正则表达式拾遗
正则介绍
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a到z之间的字母)和特殊字符(称为“元字符”),是计算机科学的一个概念。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符以及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,许多程序设计语言都支持利用正则表达式进行字符串操作。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。正则表达式中的普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
正则表达式于20世纪40年代出现,用于描述常规语言,但直到20世纪70年代才出现在编程中,由肯·汤普逊编写的QED文字编辑器是编程中找到最早使用正则表达式的地方。正则表达式在许多场合中都有非常重要的应用,例如搜索、爬虫、数据验证等。
正则表达式(Regular Expression,常简写为regex、regexp或RE)是一种强大的文本处理工具,它使用单个字符串来描述、匹配一系列符合某个规则的字符串。这个规则可以非常复杂,也可以非常简单,取决于具体的需求。
正则表达式的组成:
-
普通字符:包括大小写字母、数字、标点符号及一些其他符号。这些字符在正则表达式中表示它们自身,例如,正则表达式“hello”会匹配文本中的字符串“hello”。
-
元字符:元字符是正则表达式中具有特殊意义的字符,它们并不表示自身,而是用来描述前导字符(或字符集合)在目标对象中的出现模式。常见的元字符包括:
- “.”:匹配除了换行符以外的任意字符。
- “*”:表示前面的字符可以出现任意次(包括0次)。
- “?”:表示前面的字符可以出现0次或1次。
- “+”:表示前面的字符可以出现至少1次。
- “^”:匹配输入字符串的开始位置。
- “$”:匹配输入字符串的结束位置。
- “\d”:匹配一个数字字符,等价于[0-9]。
- “\D”:匹配一个非数字字符,等价于[^0-9]。
正则表达式的应用:
- 搜索:正则表达式常用于在文本中搜索符合特定模式的字符串。例如,可以使用正则表达式在日志文件中搜索包含特定错误信息的行。
- 替换:正则表达式也可以用来替换文本中的字符串。例如,可以使用正则表达式将文本中的所有电话号码替换为特定的占位符。
- 验证:正则表达式可以用来验证输入是否符合特定的格式。例如,可以使用正则表达式验证电子邮件地址或电话号码的格式是否正确。
正则表达式的优点:
- 灵活性:正则表达式可以描述非常复杂的匹配模式,使得它在处理各种文本处理任务时非常灵活。
- 高效性:对于大量的文本数据,使用正则表达式可以显著提高处理效率。
- 广泛的应用:正则表达式被广泛应用于各种编程语言和文本处理工具中,使得它成为一种通用的文本处理技能。
然而,正则表达式也有其缺点,比如学习曲线较陡峭,需要一定的时间和精力来掌握;同时,过于复杂的正则表达式可能导致性能下降,需要谨慎使用。
熟能生巧用的多自然而然就懂了,一开始也可以借助一些
AI进行学习。
常用元字符关键字介绍
- 字符类:
.:匹配除了换行符之外的任意单个字符。\d:匹配任意数字,相当于 [0-9]。\D:匹配任意非数字字符,相当于 [^0-9]。\w:匹配任意字母、数字或下划线,相当于 [a-zA-Z0-9_]。\W:匹配任意非字母、数字或下划线字符,相当于 [^a-zA-Z0-9_]。\s:匹配任意空白字符(包括空格、制表符、换行符等)。\S:匹配任意非空白字符。
- 锚点:
^:匹配输入字符串的开始位置。$:匹配输入字符串的结束位置。
- 量词:
*:匹配前面的子表达式零次或多次。+:匹配前面的子表达式一次或多次。?:匹配前面的子表达式零次或一次。{n}:n 是一个非负整数,匹配确定的 n 次。{n,}:n 是一个非负整数,至少匹配 n 次。{n,m}:m 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次。
- 选择、分组和引用:
|:或操作符,匹配 | 前后任一表达式。():分组,将多个字符捆绑在一起,当作一个整体进行处理,也可以用于后向引用。\n:后向引用,引用前面分组中捕获的文本(n 是一个正整数)。
- 特殊字符转义:
\:转义字符,用于转义正则表达式中的特殊字符,如 . 匹配 . 字符本身。
- 字符集和否定字符集:
[...]:字符集,匹配方括号内的任一字符。[^...]:否定字符集,匹配不在方括号内的任一字符。
