避免重复造轮子,前提是轮子已经造得很好。

大模型有多卷?
现在国内已经有180个以上生成式大模型,科技大厂、互联网大厂纷纷入局,既有百度、浪潮信息、阿里、腾讯等一众巨头,也有专攻AI的讯飞、商汤等垂直领域小巨头,以及“日日新”的创业企业。
今天A厂商发布大模型,各种参数对比下来堪称最强,第二天B厂商发布下来,又刷新了各种记录。最强、最大、强快,有可能只保持一天。这说明什么?基础大模型还有很大的进化空间。
11月27日,算力龙头企业浪潮信息发布了完全开源且可免费商用的源2.0基础大模型,包含1026亿、518亿、21亿不同参数规模,这也是国内首个千亿参数、全面开源的大模型。
作为一家做算力基础设施的公司,为什么如此努力地卷大模型?浪潮信息高级副总裁、AI&HPC总经理刘军表示:最终用户感受到的大模型能力是其在应用层面能力的表现,这些核心能力的本质,是由基础大模型能力所决定的。在他看来,今天模型基础能力与客户预期之间仍有较大的差距,这也是浪潮信息不断探索的原因所在。
GPT4不是天花板,百模大战探索“更优解”

GPT3.5的发布,算得上是AI产业发展的一个重要拐点,很多人将之称为AI的“苹果时刻”。今年3月,OpenAI发布了GPT4,GPT4的能力比GPT3.5有一个巨大的提升,GPT4是当前业界最先进的技术大模型。
但是,即便是当前公认最先进的大模型,GPT4其实也还有很多挑战没有解决。
比如算力短缺,一直是OpenAI在其迅速崛起过程中不得不面对的一个棘手问题。当用户海量涌入的时候,OpenAI已经出现过几次崩溃的情况。为此,OpenAI采用了不同级别的会员收费,对用户进行分层。并且还一度还采用停止注册的方式来限制用户的使用量,缓解算力压力。
再比如AI幻觉。今天的GPT4给出的答案并不完全正确,有时候会有明显的事实错误,有时候也会一本正经地胡说八道。这里面也有很多原因,比如数据来源的问题,再比如不同法律体系、不同价值观下的分歧等等。
GPT4遇到的挑战还有很多,这些都是整个行业正在面临的挑战。今天,看上去大模型这个领域非常卷,但本质上还是处于产业初期。一方面,国产基础大模型的能力和 Open AI 之间存在较大的差距,另一方面即使是最先进的GPT4,现在的能力还处于初级阶段,很多问题依旧在探索开发。
通用大模型基座作为通用人工智能的核心基础设施,被嵌入到智能助手、机器翻译、自动化客服等场景中,从而实现更加个性化、智能化、自适应的服务和应用。IDC预测,到2026年,全球AI计算市场规模将增长到346.6亿美元,生成式AI计算占比从22年4.2%增长到 31.7%。
通用大模型是大模型产业的地基,地基的深度和强度决定大厦的高度。大模型和应用之间的关系,如果用上学和工作来比喻:大模型是12年小初高阶段,垂直行业大模型是大学分专业学习的阶段,应用则是进入到工作岗位开始为企业、社会创造价值的阶段。
今年掀起百模大战之后,业界有一种观点认为不应该浪费资源重复造轮子。但前提是轮子已经比较成熟,如果今天的轮子还不好用,就值得更多的企业投入进来,探索各种不同的路径来把轮子造好。所以,最近业内正在形成新的共识:在产业初期,适度的泡沫还是必要的。中国大模型的“百花齐放”是利好的,很大程度它可以激活创新,促进产业生态的繁荣发展。
 浪潮信息人工智能软件研发总监吴韶华
浪潮信息人工智能软件研发总监吴韶华
“确实在当前大模型百花齐放的态势下,必然大家会有不同的实现路径,也会有理念冲突,这都是特别正常的事情。因为毕竟大家都在探索,都没有出来一条非常有效的路径。” 浪潮信息人工智能软件研发总监吴韶华表示。
浪潮信息为什么也要进来一起卷大模型?浪潮信息左手有做大模型的伙伴,右手有做垂直行业应用的伙伴,可以说既懂底层技术又有上层应用经验。更重要的是作为一家算力基础设施公司,在产业初期,浪潮信息在算力上的探索会给整个产业带来很大的推动力,比如算力资源的高效性、算力集群的可扩展性、算力系统的可持续性,这些都能让算力更充分地释放出来,这对整个产业都有极大的价值。
浪潮信息做大模型主要是两个维度的探索:一是探索路径、方法,比如有什么架构可以节省算力,什么模型可以让数据更精准等等。二是探索边界,今天大模型已经能做很多事,但随着算力、算法、数据的迭代,新的能力也不断被挖掘出来,大模型的上限到底在哪里?
