越来越多的互联网公司开始尝试 ClickHouse 存储日志,比如映客、快手、携程、唯品会、石墨文档,但是 ClickHouse 存储日志缺少对应的可视化方案,石墨文档开源了 ClickVisual 用于解决这个问题。笔者初步尝试了一下 ClickVisual,一点小小的实践经验,与各位分享。
简介
ClickVisual 官方宣扬的核心功能是:轻量级日志查询、分析、报警可视化平台。报警这块有更好的方案,我这里主要尝试一下接入日志、存储、查询日志的整个流程。ClickVisual 的相关资料地址:
- 文档:https://clickvisual.net/
- 代码:https://github.com/clickvisual/clickvisual
架构
ClickVisual 只是一个 web 端,查询日志并展示,并不参与日志流的处理,日志流主要是通过 LogAgent、Kafka、ClickHouse 来协同处理,ClickVisual 主要是对 ClickHouse 的表结构做一些调整,来控制 ClickHouse 对日志的处理过程。整个数据流如下:
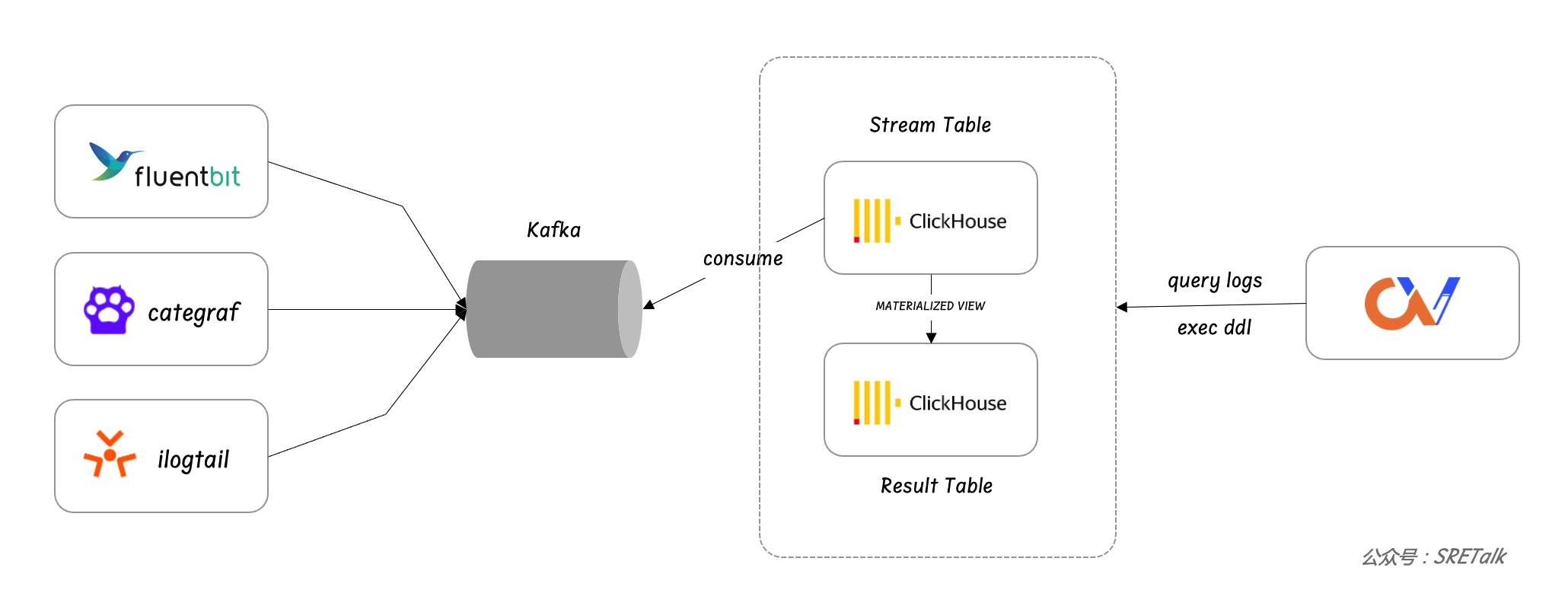
ClickVisual 不关心采集,用什么 agent 都行,只是对进入 Kafka 中的日志格式有要求,要求日志中包括时间字段和日志原文字段。ClickVisual 官网有 fluentbit、ilogtail、loggie 的相关文档,fluentbit 的文档最为详细,看来石墨的朋友内部主要是使用 fluentbit 做采集器。后面我会使用 categraf 做数据采集,categraf 中的日志采集逻辑是 fork 自 datadog-agent,比较稳定可靠。不过 categraf 没有日志清洗能力,如果想对日志格式做清洗,需要引入 logstash 或者 vector。我这里重点想尝试 ClickVisual,所以采集侧就简单搞,使用 categraf 采集 json 格式的日志,然后直接进入 Kafka。
通常,不同的 log stream 进入不同的 Kafka topic,每个 Kafka topic 对应 ClickVisual 里的一个日志库,日志库通常包含两个 ClickHouse Table + 一个物化视图,一个 Table 是 Kafka 引擎类型的 Table,用于消费 Kafka 中的原始日志,然后通过物化视图流式处理原始日志,做一些数据 ETL 之后写入日志结果 Table。比如日志原文可能是 json 格式,通过物化视图把 json 日志原文里的某个字段提取出来,作为日志结果 Table 的一个一等公民字段,可以提升查询筛选性能。
安装
