一.Langchain-Chatchat 知识库管理
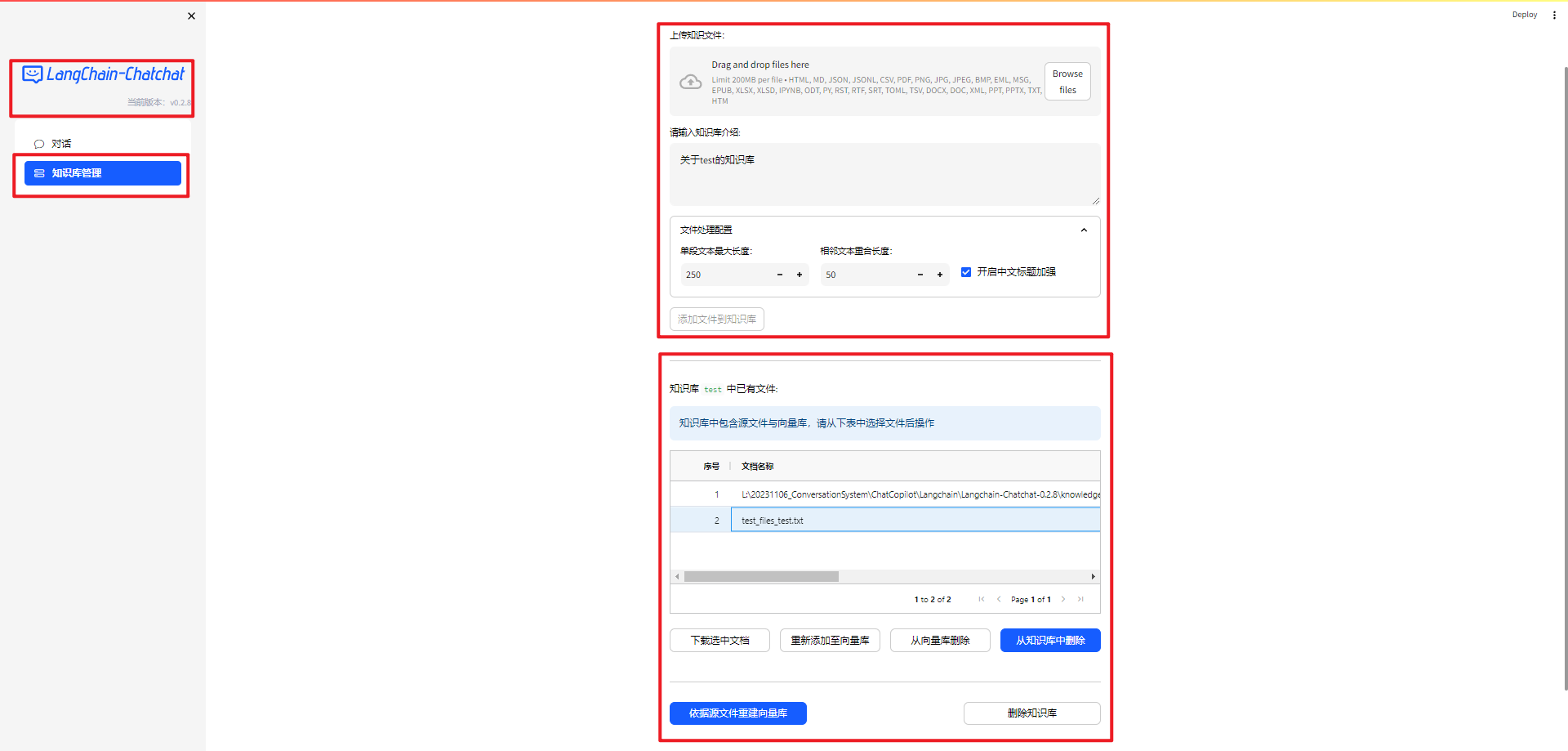
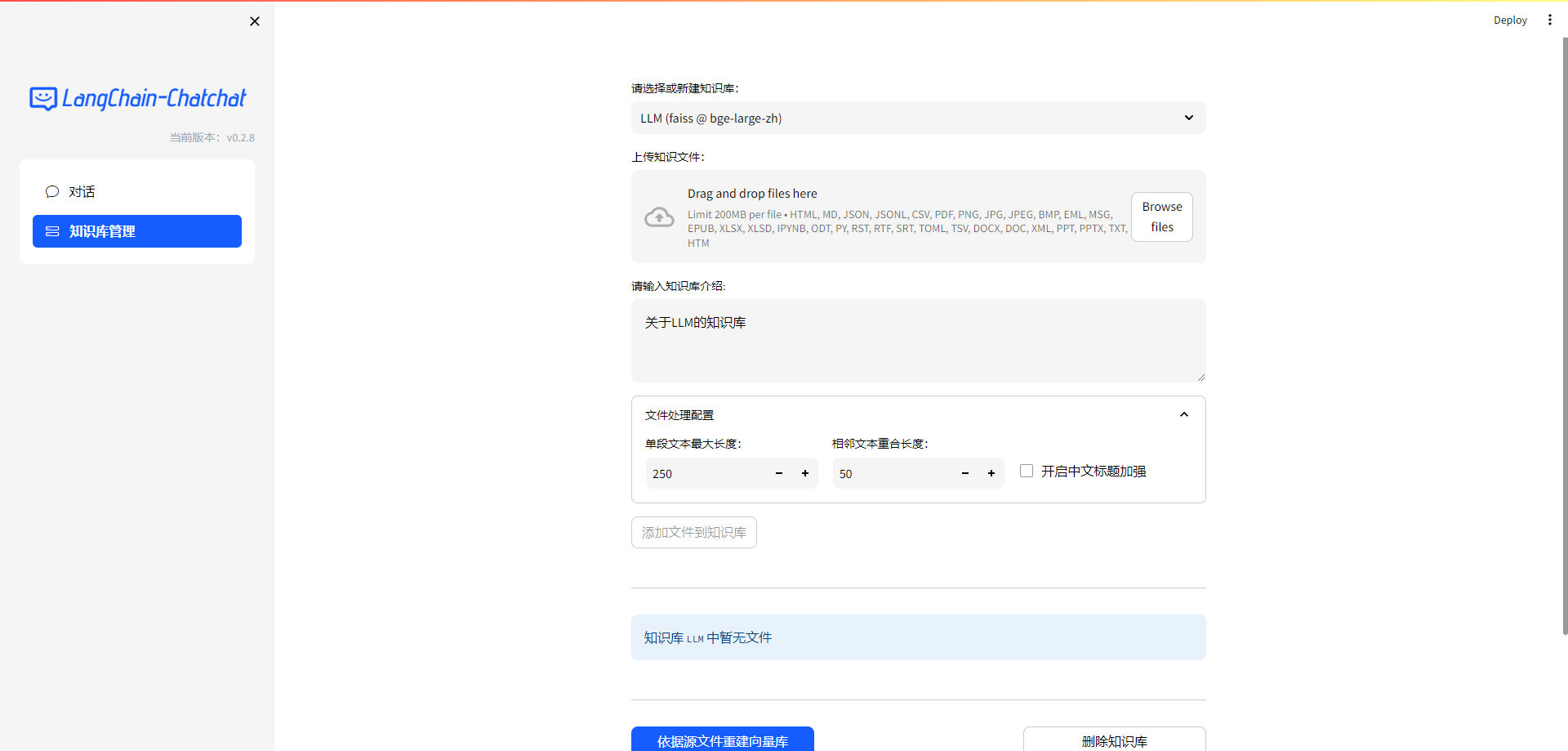
1.Langchain-Chatchat 对话和知识库管理界面
Langchain-Chatchat v0.28 完整的界面截图,如下所示:
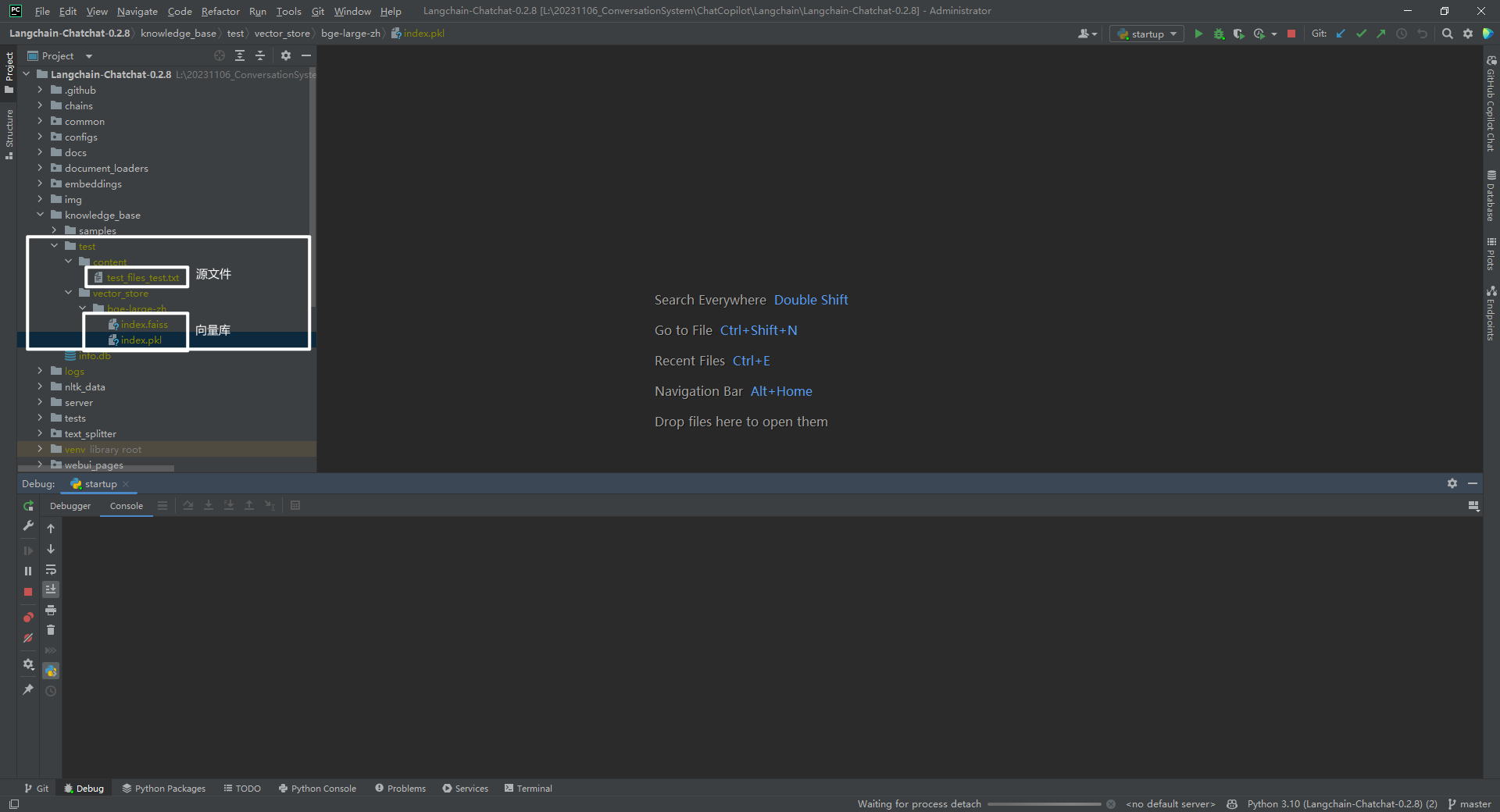
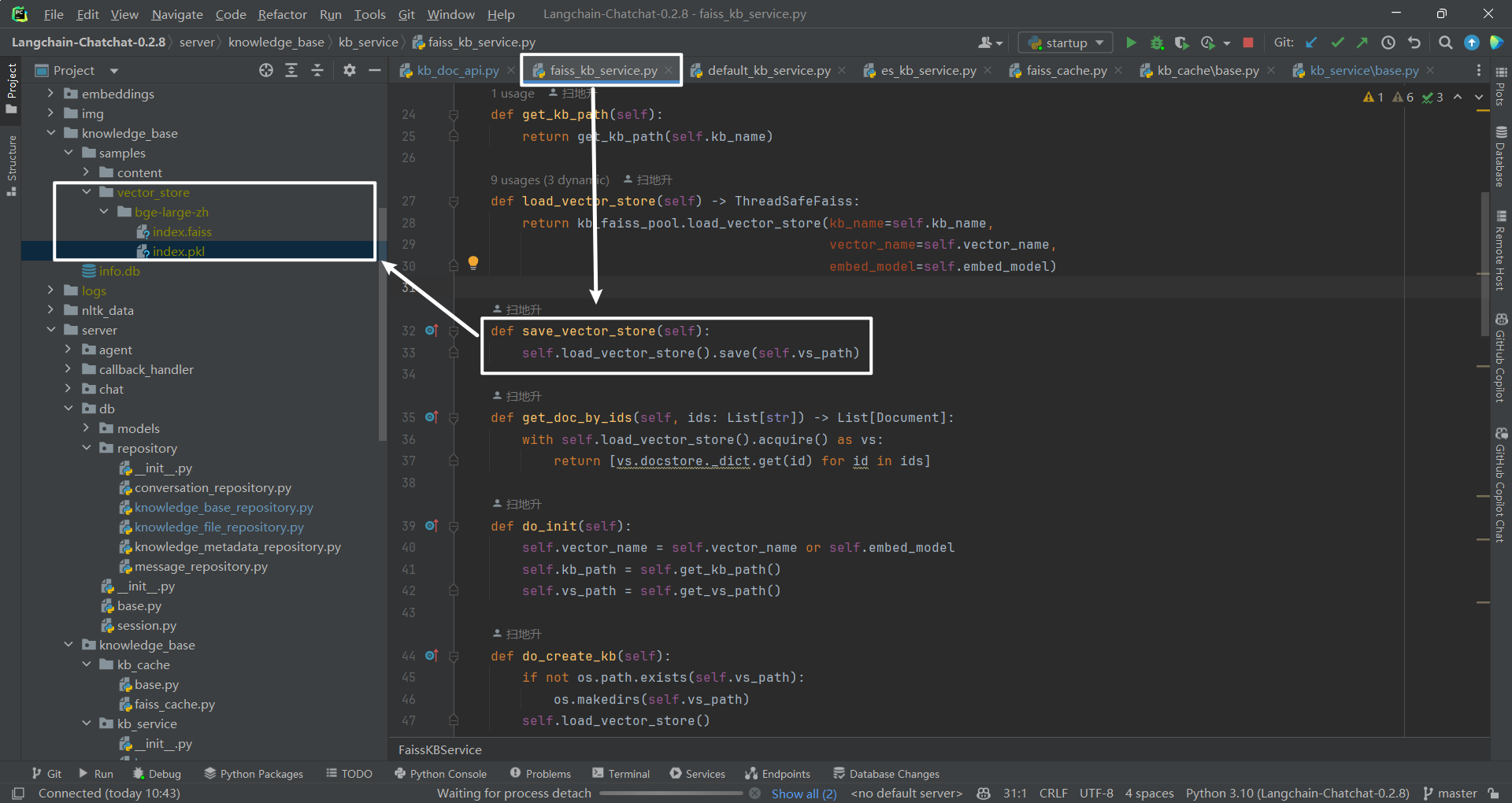
2.知识库中源文件和向量库
知识库 test 中源文件和向量库的位置,如下所示:
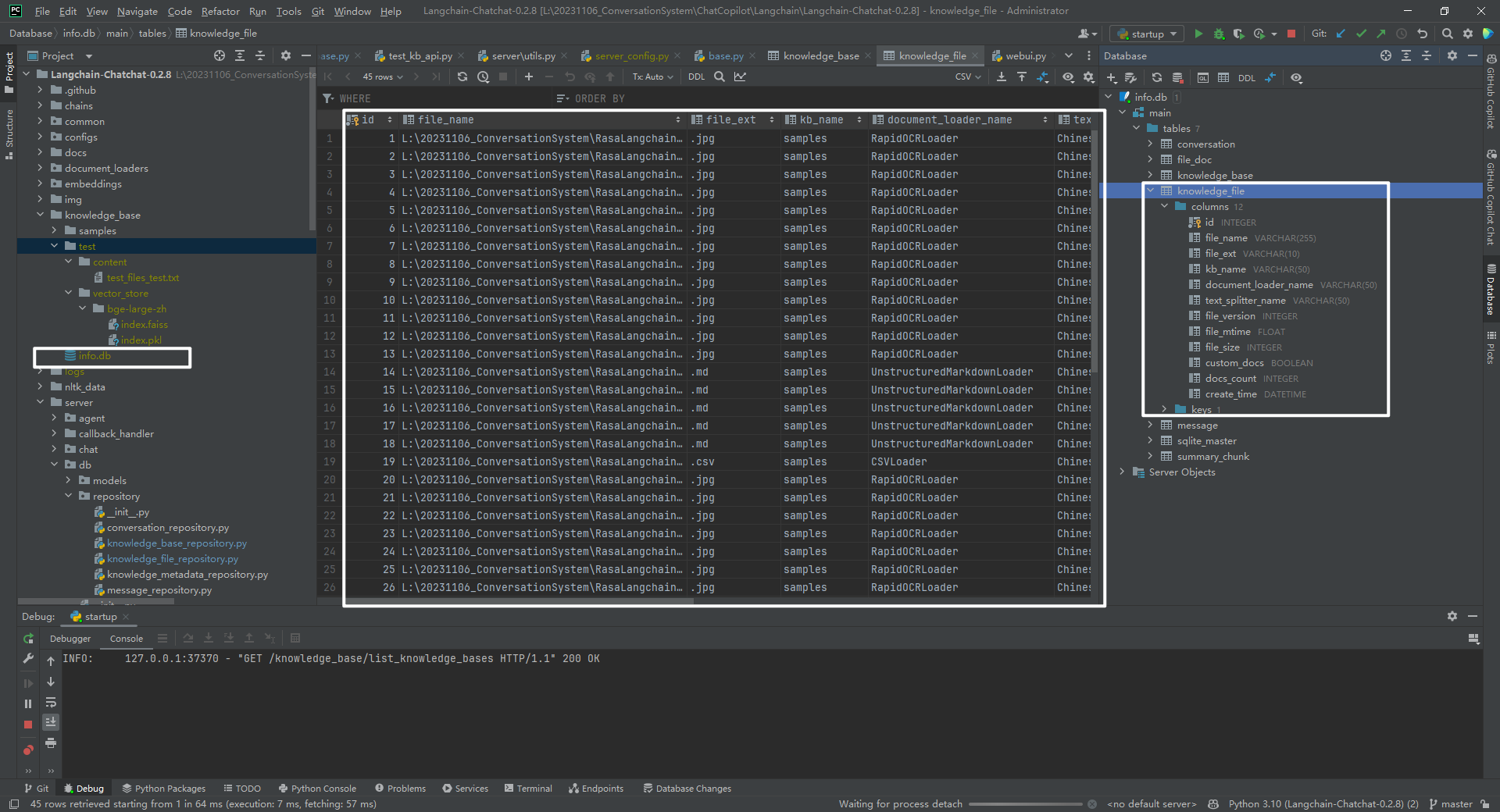
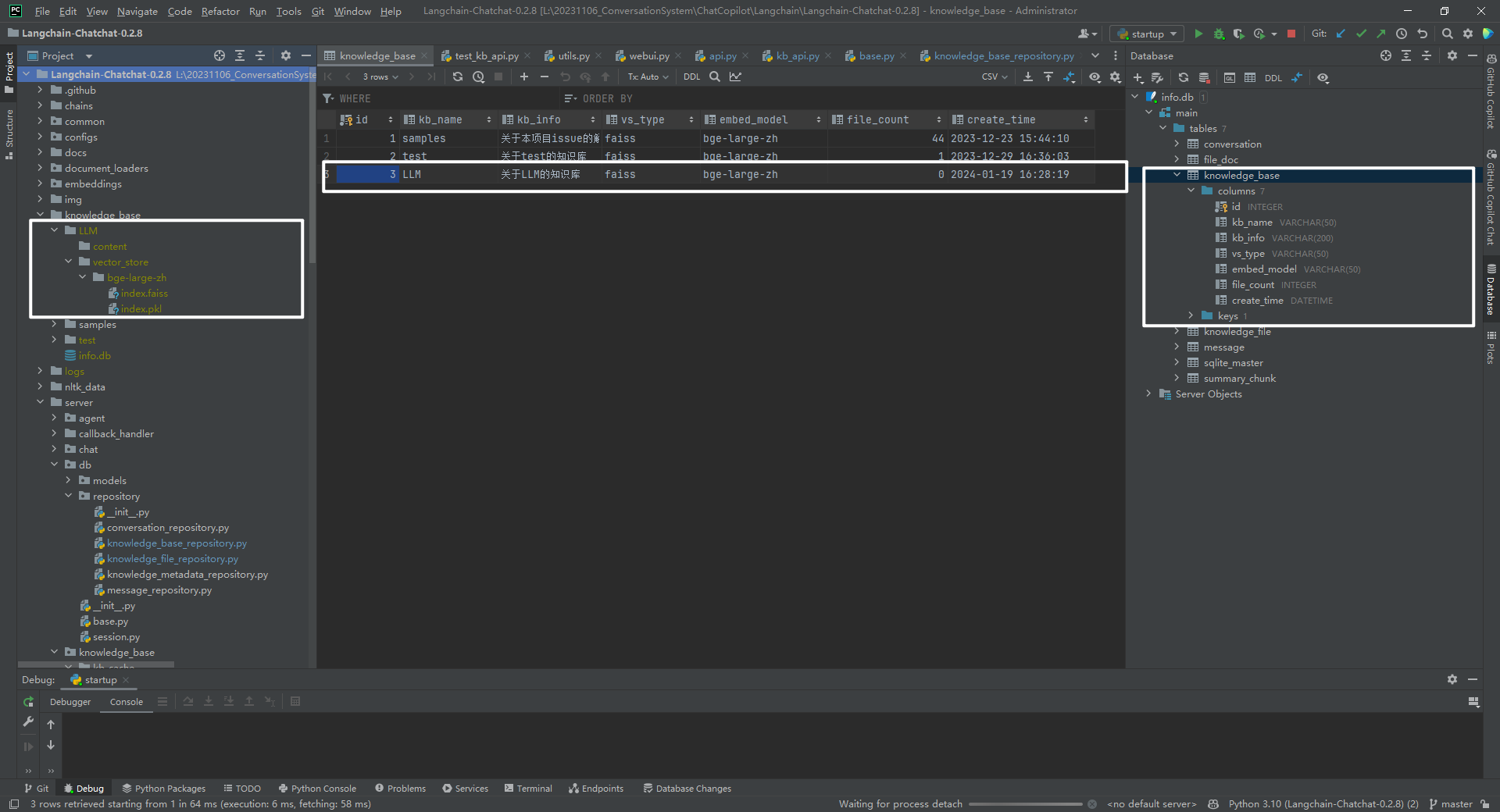
3.知识库表结构
knowledge_base 数据表内容,如下所示:
二.知识库操作 1
序号
操作名字
功能解释
链接
备注
1
获取知识库列表
就是上面的 samples(faiss @ bge-large-zh)和 test (faiss @ bge-large-zh)。
http://127.0.0.1/knowledge_base/list_knowledge_bases -
2
选择知识库
选中一个知识库
没有对应 API 接口
-
3
新建知识库
新建一个知识库
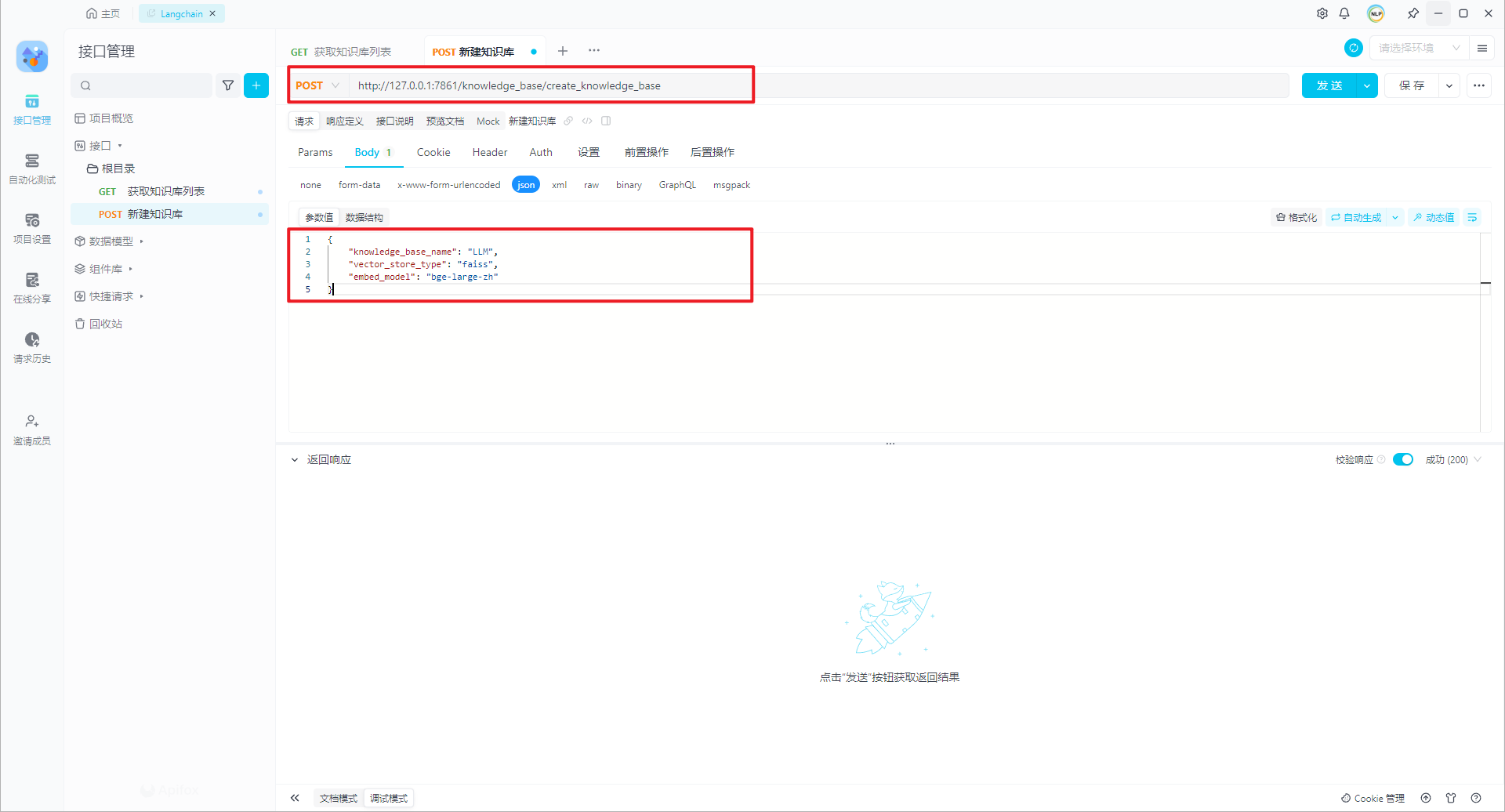
http://127.0.0.1/knowledge_base/create_knowledge_base ,如下所示:{ "knowledge_base_name": "LLM", "vector_store_type": "faiss", "embed_model": "bge-large-zh"}创建知识库
4
上传知识文件
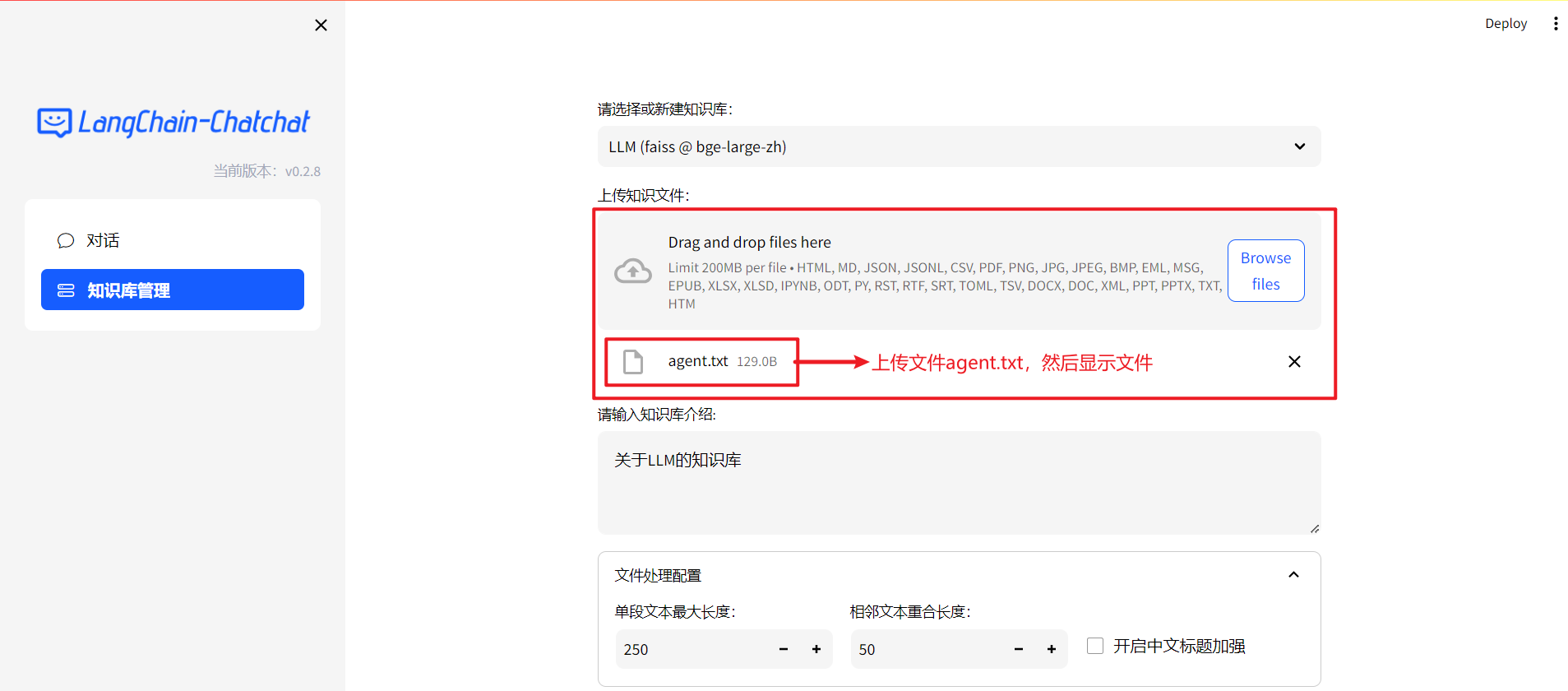
