通过之前的学习,相信你对 Kubernetes 越来越熟悉了。理论上,Kubernetes 可以跑在任何环境中,比如公有云、私有云、物理机、虚拟机、树莓派,但是任何基础设施(Infrastructure)对网络的需求都是最基本的。网络同时也是 Kubernetes 中比较复杂的一部分。
我们今天就来聊聊 Kubernetes 中的网络,先来看看 Kubernetes 中定义的网络模型。
Kubernetes 网络模型
Kubernetes 的网络模型在设计的时候就遵循了一个基本原则,即每一个 Pod 都拥有一个自己的独立的 IP 地址,且这些 Pod 之间可以不通过任何 NAT 互相连通。
基于这样一个 IP-per-Pod 的方式,用户在使用的时候就不需要再额外考虑如何建立 Pod 之间的连接,也不用考虑如何将容器的端口映射到主机端口,毕竟动态地分配映射端口不仅会给整个系统增加很大的复杂度,还不方便服务间做服务发现。而且由于主机端口的资源也是有限的,端口映射还会给集群的可扩展性带来很大挑战。
每个 Pod 有了独立的 IP 地址以后,通信双方看到的 IP 地址就是对方实际的地址,即不经过 NAT。不管 Pod 是否在同一个宿主机上,都可以直接基于对方 Pod 的 IP 进行访问。
基于这样的一个网络模型,我们来看看 Kubernetes 中的如下 4 种场景是如何进行网络通信的:
-
Pod 内容器之间的网络通信;
-
Pod 之间的网络通信;
-
Pod 到 Service 之间的网络通信;
-
集群外部与内部组件之间的网络通信。
同一 Pod 内的网络通信
我在《05 | K8s Pod:最小调度单元的使用进阶及实践》介绍 Pod 的时候提到过,Kubernetes 会为每一个 Pod 创建独立的网络命名空间(netns),Pod 内的容器共享同一个网络命名空间。这也就是说,Pod 内的所有容器共享相同的网络设备、路由表设置、端口等等,就像在同一个主机上运行不同的程序一样,这些容器之间可以通过 localhost 直接访问彼此的端口。
