准确性和可靠性。本文将介绍数据无量纲化的基本概念、常用方法的无量纲化处理方式、软件操作方法以及17种无量纲处理方法的简单说明。
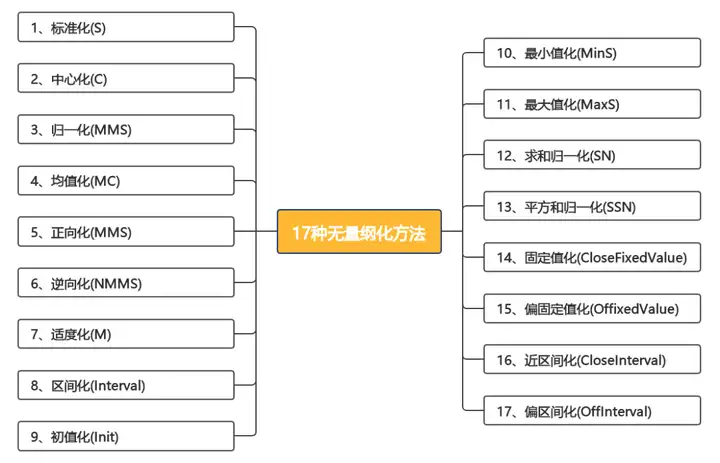
一、无量纲化处理是什么?
1、无量纲化定义
无量纲化,也称为数据的标准化、规范化,是一种常用的数据预处理的方法。它的主要目的是通过数据变换消除不同特征或指标之间的量纲影响,使数据具有可比性,从而进行后续分析。
在理解和应用无量纲化处理时,方向问题和量纲单位问题是非常重要的考虑因素。
2、方向问题&量纲单位问题
(1)方向问题
方向问题主要涉及数据指标的方向性。在实际应用中,不同的数据指标可能具有不同的方向性,即有的指标数值越大越好(如销售额、利润等),有的指标数值越小越好(如成本、耗时等),而有的指标数值越接近某个值越好(如PH接近7比较好)等等。
这种方向性的差异可能会给数据分析带来困难,因为不同方向的指标难以直接进行比较和合成。因此,在进行无量纲化处理时,需要考虑到这种方向性问题,确保处理后的数据能够保持原始数据的方向性特征。
(2)单位问题
单位问题则主要涉及数据指标的量纲和单位。不同的数据指标可能具有不同的量纲和单位,如长度、重量、时间等。为了消除这种量纲和单位的影响,需要进行无量纲化处理。使不同指标之间具有可比性,从而方便后续分析。
17种无量纲化处理方法,对于方向问题和单位问题处理有所差异。例如标准化能够解决单位问题,不能够解决方向问题;各类无量纲化处理方式对比如下表:
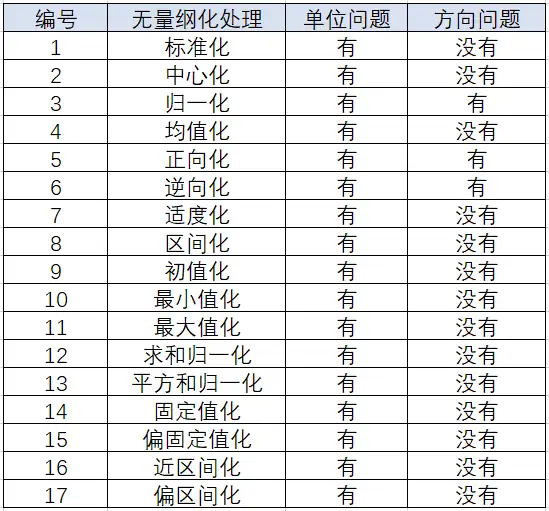
二、无量纲化方法选择
在研究时具体应该使用哪一种处理方式呢,其实并没有固定的要求,而是结合实际情况进行处理,如果有相关研究的参考文献,则以参考文献为准。
1、常用方法无量纲化处理
比如熵值法计算权重时,通常需要处理数据的方向问题,可以使用正向化、逆向化处理方式;但对于数据的单位问题,可以处理也可以不处理,对于分析并没有太大影响,如果要处理可以选择归一化处理方式。
下表列出了一些论文写作中常用分析方法的无量纲化处理方式,大家可以参考:
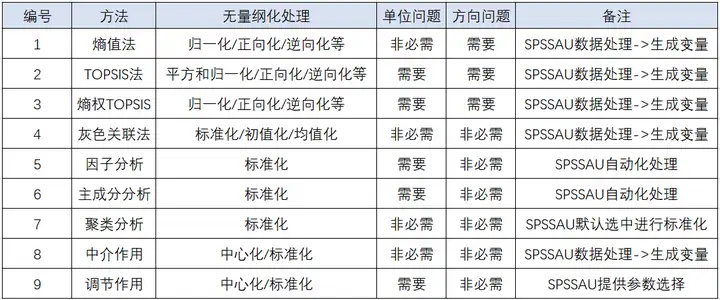
如果单独想对数据量纲进行处理,那么通常默认是使用标准化或者归一化最多,标准化直接把数据压缩且数据有一种特质即平均值为0标准差为1的特质;归一化把数据压缩在 [0,1] 之间。也或者使用中心化让数据有一种特质即平均值为0。
2、正向化&逆向化
需要特别提醒正向化和逆向化这两种处理方式,其目的有2个:一是对数据进行量纲单位处理,最终让数据压缩在【0,1】之间。除此之外,其还可以对正向或负向指标进行方向上的统一。
如果数据同时包括正向指标和逆向指标,那么正向指标进行正向化处理,负向指标进行负向化处理,最终让所有的指标都压缩在【0,1】之间,而且都让指标有一个性质即数字越大越好。如果说指标全部都是正向指标那么全部正向化即可,正向化后数字还是越大越好;如果说指标全部都是逆向指标那么全部逆向化即可,逆向化后数字就代表越大越好。