日志的处理流比指标要复杂,涉及的组件比较多,这里我会安装 Kafka 用于日志传输,Kafka 依赖 Zookeeper,Kafka 的可视化使用 Kowl,日志采集使用 Categraf,日志存储使用 ClickHouse,日志可视化使用 ClickVisual,ClickVisual 依赖 MySQL 和 Redis,所以,总共需要安装 8 个组件,我会尽可能使用二进制安装,方便摸清个中原理。
Kafka
Kafka 最新的版本是 3.6.0,直接下载最新版本安装,下载的包里包含 Zookeeper,所以 Zookeeper 不需要单独下载包。当然,Kafka、Zookeeper 都是依赖 JDK,JDK 请列位自行安装和配置。
- Kafka 下载地址:https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
下载之后解压缩,修改一下 config/zookeeper.properties,调整 dataDir 配置,不要放 /tmp 目录。然后启动 Zookeeper:
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties然后修改 Kafka 的配置:config/server.properties,修改 log.dirs,也是更换一下目录,不要使用 /tmp。然后启动 Kafka:
nohup bin/kafka-server-start.sh config/server.properties &> kafka.stdout &请自行检查 Zookeeper 和 Kafka 是否启动成功,可以使用 jps 命令查看进程,也可以使用 netstat -tunlp 查看端口。
[root@VM-0-33-debian:~/tarball/kafka_2.13-3.6.0# jps
1148293 Jps
606735 QuorumPeerMain
608066 KafkaKafka 数据查看使用 Kowl,不过 Kowl 没有找到二进制,官网建议使用容器,但是我的 Kafka 和 Zookeeper 都没有用容器,所以 Kowl 使用容器安装,但是要使用 host network,命令如下:
docker run --network=host -d -e KAFKA_BROKERS=localhost:9092 quay.io/cloudhut/kowl:masterkowl 如果启动成功,会监听在 8080 端口,页面长这样:
ClickHouse
ClickHouse 的安装比较简单,官方提供安装脚本,直接下载执行即可,curl 命令结束之后会拿到一个 clickhouse 二进制,然后执行 ./clickhouse install 就可以安装了,安装的时候会提示设置密码,我这里测试,设置为 1234。