Pod 之间的网络通信
Pod 间的相互网络通信,可以分为同主机通信和跨主机通信。
我们先来看看同主机上 Pod 间的通信。
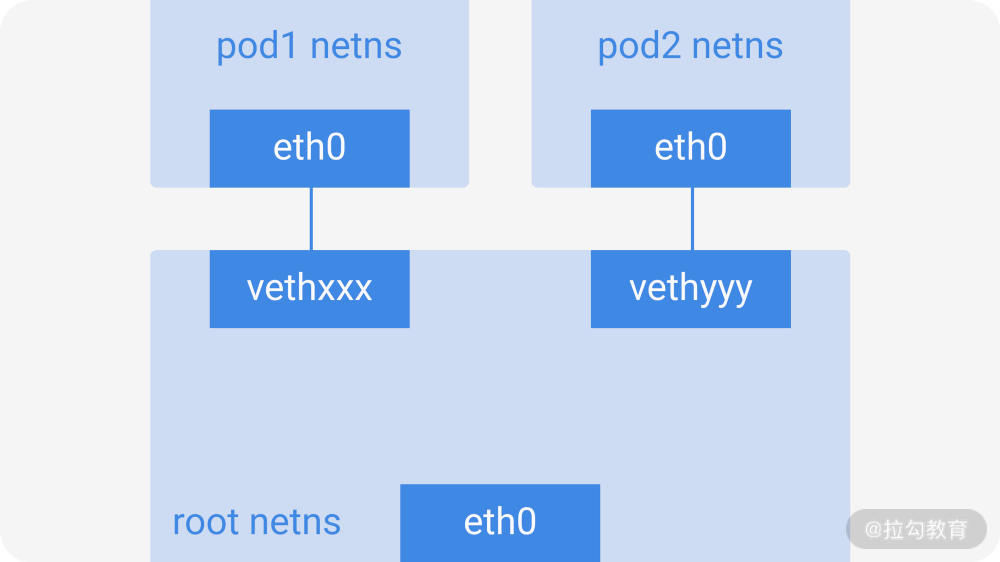
图 1:同主机上 Pod 间的通信
在网络命名空间里,每个 Pod 都有各自独立的网络堆栈,通过一对虚拟以太网对(virtual ethernet pair)连接到根网络命名空间里(root netns)。这个 veth pair 一端在 Pod 的 netns 内,另一端在 root netns 里,对应上图中的 eth0 和 vethxxx。
从上图可以看到,Pod1 和 Pod2 都通过 veth pair 连接到同一个 cbr0 的网桥上,它们的 IP 地址都是从 cbr0 所在的网段上动态获取的,也就是说 Pod1、Pod2 和网桥本身的 IP 是同一个网段的。由于 Pod1 和 Pod2 处于同一局域网内,它们之间的通信就可以通过 cbr0 直接路由通信。
下面我们再来看看处于不同主机上的 Pod 之间是如何进行网络通信的。
按照 Kubernetes 设定的网络基本原则,Pod 是需要跨节点可达的。而 Kubernetes 并不关心底层怎么处实现,我们可以借助 L2(ARP跨节点)、L3(IP路由跨节点,就像云提供商的路由表)、Overlay 网络、弹性网卡等方案,只要能够保证流量可以到达另一个节点的期望 Pod 就好。因此,如果要实现这种跨节点的 Pod 之间的网络通信,至少要满足下面 3 个条件:
-
在整个 Kubernetes 集群中,每个 Pod 的 IP 地址必须是唯一的,不能与其他节点上的 Pod IP 冲突;
-
从 Pod 中发出的数据包不应该进行 NAT ,这样通信双方看到的 IP 地址就是对方 Pod 实际的地址;