向知识库上传文件,比如限制每个文件 200MB,类型可为 HTML, MD, JSON, JSONL, CSV, PDF, PNG, JPG, JPEG, BMP, EML, MSG, EPUB, XLSX, XLSD, IPYNB, ODT, PY, RST, RTF, SRT, TOML, TSV, DOCX, DOC, XML, PPT, PPTX, TXT, HTM
只是上传并显示了一个文件,并没有真的将文件上传到知识库中。
-
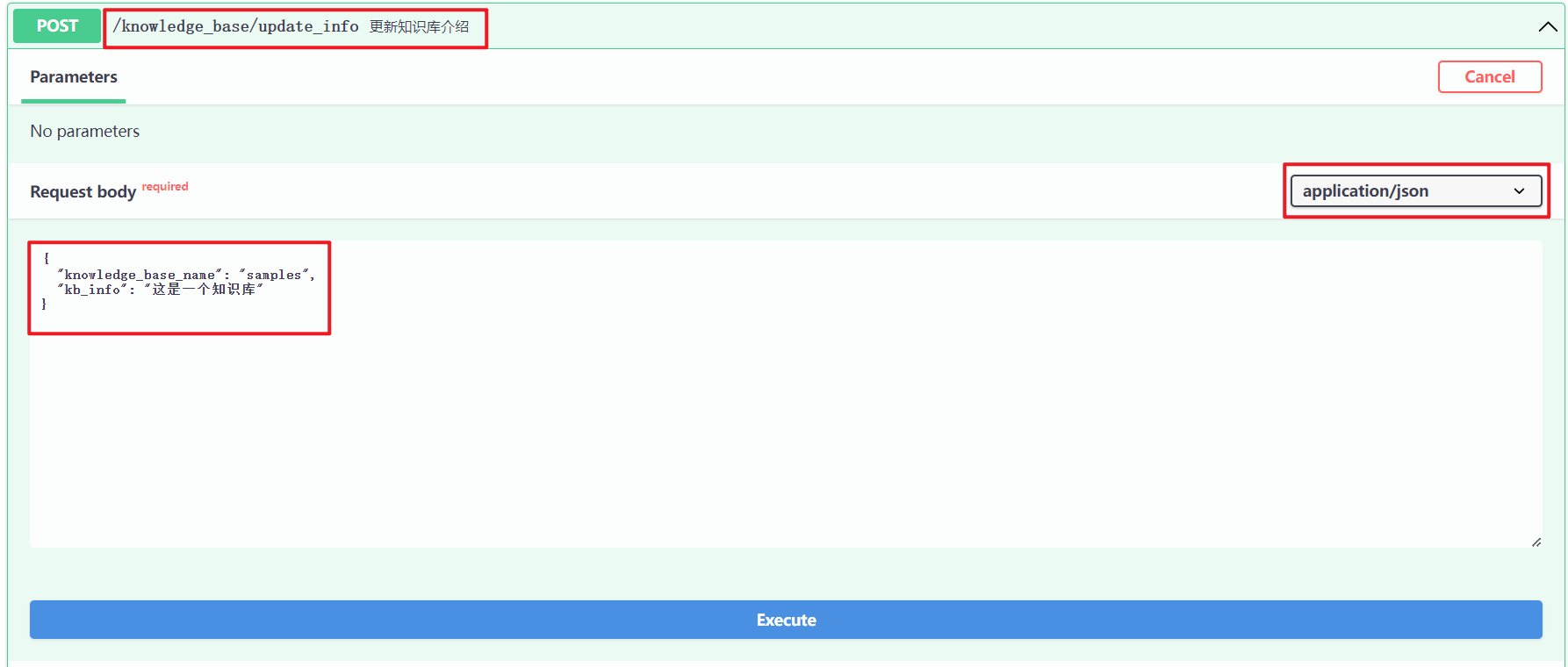
5
知识库介绍
知识库描述
http://127.0.0.1/knowledge_base/update_info ,如下所示:{ "knowledge_base_name": "samples", "kb_info": "这是一个知识库"}-
6
单段文本最大长度
就是将长文本分割成多个较短的段落,每个段落的长度都不超过这个限制。
可通过更新现有文件到知识库接口 update_docs 实现。
-
7
相邻文本重合长度
将长文本分割成多个较短的段落时,相邻段落之间重复的文本的长度。这通常是为了确保 LLM 能够理解文本的上下文。
可通过更新现有文件到知识库接口 update_docs 实现。
-
8
开启中文标题加强
参考 kb_config.py 解释:1.是否开启中文标题加强,以及标题增强的相关配置;2.通过增加标题判断,判断哪些文本为标题,并在 metadata 中进行标记;3.然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
可通过更新现有文件到知识库接口 update_docs 实现。
-
9
添加文件到知识库
将上传的文件添加到知识库中
http://127.0.0.1/knowledge_base/upload_docs 说明:接口调用格式 POST -> Body -> form-data。-
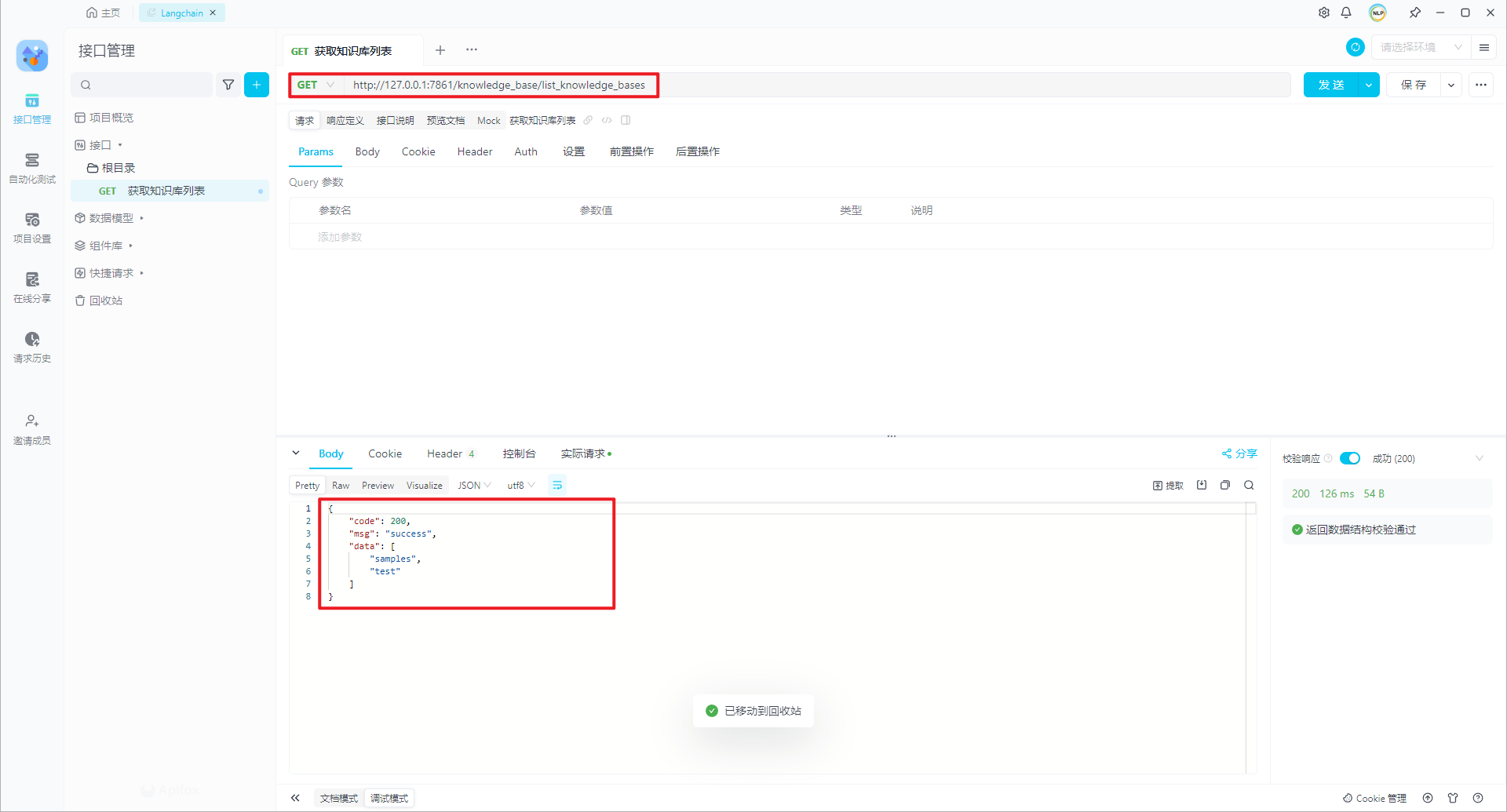
1.获取知识库列表