curl https://clickhouse.com/ | sh
./clickhouse install
clickhouse startClickVisual
ClickVisual 的安装依赖 MySQL 和 Redis,这俩太常见了大家自行搞定。ClickVisual 我也直接体验最新版本,v1.0.0-rc9,下载之后解压缩,看一下 help 信息:
mkdir clickvisual && cd clickvisual
wget https://github.com/clickvisual/clickvisual/releases/download/v1.0.0-rc9/clickvisual-v1.0.0-rc9-linux-amd64.tar.gz
tar zxvf clickvisual-v1.0.0-rc9-linux-amd64.tar.gz
[root@VM-0-33-debian:~/tarball/clickvisual# ./clickvisual --help
Usage:
clickvisual [command]
Available Commands:
agent 启动 clickvisual agent 服务端
command 启动 clickvisual 命令行
completion Generate the autocompletion script for the specified shell
help Help about any command
server 启动 clickvisual server 服务端
Flags:
-c, --config string 指定配置文件,默认 config/default.toml (default "config/default.toml")
-h, --help help for clickvisual
Use "clickvisual [command] --help" for more information about a command.从命令中可以看出,启动 ClickVisual 应该是使用 server 参数,通过 -c 传入配置文件,默认配置文件是 config/default.toml,我们要调整这个配置文件中的 MySQL 和 Redis 的认证信息,我的环境配置如下:
[redis]
debug = true
addr = "127.0.0.1:6379"
writeTimeout = "3s"
password = ""
[mysql]
debug = true
# database DSN
dsn = "root:1234@tcp(127.0.0.1:3307)/clickvisual?charset=utf8mb4&collation=utf8mb4_general_ci&parseTime=True&loc=Local&readTimeout=1s&timeout=1s&writeTimeout=3s"