-
我们得知道 Pod IP 和所在节点 Node IP 之间的映射关系。
我们以下图来说明基于 L2 的跨节点 Pod 互相访问时的网络流量走向。
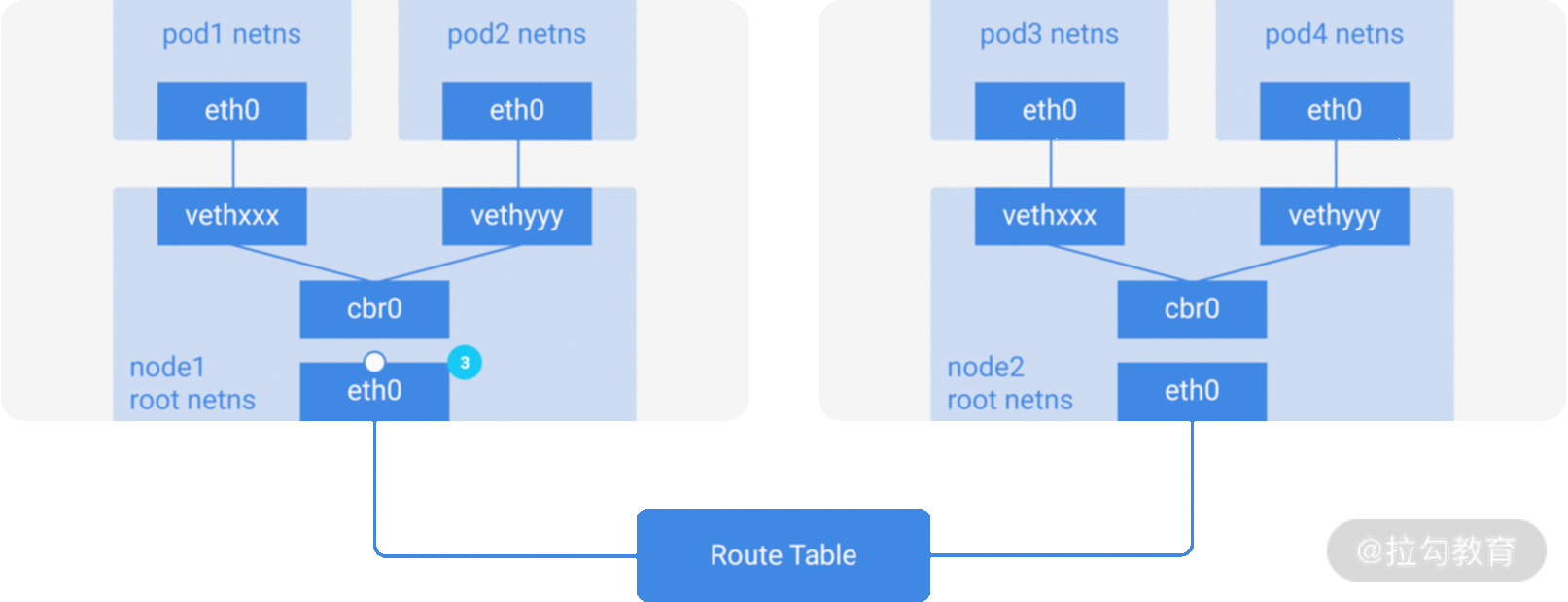
图 2:基于 L2 的跨节点 Pod 互相访问时的网络流量走向
假设一个数据包要从 Pod1 到达 Pod4,这两个 Pod 分属两个不同的节点:
-
数据包从 Pod1 中 netns 的 eth0 网口离开,通过 vethxxx 进入到 root netns;
-
数据包到达 cbr0 后,cbr0 发送 ARP 请求来找到目标地址;
-
由于 Pod1 所在的当前节点上并没有 Pod4,数据包会从 cbr0 流到宿主机的主网络接口 eth0;
-
数据包的源地址为 Pod1,目标地址设置为了 Pod4,随后离开 Node1;
-
路由表上记录着每个节点的 CIDR 的路由设定,这时候会把数据包路由到包含 Pod4 IP 地址的节点 Node2;
-
数据包到达 Node2 的 eth0 网口后,由于节点配置了 IP forward,节点上的路由表寻找到了能匹配 Pod4 IP 地址的 cbr0,数据包转发到 cbr0;
-
cbr0 网桥接收了该数据包,发送 ARP 请求查询 Pod4 的 IP 地址,发现 IP 属于 vethyyy;
-
这时候数据包跨过管道对到达 Pod4。
Pod到 Service 的网络
当我们创建一个 Service 时,Kubernetes 会为这个服务分配一个虚拟 IP。我们通过这个虚拟 IP 访问服务时,会由 iptables 负责转发。iptables 的规则由 Kube-Proxy 负责维护,当然也支持 ipvs 模式。
我们这里以 iptables 模式为例,如下图所示:
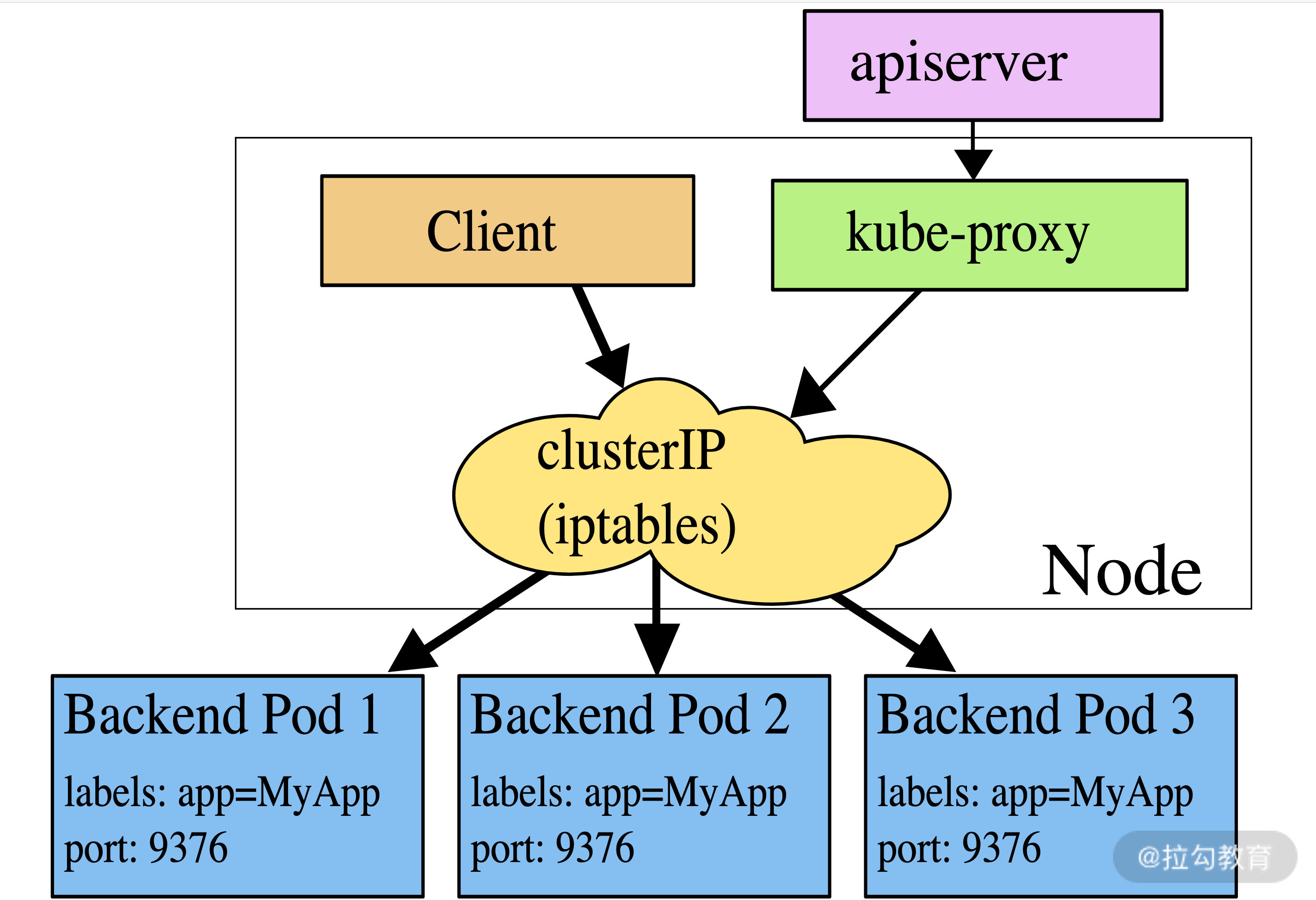
