Transformer体系结构已经成为大型语言模型(llm)成功的主要组成部分。为了进一步改进llm,人们正在研发可能优于Transformer体系结构的新体系结构。其中一种方法是Mamba(一种状态空间模型)。
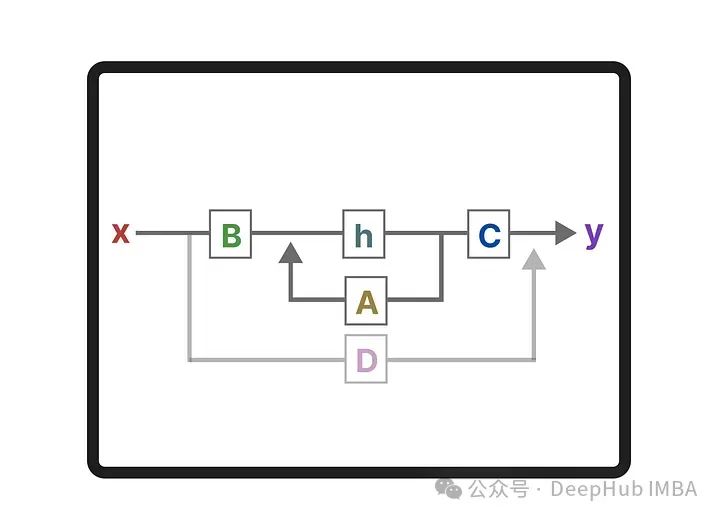
Mamba: Linear-Time Sequence Modeling with Selective State Spaces一文中提出了Mamba,我们在之前的文章中也有详细的介绍。
在本篇文章中,通过将绘制RNN,transformer,和Mamba的架构图,并进行详细的对比,这样我们可以更详细的了解它们之间的区别。
为了说明为什么Mamba是这样一个有趣的架构,让我们先介绍Transformer。
https://avoid.overfit.cn/post/94105fed36de4cd981da0b916c0ced47
标签:Transformer,架构,RNN,详细,Mamba,体系结构 From: https://www.cnblogs.com/deephub/p/18029028