数字时代,政企业务上云已成为大势所趋。虽然上云可为政企用户带来业务应用部署调度更加灵活、资源利用率更高的优点,但因云平台建设处于不同的阶段,且运转过程中包含大量的、不同类型的业务系统和应用场景,在整体云平台的建设中往往会产生如公有云、私有云、信创云、非信创云等不同架构、不同模式、不同厂商的云平台。多云并存模式是应对IT多元化的必然选择,然后随着其广泛应用,集中、统一的多云纳管、混合云运维愈发凸显其重要性。
第1章 多云纳管、混合云运维的痛点
随着企业业务规模扩大和复杂化及云计算、大数据等技术不断发展,政企用户希望通过上云加速其数字化转型,而在基础设施上云后,如何掌握平台部署架构?管理云上云下资源?掌握具体资源使用情况?如何进行日常运维巡检?等等,都是用户将面临的难题。
面临的具体难题如下:
- 公有云、私有云、虚拟化、容器云、信创云、非信创云等不同架构、不同模式、不同厂商的系统混合使用,具备极大的分散性和多样性,管理难度大。
- 不同品牌云平台的部署、升级、维护等各平台自成体系,操作差异大,需要运维人员全面了解,占用大量人力和时间。
- 如软件部署、健康检查、备份、巡检等大量重复、繁琐、耗时的日常运维工作导致运维效率降低。
- 难以快速定位故障根因,排障困难,且日常运维工作多处于“人盯机”“救火”状态,被动地处理各种故障,效率低下。
- 云上业务需求增多,其中大量的基础设施配置变更工作以手工为主,效率低、风险大。
- 云上云下资产数量巨大,种类繁多,仅靠人工管理难以管理且极易出错,资产的采购、调拨、报废等管理效率低,难审计。
第2章 一网多云下的智能运维方案
在数字化转型、云原生的趋势下,不同架构、不同模式、不同厂商的云平台已存在且将长期存在于政企的IT系统建设中。在复杂多云混合的环境下,用户面临资源整合统管的实际问题,严重影响业务敏捷运行和数字化健康持续发展。