图 3:iptables 模式
Kube-Proxy 在每个节点上都运行,并会不断地查询和监听 Kube-APIServer 中 Service 与 Endpoints 的变化,来更新本地的 iptables 规则,实现其主要功能,包括为新创建的 Service 打开一个本地代理对象,接收请求针对发生变化的Service列表,kube-proxy 会逐个处理,处理流程如下:
-
对已经删除的 Service 进行清理,删除不需要的 iptables 规则;
-
如果一个新的 Service 没设置 ClusterIP,则直接跳过,不做任何处理;
-
获取该 Service 的所有端口定义列表,并逐个读取 Endpoints 里各个示例的 IP 地址,生成或更新对应的 iptables 规则。
外部和服务间通信
Pod 和 Service 都是 Kubernetes 中的概念,而从集群外是无法直接通过 Pod IP 或者 Service 的虚拟 IP 地址加端口号访问到的。这里我们就可以用 Ingress来解决这个问题。
Ingress 可以将集群内服务的 HTTP 和 HTTPS 暴露出来,以方便从集群外部访问。流量路由 Ingress 资源上定义的规则控制。
下图就是一个简单的将所有流量都发送到同一 Service 的 Ingress 示例:
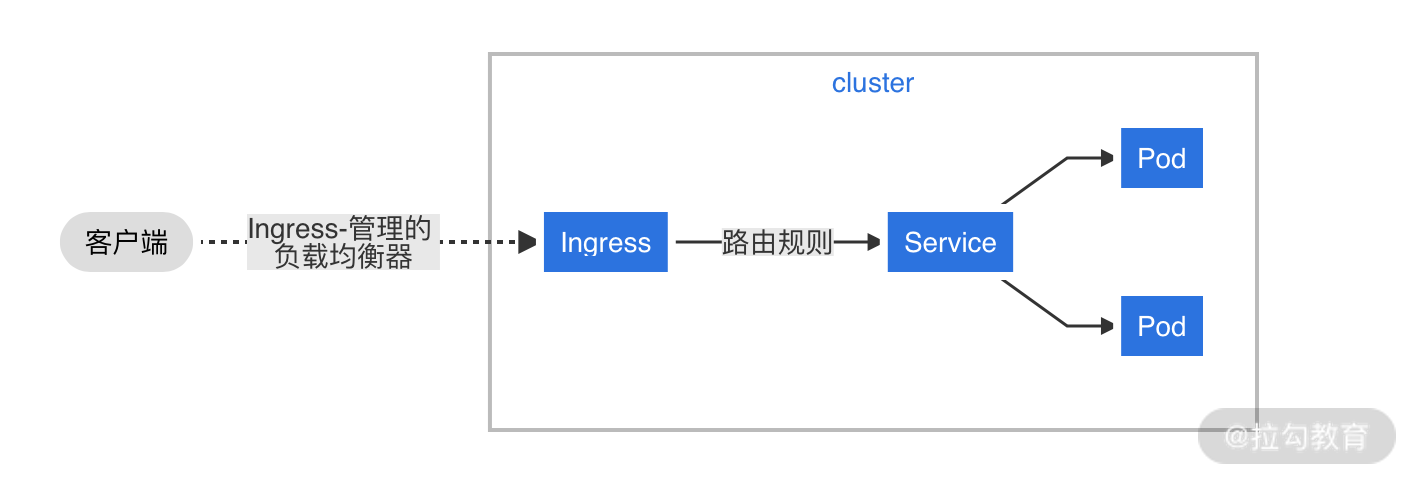
图 4:将所有流量都发送到同一 Service 的 Ingress
关于 Ingress 的更多资料,可以参考这份官方文档。
上面我们介绍了 Kubernetes 中的网络模型以及常见的 4 种网络通信情形,那么这些网络底层到底是如何实现的呢?这就有了 CNI。
CNI(Container Network Interface)
