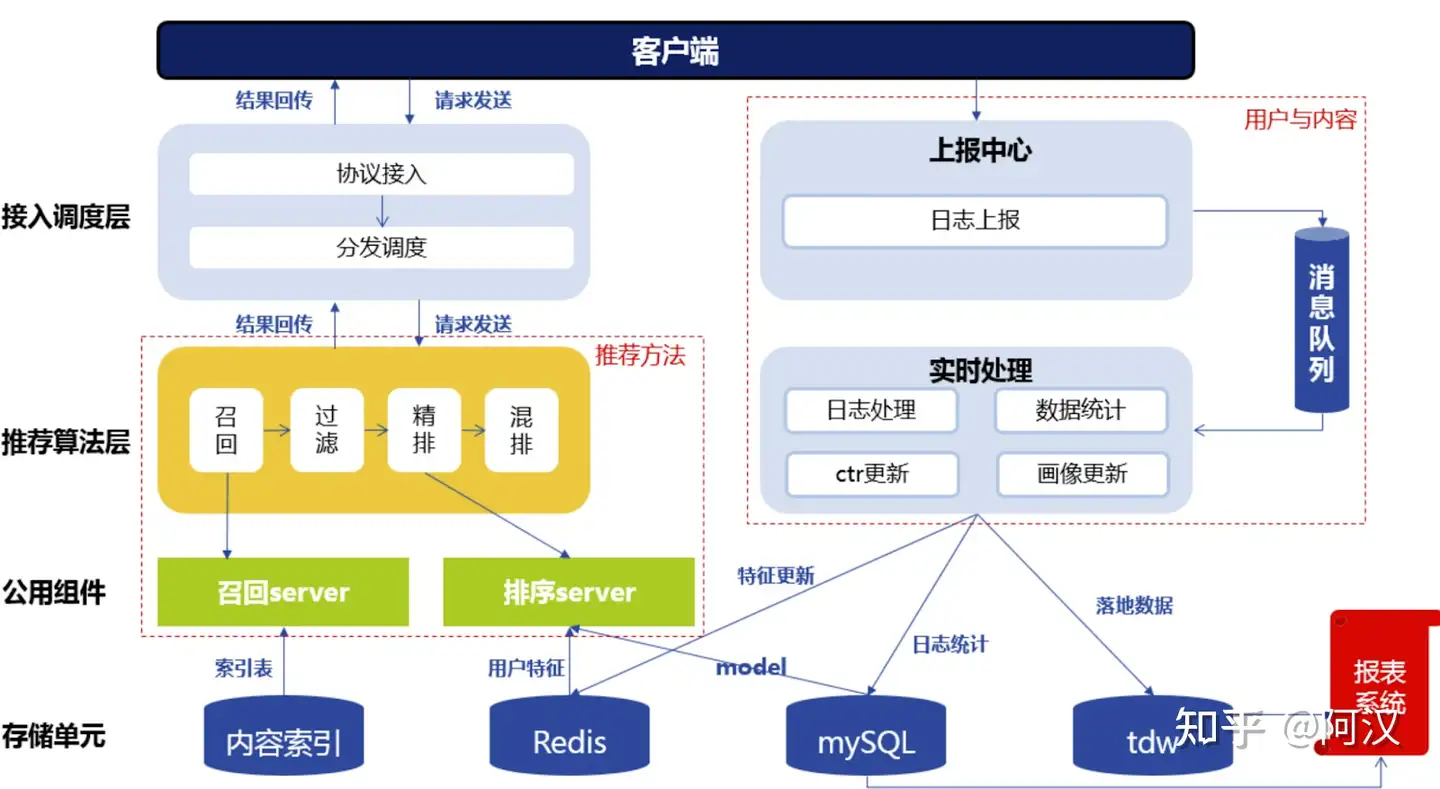
1:推荐系统简易架构图
2:推荐引擎流程图
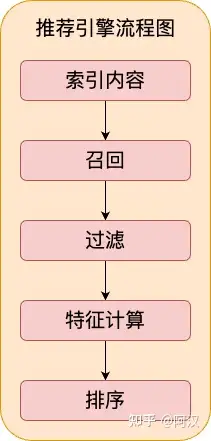
Mixer系统的用户推荐就是按照上面流程实现,接下来分别介绍各个功能
3:索引内容
1:索引目的是提供高效查询
索引内容就是将内容生产索引文件,目的是提高查询速度,不可能每个请求过来都把所有的数据查出来,然后过滤、计算特征、排序、最后将排在前面的数据推给用户,数据量实在是太多不能这么玩,所以会将一些关键数据生成索引文件,通过databus将文件推送到推荐引擎的机器上,推荐引擎加载索引文件,在内存中生成各种索引(正排索引、倒排索引等),提供快速查询。
2:怎么生成索引文件
我们把一个表的数据查出来,写入文件,那么这个文件就是索引文件,但是这个表的一些字段我们可能用不上,查出来只会增大索引文件,影响加载速度和占用多余的内存,所以我们只会将需要的字段加到索引文件中,mixer作为用户推荐系统,那么用户表是主表,还设计到用户资料表、用户兴趣表等多张表,将多张表信息和成一张表,一个用户一条记录,定义好对应的struct,填充每个用户struct中的字段,得到一个struct数组,将数组的内容以pb格式序列化写入文件,索引文件就生成了。
由于数据库中的数据会实时变化,那么我们就需要定时生成索引文件。
3:databus传输文件
索引文件我们会用一个独立的服务生成,然后通过databus服务传送到推荐引擎的机器上。这个功能可以很简单,如果你的推荐系统比较简单,生成索引的服务和推荐的服务在一台机器上,约定一个文件路径就行,定时检查文件是否变更,变更重新加载就行。
那么正常的databus怎么实现?
