业务模型训练中 Data 部分可能是瓶颈所在
在训练业务模型过程中,如果我们发现模型的训练速度不符合预期,往往会下意识地认为网络本身出了问题。但实际上,大多数时候问题发生在模型的数据供给逻辑中。
区分一个训练过程的瓶颈到底是在准备数据,还是在网络的计算阶段其实是很简单的。比如对于下面这段代码:
data_begin = time.perf_counter()
images, labels = next(dataloader)
data_end = time.perf_counter()
data_time = data_end - data_begin
net_begin = time.perf_counter()
solve(net, images, labels, optimizer)
net_end = time.perf_counter()
net_time = net_end - net_begin
我们对数据处理时间和网络计算时间分别做了监控,如果 data_time 的时间接近于 0,相对于 net_time 可以忽略不计,那么就意味着数据供给不是瓶颈;否则我们均可以认为瓶颈在数据部分。举个例子,比如 data_time 是 0.05,而 net_time 是 0.1,虽然 data_time 小于 net_time 但其实瓶颈仍然是数据处理部分。
为什么会做出这种比较反直觉的判断呢,我们需要先了解 data 和 net 的 pipeline 机制。
在实际训练中,data 和 net 实际上是并行执行的,也就是说,我们一边在 cpu 上准备数据,一边在 gpu 上进行网络训练,一个理想情况下的两者的 pipeline 如下:

在 T1 时刻,cpu 上准备 batch1 数据,而 gpu 上因为数据没有准备好而空闲;等到 T2,batch1 准备好了,gpu 上会用 batch1 进行计算,同时 cpu 也不会闲着,而是会准备 batch2 的数据,后面的都是类似的,也就是 cpu 和 gpu 彼此之间不会互相等待,两个资源都得到了最大限度的利用。
而上面代码中调用 next(dataloader) 时因为前一个周期训练时数据已经准备好了,只需直接返回准备好的数据,data 时间基本为 0,此时数据不是瓶颈。
而 data > 0 时对应什么情况呢?如下图所示,假设我们准备一个 batch 数据需要两个周期,而训练一个 batch 只需要一个周期,那么 T1,T2 时刻 cpu 上会准备 batch1 而 gpu 因为没有数据空闲,而 T3 时刻 batch1 准备完成,gpu 上开始计算,同时 cpu 上开始准备 batch2,然后 T4 时刻 batch1 完成计算,但 batch2 还没有准备完成,此时调用 next(dataloader) 的话会等待 cpu 准备数据,一直到 T5 时刻 batch2 准备完成,gpu 开始计算 batch2。这里的 data_time 实际上就是 T4。可以看到 data_time > 0 实际上对应着 data 时间比 gpu 计算时间长,所以整个瓶颈在数据准备上。

