在上一节课,我们已经了解了 Kubernetes 集群的搭建方式。从现在开始,我们就要跟 Kubernetes 集群打交道了。本节课我们会学习 Kubernetes 中最重要、也最核心的对象——Pod。
在了解 Pod 之前,我们先来看一下CNCF 官方是怎么定义云原生的。
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
有没有注意到,云原生的代表技术里面提到了一个概念——不可变基础设施(Immutable Infrastructure)。其他的代表技术,像容器、微服务等概念早已深入人心,声明式 API 我们在第一讲 Kubernetes 的前世今生中也有所提及。那么这个不可变基础设施到底是什么含义,又与我们今天要讲的 Pod 有什么关系?
怎么理解不可变基础设施?
不可变基础设施,这个名词最早由 Chad Fowler 于 2013 年在他的文章“Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components*”*中提出来。随后,Docker 带来的“容器革命”以及 Kubernetes 引领的“云原生时代”,让不可变基础设施这个概念变得越来越流行。
这里的基础设施,我们可以理解为服务器、虚拟机或者是容器。
跟不可变基础设施相对的,我们称之为可变基础设施。在以往传统的开发运维体系中,软件开发完成后,需要工程师或管理员通过SSH 连接到他们的服务器上,然后进行一些脚本安装、deb/rpm 包的安装工作,并逐个机器地调整对应的配置参数及文件。后续还会根据需要对该环境进行不断更改,比如 kernel 升级、配置更新、打补丁等。
随着这种类似变更的操作越来越多,没有人能弄清楚这个环境具体经历了哪些操作,而后续的变更也经常会遇到各种意想不到的诡异事情,比如软件包的循环依赖、参数的配置不一致、版本漂移等问题。
基础设施会变得越来越脆弱、敏感,一些小的改动都有可能引发大的不可预知的结果,这令广大开发者和环境管理员异常抓狂,他们需要凭借自己丰富的技术积累,耗费大量的时间去排查解决。正如我们 01 课时所说,云计算的出现降低了环境标准化的成本,但是业务的交付管理成本依然很高。
通常来说,这种可变基础设施会导致以下问题:
-
持续的变更修改给服务运行态引入过多的中间态,增加了不可预知的风险;
-
故障发生时,难以及时快速构建出新的服务副本;
-
不易标准化,交付运维过程异常痛苦,虽然可以通过 Ansible、Puppet 等部署工具进行交付,但是也很难保证对底层各种异构的环境支持得很好,还有随时会出现的版本漂移问题。比如你可能经常遇到的,某个软件包几个月之前安装还能够正常运行,现在到一个新环境安装后,竟然无法正常工作了。
不可变基础设施则是另一种思路,部署完成以后,便成为一种只读状态,不可对其进行任何更改。如果需要更新或修改,就使用新的环境或服务器去替代旧的。不可变基础设施带来了更一致、更可靠、更可预测的设计理念,可以缓解或完全避免可变基础设施中遇到的各种常见问题。
