SENetV2: Aggregated dense layer for channelwise and global representations
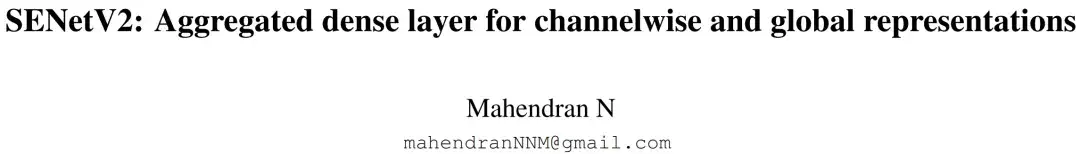
官方代码是用tf.keras实现(论文中没有标注):https://github.com/mahendran-narayanan/SENetV2-Aggregated-dense-layer-for-channelwise-and-global-representations
我用torch和tf实现了一下:https://github.com/github-eliviate/SENetV2_torch_tf/tree/main
欢迎star
1. 摘要
提出新的聚合多层感知机,在SE残差模块内设计,以超越现有架构的性能。该方法将SE模块和稠密(dense)层结合,这增强了网络捕获通道道模式的能力,具有全局知识,从而产生更好的特征表示。与SENet相比,该模型的参数增长可忽略不计。在基准数据集上进行了广泛的实验来验证模型,并与现有网络结构比较。结果表明,模型分类精度有显著提高。
2. 介绍
ResNeXt、SENet、SENetV2的结构如下:
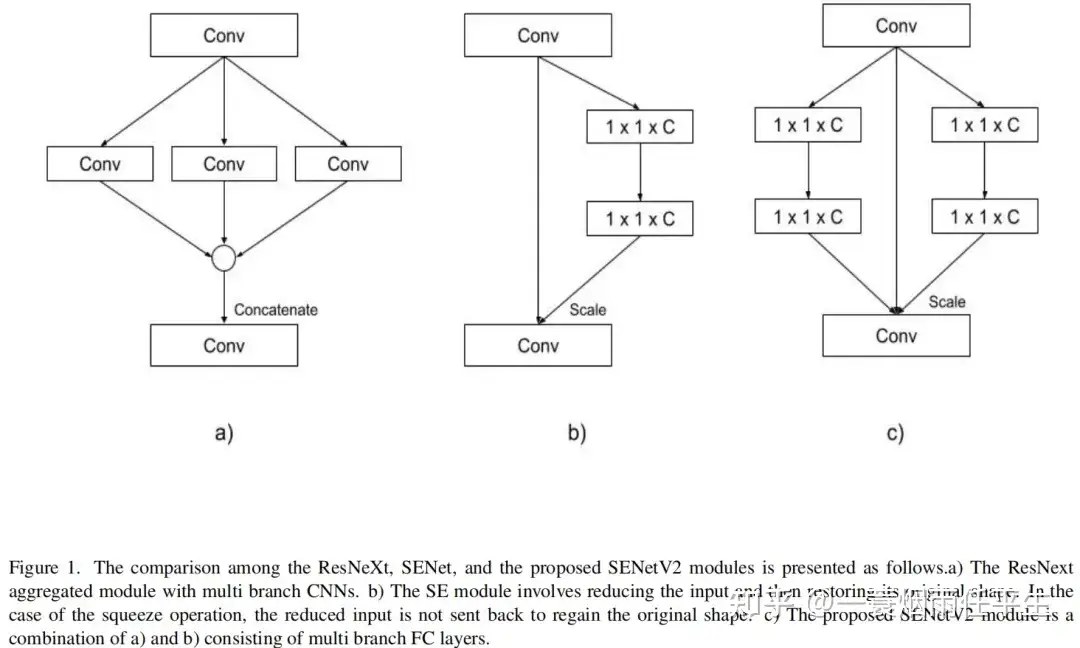
图2展示了SENetV2的SaE模块的内部功能,如下图:

3. SENet和SENetV2的表征对比
研究人员断言,通过分支输入使用包含多个卷积操作的聚合模块比选择更深的网络或更广泛的层更有效,这些模型变得善于捕获复杂的空间表示,特别是在聚合模块的卷积层中.
图3中显示的图像说明了SEnet和所提出的SEnetV2架构的初始卷积层的获取表示:

这些学习到的表征是在经过50个epoch的训练后被捕获的。训练初始学习率为0.01,每隔15个epoch衰减0.1倍。这种系统的方法使模型能有效优化其学习过程。
在对这些图像的仔细检查中,出现了一个明显的区别,这可以归因于与SEnet相比,更新的SEnet架构中整合的信息,通过更广泛的层数组传输,从而促进了更丰富、更多样化的学习过程。
4. 方法论
SENetV2架构与ResNeXt相似,因为它在SENet的残差模块中集成了一个聚合结构。为便于更清晰地理解该模块,我们将提出的方法与被广泛认可的Resnet结合起来.