# log level
level = "debug"
# maximum number of connections in the idle connection pool for database
maxIdleConns = 5
# maximum number of open connections for database
maxOpenConns = 10
# maximum amount of time a connection
connMaxLifetime = "300s"OK,启动 ClickVisual:
nohup ./clickvisual server &>stdout.log &ClickVisual 启动之后监听在 19011 端口,可以检查这个端口是否存活:
ss -tlnp|grep 19011ClickVisual 解压缩之后,里边有个 sql 脚本,位于 scripts/migration/database.sql,需要把这个 sql 导入 MySQL:
mysql -uroot -p < scripts/migration/database.sql之后就可以浏览器访问 19011 了,ClickVisual 会提示你进行表结构初始化,初始账号密码是 clickvisual/clickvisual。
Categraf
最后一个要安装的组件是日志采集器,我这里使用 categraf,下载地址如下:
- 下载:https://flashcat.cloud/download/categraf/
- 代码:https://github.com/flashcatcloud/categraf
这里选择 v0.3.38 版本,下载解压缩,重点需要 categraf 二进制以及 conf 目录下的 logs.toml,其他所有 input. 打头的配置都是指标采集插件,全部删除,另外也删除 conf 目录下的 traces.yaml,搞的干净点。然后修改两个配置文件。
1、修改 config.toml,关闭 heartbeat:
[heartbeat]
enable = falseCategraf 和 Nightingale 配合工作,主要处理指标场景,我们现在不测试指标,只是测试日志采集,所以不需要 Nightingale,关闭 Heartbeat。
2、修改 logs.toml,要给出要采集的日志路径以及要发往的 Kafka 地址。
[logs]
api_key = "x"
enable = true
send_to = "127.0.0.1:9092"
send_type = "kafka"
