以下笔记参考huggingface 官方 tutorial: https://huggingface.co/learn/nlp-course/chapter6
下图展示了完整的 tokenization 流程,接下来会对每个步骤做进一步的介绍。
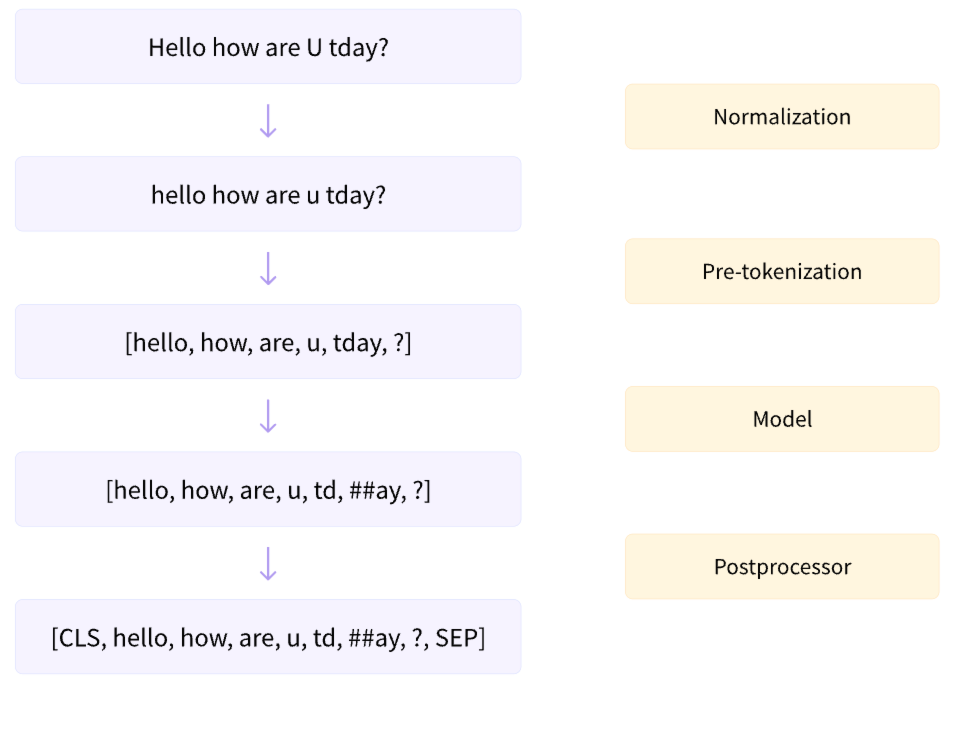
1. Normalization
normalize 其实就是根据不同的需要对文本数据做一下清洗工作,以英文文本为例可以包括删除不必要的空白、小写和/或删除重音符号。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
>>> 'hello how are u?'
2. Pre-tokenization
数据清洗好后,我们需要将文本作划分。对于英语而言,最简单的划分逻辑就是以单词为单位进行划分。不过即使是这么简单的规则也可以细分出很多不同的划分方式,下面展示了 3 种划分方式,它们适用于不同的模型训练,返回的是一个 list,每个元素是一个tuple。tuple 内第一个元素是划分后的sub-word,第二个元素是其初始和结尾的索引。
- bert 的最简单,真的就是最符合直觉的 huafenfangshi
- gpt2划分的不同点是单词前如果有空格的话,空格会转换成一个特殊字符,即 Ġ。
- t5 类似 gpt2 也考虑了空格,不过空格被替换成了 _

3. BPE Tokenization
上面Pre-tokenization展示的是比较简单的划分方式,但是他们的缺点是会导致词表非常大。而且,我们知道英文单词是有词根的,并且一个动词会有不同的时态,简单的以单词为单位划分,不太便于表示单词之间的相似性。所以一种可行的办法是我们寻找单词间的公约数,即把单词拆分成若干个 sub-word。为方便理解,我们可以以 like, liked, liking 为例,这三者的公约数是 lik, 所以分别可以拆分成如下(实际上的拆分并不一定就是下面的结果,这里只是为了方便解释说明):
- ["lik", "e"]
- ["lik", "ed"]
- ["lik", "ing"]
模型在计算这三个单词的相似性的时候,因为他们具有相同的"lik",所以肯定会认为有很高的相似性。类似的,当模型计算两个都带有"ed"的单词的时候,也会知道这两个单词也会有相似性,因为都表示过去式。
那么如何寻找公约数呢?大佬们提出了不同的算法,常见的三个算法总结在下表里了:

3.1 BPE 原理解释
这一小节我们着重介绍一下最常见的算法之一:BPE (Byte-pair Encoding)。huggingface官方tutorial 给出了非常详细的解释,这里做一个简单的介绍。
BPE 其实是一个统计算法,不同意深度神经网络,只要给定一个数据集或者一篇文章,BPE 不管运行多少次都会得出同样的结果。下面我们看看 BPE 到底是在做什么。
为了方便理解,我们假设我们的语料库中只有下面 5 个单词,数字表示出现的频率:
语料库:[("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)]
BPE 根据上述单词表首先初始化生成基础词汇表(base vocabulary),即
词汇表:["b", "g", "h", "n", "p", "s", "u"]
我们可以将每个单词看成是一个由多个基础 token 组成的 list,即
[("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)]
接下来,正如 BPE 的名字 byte-pair 所表示的,它会对每个单词内部相邻的 token 逐一进行两两匹配,然后找出出现频率最高的那一对,例如,("h" "u" "g", 10) 匹配结果会到的 ("h", "u", 10) 和 ("u", "g", 10),其他单词同理。
通过遍历所有单词我们可以发现出现频率最高的 ("u", "g"),它在 "hug"、"pug" 和 "hugs" 中出现,总共出现了 20 次,所以 BPE 会将它们进行合并(merge),即 ("u", "g") -> "ug"。这样基础词汇表就可以新增一个 token 了,更新后的词汇表和语料库如下:
词汇表:["b", "g", "h", "n", "p", "s", "u", "ug"]
语料库:("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
我们继续重复上面的 遍历和合并 操作,每次词汇表都会新增一个 token。当词汇表内 token 数量达到预设值的时候就会停止 BPE 算法了,并返回最终的词汇表和语料库。
3.2 BPE 代码实战
3.2.1. 初始化一个简单的文本数据集,如下
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
3.2.2. pre-tokenization (初始化语料库和词汇表)
- 语料库
normalize 步骤就省略了。我们直接先构建一下语料库,以单词为单位对原始文本序列进行划分,并统计每个单词的频率。
from transformers import AutoTokenizer
from collections import defaultdict
tokenizer = AutoTokenizer.from_pretrained("gpt2")
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
print(word_freqs)
>>> defaultdict(int, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1,
'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1,
'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1,