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.get("/knowledge_base/list_knowledge_bases", L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_api.py,如下所示:
def list_kbs(): L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\db\repository\knowledge_base_repository.py,如下所示:
@with_session http://127.0.0.1/knowledge_base/list_knowledge_bases ,返回结果:
{2.选中知识库
选中知识库并没有对应的接口,主要是选中知识库后,更新界面的(1)知识库介绍(2)知识库文档信息,包括源文件(遍历文件夹)和向量库(遍历数据库)。
(1)遍历文件夹
比如 test 知识库对应的 L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\test 文件夹。
(2)遍历数据库
主要是 knowledge_file 数据表,包括 id、file_name、file_ext、kb_name、document_loader_name、text_splitter_name、file_version、file_mtime(文件修改时间)、file_size(单位)、custom_docs(自定义文档)、docs_count、create_time。
3.新建知识库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/create_knowledge_base",(1)拿到 FaissKBService 实例
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_api.py
def create_kb(knowledge_base_name: str = Body(..., examples=["samples"]),(2)创建知识库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_service\base.py,如下所示:
def create_kb(self):(3)添加知识库到数据库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\db\repository\knowledge_base_repository.py,如下所示:
@with_session(4)接口调用
http://127.0.0.1/knowledge_base/create_knowledge_base ,如下所示:
{ 特别说明:没有找到知识库简介字段(确定没有)。参考更新知识库介绍/knowledge_base/update_info。
数据表 knowledge_base 信息,如下所示:
LangChain-Chatchat 知识库管理界面信息,如下所示:
4.上传知识文件
st.file_uploader 创建一个文件上传组件,显示一个选择文件的按钮。如下所示:
files = st.file_uploader("上传知识文件:", 只是显示了一个文件,并没有真的将文件上传到知识库中。
5.知识库介绍
(1)知识库更新实现
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/update_info", 对应的接口实现,如下所示:
def update_info( 本质上还是更新数据库 knowledge_base,对知识库介绍字段进行更新。
(2)接口调用
http://127.0.0.1/knowledge_base/update_info ,如下所示:
6.单段文本最大长度
可通过更新现有文件到知识库接口 update_docs 实现。
7.相邻文本重合长度
可通过更新现有文件到知识库接口 update_docs 实现。
8.开启中文标题加强
可通过更新现有文件到知识库接口 update_docs 实现。
9.添加文件到知识库,并/或向量化
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/upload_docs",(1)upload_docs 函数
