How to 充分利用你的服务器
图床在国外,图片刷新不出来就多试几次
目录本文处于preview阶段,内容并不完全严谨,如有错误敬请原谅,适当参考。
什么样的计算适合当前服务器?
从CPU架构入手
本文立足于PR4768GW服务器,由于服务器购买年限比较久远,无法查看到其对应的架构图,IO扩展的详细描述,本文只能保守估计,待有时间进行详细性能测试验证。
双路CPU常见于服务器主板上,双路CPU带来的是超多的PCIE插槽,更多的IO扩展性能。
PR4768GW 的主板支持性能如下:
最大支持两颗Intel® Xeon® processor E5-2600 v3/v4 family (up to 160W TDP ),Dual Socket R3 (LGA 2011);
组内使用的正是两颗E5-2620 V4
单颗的规格如下:

单颗包含了8颗物理核心,最通过超线程技术可同时运行16个线程。也就是说8个厨师可以同时做16个菜。
那么我们通过系统可以看到CPU的信息如下:
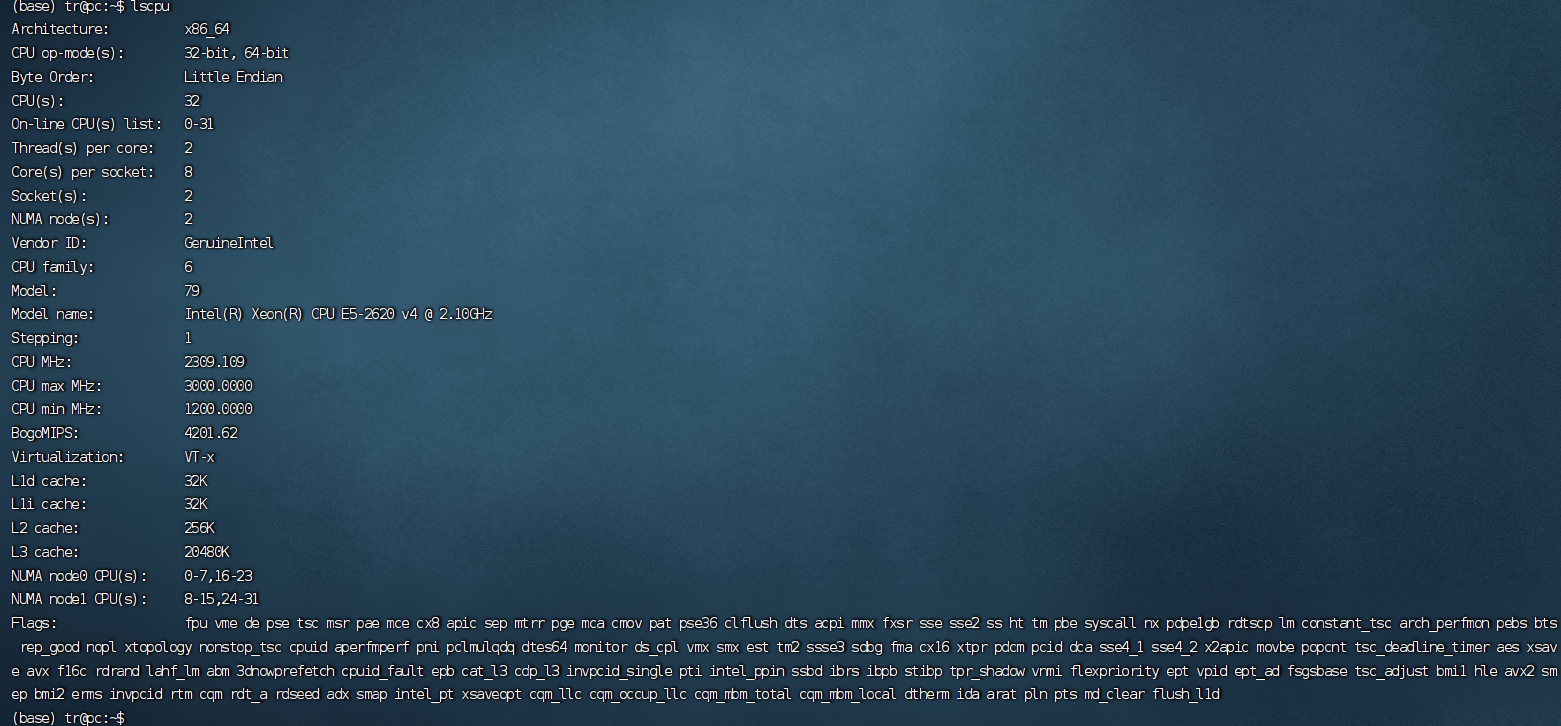
这里显示CPUS,也就是逻辑CPU有32个?