- 预定义模式,某些正则表达式引擎提供了一些预定义的字符类,如 \d、\w 等。:
i:不区分大小写匹配。g:全局匹配,查找所有匹配项而不仅仅是第一个。m:多行模式,让 ^ 和 $ 分别匹配每行的开头和结尾。
更多关键字请参考正则表达式语言 - 快速参考
.NET下正则使用
.NET 下的正则由 System.Text.RegularExpressions 相关类 提供的正则引擎。它也是比较强大的引擎,具体可以参考 正则表达式引擎/风味对比 。
- 检查一个字符串是否包含数字
string pattern = @"\d"; // 匹配任何数字
string input = "abc123def";
if (Regex.IsMatch(input, pattern))
Console.WriteLine("The string contains a number.");
else
Console.WriteLine("The string does not contain a number.");
- 从一个字符串中提取所有的单词
string pattern = @"\w+"; // 匹配一个或多个字母、数字或下划线
string input = "Hello, world! This is a test.";
MatchCollection matches = Regex.Matches(input, pattern);
foreach (Match match in matches)
Console.WriteLine(match.Value);
- 使用正则表达式替换字符串中的数字为 #
string pattern = @"\d"; // 匹配任何数字
string input = "abc123def456";
string replacement = "#";
string result = Regex.Replace(input, pattern, replacement);
Console.WriteLine(result); // 输出: abc###def###
- 从字符串中提取电子邮件地址
string pattern = @"(\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b)"; // 匹配电子邮件地址
string input = "Contact us at [email protected] or [email protected]";
MatchCollection matches = Regex.Matches(input, pattern);
foreach (Match match in matches)
Console.WriteLine(match.Value); // 输出: [email protected] 和 [email protected]
- 验证密码强度
假设我们需要验证一个密码是否满足以下条件:
- 至少包含一个大写字母
- 至少包含一个小写字母
- 至少包含一个数字
- 长度至少为8个字符
string password = "Password123";
string pattern = @"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$";
if (Regex.IsMatch(password, pattern))
Console.WriteLine("密码强度足够。");
else
Console.WriteLine("密码强度不足。");
在这个正则表达式中:
(?=.*[a-z]) 是一个前瞻断言,确保字符串中至少有一个小写字母。
(?=.*[A-Z]) 确保至少有一个大写字母。
(?=.*\d) 确保至少有一个数字。
[a-zA-Z\d]{8,} 确保字符串至少由8个字符组成,且这些字符只能是字母或数字。
- 提取HTML标签中的文本
如果你想从HTML标签中提取文本,你可以使用正则表达式(尽管对于复杂的HTML解析,通常建议使用专门的HTML解析库)。
string html = "<p>这是一个段落。</p><p>这是另一个段落。</p>";
string pattern = @"<p>(.*?)</p>"; // 懒惰匹配防止跨标签匹配
MatchCollection matches = Regex.Matches(html, pattern);
foreach (Match match in matches)
{
if (match.Success)
Console.WriteLine(match.Groups[1].Value); // 输出捕获组中的文本