我们的实验导致我们选择了一个基数值为4,而不是resnext(基数值为32)。压缩操作中的聚合层被concate到一起,然后转换到FC层,如图4所示:
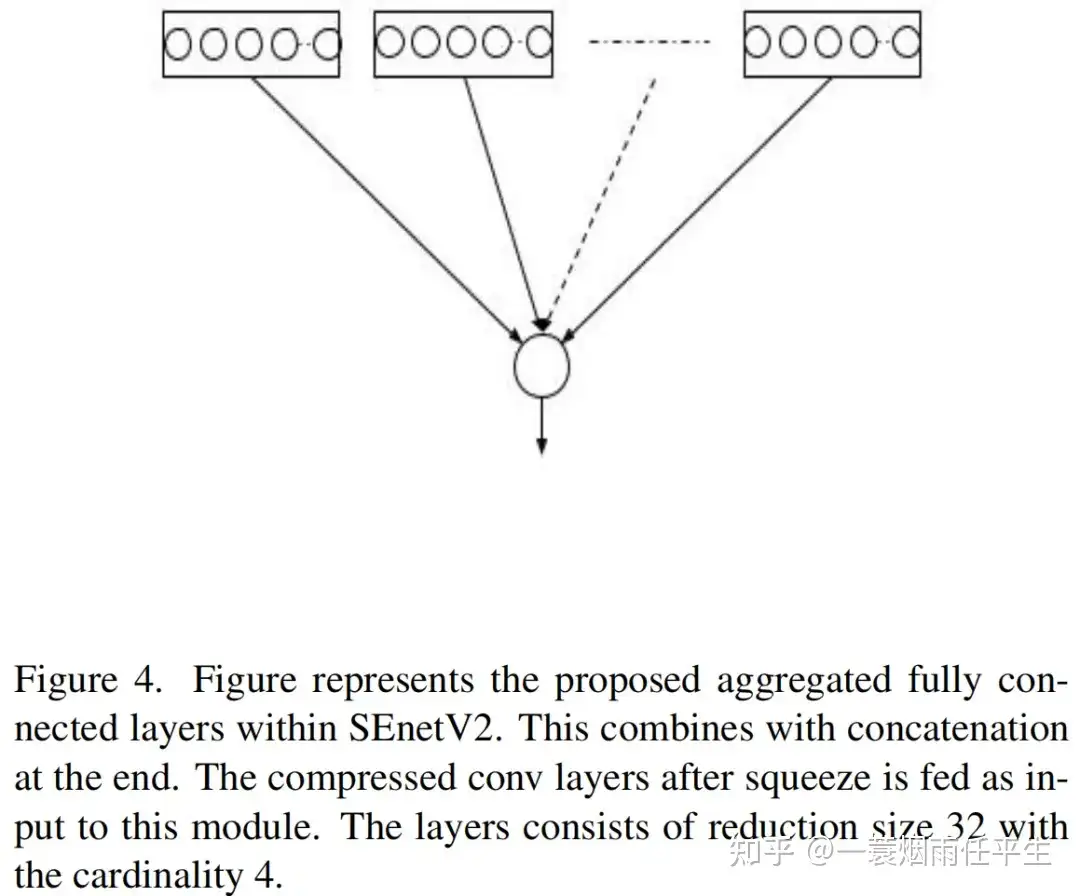
随后,将来自FC层的输出与模块的输入层进行乘法,从而恢复维度。最终输出类似于SENet的缩放操作。残差模块内的操作序列可描述如下:

5. 压缩聚合激励的resnet