这是为什么呢?
首先,CPUS = 系统最大支持的CPU线程数量。(线程和进程的概念在这里被模糊)。
本文单个CPU支持16个线程,存在2个CPU 所以 : 16 x 2 =32。
那么在系统层级上你实际是感受不出来的,到底有多少个CPU。
但为什么要强调使用的是双CPU呢?对我们有什么影响呢?
两个CPU带来的影响
两个CPU虽然在系统层级上是完全感受不到的,但实际上是有很大区别的,可以简单画一个架构图来展示一下:
graph LR RAM1 <-->ACPU ACPU <--CHIPSET--> BCPU BCPU <-->RAM2双CPU架构的计算机系统中PCIe显卡的调用过程涉及操作系统、设备驱动程序、NUMA、I/O亲和性和多CPU核心之间的协同工作。但是对于ACPU要想访问RAM2的东西或者BCPU想要访问RAM1,你就会意识到他们不仅在物理位置上相隔较远,且并没有直接链接在一起,这意味着什么呢?
即所有内存对于用户来说是透明的,即ACPU可以放访问RAM1也可以访问RAM2,但在物理意义上ACPU访问RAM2延迟往往大于RAM1,这就会造成主观感受上的很慢,并且我们再考虑一个极端情况,就是当ACPU和BCPU同时要访问一个RAM1里面的数据,这样二者就造成的抢占,CHIPSET就会介入来让A先访问,B后访问,等等措施,即二者或有先后顺序,但这个过程就或造成等待的问题,在系统层级上感受就是代码运行很慢。
那么有办法控制代码的运行,和架构来匹配吗?
讲完上述内容你会意识到一个问题,在多线程并发运行的时候,是CPU 线程越多越好吗?
并不见得,对于的服务器我们需要合理的,线程数量分配,才能发挥服务器的性能。
基于上述内容,我简单列举四种测试条件,及其收益效果:
存储在同区RAM,多CPU参与运算
有如下程序,在庞大的数据中找到对应的数据并提取出来,此处利用了Pytorch的多线程支持,即index_ select是支持多线程操作的:
import time
import numpy as np
limport torch
INDEX = 1000000
NELE = 1000
device = torch. device("cpu")
a = torch. rand(INDEX, NELE) . to(device)
