一、前言
我们需要对4个规格的kafka能力进行探底,即其可以承载的最大吞吐;4个规格对应的单节点的配置如下:
- 标准版: 2C4G
- 铂金版: 4C8G
- 专业版: 8C16G
- 企业版: 16C32G
另外,一般来讲,在同配置下,kafka的读性能是要优于写性能的,写操作时,数据要从网卡拷贝至堆内存,然后进行一堆数据校验、解析后,会将数据拷贝至堆外内存,然后再拷贝至操作系统的page cache,最后操作系统异步刷盘至设备中。而读操作时,kafka使用了零拷贝技术,数据会从disk或page cache直接拷贝到网卡,节省了大量的内存拷贝。因此我们这次探底将聚焦于链路的短板,即kafka的写操作进行压测
注:本文不是专业的压测报告,而是针对不同集群调优,以获取其最大的吞吐能力
二、磁盘能力探底
在真正开始对kafka压测前,我们首先对磁盘的能力进行一个摸底。因为kafka是典型的数据型应用,是强依赖磁盘性能的,一旦有了这个数据,那么这个就是kafka的性能天花板。如果磁盘是传统的机械磁盘,那么瓶颈毫无悬念一般都会落在磁盘上;但如果磁盘类型是SSD,而且性能很高的话,操作系统会极力压榨cpu,从而获取一个最大刷盘吞吐,因此瓶颈在哪就很难讲了
要测试磁盘吞吐的话,2个变参的影响较大:
- 单次写入磁盘的数据量
- 写盘的线程数
2.1、单次刷盘大小
现在的硬件厂商,对于磁盘的优化,基本上都是4K对齐的,因此我们的参数一般也要设置为4K的整数倍,例如4K\8K\16K... 如果单次写入量小于4K,例如只写了10byte,那么底层刷盘的时候,也会刷4K的量,这就是臭名昭著的写放大
而具体单次写多少数据量能达到最优呢? 这就需要不断的benchmark了
2.2、刷盘线程数
我们知道kafka的broker通过参数num.io.threads来控制io的线程数量,通常是cpu * 2,不过这个参数并不能真实反应在同一时刻写盘的线程数,因此我们探底的时候,也需要动态修改这个参数,从而获取磁盘真实的吞吐
2.3、探底工具
public class DiskMain2 {
private static final long EXE_KEEP_TIME = 30 * 1000;
public static void main(String[] args) throws Exception {
new DiskMain2().begin(args);
}
private void begin(String[] args) throws Exception {
AtomicLong totalLen = new AtomicLong();
long begin = System.currentTimeMillis();
int threadNum = args.length > 0 ? Integer.parseInt(args[0]) : 4;
int msgK = args.length > 1 ? Integer.parseInt(args[1]) : 16;
int size = msgK * 1024;
List<Thread> threadList = new ArrayList<>();
for (int j = 0; j < threadNum; j++) {
Thread thread = new Thread(() -> {
try {
File file = new File("/bitnami/kafka/" + UUID.randomUUID() + ".txt");
file.createNewFile();
FileChannel channel = FileChannel.open(Paths.get(file.getPath()), StandardOpenOption.WRITE);
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(size);
for (int i = 0; ; i++) {
byteBuffer.clear();
byteBuffer.position(size);
byteBuffer.flip();
channel.write(byteBuffer);
if (i % 100 == 0) {
long cost = System.currentTimeMillis() - begin;
if (cost > EXE_KEEP_TIME) {
break;
}
}
}
channel.force(false);
totalLen.addAndGet(file.length());
file.delete();
} catch (IOException e) {
throw new RuntimeException(e);
}
});
thread.start();
threadList.add(thread);
}
for (Thread thread : threadList) {
thread.join();
}
long cost = (System.currentTimeMillis() - begin) / 1000;
System.out.println((totalLen.get() / 1024 / 1024) + " MB");
System.out.println(cost + " sec");
System.out.println(totalLen.get() / cost / 1024 / 1024 + " MB/sec");
}
}简单描述下这个工具做的事儿:启动M(可配)个线程,每个线程单次往磁盘中写入N(可配)K的数据,整个过程持续30秒,然后统计所有写入文件的总大小,最后除以时间,从而计算磁盘吞吐
几个注意点:
- 大块的磁盘写入,一定要使用
FileChannel,与kafka中的log写入对齐 - 尽量减少cpu的使用,将压力下放给磁盘,demo中使用的ByteBuffer,通过修改position的值模拟大块数据
- 使用
DirectByteBuffer,减少一次堆内存 --> 对外内存的拷贝
2C4G
[root@jmc-pod kafka]# java DiskMain 2 4 802 MB/sec
[root@jmc-pod kafka]# java DiskMain 2 8 1016 MB/sec
[root@jmc-pod kafka]# java DiskMain 2 16 1105 MB/sec
[root@jmc-pod kafka]# java DiskMain 2 32 942 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 4 1013 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 8 941 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 16 1062 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 32 1076 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 4 916 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 8 993 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 16 1035 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 32 982 MB/sec
4C8G
[root@jmc-pod kafka]# java DiskMain 2 16 1320 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 4 2172 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 8 2317 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 16 2580 MB/sec