def upload_docs(
序号
字段名
类型
解释
备注
1
file
List[UploadFile]
上传文件,支持多文件
-
2
knowledge_base_name
str
知识库名称
-
3
override
bool
覆盖已有文件
-
4
to_vector_store
bool
上传文件后是否进行向量化
-
5
chunk_size
int
知识库中单段文本最大长度
就是将长文本分割成多个较短的段落,每个段落的长度都不超过这个限制。
6
chunk_overlap
int
知识库中相邻文本重合长度
将长文本分割成多个较短的段落时,相邻段落之间重复的文本的长度。这通常是为了确保 LLM 能够理解文本的上下文。
7
zh_title_enhance
bool
是否开启中文标题加强
参考 kb_config.py 解释:1.是否开启中文标题加强,以及标题增强的相关配置;2.通过增加标题判断,判断哪些文本为标题,并在 metadata 中进行标记;3.然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
8
docs
Json
自定义的 docs,需要转为 json 字符串
推测自定义文档主要是为了测试用途(不清楚还有没有其它的用途)。
9
not_refresh_vs_cache
bool
暂不保存向量库(用于 FAISS)
目前支持 FAISS,是否保存向量库。
(2)先将上传的文件保存到磁盘
不再解释,就是将上传的文件保存到知识库本地相应的文件夹中。
(3)对保存的文件进行向量化
当 to_vector_store=True 时,调用更新知识库文档接口 update_docs。具体实现如下所示:
# 对保存的文件进行向量化 默认 not_refresh_vs_cache=True,即暂不保存向量库。如果 not_refresh_vs_cache=False,那么执行 kb.save_vector_store()。FAISS 保存到磁盘(已实现),milvus 保存到数据库(未实现),PGVector 暂未支持(未实现)。具体实现,如下所示:
def save_vector_store(self):(4)接口调用