北京智和信通一网多云智能运维方案,实现传统数据中心、公有云、私有云、虚拟化等一体集中运维,自动化配置,对云上云下资源统一纳管,云部署架构可视化展现,快速定位异常资源,将周期性、重复性的日常运维巡检工作,转化为依托平台的自动化策略,以配置为核心、以服务为驱动,提升IT部门运维洞察力,帮助用户更快速、更便捷、更安全地使用云。
 智和信通混合云智能运维监控架构
智和信通混合云智能运维监控架构
2.1. 混合多云、异构纳管
方案对复杂的多云异构环境、云上云下资源、信创云等进行全面管理,实现云下服务器、网络设备、安全设备、机房、机柜、专线、配件等设施,云上各类云服务器、云磁盘等云产品以及各类IP、NAT、DNS等资源的真正一站式运维,并支持对纳管资源的快速扩展。自动监测基础设施及资源,其中包括云、混合云、容器、虚拟主机、网络、服务器、存储等。对进程、资源利用率、网络使用量、性能、日志、事件进行全面监测。
方案基于对私有云中的系统资源、租户资源的监控,实现云资源的生命周期管理,通过可视化运维编排,进行云管理策略预设配置、云策略批量/定时执行、智能监控巡检。支持多云纳管、持续监控,对云的容量进行智能化分析,为容量优化提供依据。

2.2. 全量观测,统一运维
通过北京智和信通的混合云智能运维方案实现对多种类型、不同厂商的云平台进行可视纳管,统一运维,通过多云管理,梳理整体IT资源关联关系,构建云网络统一视图,实现网络实现云资源、网络设备、链接关系、IP等实时可视展示、动态数据更新、快速定位故障。

智和云上云下混合云架构网络拓扑示意图
2.3. 虚拟资源统一管理
方案对虚拟化环境下的虚拟机、宿主机等进行全方位运维监控,全面支持Exi5、KVM、Xen、Hyper-v等,监测指标涵盖物理机内部虚拟化设备的电源、操作系统、CPU、内存、磁盘等,最大化利用计算资源,保障虚拟化平台运行稳定。