[root@jmc-pod kafka]# java DiskMain 4 32 2271 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 4 2150 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 8 2315 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 16 2498 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 32 2536 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 64 2434 MB/sec
8C16G
[root@jmc-pod kafka]# java DiskMain 4 16 2732 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 4 3440 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 8 3443 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 16 3531 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 32 3561 MB/sec
[root@jmc-pod kafka]# java DiskMain 8 64 3562 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 4 3515 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 8 3573 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 16 3659 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 32 3673 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 64 3674 MB/sec
[root@jmc-pod kafka]# java DiskMain 12 16 3672 MB/sec
16C32G
[root@jmc-pod kafka]# java DiskMain 16 16 3918 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 8 3814 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 32 3885 MB/sec
[root@jmc-pod kafka]# java DiskMain 16 64 3894 MB/sec
[root@jmc-pod kafka]# java DiskMain 24 8 4053 MB/sec
[root@jmc-pod kafka]# java DiskMain 24 16 4039 MB/sec
[root@jmc-pod kafka]# java DiskMain 24 32 4080 MB/sec
[root@jmc-pod kafka]# java DiskMain 24 64 4050 MB/sec
[root@jmc-pod kafka]# java DiskMain 32 16 4042 MB/sec
[root@jmc-pod kafka]# java DiskMain 32 32 4078 MB/sec
通过反复压测,得出如下结论:
|
规格 |
最大吞吐量 |
cpu |
参数 |
|
2C4G |
1105 MB/sec |
200% |
2线程,16K |
|
4C8G |
2580 MB/sec |
400% |
4线程,16K |
|
8C16G |
3674 MB/sec |
790% |
16线程,64K |
|
16C32G |
4080 MB/sec |
950% |
24线程,32K |
在kafka 3副本的经典协议下,上述表格便是其吞吐量的天花板。其中16C32G在算力上虽然比8C16G强了1倍,但其落盘速度却基本持平,在大数据的压力下,瓶颈终究会落在磁盘,因此可以大胆预测,其性能不会比8C16G高出太多
分析上述数据可知:
- 2C4G:磁盘的吞吐量约1G/s,远没有达到上限,此时的瓶颈在cpu
- 4C8G:吞吐量虽上升了一倍不止,不过cpu飚满,瓶颈还在cpu
- 8C16G:吞吐量约为3.5G/s,相比较4C8G并没有翻倍,后端的cpu几乎吃满,光看这组数据不好定位瓶颈
- 16C32G:终于探到磁盘的底了,在cpu还有大量剩余的前提下,磁盘明显写不动了
磁盘的性能是真好,居然能压出 4 GB/s的速率,叹叹
三、Kafka吞吐量概述
一般描述某个kafka集群的吞吐量时,通常写为 3*n MB/s,例如 3*100 MB/s。 之所以习惯这样描述,是基于kafka自身的3副本协议,即1主2备的模式,leader收到业务流量n后,2个follower还需要从leader将数据同步过来,这样在集群角度看来,是一共处理了3*n流量

某个topic所拥有的副本数,理论上是不能大于整个集群的broker数量的,因为副本本质上是做高可用的,当topic的副本数大于整个集群的broker数量后,那势必某个broker存在2个及以上副本,这样也就丧失了高可用的初衷
3.1、集群横向扩容
所谓集群横向扩容,是指为集群添加同构broker,集群的broker数量初始为3,扩容后可能变为了6,这里的broker数量与topic的replica不是同一个概念,注意区分。
某个topic副本数过多,将带来集群内部大量的数据流转,而副本数过少,例如单副本,又存在一些高可用的风险,因此即便随着broker数量的增多,kafka最佳实践还是建议将topic的副本数设置为3,这样每增加3个broker,集群的能力将会得到横向的扩容

这里的横向扩容出来的能力跟broker数量是严格呈线性关系的,本文不会对横向扩容进行压测对比
3.2、集群纵向扩容
纵向扩容是指集群的broker数量不变,但是提升broker的配置。例如之前集群是3 * 2C4G的规格,进行纵向扩容后,集群将变为3 * 4C8G
broker的配置线性提升了,其提供的吞吐能力也会随着线性提升吗? 答案是否定的;如果磁盘用的是机械磁盘,我们可能很快能够断言瓶颈将卡在disk上,但SSD的高吞吐也是非常吃cpu的,内容比较复杂,内存、磁盘、cpu等都息息相关,这里没有很好的捷径,只能benchmark
纵向压测、对比也是本文的重心
四、发压准备
4.1、客户端准备
4.1.1、发压程序
发压程序使用官方的工具kafka-producer-perf-test.sh,这个工具实际调用的是kafka内核中的类:
org.apache.kafka.tools.ProducerPerformance当然,单个Producer的pool、开辟内存、与server端的连接等都是有上限的,因此真正发压时,需要启动多个发压进程。发压脚本如下
bash kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.10:9094,10.0.0.11:9094,10.0.0.12:9094 \
acks=1 \
buffer.memory=134217728 \
--producer.config=admin5.conf \
--topic topic_6 \
--throughput=-1 \
--num-records 100000000 \
--record-size 1024000admin5.conf 配置如下(因为开启了ACL认证,因此需要申明SASL配置)
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-a9asfbx5pl" password="a9asfbxmsn";关于发压脚本的参数配置做一下说明
- bootstrap.servers 连接集群的接入点