看上去已经很激烈的百模大战,只是生成式AI的起点。通用大模型是一项异常复杂的系统工程,需从系统层面达以创新,从算力效率、线性扩展、长效稳定等多个方面进行探索。今天,没有哪个企业有绝对的优势,算力、算法、数据三要素都有很大的进化空间,此外还需要更好的应用来落地大模型的价值。也就是说,大模型还要卷,同时应用也要卷,打通一个能持续跑起来的飞轮生态,百模大战的效果才真正实现了。
基因、智商、情商,打造“三高”大模型
作为最早布局大模型的企业之一,浪潮信息早在2019年就推出了中文AI巨量模型“源1.0”,是当时最大参数的大模型。“源”大模型的数据集和清洗经验和帮助国内不少AI团队提升了其大模型的性能表现,比如助力网易伏羲中文预训练大模型“玉言”登顶中文语言理解权威测评基准CLUE分类任务榜单,并在多项任务上超过人类水平。过去的两年,源1.0大模型的智能力与To B领域复杂的服务场景进行深度融合,构建专家级数据中心智能客服大脑,荣获哈佛商业评论鼎革奖。

但是,源1.0开放出来之后,在客户的应用场景中遇到了很多具体的问题。所有这些问题,都是浪潮信息升级源2.0的发出点。此外,GPT4是一个封闭的系统,就是一个黑盒子,大家不知道它是怎么做的。那么,中国的大模型也需要更多的创新,才有机会去超越GPT4。
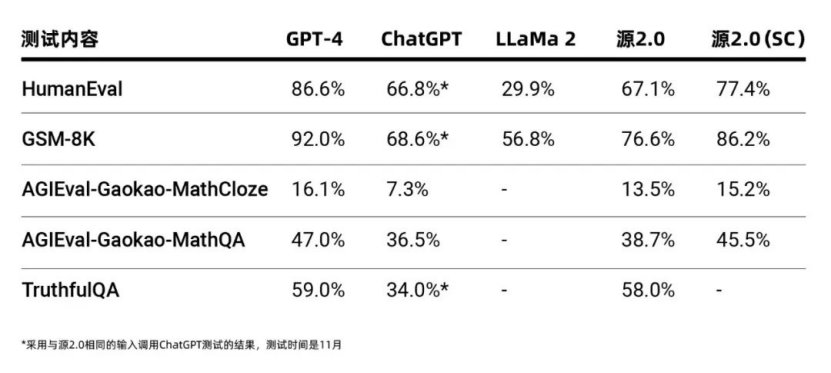
简单来讲,浪潮信息源2.0在数据、算力、算法三个维度向前迈进了一大步。在懂懂看来,数据决定大模型的基因,算力是决定大模型的智商,算法决定大模型的情商,所以这是“更聪明“的大模型的核心三要素,源2.0就是一个“三高”大模型。
先说说数据。
“在有限的算力资源上,训练数据的质量,直接决定了模型的性能,这个性能主要是指模型的智能化水平在任务上的表现。” 吴韶华强调,数据体量很重要,但是数据质量更重要。在源2.0中,浪潮信息的思路就是进一步提纯数据,让模型能基于更高水平的数据来训练。
具体而言,源2.0通过使用中英文书籍、百科、论文等资料,结合高效的数据清洗流程,为大模型训练提供了高质量的学科专业数据集和逻辑推理数据集。除此之外,为了更高效地获得高质量的代码数据集,浪潮信息提出基于主题词或Q&A问答对自动生成编程题目和答案的数据集生成流程,提高了数据集问题的多样性和随机性;同时提出基于单元测试的数据清洗方法,可以更加高效地获取高质量数据集,提高训练效率。
“我们这套数据构建方法,能够比较有效的解决互联网海量数据清洗问题。我们后续的计划是用我们的模型产生更高质量的数据,然后持续迭代,来提升我们大模型的能力。”刘军表示。
接下来讲一下算法。
传统Transformer结构被业界广泛采用,但是对中文的识别并不是最佳模式。源2.0有一个很大的创新,就是把attention(自注意力)这一层,采用了自研的新型LFA(Localized Filtering-based Attention)结构,中文名字是局部注意力过滤增强机制。考虑到自然语言输入的局部依赖性,LFA通过先强化相邻词之间的关联性,然后再计算全局关联性的方法,有效地解决了传统Transformer结构中对所有输入的文字一视同仁,不能考虑自然语言相邻词之间的强语义关联的问题,能够更好地处理自然语言的语序排列问题,对于中文语境的关联语义理解更准确、更人性,提升了模型的自然语言表达能力,进而提升了模型精度。
“我们发现在源2.0这个阶段,依然是处于研究方向的初级阶段,后面还有很多的可能性。围绕着这个方向,我们团队也会继续研究下去,来尝试进一步的得到更好的模型结构。” 吴韶华表示。
最后再来说说计算。
全球算力紧缺是一个短期内很难缓解的痛点,所以计算的调优,是整个产业都迫切需要突破的瓶颈,而这也恰好正是浪潮信息的优势所在。
为了在各类计算设备上都有一个非常好的计算性能表现,源2.0中提出了非均匀流水并行+优化器参数并行(ZeRO)+数据并行的策略。相较于经典的三维并且方法,创新算法有更好的适用性,显著降低了经典大模型训练过程中对于AI芯片之间的通讯带宽需求,同时还能获得非常高的性能表现。
大模型算力系统并不是算力的简单堆积,其需要解决低时延海量数据交换的挑战;需要解决多台机器均衡计算、避免冷热不均、消弭算力堵点的问题;需要解决在几个月漫长的计算过程中,当单一硬件出现故障时,训练中断、梯度爆炸、算法重新走一遍等等问题。所以,源2.0也不是浪潮信息的最终“答卷”。尽管源2.0已经拥有非常出色的表现,但是在刘军看来,这只是开了个头,未来还有很多值得挖掘的方向,浪潮信息会不断创新升级。
卷大模型还是卷应用?都要从开源中找答案
是应该卷模型还是卷应用?业界是有不同观点的。
很多做大模型的企业,都主张应该卷应用。现在百模酣战,是不是可以向前迈一步,开始卷应用了?