Data 部分为什么容易成为瓶颈
一般来说,算法研究过程中,因为神级网络的计算量,大家遇到的问题都是模型计算的不够快。但为什么在实际业务中往往会发现 data 也有可能出现瓶颈呢?这主要是因为两个原因:
第一个是算法研究过程中我们为了在指定数据集上获得更好的效果,我们的模型一般会设计的较大,需要的计算更多,但业务中考虑到实际推理落地的场景,模型一般不会设计的很大;
第二个是研究阶段数据集如 imagenet/coco 等原始数据图片大小一般不会很大,但业务数据的都是自己摄像头采集的,现在的摄像头越来越清晰,从 1080p 到 4k,图片大小都是很大的,所以准备数据时间占比很长。
因此在业务场景中数据成为瓶颈的可能性就大大提升。
使用 DataMonitor 定位 Data 部分的问题
那么假如数据阶段有问题,比较慢,那么到底是慢在哪里?我们又该如何解决呢?在介绍具体问题之前,先介绍一下我们是怎么处理数据的。
整个数据处理过程一般可以分成以下几个阶段:
第一阶段:加载数据,指从我们本地硬盘或者网络上读取原始的数据信息;
第二阶段:图片解码,指从原始的数据信息中还原出原始的图片,并以 numpy.ndarray 的形式表达;
第三阶段:数据 transform,一般是从原始图片做一些如加噪声,旋转裁切等操作,最后一般会把原始的图片 resize 成我们训练所需的图片大小;
第四阶段:数据 collate,一般来说会把我们处理好的单张图片等拼成符合训练要求的 batch 数据,到这里我们就完成了一个 batch 数据的生产;
最后我们可以将这个 batch 数据送给训练进程的 buffer,然后训练进程从中读取数据完成训练。
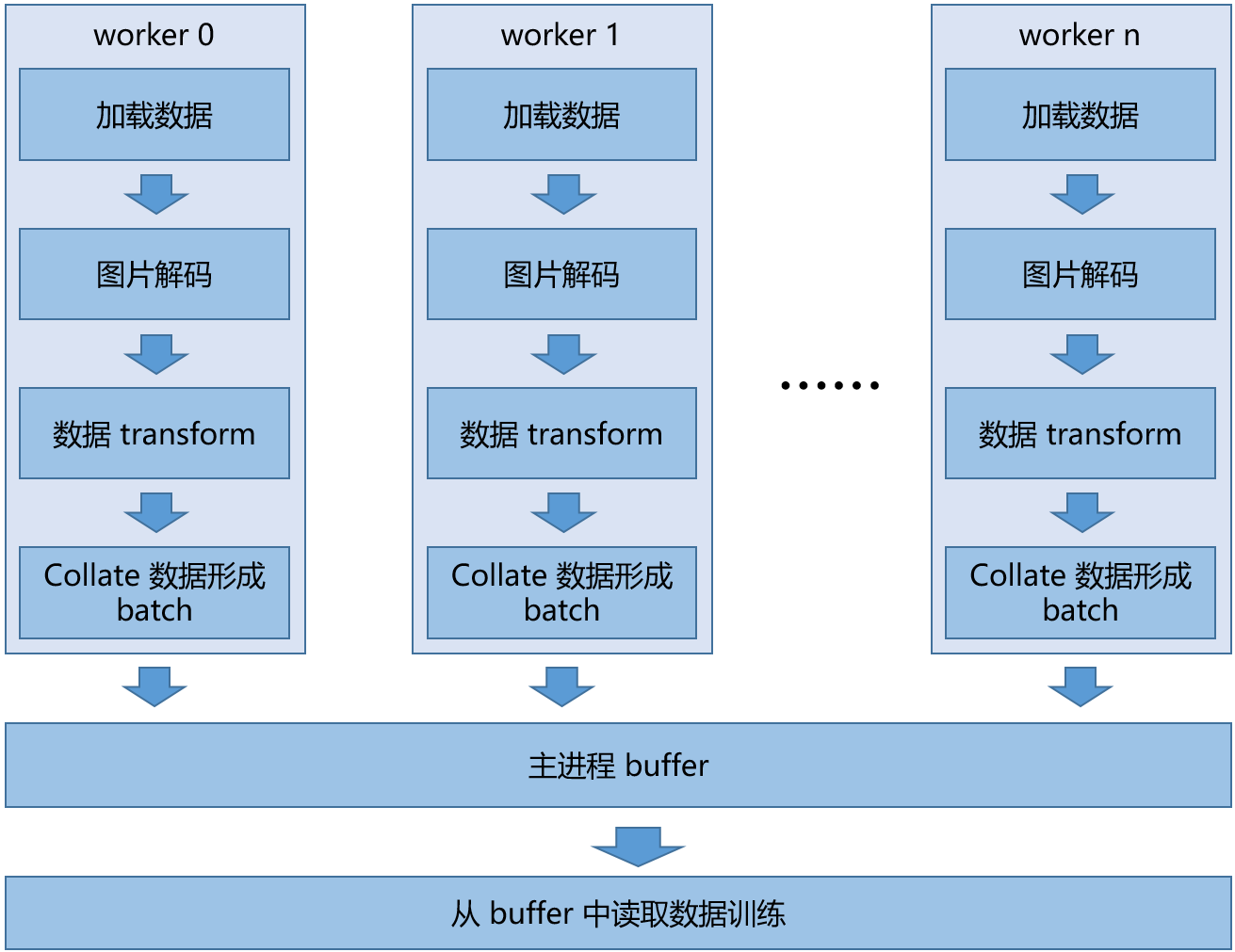
而在实际的 dataloader 中,为了加速上面的过程,我们可以给 data 处理部分开多个进程,称之为 worker,每个进程都做上面同样的事情,从而加速整体数据处理的速度。训练过程中 dataloader 的一般拓扑结构如上图所示。
造成 data 处理慢的原因一般是上面四个阶段中的一个或几个造成的。我们在做实际问题分析时可以统计数据处理过程中上面各个阶段在整体时间中的占比,从而找到具体的问题所在。
而现在 MegEngine dataloader 中已经内置了相关各个过程的时间的统计工具,使用时只需要 export MGE_DATA_MONITOR=1 即可开启,下面是一个网络训练过程中数据部分各阶段时间占比的统计实例。

这里的 pid 对应着一个 worker 的 pid,idx 对应着图片在数据集中的下标。dataset_time 记录着我们从数据集中读取一个 batch 图片的时间,对应着上述的加载数据和图片解码两个操作;transform_time 对应着数据 transform 的时间;而 collate_time 对应着 collate 数据形成 batch 的时间。
之所以这里用 dataset_time 来指代加载数据和图片解码两个阶段是因为这两个工作同时在 dataset 内部完成,dataloader 难以侵入式的区分这两个过程。不过下面会介绍我们如何用另外的方法区分这两者。
而在这个例子中,可以看到数据读取过程中主要时间均花在 dataset 阶段,所以主要问题集中在原始数据读取亦或是图片解码,如何进一步区分问题呢?一般的经验是我们可以进一步观察 cpu 的利用率,如果主要时间花在等待数据读取也就是 IO 上,那么 cpu 的利用率一般不会很高,大部分时间在等待,而如果主要时间花在图片解码上,那么一般此时 cpu 利用率会很高。如此我们就可以对瓶颈的原因做进一步区分。对于前者,主要瓶颈在 IO 上,那么我们在编写 Dataset 代码时,可以考虑使用异步 IO 来缓解 IO 瓶颈 cpu 等待的问题;而对于后者我们可以使用一些高性能的图像编解码库来替换原来的编解码流程。
而如果 transform_time 占比较大的话,则意味着训练所使用的数据预处理/数据增强比较复杂,我们可以分析此部分代码中涉及的计算是否可以用更高性能的 numpy/MegEngine 算子去代替,或者使用 gpu 去做图像预处理,又或者简化预处理相关的操作等手段进行优化。
collate_time 时间较长的情况一般比较少见,主要出现在我们 collate batch 时,会在一个 batch 内部各个图片之间做比较复杂的 data mixup 之类的操作,不过优化思路和优化 transform_time 时间是一致的。
简而言之,如果模型训练过程中的性能瓶颈定位在 data 部分,那么使用 data monitor 就可以快速定位具体问题的发生位置,从而帮助我们后续选择合适的手段高效解决问题!
附
更多 MegEngine 信息获取,您可以:查看文档、 深度学习框架 MegEngine 官网和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705
标签:monitor,瓶颈,data,dataloader,MegEngine,time,net,数据,cpu From: https://www.cnblogs.com/megengine/p/17914016.html