同时,借助容器技术我们可以自动化地构建出不可变的、可版本化管理的、可一致性交付的应用服务体系,这里包括了标准化实例、运行环境等。还可以依赖持续部署系统,进行应用服务的自动化部署更新,加快迭代和部署效率。
Kubernetes 中的不可变基础设施就是 Pod。
Pod 是什么
Pod 由一个或多个容器组成,如下图所示。Pod 中的容器不可分割,会作为一个整体运行在一个 Node 节点上,也就是说 Pod 是你在 Kubernetes 中可以创建和部署的最原子化的单位。
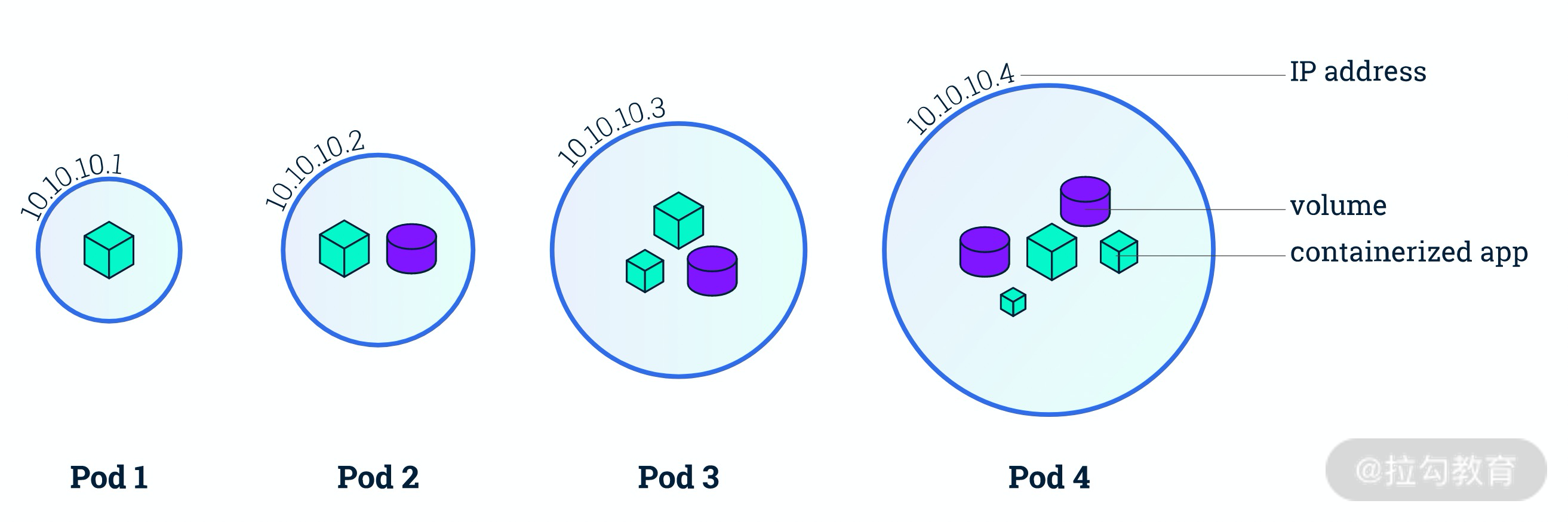
同一个 Pod 中的容器共享网络、存储资源。
-
每个 Pod 都会拥有一个独立的网络空间,其内部的所有容器都共享网络资源,即 IP 地址、端口。内部的容器直接通过 localhost 就可以通信。
-
Pod 可以挂载多个共享的存储卷(Volume),这时内部的各个容器就可以访问共享的 Volume 进行数据的读写。
既然一个 Pod 内支持定义多个容器,是不是意味着我可以任意组合,甚至将无关紧要的容器放进来都无所谓?不!这不是我们推荐的方式,也不是使用 Pod 的正确打开方式。
通常来说,如果在一个 Pod 内有多个容器,那么这几个容器最好是密切相关的,且可以共享一些资源的,比如网络、存储等。
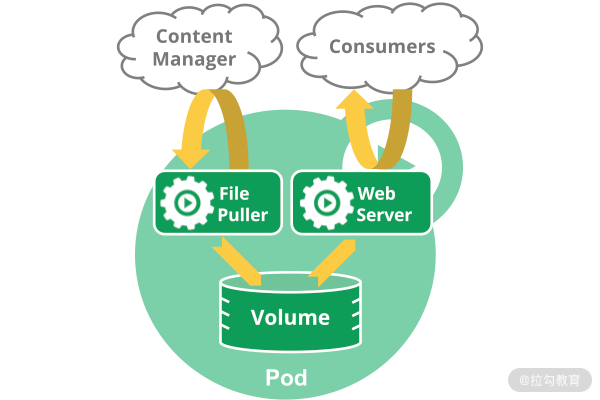
我们来看看官方文档中给的一个例子。这个 Pod 里面运行了两个容器 File Puller 和 Web Server。其中 File Puller 负责定期地从外部 Content Manager 同步内容,更新到挂载的共享存储卷(Volume)中,而 Web Server 只负责对外提供访问服务。两个容器之间通过共享的存储卷共享数据。
{kind=link}
{kind=link}
类似这样紧密耦合的业务容器,就比较适合放置在同一个 Pod 中,可以保证很高的通信效率。
一般来说,在一个 Pod 内运行多个容器,比较适应于以下这些场景。
-
容器之间会发生文件交换等,上面提到的例子就是这样。一个写文件,一个读文件。
-
容器之间需要本地通信,比如通过 localhost 或者本地的 Socket。这种方式有时候可以简化业务的逻辑,因为此时业务就不用关心另外一个服务的地址,直接本地访问就可以了。
-
容器之间需要发生频繁的 RPC 调用,出于性能的考量,将它们放在一个 Pod 内。
-
希望为应用添加其他功能,比如日志收集、监控数据采集、配置中心、路由及熔断等功能。这时候可以考虑利用边车模式(Sidecar Pattern),既不需要改动原始服务本身的逻辑,还能增加一系列的功能。比如 Fluentd 就是利用边车模式注入一个对应 log agent 到 Pod 内,用于日志的收集和转发。 Istio 也是通过在 Pod 内放置一个 Sidecar 容器,来进行无侵入的服务治理。
Pod 背后的设计理念
看完上面 Pod 的存在形式,你也许会有下面两个疑问。
1. 为什么 Kubernetes 不直接管理容器,而用 Pod 来管理呢?
