32.有哪些常用的命令行性能监控和故障处理工具?
-
操作系统工具
- top:显示系统整体资源使用情况
- vmstat:监控内存和 CPU
- iostat:监控 IO 使用
- netstat:监控网络使用
-
JDK 性能监控工具
- jps:虚拟机进程查看
- jstat:虚拟机运行时信息查看
- jinfo:虚拟机配置查看
- jmap:内存映像(导出)
- jhat:堆转储快照分析
- jstack:Java 堆栈跟踪
- jcmd:实现上面除了 jstat 外所有命令的功能
33.了解哪些可视化的性能监控和故障处理工具?
以下是一些 JDK 自带的可视化性能监控和故障处理工具:
- JConsole
JConsole概览
- VisualVM
VisualVM安装插件
- Java Mission Control
JMC主要界面
除此之外,还有一些第三方的工具:
- MAT
Java 堆内存分析工具。
- GChisto
GC 日志分析工具。
- GCViewer
GC 日志分析工具。
- JProfiler
商用的性能分析利器。
- arthas
阿里开源诊断工具。
- async-profiler
Java 应用性能分析工具,开源、火焰图、跨平台。
34.JVM 的常见参数配置知道哪些?
一些常见的参数配置:
堆配置:
- -Xms:初始堆大小
- -Xms:最大堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为 3 表示年轻代和年老代比值为 1:3,年轻代占整个年轻代年老代和的 1/4
- -XX:SurvivorRatio=n:年轻代中 Eden 区与两个 Survivor 区的比值。注意 Survivor 区有两个。如 3 表示 Eden: 3 Survivor:2,一个 Survivor 区占整个年轻代的 1/5
- -XX:MaxPermSize=n:设置持久代大小
收集器设置:
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的 CPU 数。并行收集线程数
- -XX:MaxGCPauseMillis=n:设置并行收集最大的暂停时间(如果到这个时间了,垃圾回收器依然没有回收完,也会停止回收)
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为:1/(1+n)
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单 CPU 情况
- -XX:ParallelGCThreads=n:设置并发收集器年轻代手机方式为并行收集时,使用的 CPU 数。并行收集线程数
打印 GC 回收的过程日志信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
35.有做过 JVM 调优吗?
JVM 调优是一件很严肃的事情,不是拍脑门就开始调优的,需要有严密的分析和监控机制,大概的一个 JVM 调优流程图:
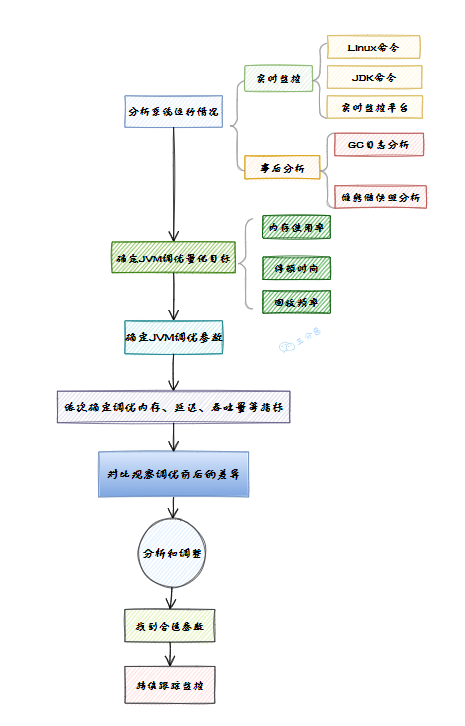
JVM调优大致流程图
实际上,JVM 调优是不得已而为之,有那功夫,好好把烂代码重构一下不比瞎调 JVM 强。
但是,面试官非要问怎么办?可以从处理问题的角度来回答(对应图中事后),这是一个中规中矩的案例:电商公司的运营后台系统,偶发性的引发 OOM 异常,堆内存溢出。
1)因为是偶发性的,所以第一次简单的认为就是堆内存不足导致,单方面的加大了堆内存从 4G 调整到 8G -Xms8g。
2)但是问题依然没有解决,只能从堆内存信息下手,通过开启了-XX:+HeapDumpOnOutOfMemoryError 参数 获得堆内存的 dump 文件。
3)用 JProfiler 对 堆 dump 文件进行分析,通过 JProfiler 查看到占用内存最大的对象是 String 对象,本来想跟踪着 String 对象找到其引用的地方,但 dump 文件太大,跟踪进去的时候总是卡死,而 String 对象占用比较多也比较正常,最开始也没有认定就是这里的问题,于是就从线程信息里面找突破点。
4)通过线程进行分析,先找到了几个正在运行的业务线程,然后逐一跟进业务线程看了下代码,有个方法引起了我的注意,导出订单信息。
5)因为订单信息导出这个方法可能会有几万的数据量,首先要从数据库里面查询出来订单信息,然后把订单信息生成 excel,这个过程会产生大量的 String 对象。
6)为了验证自己的猜想,于是准备登录后台去测试下,结果在测试的过程中发现导出订单的按钮前端居然没有做点击后按钮置灰交互事件,后端也没有做防止重复提交,因为导出订单数据本来就非常慢,使用的人员可能发现点击后很久后页面都没反应,然后就一直点,结果就大量的请求进入到后台,堆内存产生了大量的订单对象和 EXCEL 对象,而且方法执行非常慢,导致这一段时间内这些对象都无法被回收,所以最终导致内存溢出。
7)知道了问题就容易解决了,最终没有调整任何 JVM 参数,只是做了两个处理:
- 在前端的导出订单按钮上加上了置灰状态,等后端响应之后按钮才可以进行点击
- 后端代码加分布式锁,做防重处理
这样双管齐下,保证导出的请求不会一直打到服务端,问题解决!