- acks 响应方式,这个对性能影响非常大,这里使用默认的1。有3种配置
- 1 : leader收到消息后便返回成功
- 0 : 不需要等待任何副本确认
- -1 : 生产者将等待所有的副本接收到消息并进行确认
- buffer.memory 这里是设置了producer的128M的缓冲区,默认为32M
- producer.config 因为目标集群开启了acl,这里需要存放一些相关配置
- throughput 发送流量的一个上限值,-1表示不设置上限
- num-records 发送消息的条数,因为要压测,所以这里放一个大值
- record-size 每条消息的大小。这里配置的1M,因为需要压测集群的极限值,这里直接设置一个相对大的值
- 注意,如果消息大小配置较小的话,可以通过调整batch.size及linger.ms参数来控制攒批
4.1.2、发压机器
因为kafka实例是被k8s孵化出来的,因此独立开辟了 5台ECS发压,其配置
|
10.252.128.183 |
8C 16G |
|
10.252.128.185 |
8C 16G |
|
10.252.128.136 |
4C 8G |
|
10.252.128.140 |
4C 8G |
|
10.252.128.176 |
4C 8G |
因为发压程序不会占用大量cpu及内存,当开启多进程压测时,只要网络带宽不是瓶颈就OK
4.2、服务端准备
4.2.1、常规压测配置
集群新建出来后,有一些关键的配置还是需要留意设置一下的,否则性能会打很大的折扣
|
配置项 |
建议值 |
说明 |
|
num.network.threads |
与cpu核数相近 |
broker端的网络线程,负责将数据从网卡搬运至broker堆内存中,这个过程涉及内存的拷贝,是一个典型的吃cpu的操作。设置太小,网卡搬运工作将会成为瓶颈,设置太大,又会造成频繁的线程切换,建议将其设置为cpu+1 |
|
num.io.threads |
2*cpu + 1 |
broker端典型的IO线程,所有写log的操作都是该线程触发的 |
|
log.retention.bytes |
-1 |
parition目录的最大阈值,当partition目录超过该值时就会触发删除老消息的操作。这个是kafka提供的原生配置,设置为-1,代表不对其做限制 |
|
log.flush.interval.messages |
Long.MaxValue |
接收到指定条数的消息后刷盘,这里建议配置为最大值,即刷盘的行为留给操作系统自己去控制。此值切勿设置的过小,否则将会导致磁盘频繁的sync,对性能影响很大 |
|
log.flush.interval.ms |
null |
达到指定时间后将内存中的消息刷盘。这个配置项与log.flush.interval.messages类似,也是刷盘的策略,这里同样建议不对其设置,交由操作系统来控制已获得最大的吞吐性能 |
|
message.max.bytes |
10M |
这个值限定了单条消息在broker端的上限,同样在producer也有一个参数来配置max.request.size,producer端的这个配置一定是要小于server端的 |
|
num.replica.fetchers |
cpu+1 |
这个值没有特定大小,根据不同的场景来设定,如果想保证配置 |
|
replica.fetch.max.bytes |
10M |
设置副本单次拉取的最大字节数,这个值需要大于单条消息的最大值,否则可能导致性能偏低 |
4.2.2、副本同步
前文说过,kafka选择不同的副本同步策略、同步副本数量,对性能影响很大;如果选择单副本的话,那么最大吞吐就是上文使用工具测出来的磁盘性能,而如果选择多副本的话,则整体吞吐的计算公式是是业务流量*副本数,后文我们将针对不同acks、num.replica.fetchers参数以及不同的副本数分别进行压测,最终得出一个多维参考值
4.2.3、服务端监控
服务端监控主要是查看集群整体流量、broker cpu、内存参数。我们通过top命令可以快速获取cpu、memory参数,而集群整体流量,为了快速获取,可通过JMX去拉取kafka原生监控项
public class JMXMain {
public static void main(String[] args) throws Exception {
new JMXMain().begin(args);
}
private void begin(String[] args) throws Exception {
String metricName = "kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec";
List<MBeanServerConnection> connectionList = initConnectionList(args);
while (true) {
long total = 0L;
long[] arr = new long[3];
int index = 0;
for (MBeanServerConnection connection : connectionList) {
Optional<ObjectName> first = connection.queryNames(new ObjectName(metricName), null).stream().findFirst();
if (first.isPresent()) {
Object oneMinuteRate = connection.getAttribute(first.get(), "OneMinuteRate");
long single = transToM(oneMinuteRate);
arr[index++] = single;
total += single;
} else {
System.out.println("none");
}
}
System.out.println(Arrays.toString(arr));
System.out.println("rate is " + total + " MB/sec");
Thread.sleep(10000);
}
}
private List<MBeanServerConnection> initConnectionList(String[] args) throws Exception {
// 10.0.0.21:9094,10.0.0.22:9094,10.0.0.23:9094
List<String> connList = new ArrayList<>();
if (args != null) {
for (String ip : args) {
String s = "service:jmx:rmi:///jndi/rmi://" + ip + ":5555/jmxrmi";
connList.add(s);
}
}
List<MBeanServerConnection> resultList = new ArrayList<>();
// String[] arr = {"service:jmx:rmi:///jndi/rmi://10.0.0.19:5555/jmxrmi", "service:jmx:rmi:///jndi/rmi://10.0.0.20:5555/jmxrmi", "service:jmx:rmi:///jndi/rmi://10.0.0.21:5555/jmxrmi"};
for (String jmxUrl : connList) {
System.out.println(jmxUrl);
JMXConnector connector = JMXConnectorFactory.connect(new JMXServiceURL(jmxUrl));
MBeanServerConnection connection = connector.getMBeanServerConnection();
resultList.add(connection);
}
return resultList;
}
public static long transToM(Object count) {