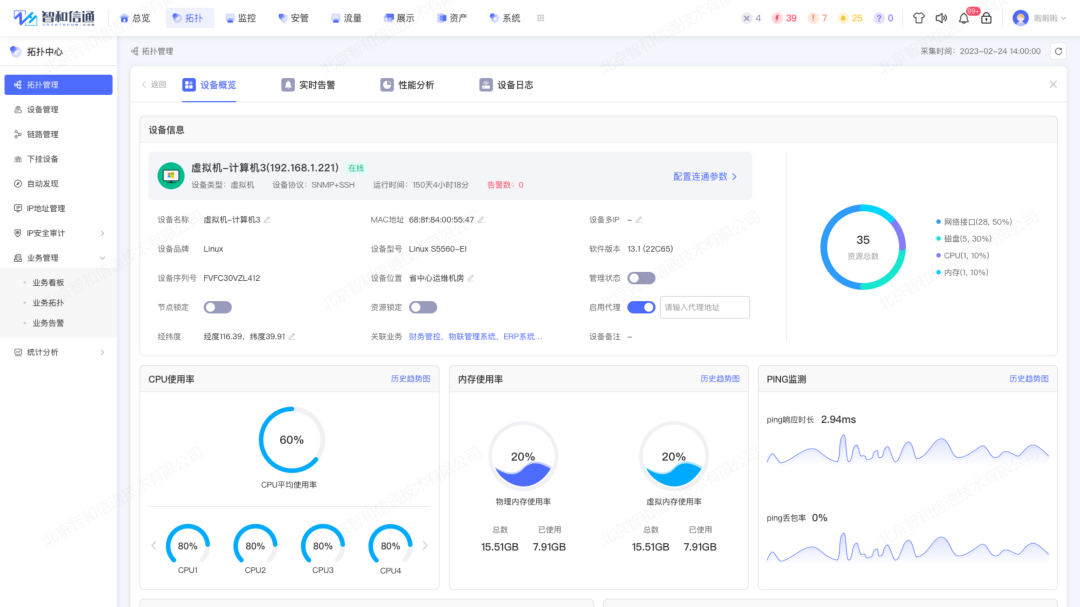
2.4. 云网络运行态势感知
实时监测并感知混合云网络性能相关情况,全面覆盖物理环境、虚假环境、云环境,采集设备资源、应用、服务等性能信息,通过智能分析,多维度处理、分析、展示网络基础设施性能状态,实现全网态势的“可观、可管、可控”。
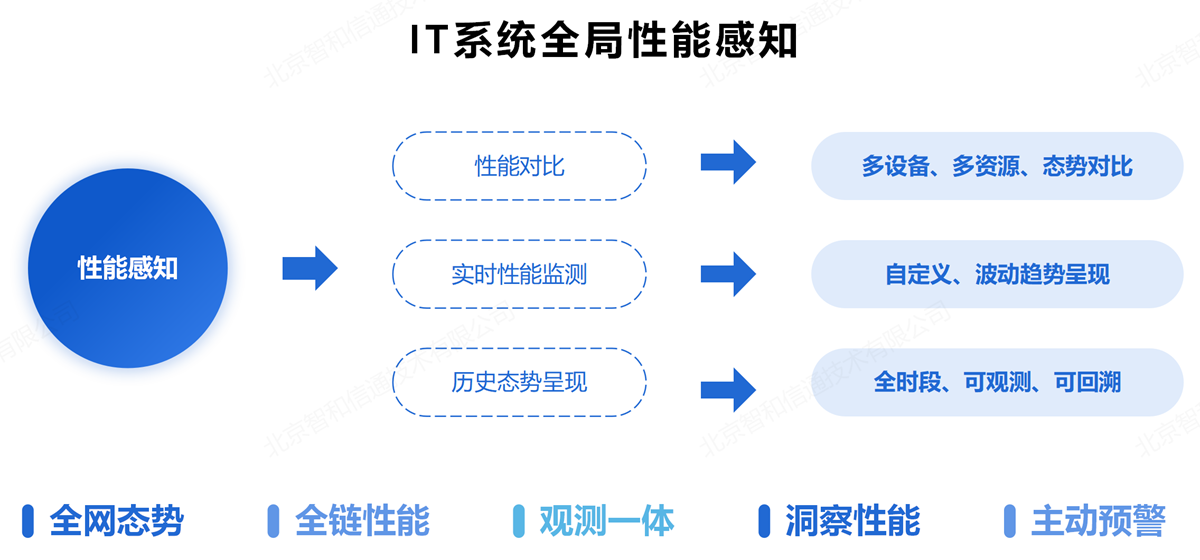
对智慧云上云下混合云架构络环境中的IT基础设施进行实时监控,获取网络最新运行态势,监控设备类型覆盖:公有云、私有云、信创云等各类云平台,服务器、交换机、路由器等网络设备,防火墙、堡垒机等安全设备,数据库,中间件,虚拟机,摄像头以及其他联网的IT设施。
2.5. 统一故障态势感知
方案通过统一的故障管理中心,统一检测、统一管理、统一分析云上云下混合云架构中各种事件日志、设备故障、网络异常、业务指标异常、流量异常等信息,快速感知网络故障。基于故障模型和AI算法分析故障原因,分析、压缩、并归关联故障信息,降低故障风暴,秒级定位故障位置,主动出击快速排障,故障处置全流程展示。

帮助运维人员主动发现85%的潜在网络问题,并识别根因和主动修复,充分利用积累的有效定障、排障经验,打通告警中心、自动运维中心、工单中心等关联数据,实现从接收告警到故障恢复的全生命周期闭环管理。
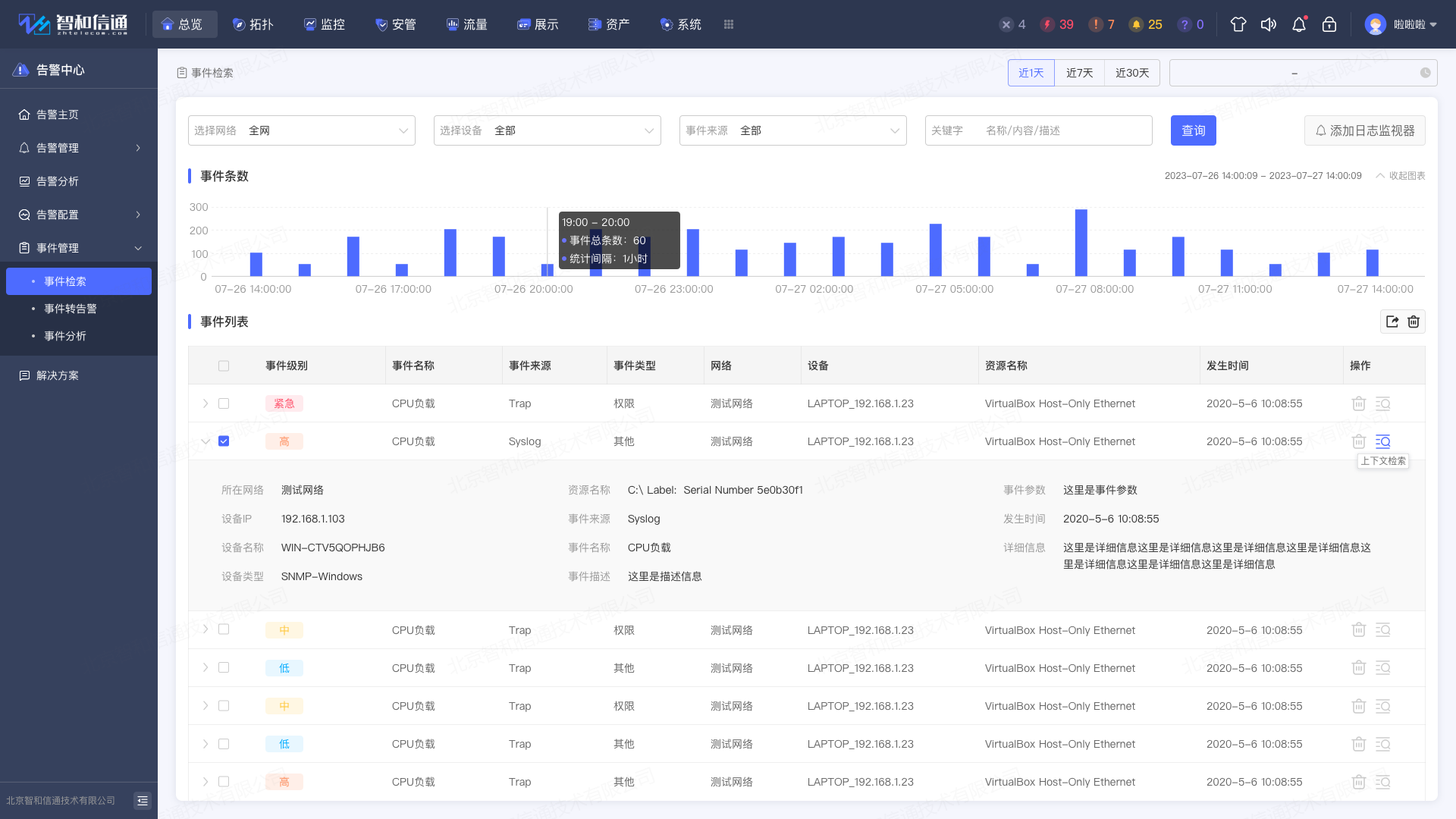
2.6. 日志与事件管理
将事件和告警分离管理,接收设备/服务器主动发送的消息,集中处理后,及时地通知用户,并可以通过集中的管理界面进行管理。接收设备/服务器主动发送的消息,极大地提高了管理的主动性,通过统一界面集中管理事件,降低了管理的难度。
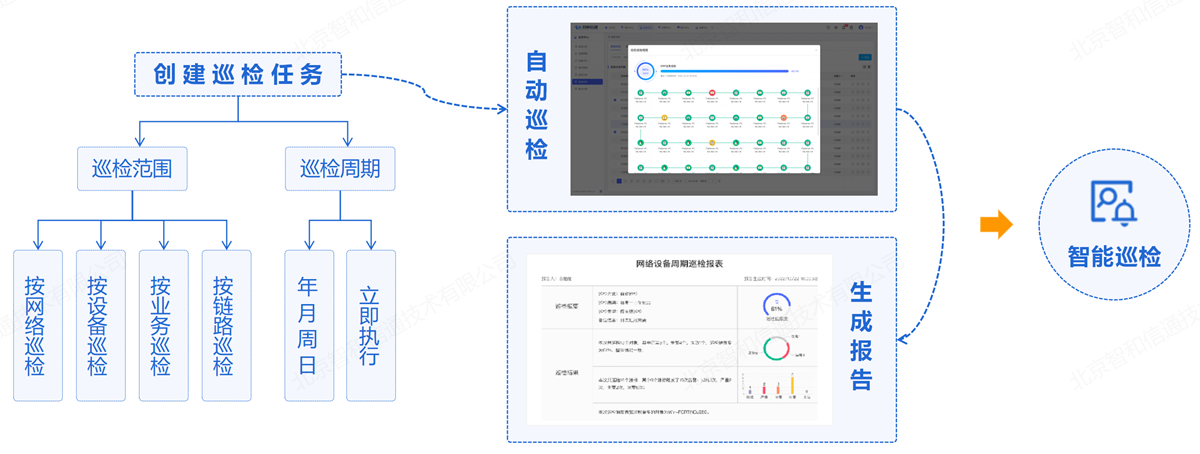