三、SPSSAU无量纲化处理操作
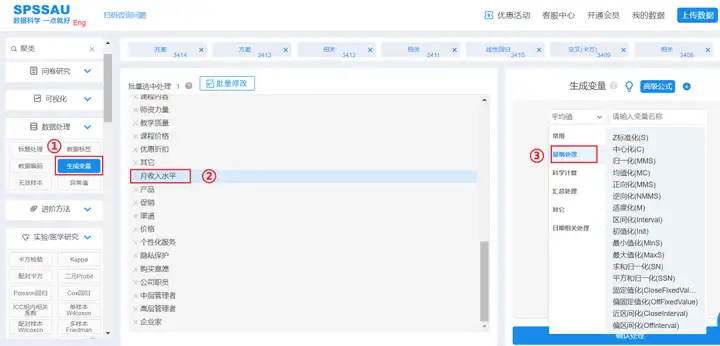
使用SPSSAU进行无量纲化处理,位于SPSSAU数据处理->【生成变量】
step1:在数据处理模块选择【生成变量】;
step2:选中需要处理的指标,可批量选中指标;
step3:选择“量纲处理”中对应的无量纲化处理方法,点击“确认处理”即可完成。
四、17种无量纲化处理方法说明
SPSSAU共提供17种无量纲化处理方法,其中比较常用的比如:标准化、中心化、归一化、均值化、正向化、逆向化等等;汇总说明如下表:
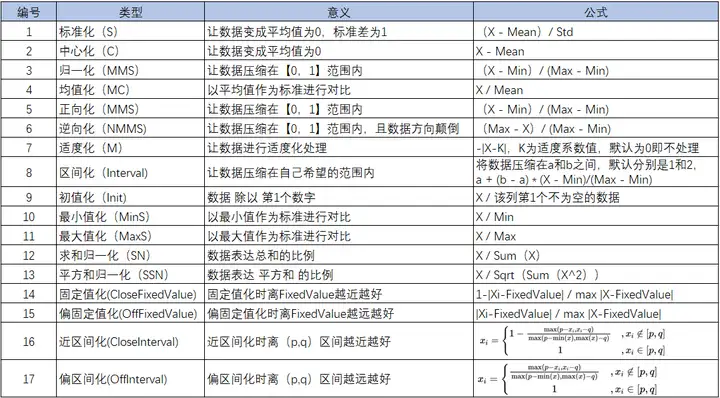
备注:表格中,X表示某数据,Mean表示平均值,Std表示标准差;Min表示最小值,Max表示最大值,Sum表示求和,Sqrt表示开根号;接下来将逐个进行说明。
1、标准化(S)
计算公式为:(X-Mean)/ Std
标准化是一种最为常见的量纲化处理方式。此种处理方式会让数据呈现出一种特征,即数据的平均值一定为0,标准差一定是1。针对数据进行了压缩大小处理,同时还让数据具有特殊特征(平均值为0标准差为1)。
在很多研究算法中均有使用此种处理,比如聚类分析前一般需要进行标准化处理,也或者因子分析时默认会对数据标准化处理。
除此之外,还有一些特殊的研究方法,比如社会学类进行中介作用,或者调节作用研究时,也可能会对数据进行标准化处理。
2、中心化(C)
计算公式为:X - Mean
中心化这种量纲处理方式可能在社会科学类研究中使用较多,比如进行中介作用,或者调节作用研究。此种处理方式会让数据呈现出一种特征,即数据的平均值一定为0。针对数据进行了压缩大小处理,同时还让数据具有特殊特征(平均值为0)。
平均值为0是一种特殊情况,比如在社会学研究中就偏好此种量纲处理方式,调节作用研究时可能会进行简单斜率分析,那么平均值为0表示中间状态,平均值加上一个标准差表示高水平状态;也或者平均值减一个标准差表示低水平状态。
3、归一化(MMS)
计算公式为:(X - Min)/ (Max - Min)
归一化的目的是让数据压缩在 [0,1] 范围内,包括两个边界数字0和数字1;当某数据刚好为最小值时,则归一化后为0;如果数据刚好为最大值时,则归一化后为1。归一化也是一种常见的量纲处理方式,可以让所有的数据均压缩在 [0,1] 范围内,让数据之间的数理单位保持一致。
4、均值化(MC)
计算公式为:X / Mean
均值化在综合评价时有可能使用,比如进行灰色关联法研究时就常用此种处理方式;需要特别说明一点是,此种处理方式有个前提,即所有的数据均应该大于0,否则可能就不适合用此种量纲方式。
5、正向化(MMS)
计算公式为:(X - Min)/ (Max - Min)。
正向化的目的是对正向指标保持正向且量纲化。比如GDP增长率、科研产出数量这两个指标;GDP增长率、科研产出数量是数字越大越好。正向化的目的就是让数字越大越好的意思,而且同时其还让数据压缩在 [0,1] 范围内即进行了量纲处理。