if (count == null) {
return 0;
} else {
double v = Double.parseDouble(count.toString()) / 1024 / 1024;
return (long) v;
}
}
}每隔10秒打印一下集群整体的流量及每个broker各自流量,例如:
[406, 407, 405]
rate is 1218 MB/sec
[409, 409, 407]
rate is 1225 MB/sec
[408, 408, 408]
rate is 1224 MB/sec
[406, 406, 405]
rate is 1217 MB/sec注意:这里打印的流量,仅包含leader处理的业务流量,不包括follower从leader同步的备份流量,例如,我创建一个单partition,3副本的topic,然后向集群写入100MB/s的流量,因为设置了3副本,因此虽然只会向其中某个broker发送数据,但是另外2个broker中同时也均会有100MB/s的备份流量,但是使用上述工具则只会打印leader的流量: [100, 0, 0]
五、发压
5.1、2C4G
5.1.1、单partition/单副本
最小配置,首先测试一下单partition、单replica 的性能,从而与磁盘极限性能做个对比;这个值体现了kafka单broker的极限能力
创建topic:【1 partition、1 replica、acks=1】
发压命令
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.10:9094,10.0.0.11:9094,10.0.0.12:9094 \
acks=0 \
max.request.size=2048000 \
--producer.config=/root/kafka_2.12-2.8.2/bin/admin5.conf \
--topic topic_1_1 \
--throughput=-1 --num-records 100000000 --record-size 1924000当启动了8个producer客户端后,监控集群的吞吐峰值来到了 550MB/s;其实启动了4个客户端后,吞吐量就达到了530,后续通过增加客户端数量带来的收益越来越小,说明broker端能力已达上限
[0, 546, 0]
rate is 546 MB/sec
[0, 545, 0]
rate is 545 MB/sec
[0, 550, 0]
rate is 550 MB/sec简单做个对比
|
规格 |
理论峰值 |
Kafka吞吐 |
|
2C4G |
1105 MB/sec |
550MB/s |
在开始对磁盘用工具进行压测时候,2C4G的规格就因为cpu成为了短板,压测工具自身没有消耗cpu的逻辑,几乎全量的cpu都消耗在了刷盘的操作中
而kafka的构成要比磁盘工具复杂很多,涉及内存的数据拷贝、数据解析、正确性验证、刷盘等,而这些操作无疑会消耗大量cpu,cpu本身就是短板,因此压测出来的kafka吞吐量会比理论值低很多
因此当前2C4G的3节点的极限能力是 3 * 550MB/s
5.1.2、多partition/三副本/all acks
当选项acks设置为all时,代表只有当3个副本的消息都落盘后,才会response,这个设置也是严格的保证了数据的高可用,不会有任何数据的丢失,同时这种配置也是效率最低的,我们创建一个 6 partition,3副本的topic,同时将acks设置为all,再查看此时的性能,做一个对比
创建topic:【6 partition、3 replica、acks=all】
发压命令
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.10:9094,10.0.0.11:9094,10.0.0.12:9094 \
acks=-1 \
max.request.size=2048000 \
--producer.config=/root/kafka_2.12-2.8.2/bin/admin5.conf \
--topic topic_6_3 \
--throughput=-1 --num-records 100000000 --record-size 1924000启动了4个producer客户端后,监控集群的吞吐峰值来到了 3 * 320MB/s
[106, 107, 105]
rate is 318 MB/sec
[107, 107, 106]
rate is 320 MB/sec
[108, 108, 106]
rate is 322 MB/sec
[108, 107, 107]
rate is 322 MB/sec
[108, 107, 107]
rate is 322 MB/sec
[108, 106, 107]
rate is 321 MB/sec4个客户端的延迟都已经很高,达到了400ms左右,说明数据都积攒到了broker端排队处理,4个客户端数据采样:
terminal-1:
230 records sent, 45.8 records/sec (84.07 MB/sec), 395.2 ms avg latency, 2228.0 ms max latency.
223 records sent, 44.4 records/sec (81.56 MB/sec), 437.7 ms avg latency, 1771.0 ms max latency.
terminal-4:
216 records sent, 43.1 records/sec (79.11 MB/sec), 429.5 ms avg latency, 1628.0 ms max latency.
225 records sent, 45.0 records/sec (82.54 MB/sec), 399.1 ms avg latency, 1279.0 ms max latency.可见,acks参数的不同,对最终结果的影响甚大
因cpu核数只有2,因此调整num.replica.fetchers参数对最终的压测影响不大,后续等cpu核数增加后可以考虑增加此值
5.1.3、多partition/三副本/leader
然而我们实际生产中,通常既不会将topic的副本数设置为1,也不会将acks设置为all,那么这个时候的最大流量值,体现的便是集群能够处理业务流量的峰值,一旦这个值超过了550MB/s,那么follower一定出现不同程度的落后leader的现象,等流量回落后,follower再逐步进行追赶,因此这个值也是具有相当重要的参考价值
创建topic:【3 partition、3 replica、acks=1】
发压命令
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh --producer-props bootstrap.servers=10.0.0.10:9094,10.0.0.11:9094,10.0.0.12:9094 acks=1 max.request.size=2048000 --producer.config=/root/kafka_2.12-2.8.2/bin/admin5.conf --topic topic_3_3 --throughput=-1 --num-records 100000000 --record-size 1924000启动了12个producer客户端后,监控集群的业务流量峰值来到约了 1GB/s
[347, 349, 343]
rate is 1039 MB/sec
[340, 345, 342]
rate is 1027 MB/sec
[339, 344, 341]
rate is 1024 MB/sec
[343, 347, 344]
rate is 1034 MB/sec客户端的延迟都已经达到了400ms左右,说明瓶颈不在客户端侧,客户端数据采样:
terminal-1:
228 records sent, 45.6 records/sec (83.60 MB/sec), 412.7 ms avg latency, 1173.0 ms max latency.