2.7. 跨云自动化巡检
传统的人工巡检,尤其是应用巡检,缺乏统一的规范、标准,导致巡检的范围和深度都存在一定的局限性,并且是基于人工的手工统计,工作效率比较低,同时耗费较大的人力资源。本方案依托平台将以前依赖手工进行的日常巡检转换为自动化、定时执行的巡检策略,日常例行巡检、节假日和重要事件前的巡检均可自动化执行。
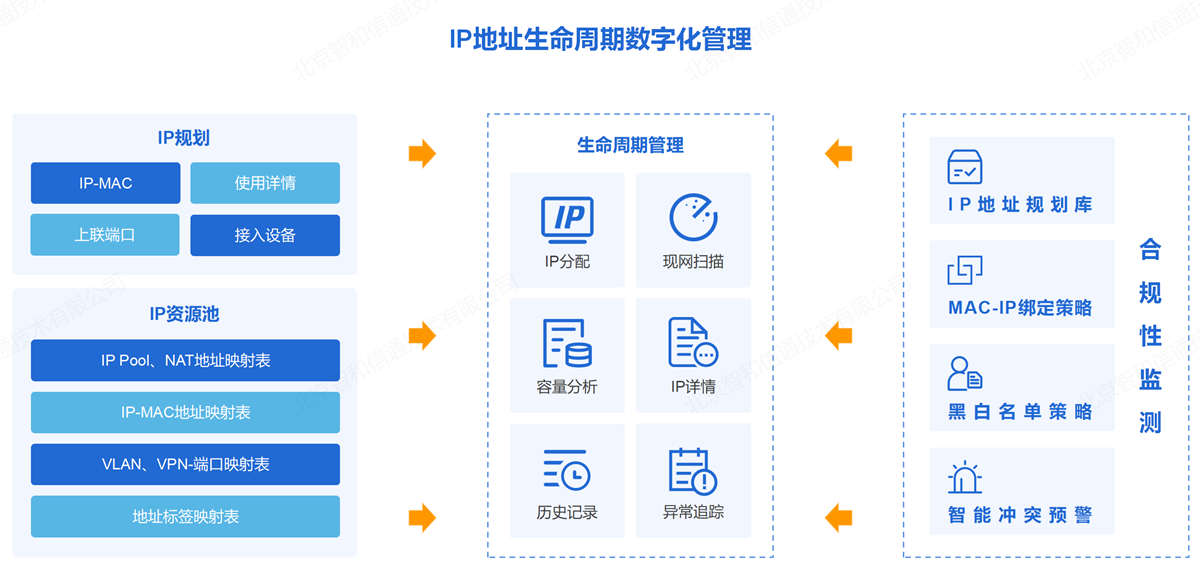
2.8. 全网IP合规管理
对于云上云下的IP地址采取统一数据标准进行梳理和管理,分网段、端到端的规划、部署、管理和监控IP地址。通过多种合规性策略检测全网MAC-IP的使用情况,实现从规划、分配到使用、回收的IP地址全视角管理,提升IP信息准确性,真正IP地址集中化、自动化、规范化管控。
第3章 跨云端到端业务运维体系
随着业务的不断增长,基于云上云下混合云架构的应用系统也越来越多,如OA、Email、ERP等。对业务层级的监控正逐渐成为日常运维巡检的核心,如何维护云上云下混合云架构的可靠稳定,不中断、不丢包、低延时、低抖动,以保障各项业务的稳定,已成为占IT运维部门超过60%份额的日常工作。
搭建可跨云的端到端业务运维体系,实现政企用户业务系统运维管理的主动化和体系化,通过实时地监测和分析发现系统潜在的问题和风险,实现主动式运维管理,保障关键业务稳定运行。
3.1. 业务全景可视化观测
方案通过构建业务系统与部门、IT资源及关键指标的关联关系,整合前端、应用、后台任务、外部服务、数据库及基础设施,直观呈现面向服务的业务系统体系架构;通过影响传递,准确反映设备异常对核心业务、用户造成的影响和威胁,并对造成业务影响的故障进行实时告警,快速查明导致业务中断的故障源,帮助运维人员做出及时响应,保障业务连续性。
3.2. 业务可用性拨测分析