当某数据刚好为最小值时,则归一化后为0;如果数据刚好为最大值时,则归一化后为1。正向化和归一化的公式刚好完全相等,但正向化强调让数字保持越大越好的特性且对数据单位压缩,而归一化仅强调数字压缩在 [0,1] 之间。正向化的使用情况为:当指标中有正向指标,又有负向指标时;此时使用正向化让正向指标全部量纲化;也或者指标全部都是正向指标,让所有正向指标都量纲化处理。
6、逆向化(NMMS)
计算公式为:(Max - X)/ (Max - Min)
逆向化的目的是对逆向指标正向且量纲化。比如失业率这个指标;失业率是数字越小越好。逆向化的目的就是让数字越小越好的意思,而且同时其还让数据压缩在 [0,1] 范围内即进行了量纲处理。
从公式就可以看出,分母永远是大于0,随着X的增大,分子会越来越小,那么就对逆向指标逆向化处理之后就会得到一个这样的特征,即数字越大越好(数字越大时,其实X是越小)。
相当于将逆向指标逆向化后,新的数据为数字越大越好,这样便于进行方向的统一,尤其是在指标同时出现正向指标和逆向指标时,针对逆向指标进行逆向处理,是非常常见的处理方式。
7、适度化(M)
计算公式为:-|X-K|
适度化其目的是让K适度系数值作为参考标准,比如K=1,其意义为数字越接近于1,适度化后数字越大,适度化处理后数字均小于等于0,但越接近0说明其离K值越近;
8、区间化(Interval)
其计算公式为:
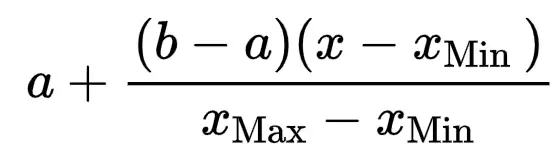
区间化的目的是让数据压缩在 [a,b] 范围内,a和b是自己希望的区间值,如果a=0,b=1,那么其实就是一种特殊情况即归一化;
此公式会让数据永远的保持在 [a,b] 之间,SPSSAU默认a为1,b为2,即将数据压缩在 [1,2] 之间,当然研究者根据需要进行设置即可。它的目的仅仅是对数据进行压缩在固定的区间,保持数据数理单位的一致性。
9、初值化(Init)
计算公式为:X / 该列第1个不为空的数据
初值化在综合评价时有可能使用,比如进行灰色关联法研究时就常用此种处理方式;即以数据中第1个不为空的数据作为参照标准,其余的数据全部去除以该值。
比如说2000,2001,2002,2003,一直到2022共计23年的GDP数据,第1个数据就是2000年的GDP,所有的数据都去除以2000年的GDP,相当于以2000年GDP作为参照标准,所有数据全部除以2000年的GDP(包括2000年GDP除以自己得到数字1)。
一般来说,初值化这种处理方式适用于有着一种趋势或规律性的数据,比如上述2000~2022年的GDP等,而且数据正常情况下都是全部大于0,因为出现负数,通常会失去其特定意义。
10、最小值化(MinS)
其计算公式为:X / Min
最小值化其目的是让最小值作为参照标准,所有的数据全部除以最小值;
需要特别说明一点是,此种处理方式时一般都是要求数据全部大于0,否则可能就不适合用此种无量纲化处理方式。