268 records sent, 53.5 records/sec (98.11 MB/sec), 334.0 ms avg latency, 774.0 ms max latency.
terminal-3:
218 records sent, 43.4 records/sec (79.62 MB/sec), 394.7 ms avg latency, 1422.0 ms max latency.
252 records sent, 50.3 records/sec (92.35 MB/sec), 377.1 ms avg latency, 1226.0 ms max latency.注意:我这里并没有使用 3 * 1GB/s 的描述,是因为虽然leader确实已经接受了1GB/s的流量,但是其并没有在同一时刻事实同步给follower,事实上,随着时间的推移,follower已经落后的越来越多
5.1.4、整理总结
|
能力 |
描述 |
流量 |
|
单broker磁盘能力 |
当前cpu+磁盘所具备的极限写入能力,作为判断kafka能力的参考 |
1105 MB/s |
|
严格写入能力 |
严格高可用地写入数据,即acks=all的方式写入数据,这种模式下,3个broker中的数据齐头并进 |
3 * 320 MB/s |
|
常规集群能力 |
用的最多的方式, acks=1,即写leader的模式,也是讨论最多的模式 |
3 * 550 MB/s |
|
可应对峰值能力 |
这种模式下,leader的流量将远大于follower的, |
1000 MB/s |
5.2、4C8G
相关认证配置 admin7.conf
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-acegzesojh" password="acegzesfmj";5.2.1、单partition/单副本
创建topic:【1 partition、1 replica、acks=1】
当启动了8个producer端时,集群的流量来到580 MB/s左右,这个值与2C4G的基本持平,难道它们两个的性能相当吗?其实不尽然,因为单partition、单副本的case,注定broker将会是同时写入1个文件,此时的瓶颈将落在IO上,因此,单纯的加cpu是不会提升吞吐的
[0, 584, 0]
rate is 584 MB/sec
[0, 589, 0]
rate is 589 MB/sec
[0, 586, 0]
rate is 586 MB/sec看一下cpu的使用率

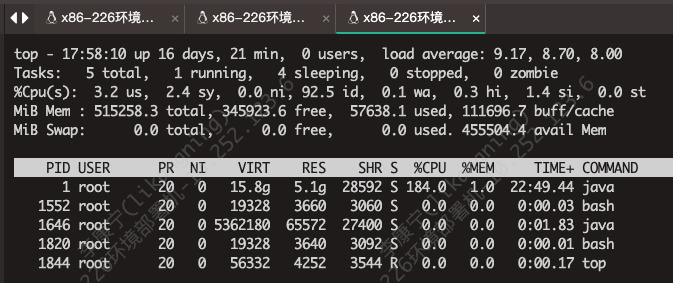
cpu基本维持在180%上下,而4C的上限是400%
5.2.2、multi 【单partition/单副本】
创建topic:4 * 【1 partition、1 replica、acks=1】
既然1个topic无法探知broker的上限,那我们就创建多个【单partition/单副本】的topic,使其落在同一个broker上,然后再向这个broker发压即可。(也可以通过手动指定将某个topic的分区都分布在1台broker上实现)
查看topic_1_1的ISR分布情况:
bash /root/kafka_2.12-2.8.2/bin/kafka-topics.sh \
--bootstrap-server 10.0.0.5:9094,10.0.0.9:9094,10.0.0.18:9094 \
--command-config /root/kafka_2.12-2.8.2/bin/admin7.conf \
--describe --topic topic_1_1返回结果
Topic: topic_1_1 Partition: 0 Leader: 1000 Replicas: 1000 Isr: 1000通过这种方式,选取4个topic:topic_1_1、topic_i_1_1、topic_j_1_1、topic_n_1_1,然后每个topic启动4个producer进行发压,也就是一共开启了16个client端发压
首先看一下broker端的流量统计指标,单broker的流量来到了 1GB/s
[0, 1009, 0]
rate is 1009 MB/sec
[0, 1016, 0]
rate is 1016 MB/sec
[0, 1021, 0]
rate is 1021 MB/sec
[0, 1016, 0]
rate is 1016 MB/sec
[0, 1015, 0]
rate is 1015 MB/sec再观察一下cpu利用率,维持在400%,已经打满

客户端的监控日志采样。延迟也高达500ms,说明压力已经完全给到了broker
196 records sent, 38.8 records/sec (71.24 MB/sec), 457.4 ms avg latency, 560.0 ms max latency.
167 records sent, 33.4 records/sec (61.21 MB/sec), 536.9 ms avg latency, 649.0 ms max latency.
147 records sent, 29.1 records/sec (53.35 MB/sec), 623.0 ms avg latency, 782.0 ms max latency.
184 records sent, 36.6 records/sec (67.19 MB/sec), 489.4 ms avg latency, 588.0 ms max latency.
189 records sent, 37.8 records/sec (69.33 MB/sec), 478.6 ms avg latency, 563.0 ms max latency.至此,探知当前配置的单broker的处理上限为 1 GB/s,因此集群的最大吞吐为 3 * 1 GB/s
5.2.3、多partition/三副本/all acks
创建topic:【6 partition、3 replica、acks=-1】
发压命令
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.27:9094,10.0.0.28:9094,10.0.0.29:9094 \
acks=-1 max.request.size=2048000 \
--producer.config=/root/kafka_2.12-2.8.2/bin/admin77.conf \
--topic topic_a_6_3 --throughput=-1 \
--num-records 100000000 --record-size 1924000吞吐停留在330 MB/s,怎么跟2C4G的相差不大呢?