}
在这个例子中,我们使用了懒惰量词 *? 来确保只匹配到最近的闭合标签
。但是,请注意,正则表达式并不是解析HTML的最佳工具,因为它不能很好地处理嵌套的或不规则的HTML结构。对于实际的HTML内容提取,应该使用像HtmlAgilityPack这样的库。- 匹配和替换日期格式
假设你有一个字符串,里面包含了多种日期格式,你想将它们统一成一种格式。例如,将 "dd/mm/yyyy" 和 "mm-dd-yyyy" 都转换成 "yyyy-mm-dd"
string input = "我的生日是09/25/1990,但她的生日是25-09-1992。";
string pattern1 = @"(\d{2})/(\d{2})/(\d{4})"; // 匹配 dd/mm/yyyy 格式
string pattern2 = @"(\d{2})-(\d{2})-(\d{4})"; // 匹配 dd-mm-yyyy 格式
string result = Regex.Replace(input, pattern1, "$3-$2-$1"); // 转换第一种格式
result = Regex.Replace(result, pattern2, "$3-$2-$1"); // 转换第二种格式
Console.WriteLine(result); // 输出: 我的生日是1990-09-25,但她的生日是1992-09-25。
- 手机号匹配
匹配国内手机号,或者海外手机号
string pattern = @"^(?:\(\+?86\))?1[0-9]{10}$|^(?!\(\+?86\))\(\+?[0-9]{1,4}\)[0-9-]+$";
string[] phoneNumbers = new string[]
{
"(+86)13800138000",
"13800138000",
"(+123)456-7890",
"+4917612345678", // 这个号码不符合你的原始正则表达式,因为没有括号
"(+86)123456789012" // 故意放一个不符合的号码来测试
};
foreach (string phoneNumber in phoneNumbers)
{
if (Regex.IsMatch(phoneNumber, pattern))
Console.WriteLine($"'{phoneNumber}' matches the pattern.");
else
Console.WriteLine($"'{phoneNumber}' does not match the pattern.");
}
正则验证工具
有很多正则在线验证工具
- https://www.regexp.cn/Regex
- https://www.jyshare.com/front-end/854/
- https://www.w3cschool.cn/tools/index?name=create_reg
- https://regex101.com/(推荐)
我们以这段正则举例
^(?:\(\+?86\))?1[0-9]{10}$|^(?!\(\+?86\))\(\+?[0-9]{1,4}\)(?:[0-9]+\-)*[0-9]+$
这段正则表达式可以分成两部分:
(?:\(\+?86\))?1[0-9]{10}$:匹配中国手机号码,可以以"+86"开头,也可以不加区号,然后接11位数字。^(?!\(\+?86\))\(\+?[0-9]{1,4}\)(?:[0-9]+\-)*[0-9]+$:匹配国际电话号码,不匹配以"+86"开头的号码,可以包含国际区号,然后是一系列数字和短横线,最后以数字结尾。
Regester
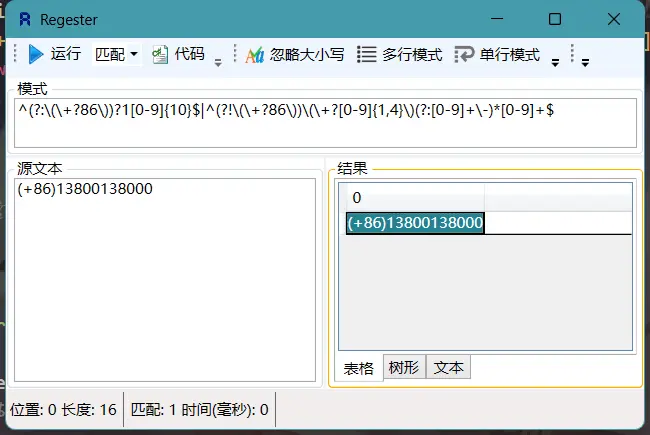
Regester是一款非常实用的正则表达式测试工具。以下是这款工具的主要功能和特点:
- 多种结果查看方式:支持树形、表格、文本等三种结果查看方式,用户可以根据需要灵活选择。
- 丰富的表格操作:表格内容不仅可以自由选择,还可以自由复制。此外,表格内容还可以导出为csv/xlsx文件,方便用户进行后续处理和分析。
- 拖入文件作为匹配源文本:用户可以直接将需要测试的文件拖入软件界面,作为匹配源文本,无需手动复制粘贴。
正则可视化
PlantUML 是一种简单的文本语言,用于快速创建 UML 图。UML(统一建模语言)是一种广泛使用的图形表示法,用于建模、设计和构建软件系统。然而,创建 UML 图通常是一个繁琐的过程,需要专业的绘图工具。PlantUML 旨在通过提供一种简单的、易于学习的文本语法来解决这个问题,该语法可以直接转换为 UML 图。