topic = "categraf"
use_compress = false
send_with_tls = false
batch_wait = 5
run_path = "/opt/categraf/run"
open_files_limit = 100
scan_period = 10
frame_size = 9000
collect_container_all = false
[[logs.items]]
type = "file"
path = "/root/works/catpaw/stdout.log"
source = "app"
service = "catpaw"
topic = "catpaw"
accuracy = "s"其中 send_to 字段是配置了 Kafka 的地址,send_type 配置为 kafka,collect_container_all 设置为 false 避免一些非 K8s 环境下的报错日志,[[logs.items]] 是双中括号,在 toml 里表示数组,即可以配置多个 [[logs.items]] 段,这里我采集了 catpaw 的 stdout.log,source、service 都是标签,topic 是日志发往 Kafka 的 Topic。
stdout.log 的日志内容,给大家看一行例子:
{"level":"error","ts":"2023-11-01T16:57:15+08:00","caller":"http/http.go:236","msg":"failed to send http request","error":"Get \"http://a.cn\": dial tcp: lookup a.cn on 183.60.83.19:53: no such host","plugin":"http","target":"http://a.cn"}这是一个 json 格式的日志,不需要额外的数据清洗了,直接采集即可。推荐大家写的程序都打印 json 格式的日志,对于日志采集非常方便。
启动 categraf:
nohup ./categraf &> categraf.log &通过 ps 查看 categraf 进程是否启动成功,查看 categraf.log 是否有异常日志,如果一切正常,咱们就可以去 Kowl 查看日志了。
查看 Kafka 中的日志
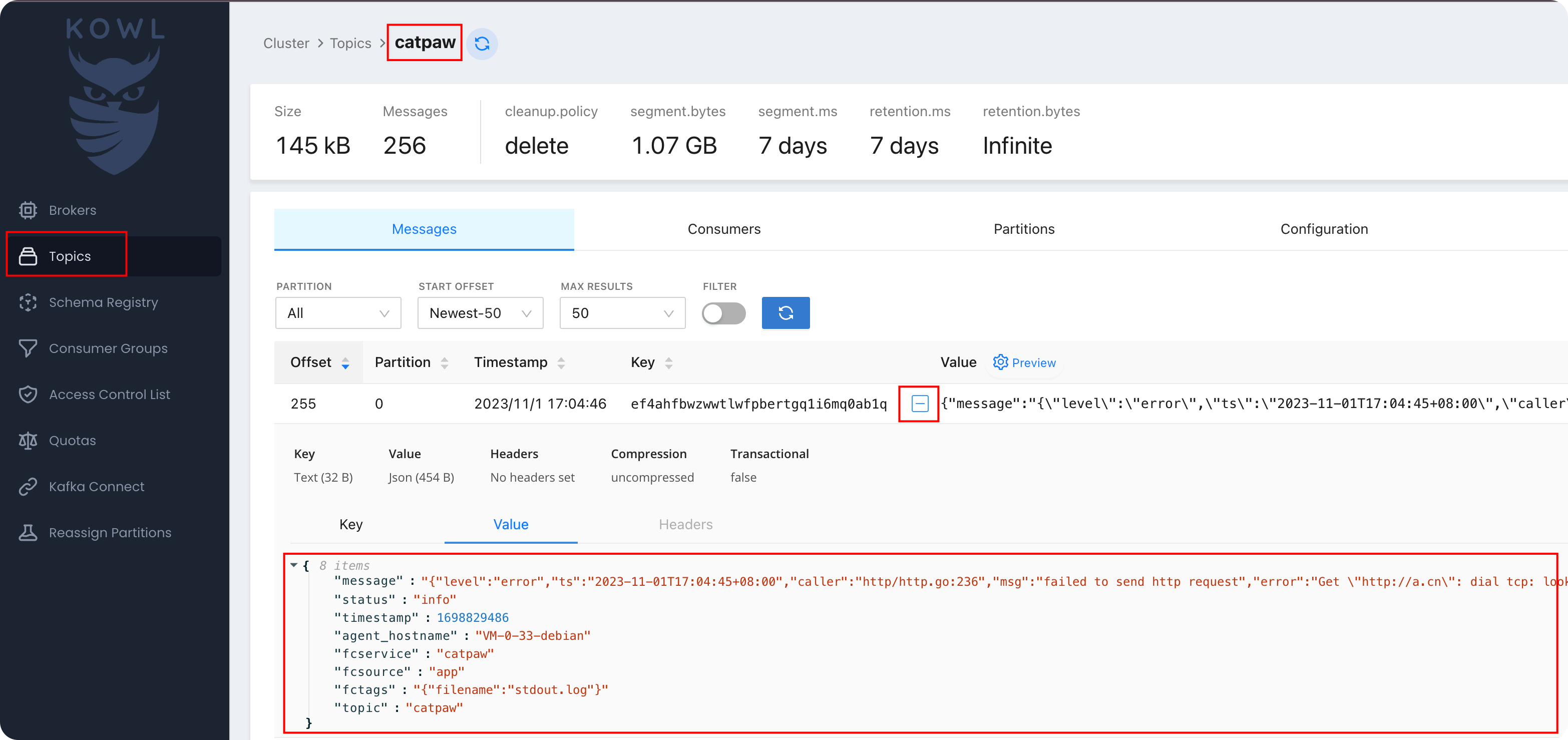
其中 message 字段是日志原文,timestamp 是采集日志时的时间戳,有这俩字段,ClickVisual 就可以处理了。其他字段是 categraf 自动添加的,比如 source、service、topic,即便没有这些额外的字段,也不影响 ClickVisual 的使用。