[112, 111, 111]
rate is 334 MB/sec
[112, 111, 111]
rate is 334 MB/sec
[112, 111, 112]
rate is 335 MB/sec这里别忘了一个参数num.replica.fetchers,这个参数默认为1,调大这个参数将加快follower从leader拉取数据的速率;我们首先看下当前这个参数的设置:
sh kafka-configs.sh \
--bootstrap-server 10.0.0.27:9094,10.0.0.28:9094,10.0.0.29:9094 \
--command-config admin77.conf --all \
--entity-type brokers --describe | grep "num.replica.fetchers"最终返回
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}这个参数是可以调用命令进行直接修改的,我们将其修改为cpu核数
sh kafka-configs.sh \
--bootstrap-server 10.0.0.27:9094,10.0.0.28:9094,10.0.0.29:9094 \
--command-config admin77.conf \
--alter --entity-type brokers --entity-default \
--add-config 'num.replica.fetchers=4' 最终broker的性能提升至了550 MB/s
[181, 182, 182]
rate is 545 MB/sec
[183, 184, 183]
rate is 550 MB/sec
[183, 184, 183]
rate is 550 MB/seccpu利用率也相当低,大量的耗时都停留在三副本sync上

5.2.4、多partition/三副本/leader
将参数“num.replica.fetchers”调整为默认值后,同时将acks设置为1,再次发压
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.27:9094,10.0.0.28:9094,10.0.0.29:9094 \
acks=1 max.request.size=2048000 \
--producer.config=/root/kafka_2.12-2.8.2/bin/admin77.conf \
--topic topic_a_6_3 --throughput=-1 \
--num-records 100000000 --record-size 1924000共启动了16个客户端,流量来到了2200 MB/s
[734, 737, 733]
rate is 2204 MB/sec
[734, 736, 744]
rate is 2214 MB/sec
[737, 745, 741]
rate is 2223 MB/sec同时cpu被打满

部分发压程序日志采样。随着producer的增多,吞吐量维持在恒定值
432 records sent, 86.2 records/sec (158.12 MB/sec), 198.7 ms avg latency, 1601.0 ms max latency.
378 records sent, 75.4 records/sec (138.33 MB/sec), 238.2 ms avg latency, 1297.0 ms max latency.
413 records sent, 82.4 records/sec (151.17 MB/sec), 222.9 ms avg latency, 1315.0 ms max latency.
353 records sent, 70.5 records/sec (129.39 MB/sec), 268.1 ms avg latency, 1442.0 ms max latency.5.2.5、整理总结
|
能力 |
描述 |
流量 |
|
单broker磁盘能力 |
当前cpu+磁盘所具备的极限写入能力,作为判断kafka能力的参考 |
2580 MB/s |
|
严格写入能力 |
严格高可用地写入数据,即acks=all的方式写入数据,这种模式下,3个broker中的数据齐头并进 |
3 * 550 MB/s |
|
常规集群能力 |
用的最多的方式, acks=1,即写leader的模式,也是讨论最多的模式 |
3 * 1000 MB/s |
|
可应对峰值能力 |
这种模式下,leader的流量将远大于follower的,会产生了流量倾斜 |
2250 MB/s |
5.3、8C16G
用到的配置信息 admin6.conf
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-acntgcoin9" password="acntgcozqb";5.3.1、multi 【单partition/单副本】
创建topic:【12 partition、1 replica、acks=1】
通过命令创建topic,将12个分区全部都放在第一个broker上
bash /root/kafka_2.12-2.8.2/bin/kafka-topics.sh \
--bootstrap-server 10.0.0.5:9094,10.0.0.6:9094,10.0.0.7:9094 \
--command-config /root/kafka_2.12-2.8.2/bin/admin6.conf \
--create --topic topic_1_1 \
--replica-assignment 1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000启动28个producer端发压客户端后,broker流量趋于稳定
[1964, 0, 0]
rate is 1964 MB/sec
[1959, 0, 0]
rate is 1959 MB/sec
[1962, 0, 0]
rate is 1962 MB/sec查看对应pod的cpu使用率,已经打满

最终得出结论,单台broker的吞吐上限为 1.9 GB/s
5.3.2、多partition/三副本/all acks
创建topic:【12 partition、3 replica、acks=-1】
当前规格配置较高,需要创建更多的partition以压榨更多的cpu资源
查看参数num.replica.fetchers
sh kafka-configs.sh \
--bootstrap-server 10.0.0.5:9094,10.0.0.6:9094,10.0.0.7:9094 \
--command-config admin6.conf --all \
--entity-type brokers --describe | grep "num.replica.fetchers"返回
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}
num.replica.fetchers=1 sensitive=false synonyms={DEFAULT_CONFIG:num.replica.fetchers=1}用同样的方法查看参数replica.fetch.max.bytes,返回