百度李彦宏在今年3月份就提出下一步的方向是大模型的应用,随后在10月份的百度大会上一口气发布了几十个原生应用。从做大模型的企业来看,一定是在自己的模型上卷应用,让模型不断进化,让应用价值不断落地,这是没有错的。
 浪潮信息高级副总裁、AI&HPC总经理刘军
浪潮信息高级副总裁、AI&HPC总经理刘军
那为什么还有那么多企业参与到百模大战当中呢?中国的大模型与GPT4还有或多或少的差距,即使是GPT4也还没有进化到天花板,也依然有很大的提升空间。此外,刘军认为未来的生成式AI是多元化生态,每个基础大模型可能会有不同的擅长领域。
所以,放到整个产业的视角来看,大模型和应用都要卷:一方面需要继续提升基础大模型的能力,因为只有基础大模型做好了才能更好地实现行业落地;另一方面,需要在应用落地方面继续创新。只有大模型侧和应用侧同时发力,双轮驱动,生成式AI的发展甚至是中国的AI产业才会有更好的前景。
双轮驱动,怎么卷才能最高效?答案是:开源。
在移动互联网时代,有一个封闭的iOS系统,还有一个开源的安卓系统。苹果很强大,自己就支撑了一个生态。但安卓更强大,开放的安卓系统吸引更多的手机厂商,更多的开发者,也衍生出一个更庞大的生态。
今年上半年,Meta的LLaMA开源,给业界开了一个好头。正是看到开源的能量,国内的大模型也纷纷加入开源的阵营,包括阿里云、百川、智谱AI、清华EKG等等。这一次源2.0也彻底开源,并且这是行业首个千亿开源大模型。
“完全免费、完全可商用、不需要授权、最彻底的开源。”吴韶华表示,浪潮信息希望通过开源真正的能够普惠产业用户,个人开发者,让大家能够通过源2.0构建更强的AI系统。

刘军强调,开源最本质的好处是让整个产业能够协同发展,“回顾过去所有成功的开源项目,都是因为整个社区共同贡献的结果。”
首先,开源可以建立一个高效的反馈闭环,通过应用反哺大模型,加速大模型的进化。
浪潮信息希望通过开源吸引更多的开发者进来,同时发起了大模型共训计划,开发者可以在源2.0上自由地开发,如果遇到问题可以反馈给浪潮信息,尽快地提升模型的能力。
其次,开源可以更广泛地赋能行业、赋能企业,加速大模型价值的落地。
优秀开源模型是吸引开发者、繁荣生态的关键因素。以开放的心态开源,给开发者更强有力的支持,他们可以直接调用API、中文数据集、模型训练代码等,大大降低开发者将大模型能力适配不同场景的难度,加速应用的落地,让企业尽快吃到AI时代的红利。
所以,无论是卷大模型还是卷应用,开源都是一条光明大道。
【结束语】
在诸多大模型中,浪潮信息也卷了进来。与其它大模型不同之处,就是其在计算方面的优势,通过算力的产品和技术的创新推动数字化、智能化的发展。
源从1.0进化到2.0,给产业打个样,通过智算的力量去训练生成式AI大模型,浪潮信息的很多探索成果,可以赋能加速AI产业化和产业AI化的进步。
标签:AI,模型,浪潮,再卷,做算力,2.0,算力,开源 From: https://www.cnblogs.com/dongdongbiji/p/17875535.html