使用 PlantUML,您可以在文本编辑器中编写描述 UML 图的代码,然后使用 PlantUML 工具或插件将其转换为图形表示。这种方法的优点是您可以在版本控制系统中轻松管理 UML 图,因为它们只是文本文件。此外,PlantUML 还支持多种 UML 图类型,包括类图、用例图、顺序图、活动图等。
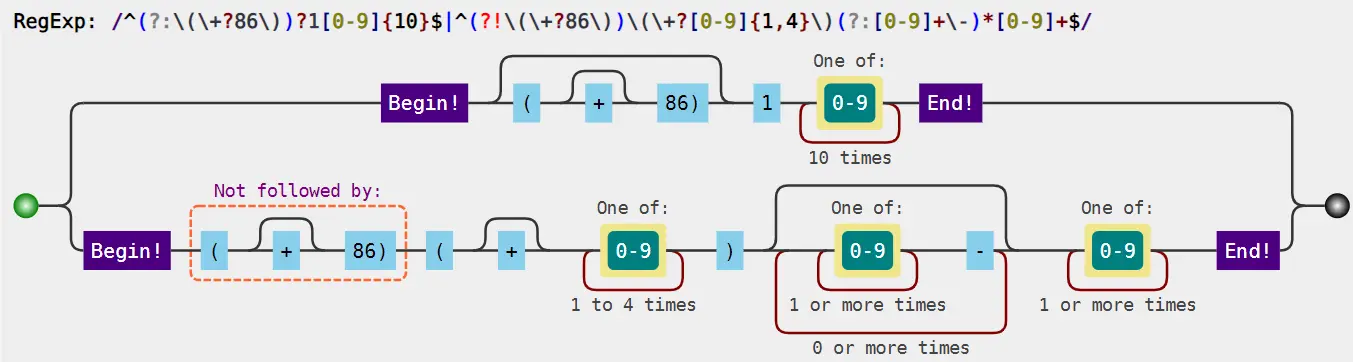
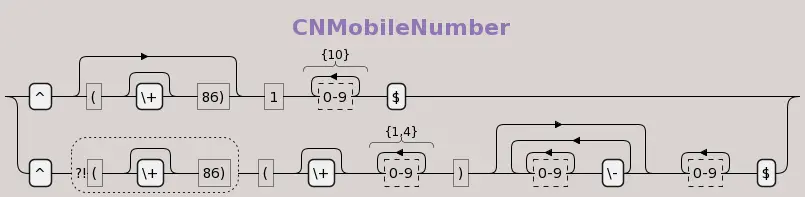
我们可以使用它提供的regex生成可视化图形。
@startregex
!theme cyborg
title CNMobileNumber
^(?:\(\+?86\))?1[0-9]{10}$|^(?!\(\+?86\))\(\+?[0-9]{1,4}\)(?:[0-9]+\-)*[0-9]+$
@endregex
常用正则
校验数字的表达式
| 正则表达式描述 | 正则表达式模式 |
|---|---|
| 数字 | ^[0-9]*$ |
| n位的数字 | ^\d{n}$ |
| 至少n位的数字 | ^\d{n,}$ |
| m-n位的数字 | ^\d{m,n}$ |
| 零和非零开头的数字 | ^(0|[1-9][0-9]*)$ |
| 非零开头的最多带两位小数的数字 | ^([1-9][0-9]*)+(\.[0-9]{1,2})?$ |
| 带1-2位小数的正数或负数 | ^(\-)?\d+(\.\d{1,2})$ |
| 正数、负数、和小数 | ^(\-|\+)?\d+(\.\d+)?$ |
| 有两位小数的正实数 | ^[0-9]+(\.[0-9]{2})?$ |
| 有1~3位小数的正实数 | ^[0-9]+(\.[0-9]{1,3})?$ |
| 非零的正整数 | ^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$ |
| 非零的负整数 | ^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$ |
| 非负整数 | ^\d+$ 或 ^[1-9]\d*|0$ |
| 非正整数 | ^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$ |
| 非负浮点数 | ^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ |
| 非正浮点数 | ^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ |
| 正浮点数 | ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ |
| 负浮点数 | ^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ |
| 浮点数 | ^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ |
校验字符的表达式
| 正则表达式描述 | 正则表达式 | ||
|---|---|---|---|
| 英文和数字 | ^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{440}$ |
||
| 长度为3-20的所有字符 | ^.{320}$ |
||
| 由26个英文字母组成的字符串 | ^[A-Za-z]+$ |
||
| 由26个大写英文字母组成的字符串 | ^[A-Z]+$ |
||
| 由26个小写英文字母组成的字符串 | ^[a-z]+$ |
||
| 由数字和26个英文字母组成的字符串 | ^[A-Za-z0-9]+$ |
||
| 由数字、26个英文字母或者下划线组成的字符串 | ^\w+$ 或 ^\w{320}$ |
||
| 中文、英文、数字包括下划线 | ^[\u4E00-\u9FA5A-Za-z0-9_]+$ |
||
| 中文、英文、数字但不包括下划线等符号 | ^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{220}$ |
||
| 可以输入含有^%&',;=?$"等字符 | [^%&',;=?$\x22]+ |
||
| 禁止输入含有~的字符 | [^~]+ |
特殊需求表达式
| 正则表达式描述 | 正则表达式 |
|---|---|