replica.fetch.max.bytes=30240000 sensitive=false synonyms={STATIC_BROKER_CONFIG:replica.fetch.max.bytes=30240000, DEFAULT_CONFIG:replica.fetch.max.bytes=1048576}
replica.fetch.max.bytes=30240000 sensitive=false synonyms={STATIC_BROKER_CONFIG:replica.fetch.max.bytes=30240000, DEFAULT_CONFIG:replica.fetch.max.bytes=1048576}
replica.fetch.max.bytes=30240000 sensitive=false synonyms={STATIC_BROKER_CONFIG:replica.fetch.max.bytes=30240000, DEFAULT_CONFIG:replica.fetch.max.bytes=1048576}将参数num.replica.fetchers修改为cpu核数
sh kafka-configs.sh \
--bootstrap-server 10.0.0.5:9094,10.0.0.6:9094,10.0.0.7:9094 \
--command-config admin6.conf \
--alter --entity-type brokers --entity-default \
--add-config 'num.replica.fetchers=8' 发压
bash /root/kafka_2.12-2.8.2/bin/kafka-producer-perf-test.sh \
--producer-props \
bootstrap.servers=10.0.0.5:9094,10.0.0.6:9094,10.0.0.7:9094 \
acks=-1 \
max.request.size=2048000 \
--producer.config=/root/kafka_2.12-2.8.2/bin/admin6.conf \
--topic topic_a_12_3 --throughput=-1 --num-records 100000000 --record-size 1924000一共启动了24个producer压测,强劲的cpu发挥了作用,写入速率达到了950 M/s
[315, 315, 315]
rate is 945 MB/sec
[315, 317, 318]
rate is 950 MB/sec
[313, 317, 317]
rate is 947 MB/sec5.3.3、多partition/三副本/leader
创建topic:【12 partition、3 replica、acks=1】
按照常规,我们压一下三副本写leader的case;此时num.replica.fetchers同样设置为8
启动28个压测客户端后,流量趋于稳定
1034, 1032, 1028]
rate is 3094 MB/sec
[1034, 1038, 1034]
rate is 3106 MB/sec
[1036, 1039, 1040]
rate is 3115 MB/sec客户端延迟1s+
426 records sent, 85.1 records/sec (156.14 MB/sec), 204.5 ms avg latency, 1791.0 ms max latency.broker cpu使用率接近饱和

至此,可以得出结论,陡增业务流量可承接 3.1 GB/s
5.3.4、整理总结
当前规格,cpu还是短板,无法触及磁盘的3.6GB/s
|
能力 |
描述 |
流量 |
|
单broker磁盘能力 |
当前cpu+磁盘所具备的极限写入能力,作为判断kafka能力的参考 |
3674 MB/s |
|
严格写入能力 |
严格高可用地写入数据,即acks=all的方式写入数据,这种模式下,3个broker中的数据齐头并进 |
3 * 950 MB/s |
|
常规集群能力 |
用的最多的方式, acks=1,即写leader的模式,也是讨论最多的模式 |
3 * 1920 MB/s |
|
可应对峰值能力 |
这种模式下,leader的流量将远大于follower的, |
3100 MB/s |
5.4、16C32G
这个配置规格与另外3个规格有本质的区别,当前规格在使用磁盘压测工具时,已经窥探到了磁盘的上限,我们继续benchmark,看它的压测数据。用到的配置信息 admin0.conf
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-acrk9ciqkx" password="acrk9cihnz";5.4.1、multi 【单partition/单副本】
创建topic:【24 partition、1 replica、acks=1】
通过命令创建topic,将24个分区全部都放在第一个broker上
bash /root/kafka_2.12-2.8.2/bin/kafka-topics.sh \
--bootstrap-server 10.0.0.5:9094,10.0.0.6:9094,10.0.0.7:9094 \
--command-config /root/kafka_2.12-2.8.2/bin/admin0.conf \
--create --topic topic_1_1 \
--replica-assignment \
1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000启动35个producer端发压客户端后,broker流量趋于稳定
[0, 2714, 0]
rate is 2714 MB/sec
[0, 2717, 0]
rate is 2717 MB/sec
[0, 2719, 0]
rate is 2719 MB/sec查看对应pod的cpu使用率

最终得出结论,单台broker的吞吐上限为 2.7 GB/s
不对啊,这个与预期不符的,单broker能力上限的探测,8C16G已经达到了 1.9G/s,而当前配置预期可以达到 4G/s的,可无论怎么压,顶多到达 2.7+ GB/s,到底哪里是瓶颈呢?
- cpu ? cpu明显不是瓶颈,当前broker的cpu使用率还有富余
- 磁盘? 2.7 GB/s 显然没有达到disk的上限,上文已经探知其上限为 4GB/s
- 发压端? 发压端为了压测最大规格的实例,又额外申请了一个16C32G的压测机,而且即便是将客户端数量提升至40个,依旧没有变化,甚至可能有小幅度的下掉
既然都不是瓶颈,为什么吞吐上不去呢?难道瓶颈落在了网卡上?
5.4.2、网卡带宽探测--iperf3
这里我们还是很有必要探测一下网卡带宽的上限,使用的压测工具是
「iperf3」
- 启动server端程序
iperf3 -s
- 这里-s是-server的缩写,标明当前启动的是server端程序,默认监听5201端口
- 启动client端
iperf3 -c 21.100.18.151 -P 8
- -c 指启动client端,后面的IP是server端IP
- -P 8 启动并发连接数。这个要额外注意,如果不指定的话,默认是启动1个链接测试,这个时候网卡是打不满的,具体设置为多少能打满,需要反复不断测试
当将并发连接数设置为8时,达到网络传输的峰值
server端日志
[SUM] 0.00-10.04 sec 23.6 GBytes 20.2 Gbits/sec receiverclient端日志
...