针对业务应用性能与用户体验进行检测分析,无需安装插件即可提供开箱即用的主动拨测试业务监测。从前端用户体验、网络延迟到后端业务服务和基础架构,全栈溯源为用户提供端到端完整全链路数据融合和关联分析,为用户快速发现业务性能瓶颈,提升用户体验奠定基础。
 业务看板示意图
业务看板示意图
3.3. 全量业务调用链追踪
方案实现完整全链路调用链追踪,包含详细的调用链访问路径和性能等访问信息,以及相关的各类请求参数等业务数据指标,为故障定位、根因分析提供详尽的参考数据。
 业务全景示意图
业务全景示意图
3.4. 业务瓶颈根因定位
方案通过全面的业务数据可视化能力,既可集中呈现业务数据的用户体验状态,也可以基于应用、设备实时监控、呈现业务各节点的实时运行状态,包括用户体验、节点可用性、节点负载等状态信息。基于自定义阈值自动监测,异常指标自动触发告警,快速定位业务瓶颈根因,并可根据用户自愈策略,触发自动运维实现故障自愈。
第4章 全场景可视化跨云运维编排
随着政企用户数字化、信息化建设发展而来的是越来越复杂的业务和越来越多样化的需求,不断扩展的应用需要更加合理的运维模式来保障。传统运维依赖人工进行,运维效率低,网络配置管理易出错,排障处置困难。
方案通过运维自动化将IT运维中涉及的服务、命令、操作、执行组件化、策略化,将需要进行的运维服务、操作等以组件、策略的形式托管至平台中进行维护和管理,通过简单灵活的编排能力,使用者可以选择业务场景所需的策略,通过可视化拖拽的编排方式进行组合,即可完成应用场景端到端的图形化编排。
4.1. 网络变更、云平台配置自动化
混合云架构承载的业务经常发生变更,在传统云平台管理模式中,配置变更、性能优化等需求,均需通过运维工程师登录云平台手动执行,将产生大量重复性的工作,不仅耗时还极大地增加了运维的工作量。