在 ClickVisual 配置日志库
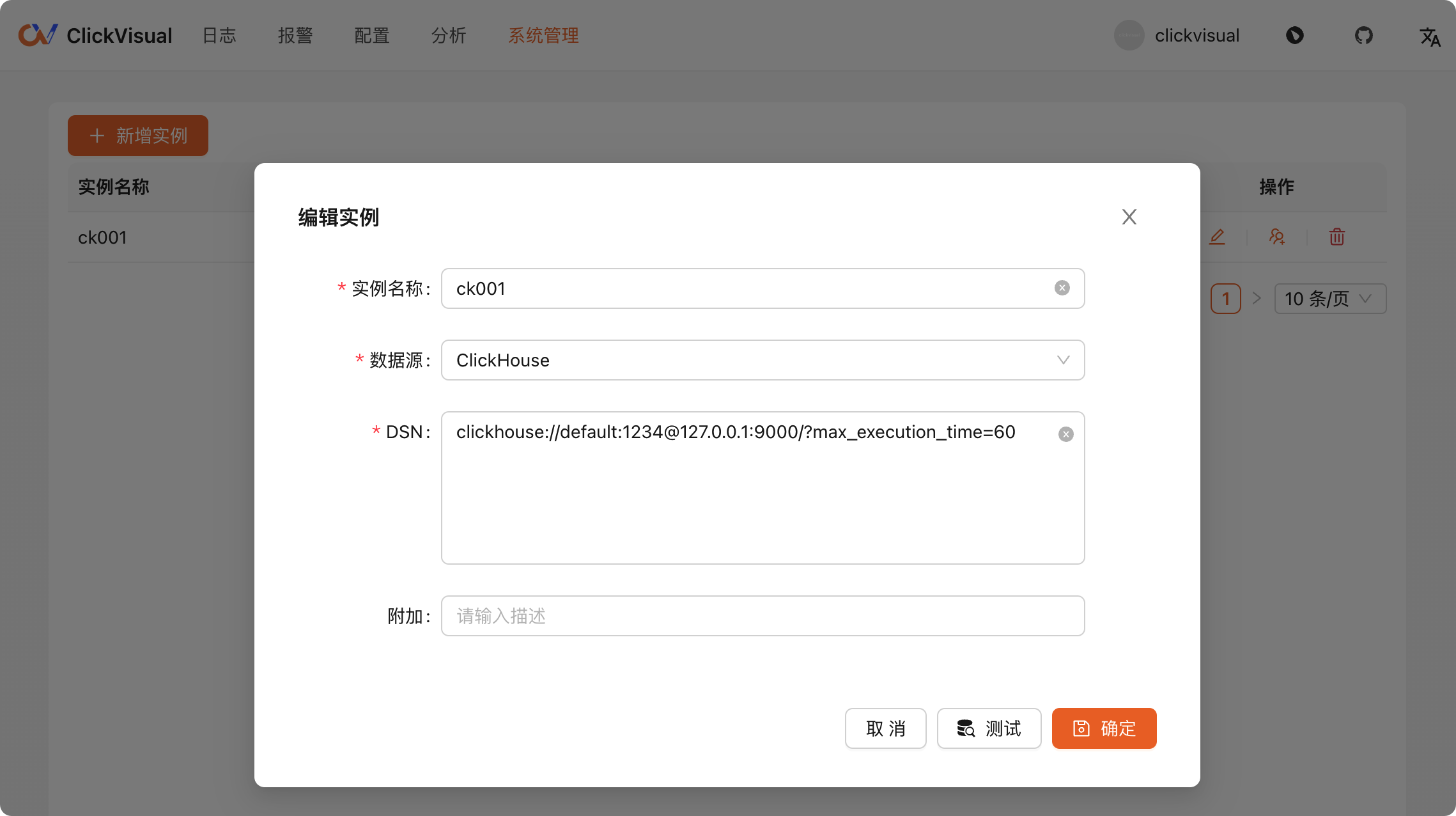
终于到了最后一步了,到 ClickVisual 配置日志库。首先去系统管理里新增 ClickHouse 实例:

我之前创建过,现在点击编辑给大家看一下内容:
进入日志菜单,可以看到刚才添加的 ClickHouse 实例,右键添加数据库(一个 ClickHouse 实例里可以创建多个数据库,跟 MySQL 一样,我这里直接取名 db01,你随意 ):
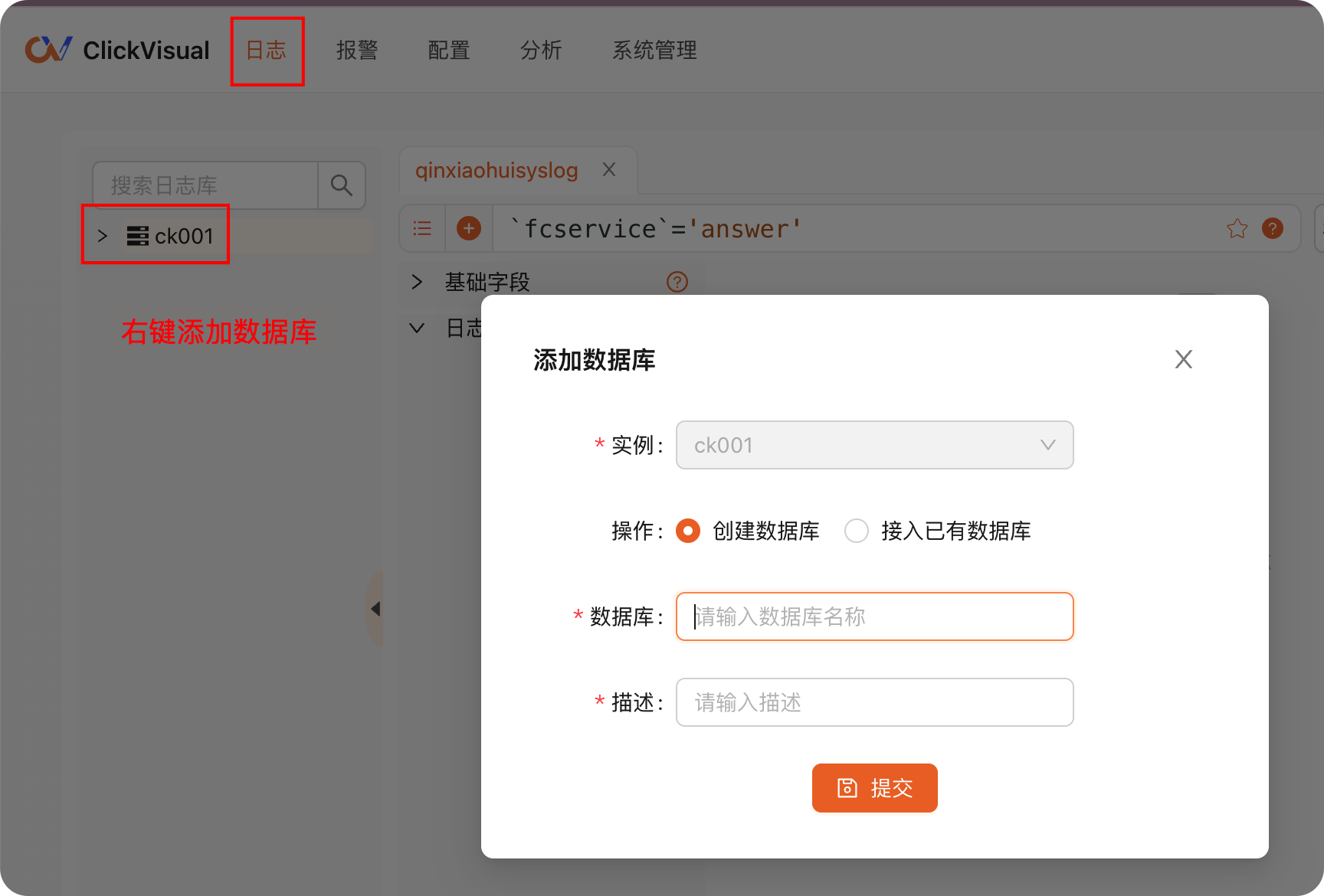
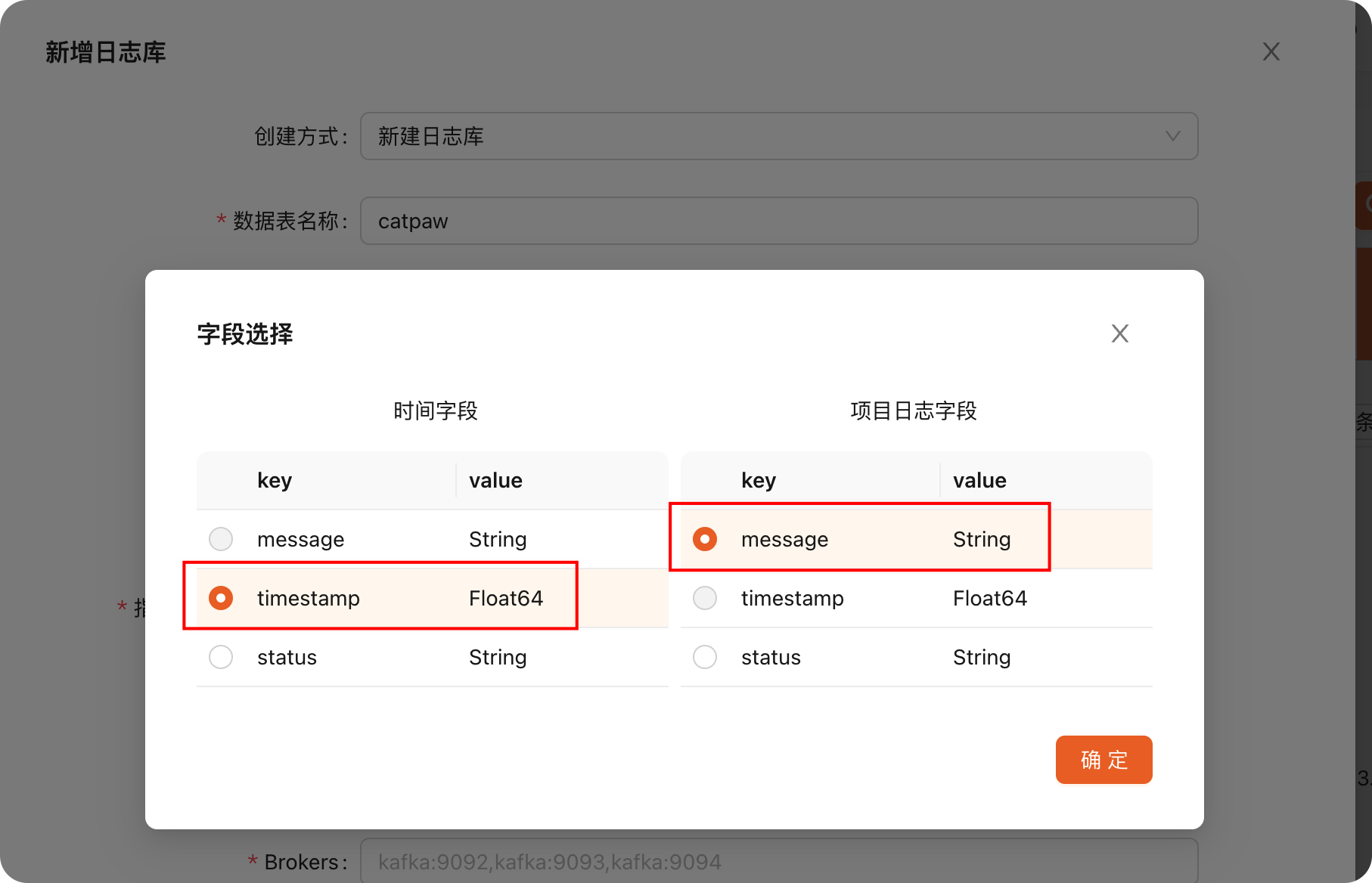
之后在 db01 上右键,新增日志库。数据表通常填成 topic 名字就行,其实就是 log stream 的名字。source 字段很关键,ClickVisual 会根据 source 来提取日志,Kowl 的截图中大家看到了,我的日志里有好几个字段:message、status、timestamp、agent_hostname、fcservice、fcsource 等,但是我在 source 里故意少填几个字段,填入如下内容:
{
"message": "x",
"timestamp": 1698829486,
"status": "y"
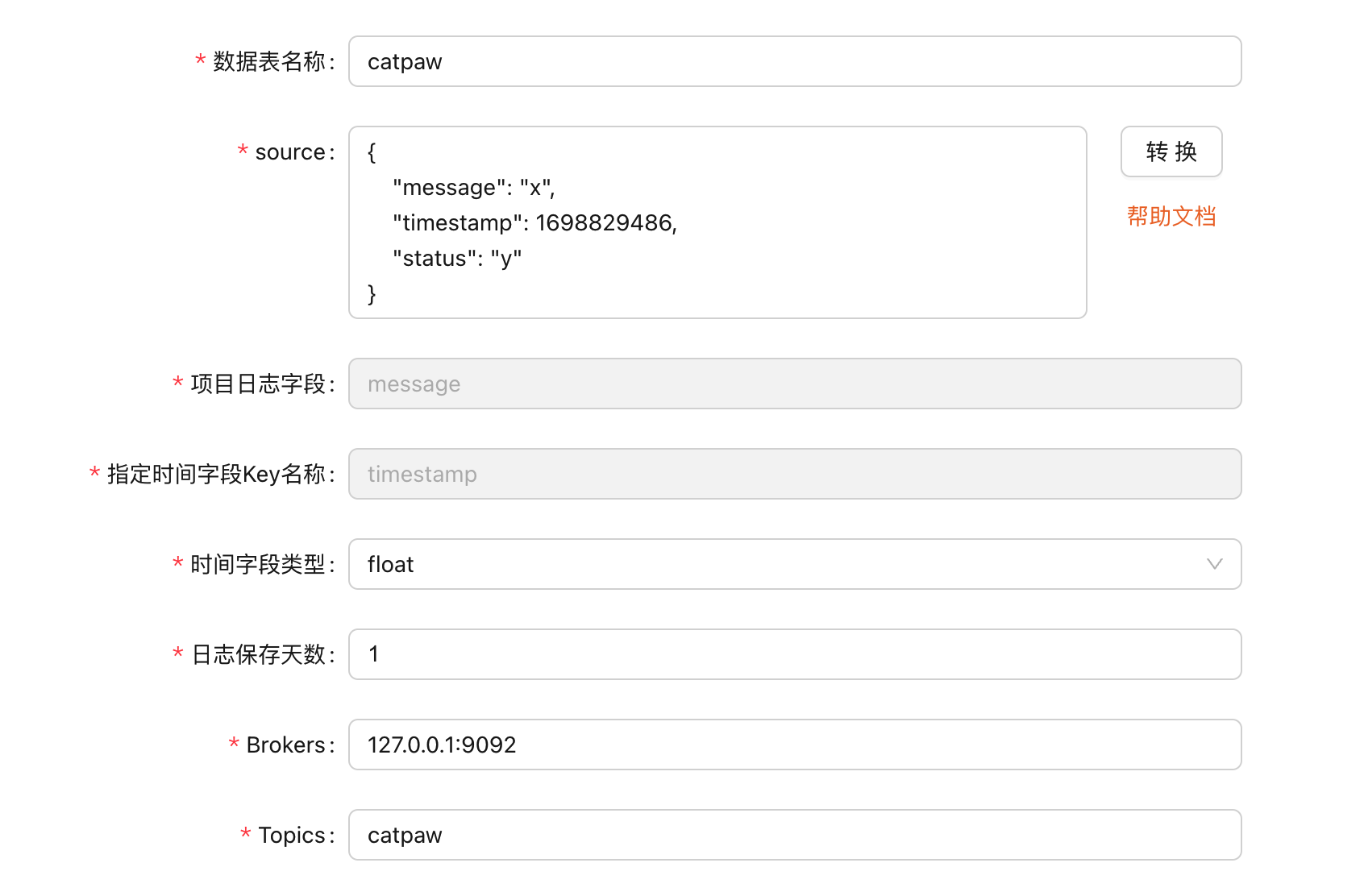
}source 里填 json 结构,不用填真实内容,只要填一个假数据结构,ClickVisual 能推断出各个字段的类型就行,我呢,就填了上面三个字段。点击转换,选择时间字段和日志详情字段:
确定之后,ClickVisual 自动填充了相关字段,然后,我们补齐剩下的 Kafka 信息即可:
确定之后,稍等几秒钟,就可以看到数据了,我的截图如下:
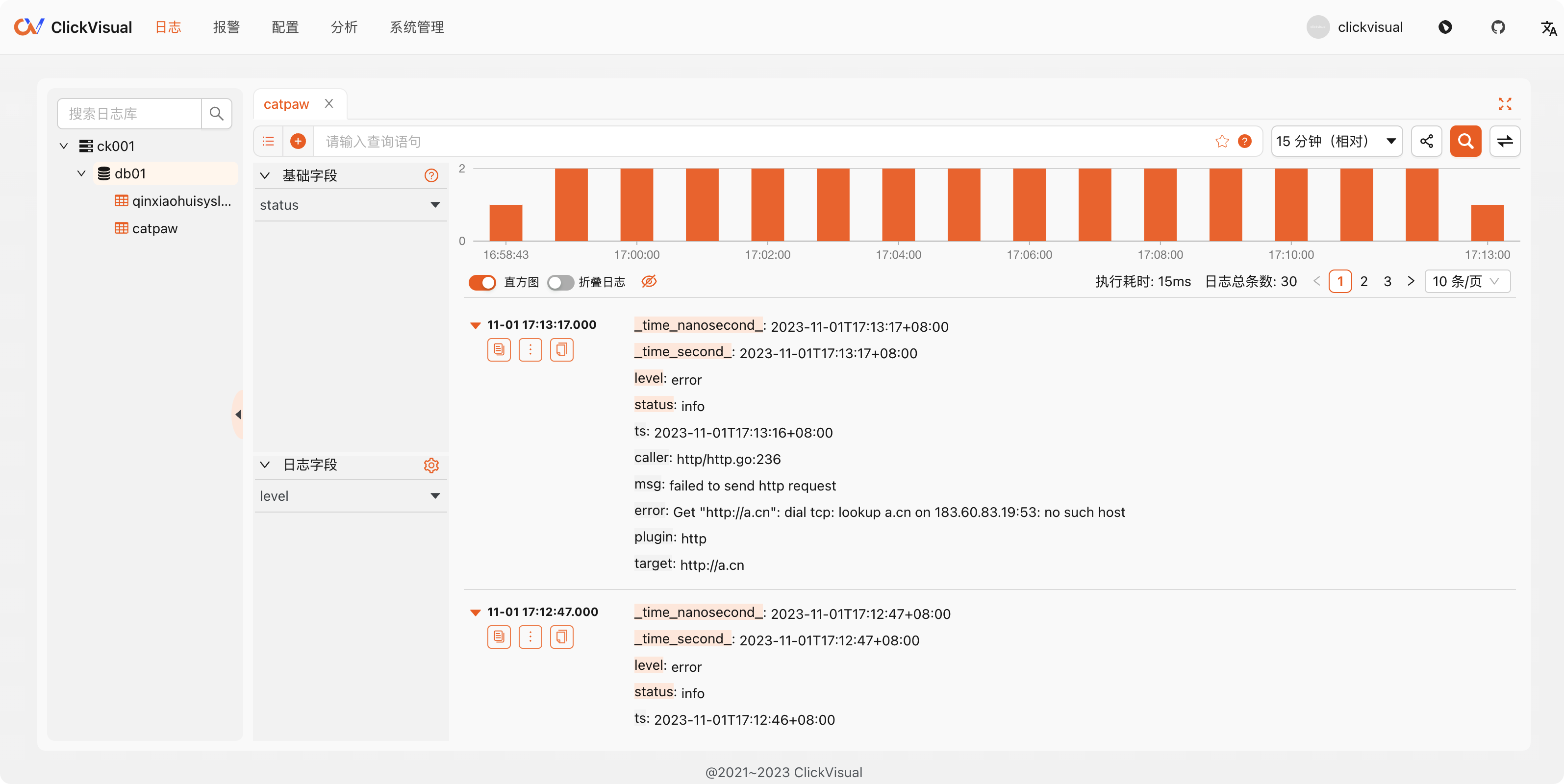
其实,刚开始日志字段下面是空的,右侧日志详情里的 level 字段也没有背景色。基础字段里有 status,显然,因为配置日志库的时候,source 样例只给了 message、timestamp、status 三个字段,所以,ClickHouse 只拿到一个基本字段 status,如果当时要是把 fcservice、fcsource 也作为 source 样例写上,基础字段里大概率就会有了。
查看 ClickHouse 中的库表
clickhouse client 进入 ClickHouse 客户端,可以看到相关库表:
localhost.localdomain :) use db01
USE db01
Query id: a96ccd16-990c-4c8a-9d07-7bba0d0c4425
Ok.