36.线上服务 CPU 占用过高怎么排查?
问题分析:CPU 高一定是某个程序长期占用了 CPU 资源。
CPU飙高
1)所以先需要找出那个进程占用 CPU 高。
- top 列出系统各个进程的资源占用情况。
2)然后根据找到对应进行里哪个线程占用 CPU 高。
- top -Hp 进程 ID 列出对应进程里面的线程占用资源情况
3)找到对应线程 ID 后,再打印出对应线程的堆栈信息
- printf "%x\n" PID 把线程 ID 转换为 16 进制。
- jstack PID 打印出进程的所有线程信息,从打印出来的线程信息中找到上一步转换为 16 进制的线程 ID 对应的线程信息。
4)最后根据线程的堆栈信息定位到具体业务方法,从代码逻辑中找到问题所在。
查看是否有线程长时间的 watting 或 blocked,如果线程长期处于 watting 状态下, 关注 watting on xxxxxx,说明线程在等待这把锁,然后根据锁的地址找到持有锁的线程。
37.内存飙高问题怎么排查?
分析: 内存飚高如果是发生在 java 进程上,一般是因为创建了大量对象所导致,持续飚高说明垃圾回收跟不上对象创建的速度,或者内存泄露导致对象无法回收。
1)先观察垃圾回收的情况
- jstat -gc PID 1000 查看 GC 次数,时间等信息,每隔一秒打印一次。
- jmap -histo PID | head -20 查看堆内存占用空间最大的前 20 个对象类型,可初步查看是哪个对象占用了内存。
如果每次 GC 次数频繁,而且每次回收的内存空间也正常,那说明是因为对象创建速度快导致内存一直占用很高;如果每次回收的内存非常少,那么很可能是因为内存泄露导致内存一直无法被回收。
2)导出堆内存文件快照
- jmap -dump:live,format=b,file=/home/myheapdump.hprof PID dump 堆内存信息到文件。
3)使用 visualVM 对 dump 文件进行离线分析,找到占用内存高的对象,再找到创建该对象的业务代码位置,从代码和业务场景中定位具体问题。
38.频繁 minor gc 怎么办?
优化 Minor GC 频繁问题:通常情况下,由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此可以通过增大新生代空间-Xmn来降低 Minor GC 的频率。
39.频繁 Full GC 怎么办?
Full GC 的排查思路大概如下:
1)清楚从程序角度,有哪些原因导致 FGC?
- 大对象:系统一次性加载了过多数据到内存中(比如 SQL 查询未做分页),导致大对象进入了老年代。
- 内存泄漏:频繁创建了大量对象,但是无法被回收(比如 IO 对象使用完后未调用 close 方法释放资源),先引发 FGC,最后导致 OOM.