index = np. random. randint(INDEX-1, size=INDEX *8)
b = torch. from numpy (index) .to(device)
for threads in range(5, torch. get_ num. threads()*2):
torch. set. _num_ threads (threads)
start = time. time()
for in range(5):
res = a.index_ seLect(o, b
print("the number of cpu threads:{} , time {}". format(torch.get . num. threads(),time. time() - start))
数据量相对较小运行的时候 即数据为:INDEX = 10000 NELE = 1000的时候
我们让代码运行看一看在不同线程运行下运行的时间:
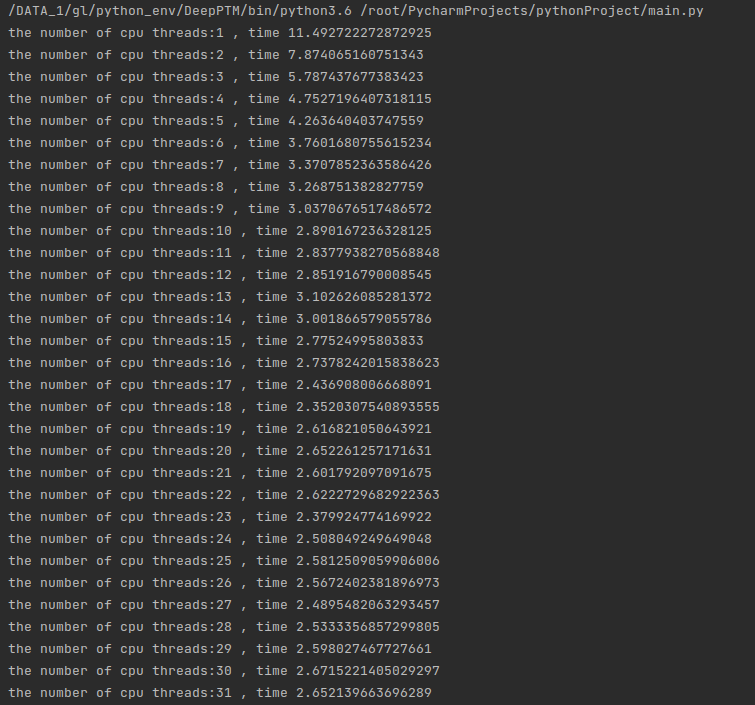
可以看到随着线程增加时间在快速下降,但是需要注意的是,当线程从8-16的时候:
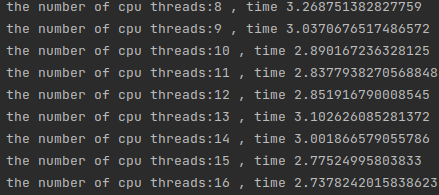
时间下降并不是很明显,是因为在这里启用了超线程技术,即同一个cpu的超线程技术,8个厨师做16道菜,当我们来到16-32线程的时候,时间有了明显的下降:
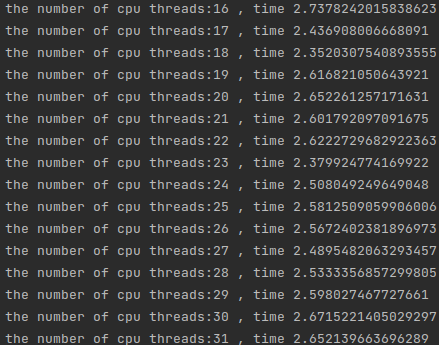
这因为CPU2来参与了运算。同理后边的运算随着线程的增多,多线程的开销反而占了大头,运算反而变慢了,当然这里也有因为双CPU抢占内存读取的问题,也就是说上文的抢占RAM1的情况,当然具体情况不会这么简单,这里想要讨论的是这种情况下甜点在于16线程。
这里的讨论结果具有一次性,并不能作为参考,所以我翻倍增加了内层循环的运行时间,运行结果如下:
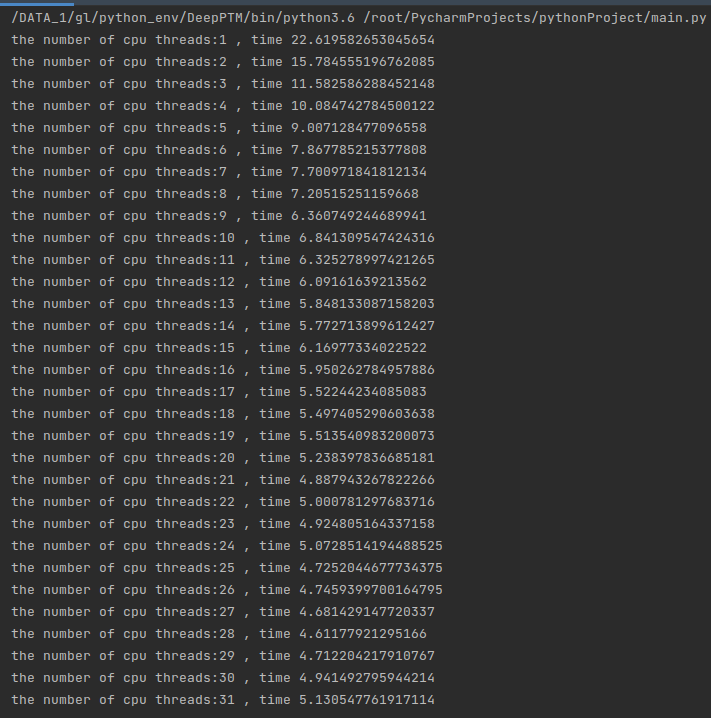
可以看到规律几乎一致。
下图展示了确实调用了很多CPU来运行:

存储在不同区RAM,多CPU参与运算
上文的结果可能令人沮丧,我的双CPU是否废了?