0 rows in set. Elapsed: 0.001 sec.
localhost.localdomain :) show tables;
SHOW TABLES
Query id: 3b0849f7-cd05-481e-b786-5c8c1870caaf
┌─name────────────────────┐
│ catpaw │
│ catpaw_stream │
│ catpaw_view │
│ qinxiaohuisyslog │
│ qinxiaohuisyslog_stream │
│ qinxiaohuisyslog_view │
└─────────────────────────┘
6 rows in set. Elapsed: 0.001 sec.catpaw 相关的三个表就是我刚才一通操作产生的,qinxiaohuisyslog 相关的三个表不用关注,那是之前测试的时候生成的。看一下 stream 表的表结构:
localhost.localdomain :) show create table catpaw_stream\G
SHOW CREATE TABLE catpaw_stream
Query id: 1c75d947-d122-48cf-ad0e-e4f4049795b5
Row 1:
──────
statement: CREATE TABLE db01.catpaw_stream
(
`status` String,
`timestamp` Float64,
`message` String CODEC(ZSTD(1))
)
ENGINE = Kafka
SETTINGS kafka_broker_list = '127.0.0.1:9092', kafka_topic_list = 'catpaw', kafka_group_name = 'db01_catpaw', kafka_format = 'JSONEachRow', kafka_num_consumers = 1, kafka_skip_broken_messages = 0
1 row in set. Elapsed: 0.001 sec.这是一个引擎类型为 Kafka 的 Table,再看一下 catpaw_view:
localhost.localdomain :) show create table catpaw_view\G
SHOW CREATE TABLE catpaw_view
Query id: 99c22d6a-a617-43fc-9963-3575778b0623
Row 1:
──────
statement: CREATE MATERIALIZED VIEW db01.catpaw_view TO db01.catpaw
(
`status` String,
`_time_second_` DateTime,
`_time_nanosecond_` DateTime64(9),
`_raw_log_` String
) AS
SELECT
status,
toDateTime(toInt64(timestamp)) AS _time_second_,
fromUnixTimestamp64Nano(toInt64(timestamp * 1000000000)) AS _time_nanosecond_,
message AS _raw_log_
FROM db01.catpaw_stream
WHERE 1 = 1
1 row in set. Elapsed: 0.001 sec.这是一个 ClickHouse 物化视图,查询 stream 表的数据,塞入日志结果表 catpaw,我们看一下日志结果表 catpaw 的表结构:
localhost.localdomain :) show create table catpaw\G
SHOW CREATE TABLE catpaw
Query id: d06e11b9-4b5a-4594-97af-877435b93238
Row 1:
──────
statement: CREATE TABLE db01.catpaw
(
`status` String,
`_time_second_` DateTime,
`_time_nanosecond_` DateTime64(9),
`_raw_log_` String CODEC(ZSTD(1))
INDEX idx_raw_log _raw_log_ TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(_time_second_)
ORDER BY _time_second_
TTL toDateTime(_time_second_) + toIntervalDay(1)