[SUM] 6.00-7.00 sec 2.64 GBytes 22.7 Gbits/sec 0
....
[SUM] 0.00-10.00 sec 23.7 GBytes 20.3 Gbits/sec 214 sender
[SUM] 0.00-10.04 sec 23.6 GBytes 20.2 Gbits/sec receiver
iperf Done.虽然压测的平均速率是20.3 Gbits/sec,但其曾经最高速率达到了22.7 Gbits/sec,因此我们就那这个进行计算。因为这个的单位是bit,我们需要将其转换为byte
22.7Gbits/8 = 2.8 GB/s
果然与我们压测的 2.72 GB 对应上了,压力实实在在的给到了网卡
5.4.3、多partition/三副本/all acks
创建topic:【24 partition、3 replica、acks=-1】
根据之前的磁盘压测工具已经判断出,当前的规格实例的cpu已经不是短板,因此我们这里将partition数量设置大一些。另外一些配置的修改
- 将参数num.replica.fetchers修改为cpu核数
- 将参数replica.fetch.max.bytes设置为20M
这样做的目的是加快follower同步leader数据的速率,经过一段时间发压后,broker端的速率来到了1350 MB/s
[448, 450, 446]
rate is 1344 MB/sec
[451, 450, 450]
rate is 1351 MB/sec
[452, 451, 450]
rate is 1353 MB/sec8C16G的速率接近 1GB/s,而当前规格虽然配置翻倍了,但是速率却没能翻倍,为什么呢?其实这里也是符合预期的,因为8C16G的集群已经非常接近磁盘上限了,压出了3580 MB/s的吞吐,而16C32G也只能压出4GB/s的吞吐,因此瓶颈已经悄悄转移至磁盘上了(acks=all的情况,很大一部分开销在3副本的sync上)
其实这里我对不同partition的速率也做了压测,这里简单公布结论
|
partition |
吞吐(MB/s) |
|
12 |
950 |
|
18 |
1200 |
|
21 |
1350 |
|
24 |
1350 |
5.4.4、整理总结
因为已经将短板确定为网卡,我们这里不再对峰值进行赘述
|
能力 |
描述 |
流量 |
|
单broker磁盘能力 |
当前cpu+磁盘所具备的极限写入能力,作为判断kafka能力的参考 |
4080 MB/s |
|
严格写入能力 |
严格高可用地写入数据,即acks=all的方式写入数据,这种模式下,3个broker中的数据齐头并进 |
3 * 1350 MB/s |
|
常规集群能力 |
用的最多的方式, acks=1,即写leader的模式,也是讨论最多的模式 |
3 * 2720 MB/s |
六、总结
此处我们还是有必要对流量规格再做个说明,以2C4G来举例,我们对外宣讲的流量规格是
「 3 * 550 MB/s 」
即集群可以处理 550 MB/s的吞吐,且在集群内部做好了经典三副本同步,因此站在partiton leader的视角,我们脑海中的画面可能是这样的:

而实际结果很有可能是这样的

甚至这样

这取决于follower从leader的拉取策略,比如参数num.replica.fetchers、replica.fetch.max.bytes等的配置,但在磁盘吞吐较高的背景下,又加剧了同步的不稳定性;以下分别以低IO及高IO进行阐述
- 低IO:集群的磁盘吞吐并不高,例如50 MB/s,集群的吞吐瓶颈会落在了IO上,因此当数据进来后会首先进入page cache中,然后再由操作系统异步刷盘到磁盘中。因为吞吐不高,因此新数据在page cache中存活的时间相对较长,当follower从leader拉取数据时,数据大概率还在cache当中,此时调用kafka的零拷贝,将数据copy走,性能快,速率稳定,且不占用磁盘IO
- 高IO:就像我们现在部署的集群,IO的吞吐非常高,拿2C4G的规格来讲,单broker的写入速率可达 550 MB/s,而内存只有4个G,其中Java堆内存又会占用2.5个G,以及操作系统本身的占用,留给page cache的空间满打满算也就1G左右,那数据进入在page cache中停留的时间不会超过2秒,等follower来拉取数据时,大概率是需要从disk设备中进行二次读取的,这就占用了磁盘的带宽,也让整个拉取的过程变得相对不稳定
但我们同样测出了acks=all场景中,流量的一个相对精确的保底值,供大家参考
总结各规格集群吞吐如下
|
规格 |
Broker数量 |
流量 Acks=all |
流量 Acks=1 |
|
2C4G |
3 |
3 * 320 MB/s |
3 * 550 MB/s |
|
4C8G |
3 |
3 * 550 MB/s |
3 * 1100 MB/s |
|
8C16G |
3 |
3 * 950 MB/s |
3 * 1920 MB/s |
|
16C32G |
3 |
3 * 1350 MB/s |
3 * 2720 MB/s |
测试多规格kafka集群的极限吞吐是一个艰巨的任务,其中至少涉及
- 网络
- cpu
- 磁盘/网络 IO
- kafka攒批模式/消息体大小
- 刷盘策略
- 不同规格的partition控制
- replica副本同步策略
- 发压端控制
- 网络线程/IO线程搭配
- 等等。。
这些环节中,只要有1个掉链子,那整个链路的吞吐也会拉胯;另外上述所有case,Java堆空间只分配了系统一半的内存,另一半留给了page cache
标签:replica,MB,--,kafka,调优,sec,集群,Kafka,root From: https://www.cnblogs.com/xijiu/p/17878078.html