在安全合规的前提下,本方案将运维人员从整体的变更流程及变更内容的准备中解脱出来,实现网络变更、设备配置自动化,业务需求变更,通过平台自动部署实现,无需手工敲命令行,快速响应需求变化。以“拖拉拽”的简单操作让“运维方案”真正自动化,实现业务应用软件自动部署、自动化升级等快速交付能力。

4.2. 人工运维与故障自愈结合
将人工运维与故障自愈结合,无需针对告警进行手动处置,只需预编排告警处理流程,平台根据场景自动触发,实现故障自愈。降低甚至清除排障处置中的延迟时间,完成零延迟的IT运维。
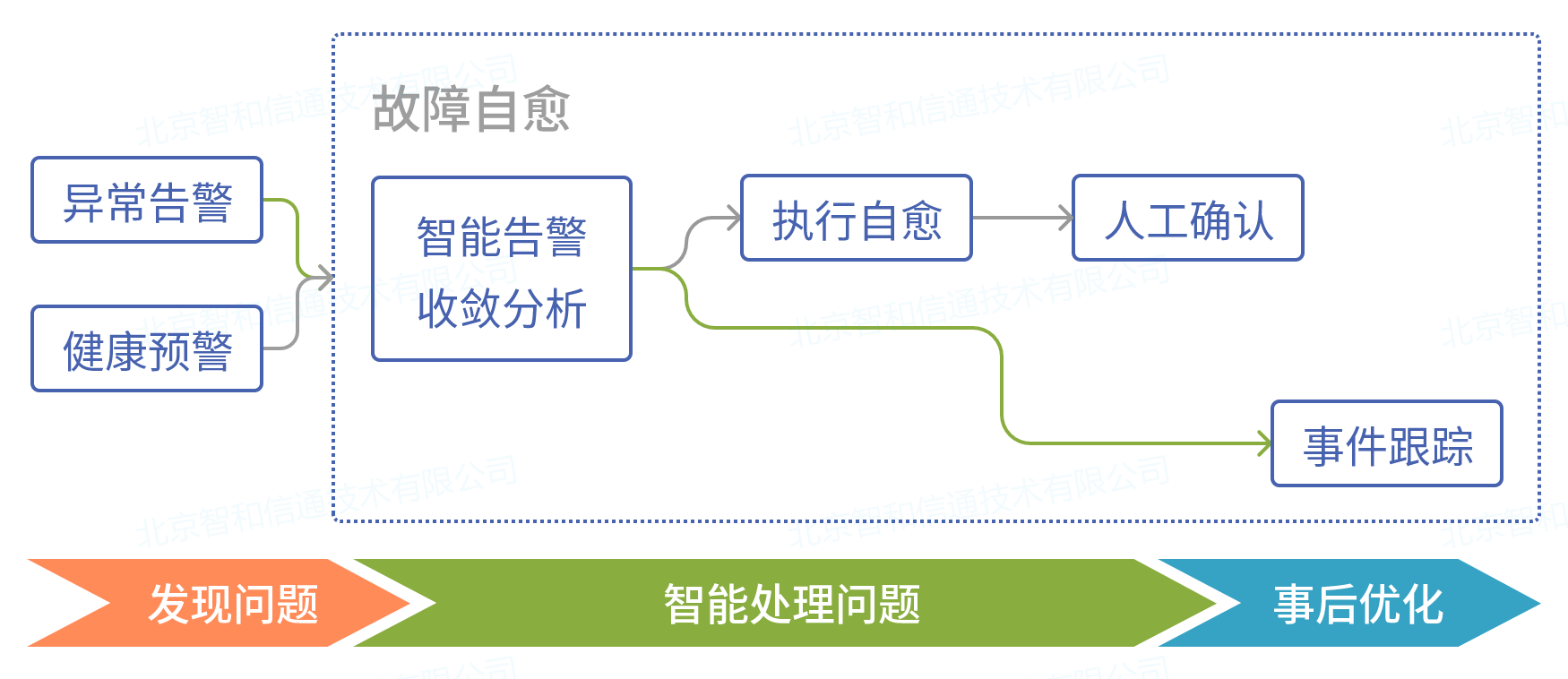
通过实时发现告警,进行预诊断分析,判断告警类型和级别,如果是一般告警,平台进行自动恢复,如果是严重复杂告警则通过告警通知、运维工单等形式通知运维管理人员,进行人工处理。同时,将只能由专家处理的各类操作和判断转化为可存在于平台内的流程,形成可保留可复用的运维知识。
4.3. 灵活编排,多场景支持
自动化运维编排,可实现完全根据用户场景,定制化设计运维剧本,真正将运维任务托管至平台,全面解放人力。
- 开发环境自动化,如软件代码自动化更新、自动化编译、自动化打包、自动化发布预警生产环境。
- 应用发布自动化,如服务自动化升级、软件自动化部署等。
- 故障自愈能力,如网口异常自动关闭、磁盘爆满自动清理、非法设备入侵阻断、CPU空间不足自动重启等。
- 定时服务重启,如在工作日每天晚上定时关闭应用,每天早上自动重启应用等。
- 智能批量设备管控,如批量设备策略执行,当设备的配置状态不一时,能够基于当前设备自身的状态自动决策适合于本设备的管控操作等。
- 定期设备健康状况自检,如定期设备健康状态自检、服务运行状态自检等。
- 基于HTTP接口自动化,如基于HTTP接口的工单自动化、审批自动化、业务自动化等。