SETTINGS index_granularity = 8192
1 row in set. Elapsed: 0.001 sec.如果根据 status 字段来筛选,速度是比较快的,但是如果想根据 _raw_log_ 里的信息来筛选,比如根据 level 字段来筛选,level 是日志原文 json 里的一个字段,不是一等公民字段,速度就慢了,ClickVisual 官方建议,这种情况,应该把日志原文里的过滤字段单独出来作为一个字段,点击日志字段右侧的小齿轮:
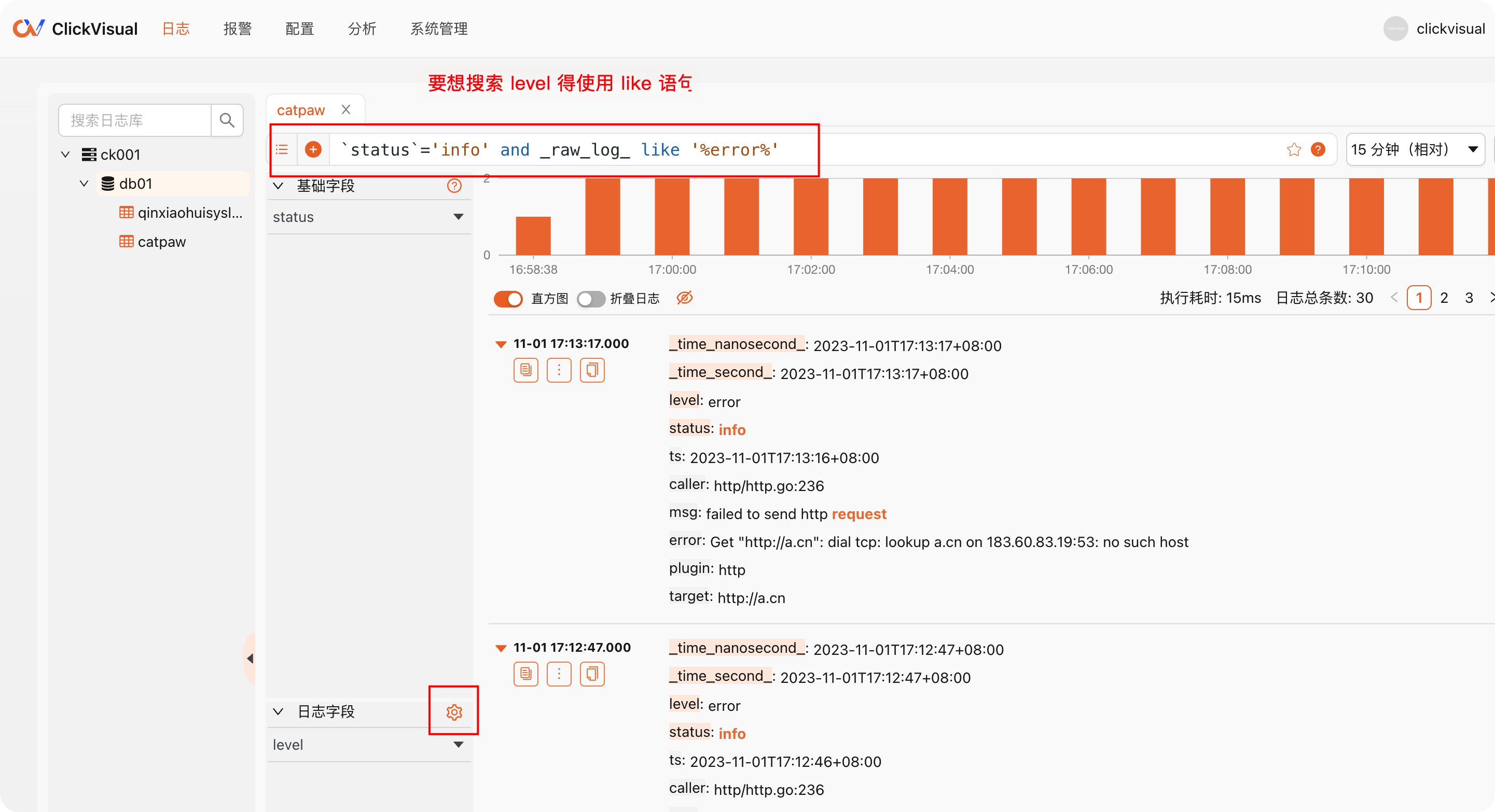
可以把日志原文那个 json 里的 level 字段单独提取出来,配置如下
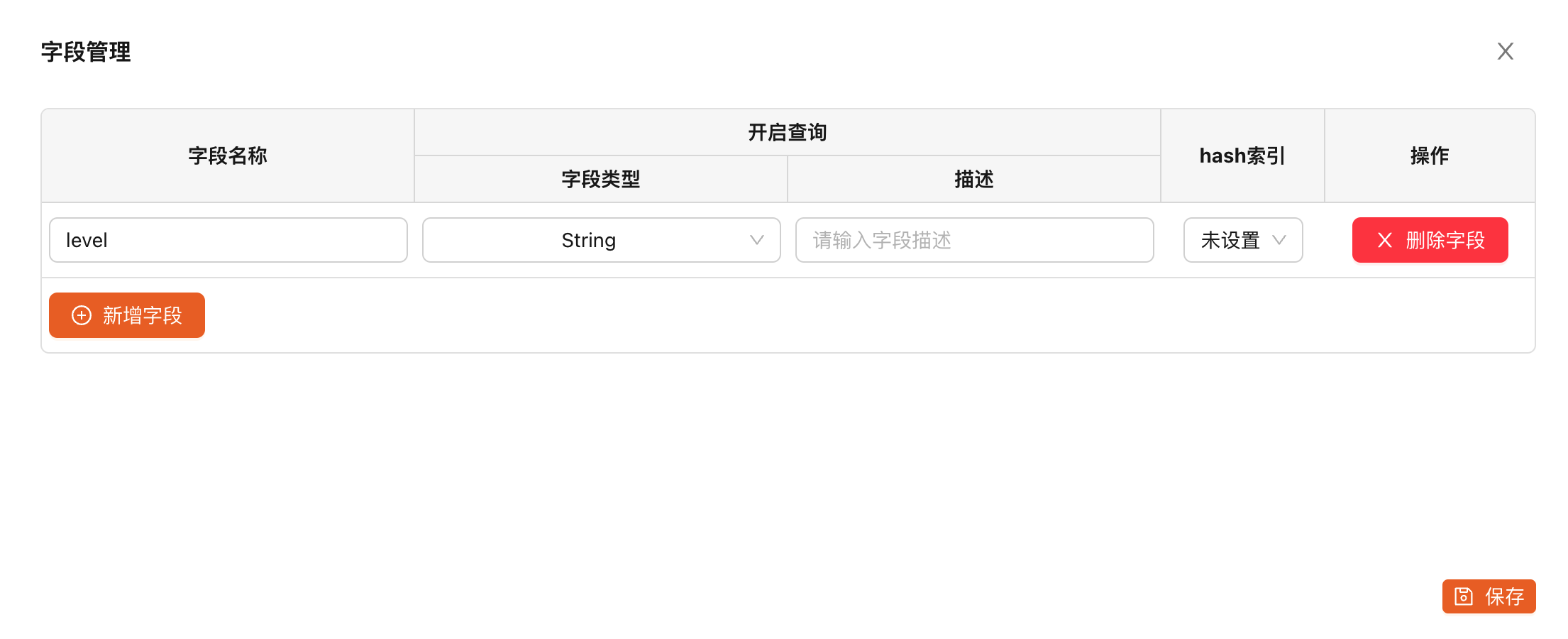
如上操作之后,重新查看 catpaw 和 catpaw_view 的表结构:
localhost.localdomain :) show create table catpaw\G
SHOW CREATE TABLE catpaw
Query id: d06e11b9-4b5a-4594-97af-877435b93238
Row 1:
──────
statement: CREATE TABLE db01.catpaw
(
`status` String,
`_time_second_` DateTime,
`_time_nanosecond_` DateTime64(9),
`_raw_log_` String CODEC(ZSTD(1)),
`level` Nullable(String),
INDEX idx_raw_log _raw_log_ TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(_time_second_)
ORDER BY _time_second_
TTL toDateTime(_time_second_) + toIntervalDay(1)
SETTINGS index_granularity = 8192
1 row in set. Elapsed: 0.001 sec.
localhost.localdomain :) show create table catpaw_view\G
SHOW CREATE TABLE catpaw_view
Query id: ebfebeb7-d8f5-4427-b3ba-33c0d07d24b1
Row 1:
──────
statement: CREATE MATERIALIZED VIEW db01.catpaw_view TO db01.catpaw
(
`status` String,
`_time_second_` DateTime,
`_time_nanosecond_` DateTime64(9),
`_raw_log_` String,
`level` Nullable(String)
) AS
SELECT
status,
toDateTime(toInt64(timestamp)) AS _time_second_,
fromUnixTimestamp64Nano(toInt64(timestamp * 1000000000)) AS _time_nanosecond_,
message AS _raw_log_,
toNullable(toString(replaceAll(JSONExtractRaw(message, 'level'), '"', ''))) AS level
FROM db01.catpaw_stream
WHERE 1 = 1
1 row in set. Elapsed: 0.001 sec.雾化视图 catpaw_view 里,增加了对 level 字段的提取,日志结果表 catpaw 里也新增了一个 level 字段。看来 ClickVisual 是执行了一些 alter table 的语句。之后就可以这么查了(不用像之前使用 like 语句):

总结
ClickVisual 的整体思路设计挺巧妙的,不过业界使用 ClickHouse 存储日志,大都是使用的双 array 存储动态字段。你们公司是如何做的呢?有在生产环境使用 ClickVisual 么?感觉如何?欢迎大家留言交流。
标签:log,catpaw,clickvisual,ClickVisual,Kafka,日志,ClickHouse From: https://www.cnblogs.com/ulricqin/p/17867075.html作者:秦晓辉,Open-Falcon、Nightingale、Categraf 等开源项目创始研发人员,极客时间专栏《运维监控系统实战笔记》作者,目前在创业,提供可观测性产品,微信 picobyte,欢迎加好友交流,加好友请备注公司。