直接管理一个容器看起来更简单,但为了能够更好地管理容器,Kubernetes 在容器基础上做了更高层次的抽象,即 Pod。
因为使用一个新的逻辑对象 Pod 来管理容器,可以在不重载容器信息的基础上,添加更多的属性,而且也方便跟容器运行时进行解耦,兼容度高。比如:
-
存活探针(Liveness Probe)可以从应用程序的角度去探测一个进程是否还存活着,在容器出现问题之前,就可以快速检测到问题;
-
容器启动后和终止前可以进行的操作,比如,在容器停止前,可能需要做一些清理工作,或者不能马上结束进程;
-
定义了容器终止后要采取的策略,比如始终重启、正常退出才重启等;
这些能力我们会在下一节课“ 05 Pod:最小调度单元的使用进阶及实践”中逐一介绍。
2. 为什么要允许一个 Pod 内可以包含多个容器?
再回答这个问题之前,我们思考一下另外一个问题 “为什么不直接在单个容器里运行多个程序?”。
由于容器实际上是一个“单进程”的模型,这点非常重要。因为如果你在容器里启动多个进程,这将会带来很多麻烦。不仅它们的日志记录会混在一起,它们各自的生命周期也无法管理。毕竟只有一个进程的 PID 可以为 1,如果 PID 为 1 的进程这个时候挂了,或者说失败退出了,那么其他几个进程就会自然而然地成为“孤儿”,无法管理,也无法回收资源。
很多公司在刚开始容器化改造的时候,都会这么去使用容器,把容器当作 VM 来使用,有时候也叫作富容器模式。这其实是一种非常不好的尝试,也不符合不可变基础设施的理念。我们可以接受将富容器当作容器化改造的一个短暂的过渡形态,但不能将其作为改造的终态。后续,还需要进一步对这些富容器进行拆分、解耦。
看到这里,第二个问题的答案已经呼之欲出了。用一个 Pod 管理多个容器,既能够保持容器之间的隔离性,还能保证相关容器的环境一致性。使用粒度更小的容器,不仅可以使应用间的依赖解耦,还便于使用不同技术栈进行开发,同时还可以方便各个开发团队复用,减少重复造轮子。
如何声明一个 Pod
在 Kubernetes 中,所有对象都可以通过一个相似的 API 模板来描述,即元数据 (metadata)、规范(spec)和状态(status)。这种方式也是从 Borg 吸取的经验,避免过多的 API 定义设计,不利于统一和对接。Kubernetes 有了这种统一风格的 API 定义,方便了通过 REST 接口进行开发和管理。
元数据(metadata)
metadata 中一般要包含如下 3 个对该对象至关重要的元信息:namespace(命名空间)、name(对象名)和 uid(对象 ID)。
-
namespace是 Kubernetes 中比较重要的一个概念,是对一组资源和对象的抽象集合,namespace 主要用于逻辑上的隔离。Kubernetes 中有几个内置的 namespace:
-
default,这是默认的缺省命名空间;
-
kube-system,主要是部署集群最关键的核心组件,比如一般会将 CoreDNS 声明在这个 namespace 中;
-
kube-public,是由 kubeadm 创建出来的,主要是保存一些集群 bootstrap 的信息,比如 token 等;
-
kube-node-lease,是从 v1.12 版本开始开发的,到 v1.14 版本变为 beta 可用版本,在 v1.17 的时候已经正式 GA 了,它要用于 node 汇报心跳(我们在第一节课已经解释过了心跳的概念),每一个节点都会有一个对应的 Lease 对象。
-
-
对象名比较好理解,就是用来标识对象的名称,在 namespace 内具有唯一性,在不同的 namespace 下,可以创建相同名字的对象。
-
uid 是由系统自动生成的,主要用于 Kubernetes 内部标识使用,比如某个对象经历了删除重建,单纯通过名字是无法判断该对象的新旧,这个时候就可以通过 uid 来进行唯一确定。
当然, Kubernetes 中并不是所有对象都是 namespace 级别的,还有一些对象是集群级别的,并不需要 namespace 进行隔离,比如 Node 资源等。