- 高可用服务自动切换,如主备数据库运行状况自检异常自动切换,服务运行状态检查主备切换等。
- 虚拟化、云服务资源自动化扩容,如在虚拟化环境资源不足时自动化根据实际情况进行扩容。
- 日常运维自动化,如自动化定期执行批处理cmd\sh脚本、自动化定期数据清洗、自动化定期环境检查并导出报表等。
第5章 云监管数据分析展示
混合云架构中涉及的IT设施及各业务系统产生的海量数据无法得到深层次的应用,管理者决策缺乏数据依据,难以参考各类网络业务指标、数据等实现对运行态势、隐患风险的实时掌控及运营管理。
为解决此难题,智和信通混合云智能运维方案对云监管涉及的数据进行整合分析、分区域分层级地进行直观的图形、图表、图例等展示,从而帮助运维人员在短时间内更好地理解和获得更多的信息,帮助运维中心能够实时了解业务和其所依赖IT资源的运行状况,以及提供系统运维和优化的指示和依据。
 混合云运维大屏示意图
混合云运维大屏示意图
第6章 更多协同运维能力
6.1. 云上云下资产整合管理
对于云上云下各类资产管理,采取统一数据标准进行梳理和调用,避免资产信息在运维系统和实物间的差异,减少网络运维过程中信息不一致、数据不统一等问题通过平台将资产实物与运维数据库一一对应,解决网络设备在日常运维过程中出现“脱管”或“半脱管”的问题。

建立健全资产台账,实现一机一档,通过自定义多级资产分类,细化资产类别,实现物资资产、虚拟资产、云资产分类管控,通过在横向上纳管异构云平台,在纵向上理清异构跨层级资产间的对应关系,从根本上解决IT资源割裂、分散的问题,提高资产精细管理程度。
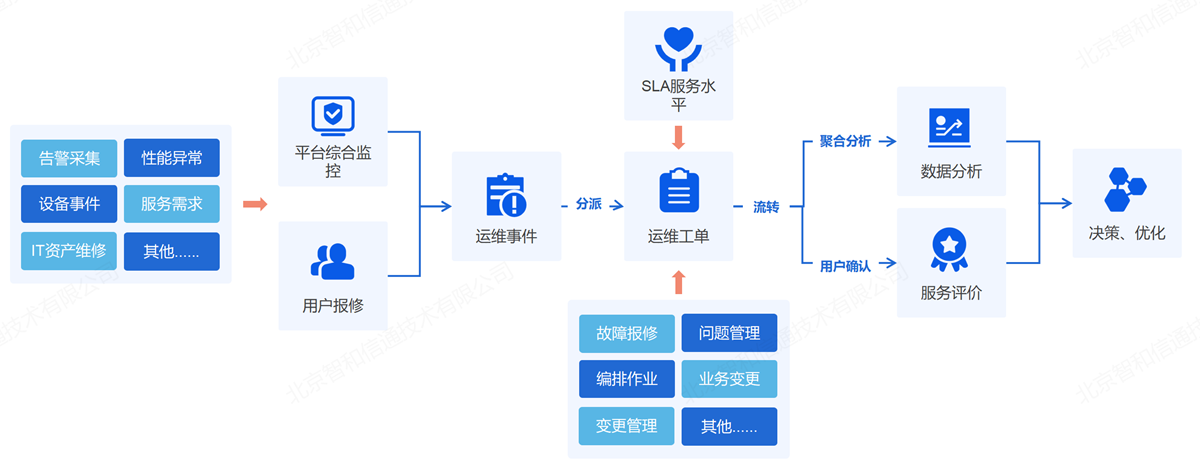
6.2. 运维工单无纸化流转
通过方案实现运维工单“无纸化”,支持于设备和故障管理页面快速创建工单,把控故障处理进度,通过工单平台简化故障处理流程,形成自动化故障处理机制,并在每个处理流程的节点上责任到人,实现在快速响应故障的同时,实现兼顾运维流程管控。