网络方案没有银弹,没有任何一个“普适”的网络可以满足不同的基础架构,所以 Kubernetes 早在 v1.1 版本就开始采用了 CNI(Container Network Interface)这种插件化的方式来集成不同的网络方案。
CNI 其实就是定义了一套标准的、通用的接口。CNI 关心容器的网络连接,在创建容器时分配网络资源,删除容器时释放网络资源。这套框架非常开放,可以支持不同的网络模式,并且很容易实现。
正是因为有了 CNI,才使得 Kubernetes 在各个平台上都有很好的移植性。如果每出现一个新的网络解决方案,Kubernetes 都需要进行适配,那工作量必然非常巨大,维护成本也极高。所以我们只需要提供一套标准的接口,就完美地解决了上述问题。任何新的网络方案,都只需要实现 CNI 的接口。
容器网络的最终实现都依赖这些 CNI 插件,每个 CNI 插件本质上就是一个可以执行的二进制文件。总的来说,这些 CNI 插件的执行过程包括如下 3 个部分:
-
解析配置信息;
-
执行具体的网络配置 ADD 或 DEL;
-
对于 ADD 操作还需输出结果。
如果你想自己动手写一个 CNI 插件,可以参考这个 GitHub 项目。
目前已经有很多的 CNI 插件可供选择,你可以直接从这份插件列表里选择适合的 CNI ,比如 Flannel、Calico、Cilium。
写在最后
基于 IP-per-Pod 的基本网络原则,Kubernetes 设计出了 Pod - Deployment - Service 这样经典的 3 层服务访问机制,极大地方便开发者在 Kubernetes 部署自己的服务。在生产实践中,大家可以根据自己的业务需要选择合适的 CNI 插件。
关于这一讲,你还有什么问题吗?欢迎在留言区留言。
下一讲,我将带你了解如何根据需求自定义你的 API。
标签:插件,Service,Kubernetes,IP,26,网络,Pod,CNI From: https://www.cnblogs.com/huangjiale/p/17958428