http://127.0.0.1/knowledge_base/upload_docs ,如下所示:
控制台输出,可以看到使用的加载器为 UnstructuredFileLoader,然后将向量库保存到磁盘(FAISS),如下所示:
2024-01-21 19:17:56,650 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt(5)可能遇到的问题
通过界面操作时,Browser files 上传一个文件之后,点击按钮"添加文件到知识库",出现如下所示:
INFO: 127.0.0.1:60656 - "POST /knowledge_base/upload_docs HTTP/1.1" 422 Unprocessable Entity说明:暂未找到原因。
三.知识库操作 2
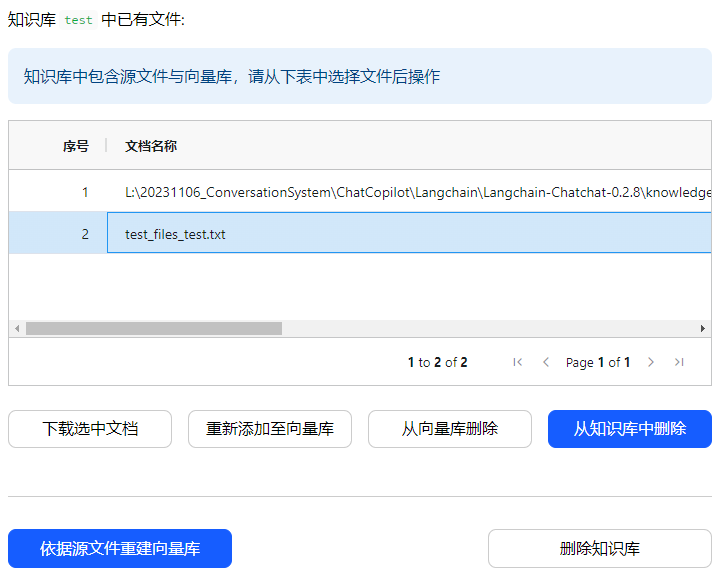
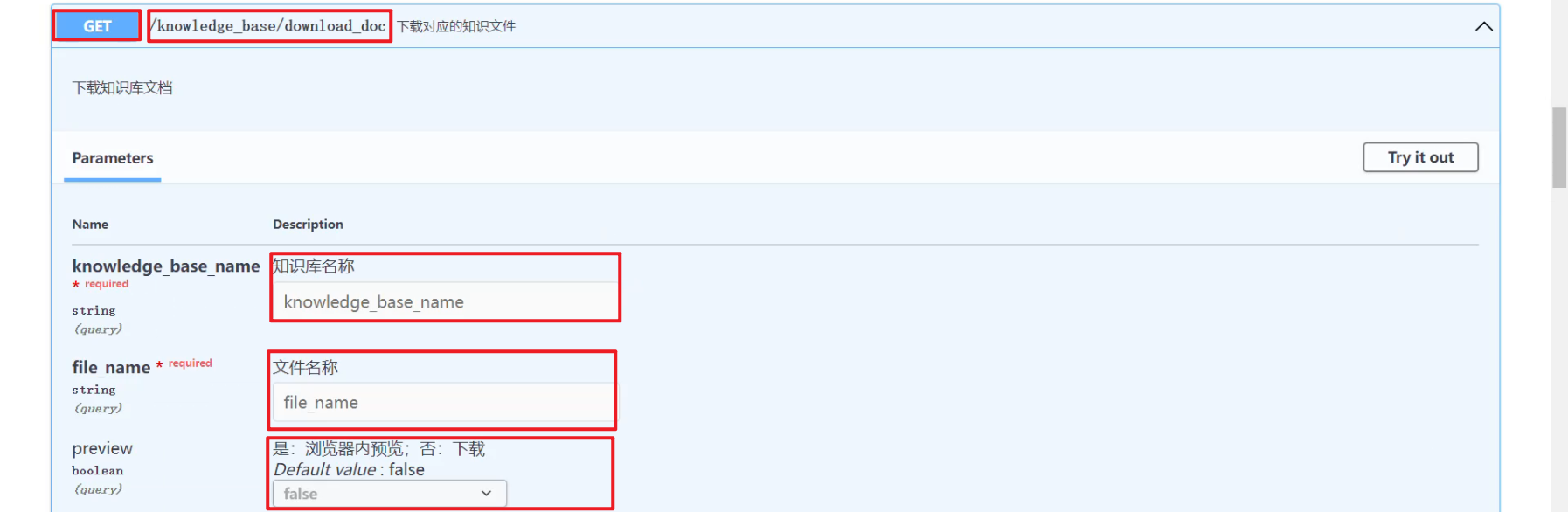
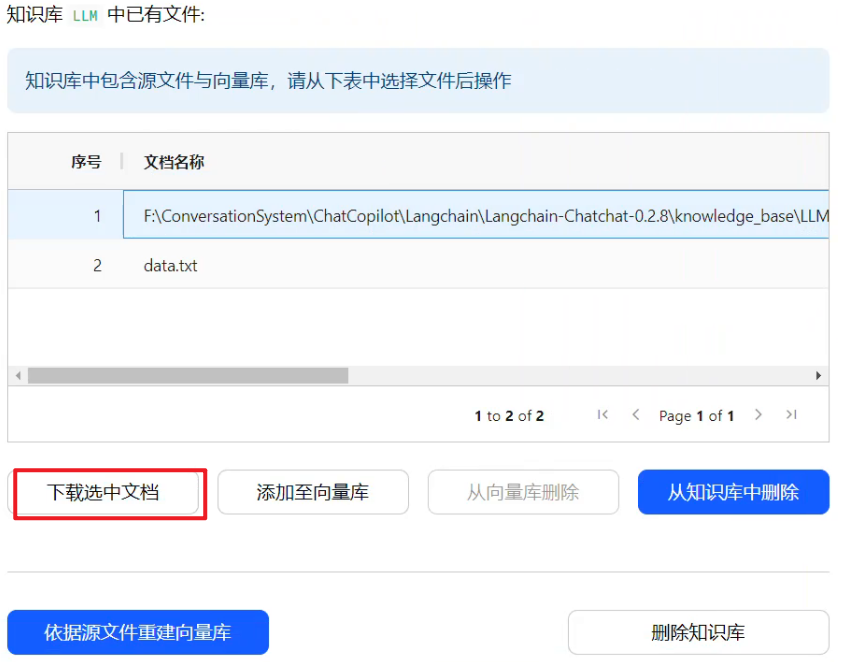
1.下载选中文档
(1)download_doc 接口
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.get("/knowledge_base/download_doc",download_doc 接口主要是根据知识库名字和文件名字拿到文件路径,然后返回 FileResponse 对象。
(2)接口调用
http://127.0.0.1/knowledge_base/download_doc ,如下所示:
(3)界面操作
无论是下载源文件,还是向量库文件,都是先选中,然后下载。下载的向量库文件,和下载的源文件内容都是一样的,都是源文件的内容,而不是编码后的内容。
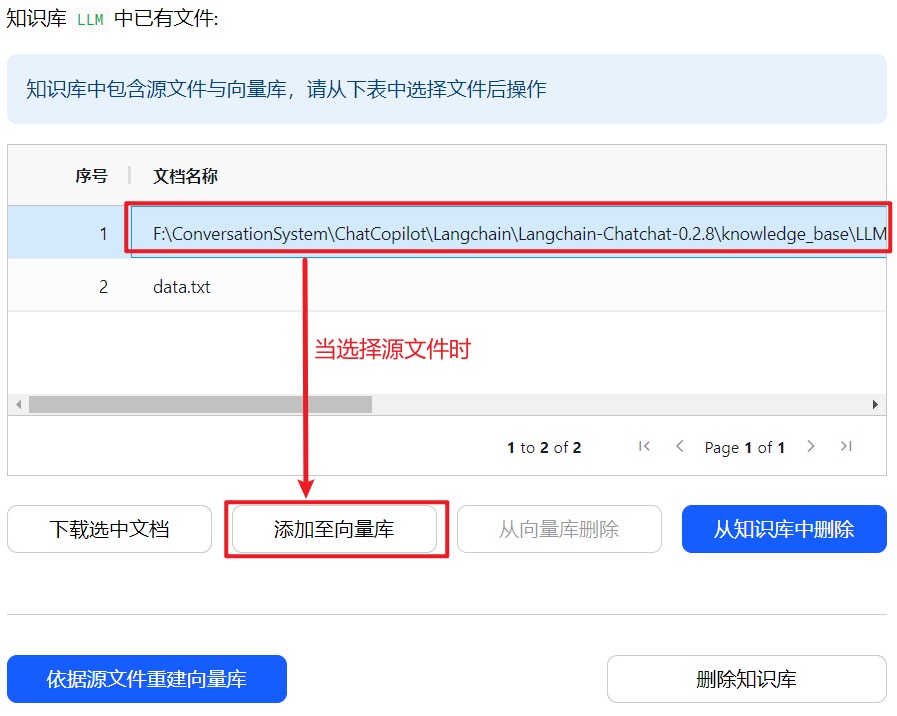
2.添加至向量库/重新添加至向量库