- 程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,最后引发 FGC. (即本文中的案例)
- 程序 BUG
- 代码中显式调用了 gc方法,包括自己的代码甚至框架中的代码。
- JVM 参数设置问题:包括总内存大小、新生代和老年代的大小、Eden 区和 S 区的大小、元空间大小、垃圾回收算法等等。
2)清楚排查问题时能使用哪些工具
- 公司的监控系统:大部分公司都会有,可全方位监控 JVM 的各项指标。
- JDK 的自带工具,包括 jmap、jstat 等常用命令:
查看堆内存各区域的使用率以及GC情况
jstat -gcutil -h20 pid 1000
查看堆内存中的存活对象,并按空间排序
jmap -histo pid | head -n20
dump堆内存文件
jmap -dump:format=b,file=heap pid
- 可视化的堆内存分析工具:JVisualVM、MAT 等
3)排查指南
- 查看监控,以了解出现问题的时间点以及当前 FGC 的频率(可对比正常情况看频率是否正常)
- 了解该时间点之前有没有程序上线、基础组件升级等情况。
- 了解 JVM 的参数设置,包括:堆空间各个区域的大小设置,新生代和老年代分别采用了哪些垃圾收集器,然后分析 JVM 参数设置是否合理。
- 再对步骤 1 中列出的可能原因做排除法,其中元空间被打满、内存泄漏、代码显式调用 gc 方法比较容易排查。
- 针对大对象或者长生命周期对象导致的 FGC,可通过 jmap -histo 命令并结合 dump 堆内存文件作进一步分析,需要先定位到可疑对象。
- 通过可疑对象定位到具体代码再次分析,这时候要结合 GC 原理和 JVM 参数设置,弄清楚可疑对象是否满足了进入到老年代的条件才能下结论。
40.有没有处理过内存泄漏问题?是如何定位的?
内存泄漏是内在病源,外在病症表现可能有:
- 应用程序长时间连续运行时性能严重下降
- CPU 使用率飙升,甚至到 100%
- 频繁 Full GC,各种报警,例如接口超时报警等
- 应用程序抛出
OutOfMemoryError错误 - 应用程序偶尔会耗尽连接对象
严重内存泄漏往往伴随频繁的 Full GC,所以分析排查内存泄漏问题首先还得从查看 Full GC 入手。主要有以下操作步骤:
1)使用 jps 查看运行的 Java 进程 ID
2)使用top -p [pid] 查看进程使用 CPU 和 MEM 的情况
3)使用 top -Hp [pid] 查看进程下的所有线程占 CPU 和 MEM 的情况
4)将线程 ID 转换为 16 进制:printf "%x\n" [pid],输出的值就是线程栈信息中的 nid。
例如:printf "%x\n" 29471,换行输出 731f。
5)抓取线程栈:jstack 29452 > 29452.txt,可以多抓几次做个对比。
在线程栈信息中找到对应线程号的 16 进制值,如下是 731f 线程的信息。线程栈分析可使用 Visualvm 插件 TDA。
"Service Thread" 7 daemon prio=9 os_prio=0 tid=0x00007fbe2c164000 nid=0x731f runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
6)使用jstat -gcutil [pid] 5000 10 每隔 5 秒输出 GC 信息,输出 10 次,查看 YGC 和 Full GC 次数。通常会出现 YGC 不增加或增加缓慢,而 Full GC 增加很快。
或使用 jstat -gccause [pid] 5000 ,同样是输出 GC 摘要信息。
或使用 jmap -heap [pid] 查看堆的摘要信息,关注老年代内存使用是否达到阀值,若达到阀值就会执行 Full GC。
7)如果发现 Full GC 次数太多,就很大概率存在内存泄漏了
8)使用 jmap -histo:live [pid] 输出每个类的对象数量,内存大小(字节单位)及全限定类名。
9)生成 dump 文件,借助工具分析哪 个对象非常多,基本就能定位到问题在那了
使用 jmap 生成 dump 文件:
jmap -dump:live,format=b,file=29471.dump 29471
Dumping heap to /root/dump ...
Heap dump file created
10)dump 文件分析
可以使用 jhat 命令分析:jhat -port 8000 29471.dump,浏览器访问 jhat 服务,端口是 8000。
通常使用图形化工具分析,如 JDK 自带的 jvisualvm,从菜单 > 文件 > 装入 dump 文件。
或使用第三方式具分析的,如 JProfiler 也是个图形化工具,GCViewer 工具。Eclipse 或以使用 MAT 工具查看。或使用在线分析平台 GCEasy。
注意:如果 dump 文件较大的话,分析会占比较大的内存。
11)在 dump 文析结果中查找存在大量的对象,再查对其的引用。
基本上就可以定位到代码层的逻辑了。
41.有没有处理过内存溢出问题?
内存泄漏和内存溢出二者关系非常密切,内存溢出可能会有很多原因导致,内存泄漏最可能的罪魁祸首之一。
排查过程和排查内存泄漏过程类似。
标签:dump,对象,面试,XX,GC,内存,JVM,线程,优化 From: https://www.cnblogs.com/pxzbky/p/17995740