| Email地址 | ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? |
| InternetURL | [a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ |
| 手机号码 | ^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$ |
| 电话号码 | ^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$ |
| 国内电话号码 | \d{3}-\d{8}|\d{4}-\d{7} |
| 电话号码正则表达式 | ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$) |
| 身份证号 | (^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$) |
| 帐号是否合法 | ^[a-zA-Z][a-zA-Z0-9_]{4,15}$ |
| 密码 | ^[a-zA-Z]\w{5,17}$ |
| 强密码 | ^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$ |
| 强密码 | ^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ |
| 日期格式 | ^\d{4}-\d{1,2}-\d{1,2} |
| 一年的12个月 | ^(0?[1-9]|1[0-2])$ |
| 一个月的31天 | ^((0?[1-9])|((1|2)[0-9])|30|31)$ |
| xml文件 | ^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$ |
| 中文字符的正则表达式 | [\u4e00-\u9fa5] |
| 双字节字符 | [^\x00-\xff] |
| 空白行的正则表达式 | \n\s*\r |
| HTML标记的正则表达式 | <(\S*?)[^>]*>.*?|<.*? /> |
| 首尾空白字符的正则表达式 | ^\s*|\s*$或(^\s*)|(\s*$) |
| 腾讯QQ号 | [1-9][0-9]{4,} |
| 中国邮政编码 | [1-9]\d{5}(?!\d) |
| IPv4地址 | ((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3} |
钱的输入格式
| 正则表达式描述 | 正则表达式 |
|---|---|
| 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000" | ^[1-9][0-9]*$ |
| 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式 | ^(0|[1-9][0-9]*)$ |
| 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号 | ^(0|-?[1-9][0-9]*)$ |
| 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分 | ^[0-9]+(.[0-9]+)?$ |
| 必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的 | ^[0-9]+(.[0-9]{2})?$ |
| 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样 | ^[0-9]+(.[0-9]{1,2})?$ |
| 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样 | ^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$ |
| 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须 | ^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$ |
| 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?) | 最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里 |