(1)界面操作
当选择源文件时,显示添加至向量库,如下所示:
当选择向量库文件时,显示重新添加至向量库,如下所示:
(2)接口调用
无论是"添加至向量库",还是"重新添加至向量库"都是调用的 upload_docs 接口,"添加至向量库"控制台日志如下所示:
2024-01-21 23:59:11,127 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt "重新添加至向量库"控制台日志如下所示:
2024-01-22 00:14:56,917 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt3.从向量库删除
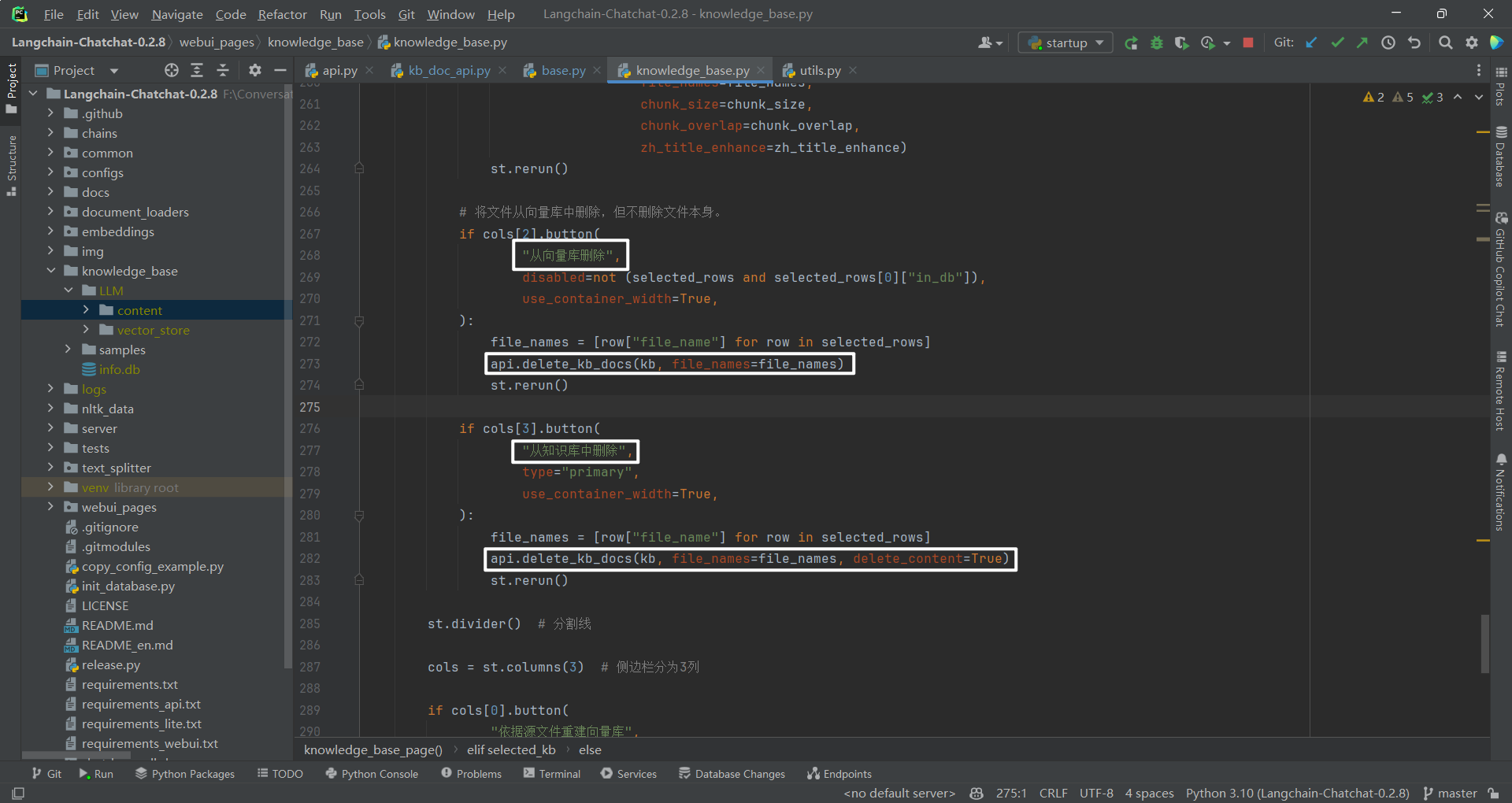
(1)基本删除思路
只能删除向量库文件,不能删除源文件。因为当选中源文件时,这个按钮是禁用状态。基本删除思路为:删除向量库中的内容(比如 faiss),删除数据库中的内容(knowledge_file 数据表)。F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
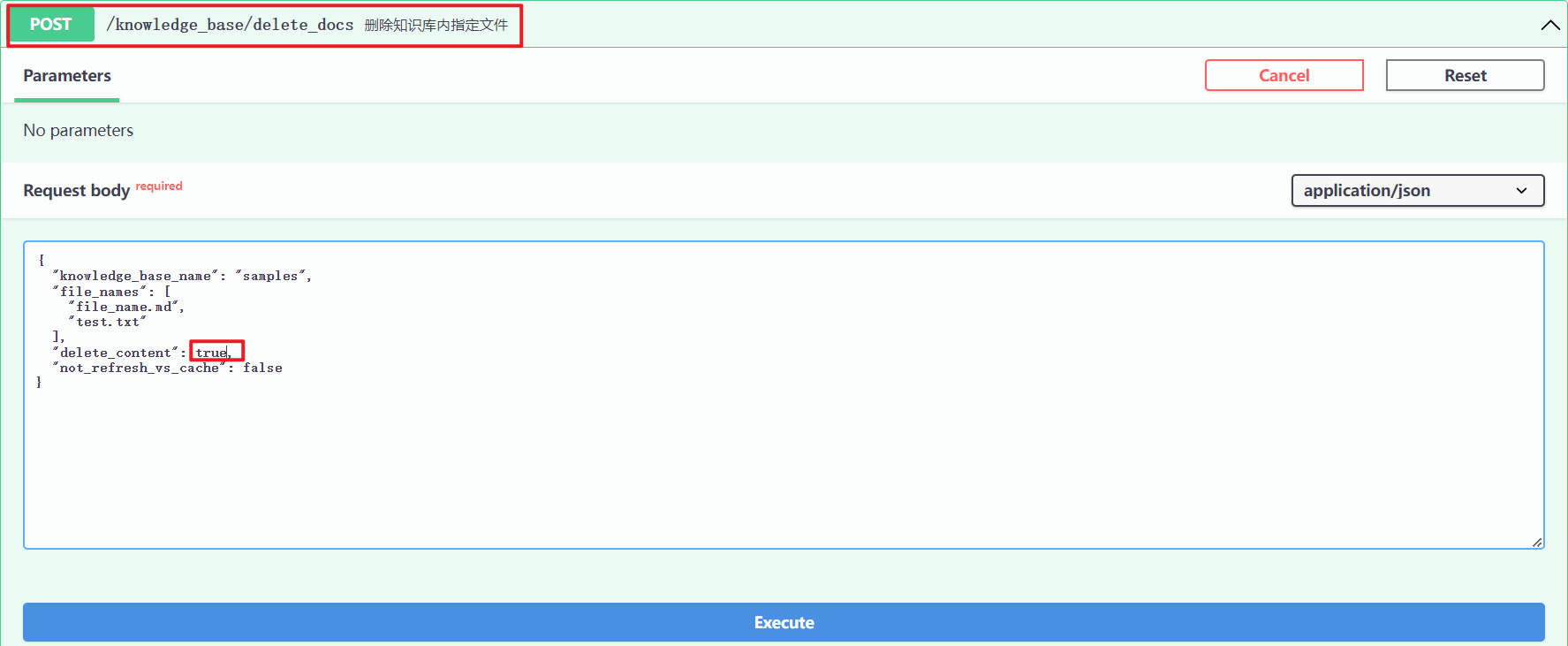
app.post("/knowledge_base/delete_docs",(2)接口调用
http://127.0.0.1/knowledge_base/delete_docs ,如下所示:
4.从知识库中删除
(1)基本思路
无论是向量库文件,还是源文件都是可以删除的。基本删除思路为:删除向量库中的内容(比如 faiss),删除数据库中的内容(knowledge_file 数据表),删除上传文件夹中的文件。
(2)接口调用
查看源码,从向量库删除和从知识库删除区别,前者"delete_content": false,而后者为"delete_content": true。这个字段主要是控制着是否删除文件夹。http://127.0.0.1/knowledge_base/delete_docs ,如下所示:
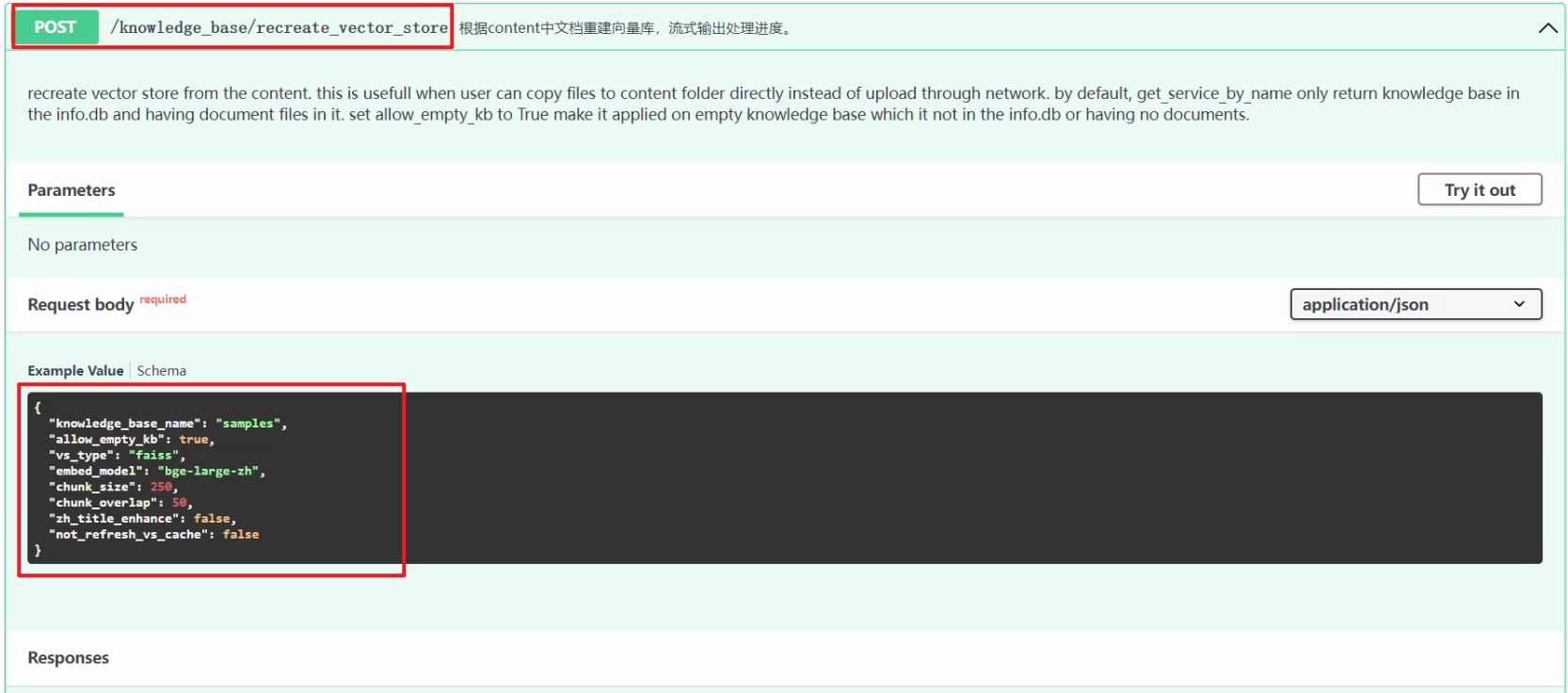
5.依据源文件重建向量库
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/recreate_vector_store", 本质上就是将原来的向量库清空,然后重建操作。http://127.0.0.1/knowledge_base/recreate_vector_store 接口调用如下所示:
上述英文内容翻译:从内容重新创建矢量存储。当用户可以直接将文件复制到内容文件夹而不是通过网络上传时,这很有用。默认情况下,get_service_by_name 只返回 info.db 中的知识库并在其中包含文档文件。将 allow_empty_kb 设置为 True 使其应用于不在 info.db 中或没有文档的空知识库。
6.删除知识库
本质上是删除向量库、数据库信息和文件夹。F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/delete_knowledge_base",http://127.0.0.1/knowledge_base/ 接口调用如下所示:
除此之外,还有一些接口没有介绍实现逻辑,可参考文献[1]。如果不查看源代码,可能很难较为深入的理解每个操作步骤的具体实现逻辑。
参考文献
[1] Langchain-Chatchat API Server:http://127.0.0.1/docs
[2] https://github.com/chatchat-space/Langchain-Chatchat/releases/tag/v0.2.8
[3] 梳理Langchain-Chatchat知识库API接口(原文链接):https://z0yrmerhgi8.feishu.cn/wiki/XN7AwrH6DiCpMIkaNnAcPd7znZc
NLP工程化
1.本公众号以对话系统为中心,专注于Python/C++/CUDA、ML/DL/RL和NLP/KG/DS/LLM领域的技术分享。
NLP工程化(公众号)
NLP工程化(星球号)