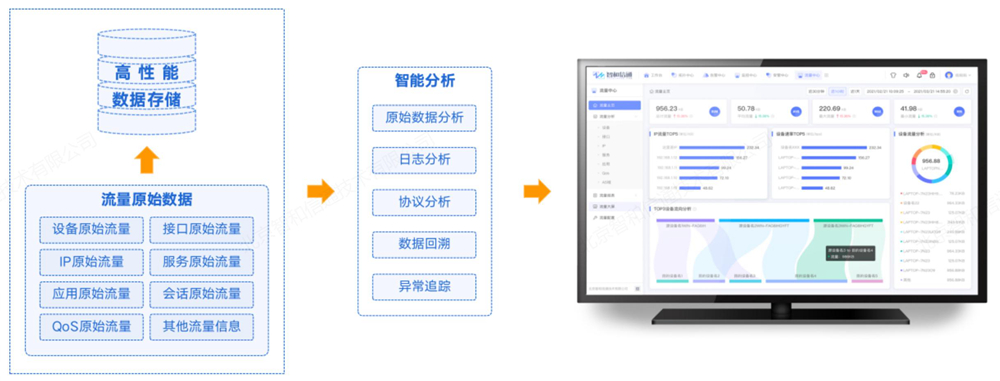
6.3. 全网带宽、流量透视
随着政企用户数字化转型和上云的加速,其业务、应用层出不穷,对网络带宽的需求越来越高。正常的业务需要良好的带宽环境保障机制,避免被一些与业务无关的杂事干扰,影响工作效率。方案对混合云路网络全局流量和带宽实时监控,将出入双方向流量情况可视化展现。基于海量流量数据的存储挖掘,统计分析流量峰值、谷值、流量趋势、设备流量等数据,为网络流量管理提供数据支撑。
第7章 兼容信创国产生态
方案实现对国产云、信创云、国产服务器的统一纳管,也支持在中标麒麟、银河麒麟、红旗Linux等国产操作系统上运行,支持在达梦、金仓、神州等国产数据库进行数据存储,通过东方通等国产中间件提供对外服务,支持龙芯、申威等国产CPU架构,助力用户业务应用的国产化环境改造。在支撑用户构建信创环境的同时,也针对各类信创设备、服务组件等提供相应的运维服务,在降本增效的同时,促进政企用户业务创新发展。

第8章 方案应用价值
通过多云资源池、多云专线、物理服务器、虚拟机、网络设备、存储设备等统一纳管,实现用户统一监控、统一告警、统一运营,避免运维孤岛。支持对任意云的接入纳管,实现对异构混合云的可观测能力建设,高效拉通异构云环境下的监控、配置、故障处置等运维能力。有效避免运维风险,保障业务连接不中断,通过自动化编排能力,避免在每个云平台上进行重复操作,降低了运维复杂性,全面提升IT管理和运维效率,让运维更简单。
标签:创云,用户,运维,平台,业务,公有,故障,自动化,云运维 From: https://www.cnblogs.com/zhtelecom/p/17839404.html