当然不是,也存在一种结果:当申请的内存足够多,如下所示:
数据量相对较小运行的时候 即数据为:INDEX = 1000000 NELE = 1000的时候
运算的结果会不会像上文一样?当然不是,此时内存峰值已经到到了如下:

远远超过了一半。
那么性能还会保持下降的趋势吗?如果没有保持效果是什么样呢?
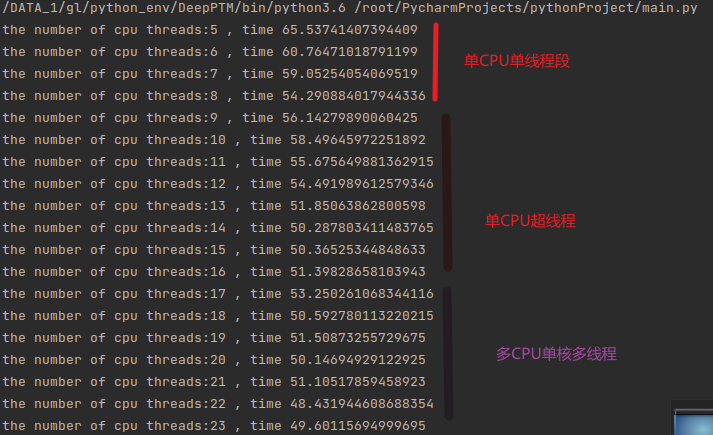
由于参数量过大,这里就不使用1到两个线程来实现了可以看到在前8个线程中都保持了比较好的运行性能下降的趋势,此时处于单线程单核心的阶段,性能会保持一个线性的下降:

可看到随着核心数量的变化,CPU运行处于不同的阶段,在跨阶段的时候运行时间会明显增加,这是因为内存访问和CPU抢占、多线程之间的开销三者的互相关系所造成的。所以线程数量往往设定为跨阶段的最终状态是最合适的。
当然这里的结论依赖于内存的高负载使用条件。
可以看到最终结果呈现出完整的阶段下降趋势:
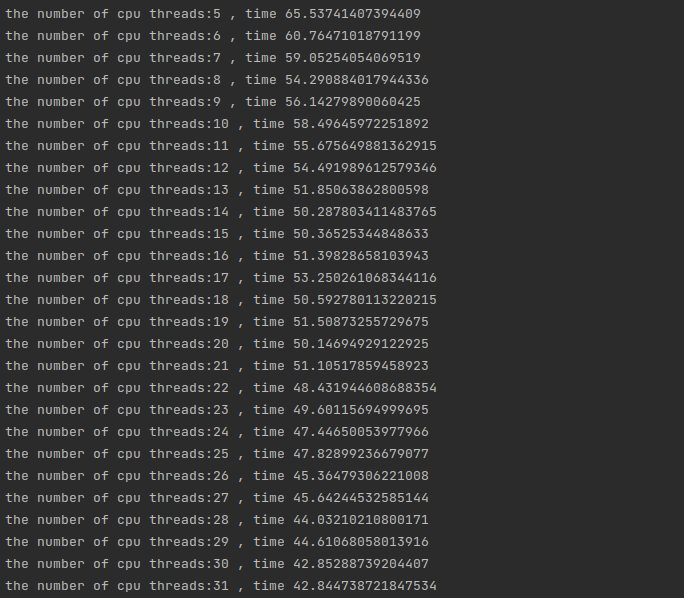
结论
在内存使用不明显的情况下推荐使用16线程,当然最保险的情况是实验一下,哪个线程比较合适。
在内存使用需要跨俩个CPU的时候,以阶段最多的CPU核心数量为优点,8,16,24不要直接32,系统会卡死!
参考文献
Set the Number of Threads to Use in PyTorch - jdhao's digital space
标签:16,torch,How,线程,内存,服务器,充分利用,CPU From: https://www.cnblogs.com/NeoNexus/p/17888455.html