除此以外,还可以在 metadata 里面用各种标签 (labels)和注释(annotations)来标识和匹配不同的对象,比如用户可以用标签env=dev来标识开发环境,用env=testing来标识测试环境。我们会在后面的课程中,具体介绍 labels 和 annotations 的一些用途以及它们扮演的角色。
规范 (Spec)
在 Spec 中描述了该对象的详细配置信息,即用户希望的状态(Desired State)。Kubernetes 中的各大组件会根据这个配置进行一系列的操作,将这种定义从“抽象”变为“现实”,我们称之为调和(Reconcile)。用户不需要过度关心怎么达到终态,也不用参与。
状态(Status)
在这个字段里面,包含了该对象的一些状态信息,会由各个控制器定期进行更新。也是不同控制器之间进行相互通信的一个渠道。在 Kubernetes 中,各个组件都是分布式部署的,围绕着 kube-apiserver 进行通信,那么不同组件之间进行信息同步,就可以通过 status 进行。像 Node 的 status 就记录了该节点的一些状态信息,其他的控制器,就可以通过 status 知道该 Node 的情况,做一些操作,比如节点宕机修复、可分配资源等。
现在我们来看一个 Pod 的 API 长什么样子。
一个 Pod 的真实例子
下面是我用 Yaml 写的一个 Pod 定义,我做了注释让你一目了然:
apiVersion: v1 #指定当前描述文件遵循v1版本的Kubernetes API
kind: Pod #我们在描述一个pod
metadata:
name: twocontainers #指定pod的名称
namespace: default #指定当前描述的pod所在的命名空间
labels: #指定pod标签
app: twocontainers
annotations: #指定pod注释
version: v0.5.0
releasedBy: david
purpose: demo
spec:
containers:
- name: sise #容器的名称
image: quay.io/openshiftlabs/simpleservice:0.5.0 #创建容器所使用的镜像
ports:
- containerPort: 9876 #应用监听的端口
- name: shell #容器的名称
image: centos:7 #创建容器所使用的镜像
command: #容器启动命令
- "bin/bash"
- "-c"
- "sleep 10000"
你可以通过 kubectl 命令在集群中创建这个 Pod。kubectl 的功能比较强大、也比较灵活。我们会在后面的课程中,慢慢会看到 kubectl 的各种使用方法。
$ kubectl create -f ./twocontainers.yaml
kubectl get pods
NAME READY STATUS RESTARTS AGE
twocontainers 2/2 Running 0 7s
创建出来后,稍微等待一下,我们就可以看到,该 Pod 已经运行成功了。现在我们可以通过 exec 进入shell这个容器,来访问sise服务:
$ kubectl exec twocontainers -c shell -i -t -- bash
[root@twocontainers /]# curl -s localhost:9876/info
{"host": "localhost:9876", "version": "0.5.0", "from": "127.0.0.1"}
写在最后
Pod 是 Kubernetes 项目中实现“容器设计模式”的最佳实践之一,也是 Kubernetes 进行复杂应用编排的基础依赖。引入 Pod 主要基于可管理性和资源共享的目的,希望你能够仔细理解和揣摩 Pod 的这种设计思想,对今后的容器化改造颇有受益。
我们在后续的课程中会逐渐接触到更为复杂、弹性的应用。下一节课,我将带你实践 Pod。如果你对本节课有什么想法或者疑问,欢迎你在留言区留言,我们一起讨论。
标签:容器,搞定,04,Kubernetes,可以,namespace,Pod,Kubernete,基础设施 From: https://www.cnblogs.com/huangjiale/p/17958372