11、最大值化(MaxS)
计算公式为:X / Max
最大值化其目的是让最大值作为参照标准,所有的数据全部除以最大值;即以最大值作为单位,全部数据全部去除以最大值。
需要特别说明一点是,此种处理方式时一般都是要求数据全部大于0,否则可能就不适合用此种无量纲化处理方式。
12、求和归一化(SN)
计算公式为:X / Sum(X)
求和归一化其目的是让‘求和值’作为参照标准,所有的数据全部除以求和值,得到的数据相当于为求和的占比。
需要特别说明一点是,此种处理方式时一般都是要求数据全部大于0,否则可能就不适合用此种无量纲化处理方式。TOPSIS法的时候使用此种处理方式较多。
13、平方和归一化(SSN)
计算公式为:X / Sqrt(Sum(X^2))
平方和归一化其目的是让 ‘ 平方和值 ’ 作为参照标准,所有的数据全部除以平方和值,得到的数据相当于为平方和的占比。
需要特别说明一点是,此种处理方式时一般都是要求数据全部大于0,否则可能就不适合用此种量纲方式。TOPSIS法的时候使用此种处理方式较多。
14、固定值化(CloseFixedValue)
计算公式为:
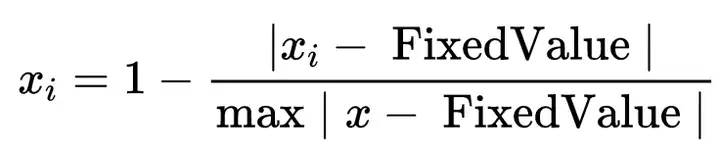
固定值化其目的是让某一固定值FixedValue作为标准;比如固定值为10,则分母为一定值——代表所有数据离10的最远距离。固定值化的实际意义为离10的相对距离(处理后数字越大越接近,数据越小越远离),经过固定值化处理,使数据压缩在 [0,1] 之间,0代表远离10,1代表刚好为10。固定值化时离固定值FixedValue越近越好。
15、偏固定值化(OffFixedValue)
计算公式为:
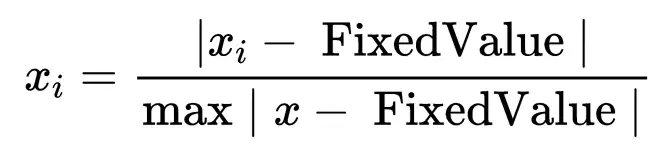
偏固定值化其目的是让某一固定值FixedValue作为标准;比如固定值为10,固定值化的实际意义为离10的相对距离(处理后数字越大越远离,数据越小越接近),经过固定值化处理,使数据压缩在 [0,1] 之间,0代表刚好为10,1代表远离10。偏固定值化时离固定值FixedValue越远越好。
16、近区间化(CloseInterval)
计算公式为:
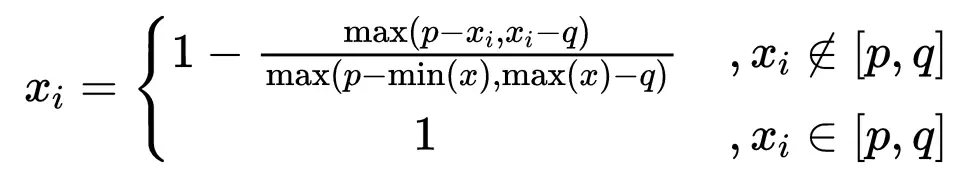
近区间化其目的是让某一区间(p,q)作为标准,属于该区间的数值取数字1,不属于的进行近区间化处理,近区间化时离(p,q)区间越近越好。
17、偏区间化(OffInterval)
其计算公式为:
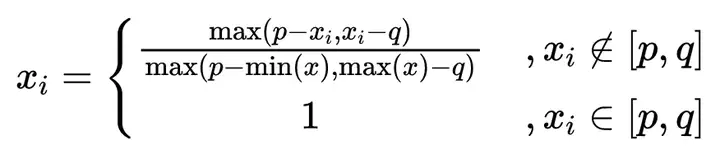
偏区间化其目的是让某一区间(p,q)作为标准,属于该区间的数值取数字1,不属于的进行偏区间化处理,偏区间化时离(p,q)区间越远越好。
标签:纲化,17,处理,无量,指标,归一化,数据 From: https://www.cnblogs.com/spssau/p/18042926