'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
- 词汇表
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
vocab = ["<|endoftext|>"] + alphabet.copy()
print(vocab)
>>> ['<|endoftext|>', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's',
't', 'u', 'v', 'w', 'y', 'z', 'Ġ']
根据词汇表将语料库进行进一步的划分,即把每一个单词表示成由多个 token(或 sub-word)组成的 list:
splits = {word: [c for c in word] for word in word_freqs.keys()}
3.2.3 BPE 合并字典和词汇表
遍历搜索,找到出现频率最高的 byte-pair
def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
print(best_pair, max_freq)
>>> ('Ġ', 't') 7
更新词汇表和初始化合并字典,该字典记录了整个合并的过程;
vocab.append("Ġt")
merges = {("Ġ", "t"): "Ġt"}
根据新增合并规则更新语料库
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
splits = merge_pair("Ġ", "t", splits)
print(splits["Ġtrained"])
>>> ['Ġt', 'r', 'a', 'i', 'n', 'e', 'd']
总结一下上述步骤,我们找到了出现频率最高的一组 byte-pair,由此更新了词汇表和语料库。接下来,我们重复上述过程,不断增加词汇表的大小,直到词汇表包含 50 个 token 为止:
vocab_size = 50
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
splits = merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
print(vocab)
>>> ['<|endoftext|>', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o',
'p', 'r', 's', 't', 'u', 'v', 'w', 'y', 'z', 'Ġ', 'Ġt', 'is', 'er', 'Ġa', 'Ġto', 'en', 'Th', 'This', 'ou', 'se',
'Ġtok', 'Ġtoken', 'nd', 'Ġis', 'Ġth', 'Ġthe', 'in', 'Ġab', 'Ġtokeni']
print(merges)
>>> {('Ġ', 't'): 'Ġt', ('i', 's'): 'is', ('e', 'r'): 'er', ('Ġ', 'a'): 'Ġa', ('Ġt', 'o'): 'Ġto', ('e', 'n'): 'en',
('T', 'h'): 'Th', ('Th', 'is'): 'This', ('o', 'u'): 'ou', ('s', 'e'): 'se', ('Ġto', 'k'): 'Ġtok',
('Ġtok', 'en'): 'Ġtoken', ('n', 'd'): 'nd', ('Ġ', 'is'): 'Ġis', ('Ġt', 'h'): 'Ġth', ('Ġth', 'e'): 'Ġthe',
('i', 'n'): 'in', ('Ġa', 'b'): 'Ġab', ('Ġtoken', 'i'): 'Ġtokeni'}
3.2.4 tokenize 文本数据
至此,我们完成了对给定文本数据的 BPE 算法,得到了长度为 50 的词汇表和语料库。那么该如何利用生成的词汇表和语料库对新的文本数据做 tokenization 呢?代码如下:
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
tokenize("This is not a token.")
>>> ['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']
3.2.5. tokenize 的逆(decode)过程
借助前面生成的 merge 字典,我们可以实现 tokenize的逆过程,这通常是在处理模型预测结果的时候需要用到,代码如下:
def detokenize(tokens, merges):
reconstructed_text = ''.join(tokens)
for pair, merge in merges.items():
reconstructed_text = reconstructed_text.replace(merge, pair[0] + pair[1])
return reconstructed_text.replace('Ġ', ' ')
# 假设 merges 是你之前代码中使用的 merges 字典
merges = {('u', 'g'): 'ug', ('u', 'n'): 'un', ('h', 'ug'): 'hug'} # 举例的 merges 字典
tokens = tokenize("This is not a token.") # 假设 tokens 是之前 tokenize 函数的输出结果
original_text = detokenize(tokens, merges)
print(original_text)
>>> This is not a token.