数据巴士就是一个文件下载服务,你可以提供ftp服务或是http服务,下面以http服务为例简要说明databus的实现,他真的太简单了。databus提供一个server端和一个client端。server定时判定索引文件有没有更新,如果有更新,更新文件路径和文件的md5,每个推荐引擎机器部署一个client,client定时请求server端,比对client和server的md5是否一致,如果不一致说明文件更新了,就下载文件。可能你觉得定时请求有些没必要,想减少没必要的http请求,那么server只需要发现文件变更就通知所有客户端,你可以用etcd作为通知工具,但我们也要考虑引入一个中间件带来的问题,有可能是中间的问题,或是你使用的问题导致client没有加载最新的索引文件。
client下载索引文件放到指定路径,推荐引擎检测到文件变更,加载最新文件,实现索引文件传输。
4:内存中建立索引
推荐引擎加载索引文件建立内存索引,这块是核心。
索引文件我们可以理解成一张表,然后我们在内存中给这张表建立索引,比如我想按照性别查询、按照学历查询、按照年龄范围查询、按照城市id查询,我们可以将这4个查询分成2类,一类是这个字段的值是固定的几个(性别:0无,1男,2女;学历:0~7),第二类字段的值是多个的(年龄:18~150;城市id可能有几百个)
第一类的倒排索引可以用BitMap实现。
以性别为例,性别有3个值,我们建立3个BitMap为[3]BitMap,第一个性别bitmap表示无,第二个BitMap表示男,第三个BitMap表示女。比如我们有100W个用户,那么一个BitMap就是一个长度为15625的[]uint64,一个bit位对应一个用户,那么这个bitmap占用15625*8=122K,3个bitmap占用366K,占用内存是非常少的。
type BitMap []uint64
func NewBitMap(length int) BitMap { bitLen := (length + 63) / 64 return make([]uint64, bitLen) }
bt := NewBitMap(1000000) // 15625 = (1000000 +63) / 64
BitMap怎么赋值?
如第100个用户是男性,男性对应第二个bitmap,将[]uint64的100位设置成1,是第100位不是数组下标100。遍历这100w个用户,按照性别和下标设置对应bitmap的二进制位的值,把bitmap看成二进制数组就行,它的值只有0和1。
BitMap怎么查询?
如果我要给一个用户推荐男性用户,那么第二个BitMap中二进制位为1的下标的集合就是100W个用户组数中男性的集合,当然我们不需要现在就取出所有男性的信息,因为查询条件可能是:男性+本科+25岁+北京。索引性别只需要取第二个BitMap就行,索引查询性别就是取数组下标为1的元素,还有比这还快的查询吗?
同样的学历定义为bt := [8]BitMap,本科只需要取bt[4],快得飞起,然后把学历和性别的两个BitMap取交集,就是SQL中的and,得到一个BitMap,二进制位1的用户就是我们要找的用户。时间复杂度是O(1)
第一类的倒排索引可以用排序+BitMap实现。
像年龄有100多个,城市有几百个,我们不能建立几百个BitMap的数组,那样占用内存较多,而且这些值随时变多,用固定长度数组不好解决,我们只能提前排好序,通过二分查找+遍历的方式实现,二分查找时间复杂度O(log n)。
比如年龄我们可以定义一下结构
type IndexAge struct {
Index uint32 //数组下标值,数组为100W用户数组
Age uint32 //用户对应的年龄
}
100W用户就定义[1000000]IndexAge,然后Age排序,如何按照年龄范围查找,以查找年龄范围是[18,25]为例,通过二分查找找到第一个年龄=18的用户,然后往后遍历直到年龄>25为止,Index指定的下标用户几位所求。类似mysql的between and。年龄查询时间复杂度O(n log n)。
不用BitMap,用数组也行,但每个索引的内存占用会扩大到八倍
5:召回
召回就是通过内存索引进行查询,然后取交集,如查找:性别男 + 学历(本科/硕士)+年龄(18~25)+城市(北京/上海)。
性别男,直接取下标,得到一个BitMap
学历(本科/硕士),直接取2次下标,得到本科BitMap和硕士BitMap,两个BitMap取并集,得类似mysql中的or,到一个BitMap
年龄(18~25),二分查找+遍历,类似mysql的between and,得到一个BitMap
城市(北京/上海),两次二分查找+遍历,类似mysql的in,得到两BitMap后取并集得到一个BitMap
然后4个BitMap取交集得到一个BitMap,BitMap为1的就是我们要找的用户。
6:过滤
作为用户推荐系统
1:推荐过的用户一天总不能推2次吧
2:不能把自己推荐给自己
3:我拉黑的人不能推荐给我
4:把我拉黑的人不能推荐给我
5:我喜欢的人,就不要再推荐给我了
6:………..
这些数据都会存在数据库中,同时在redis中保存一份对应的uid,这些都是要过滤的用户,通过查询redis得到所有要过滤的uid,将这些uid存到map中,将召回的用户列表都到map中判断一下是否存在,存在就被过滤,golang的map查询时间复杂度是O(1),遍历用户列表时间复杂度是O(n),整个过滤的时间复杂度是O(n)
7:特征计算
过滤完后得到一个用户列表,根据每个用户的特征信息,每个特征一个分值,然后按照一个公式,计算得到一个最终的分值。就像学生每门课成绩有一个分值,这里的公式可能不是简单的相加,而是按照业务随时调整的公式
8:排序
特征计算已经得到一个分值,按照这个分值排序,取top30推荐给用户,一个简单的推荐系统就完成了。
标签:文件,推荐,用户,介绍,BitMap,索引,原理,查询 From: https://www.cnblogs.com/hlxs/p/18002717