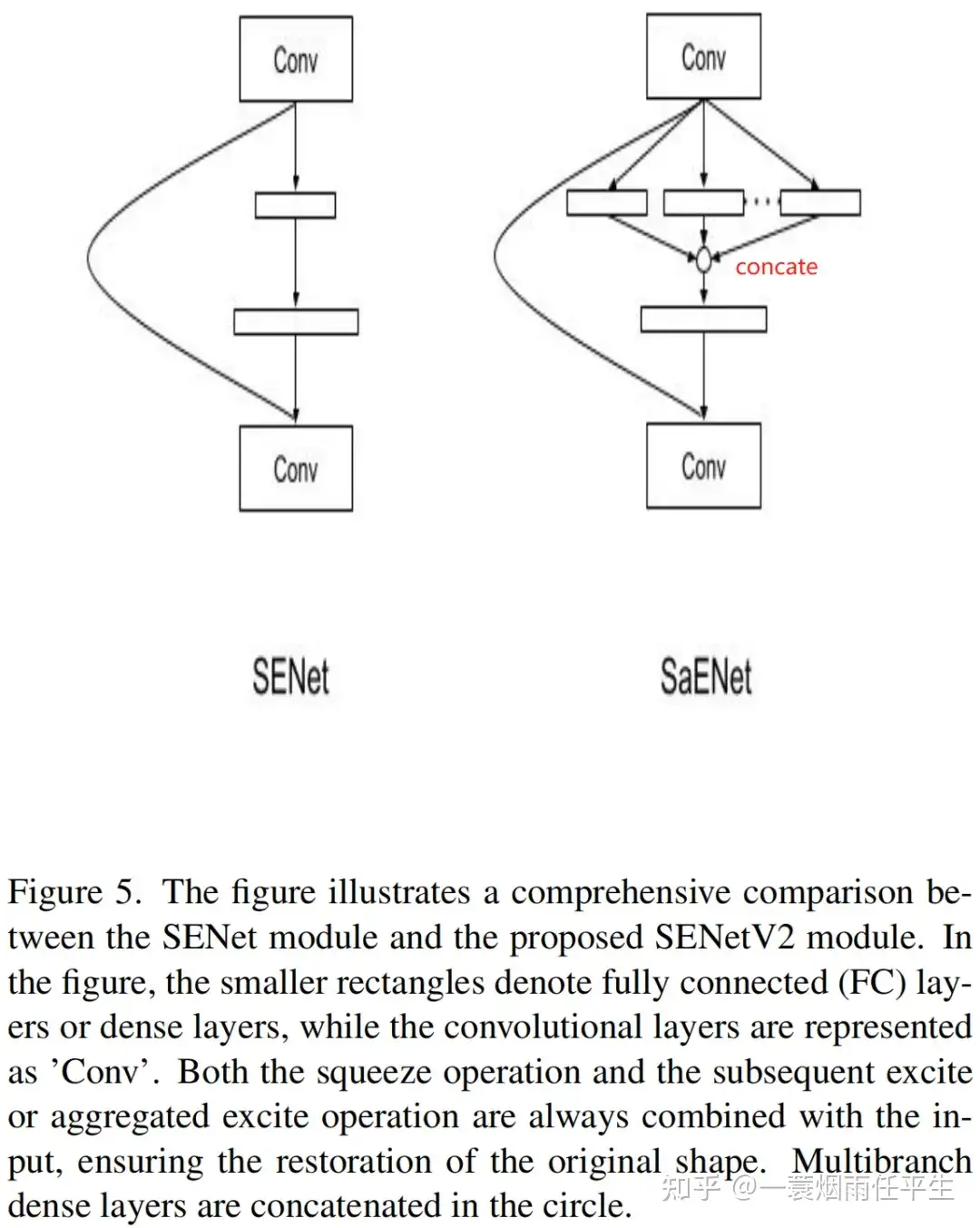
在ResNet的上下文中,SE(压缩和激励)模块与提出的SaE模块之间的比较如图5所示:
6. 实现
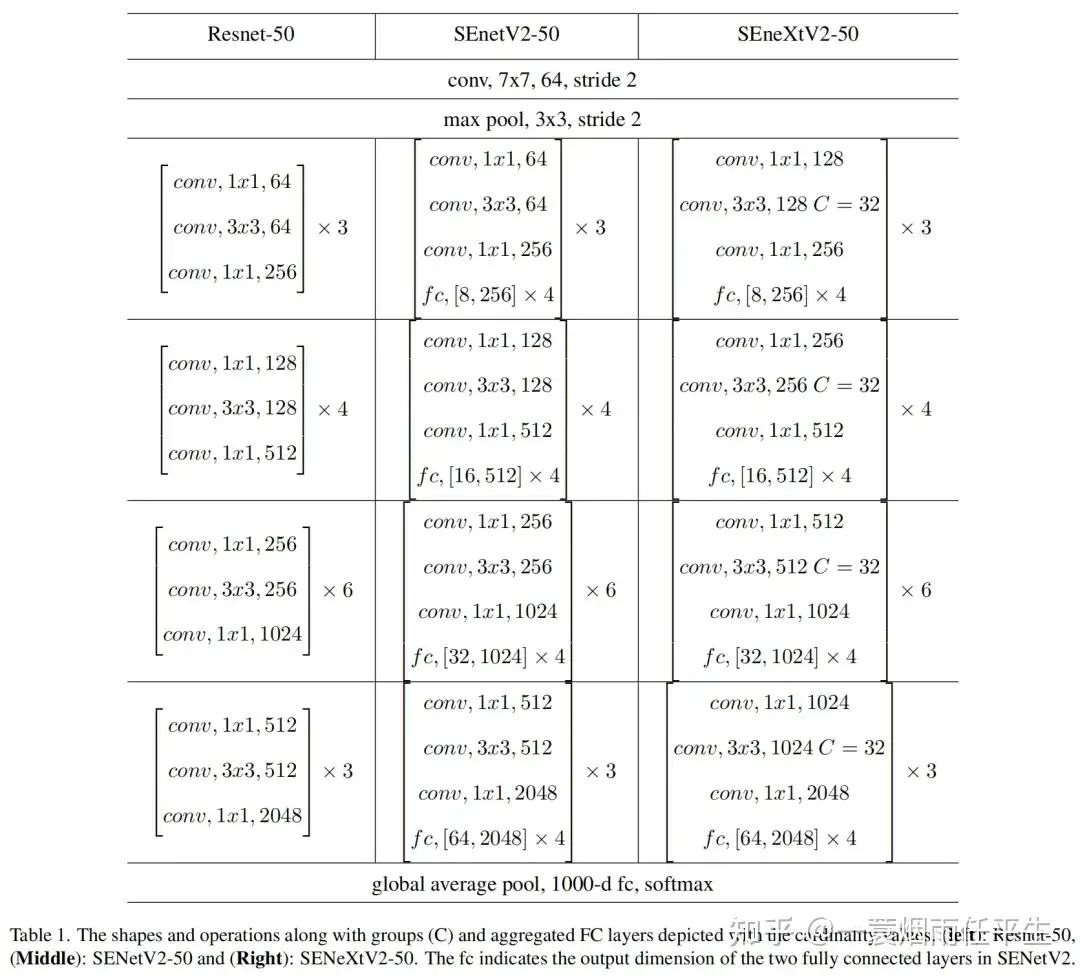
通过与sota结构的对比验证提出方法的有效性,如表1所示:
7. 实验
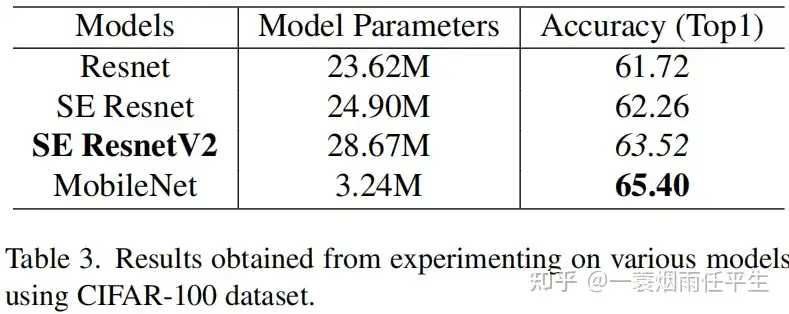
下面这张表中mobilenet的结果有点蒙,参数比resnet少,结果反而高,不过消融实验主要看前三行,说明senetv2还是有用的:

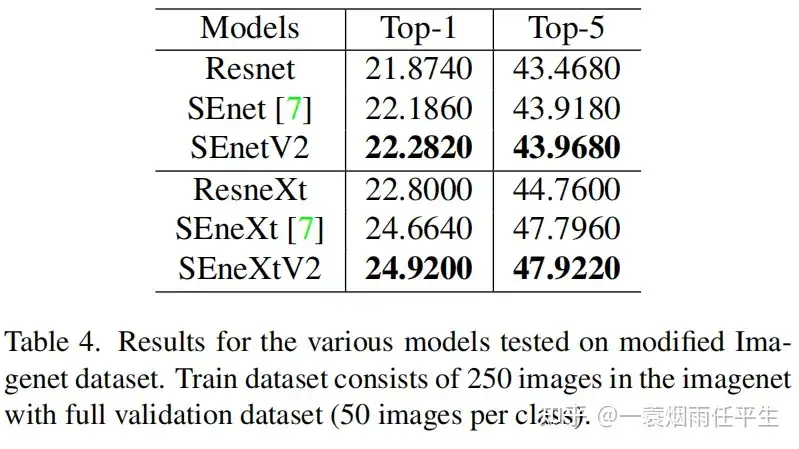

公众号同步
标签:聚合,SENetV2,SENet,dense,模块,tf,稠密 From: https://www.cnblogs.com/BlogLwc/p/17880269.html