前言
昨天晚上阿里云史诗级崩溃了。
涉及到阿里云盘、淘宝、咸鱼、钉钉、语雀等等多条业务线产品。
“阿里云盘崩了”“淘宝又崩了”“闲鱼崩了”“钉钉崩了”等话题相继登上热搜,阿里系诸多产品受到影响。

这一次事故,影响范围之大,可以说是史诗级别的。
1 语雀出现异常
昨天那段时间,我正在使用语雀编辑知识星球中的文章,发现保存出现异常,页面直接报错了。
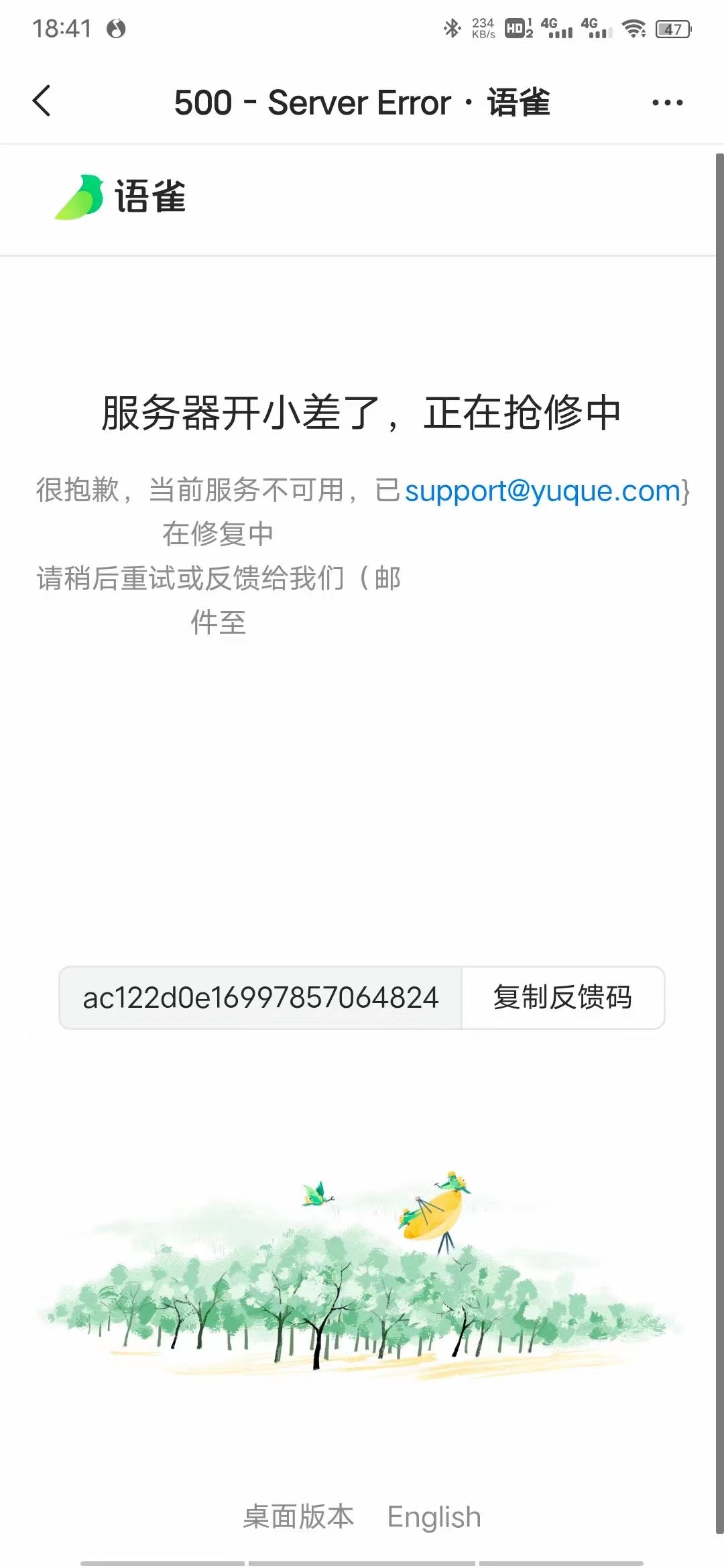
2 朋友圈很热闹
紧接着,我的朋友圈一下子热闹起来了。
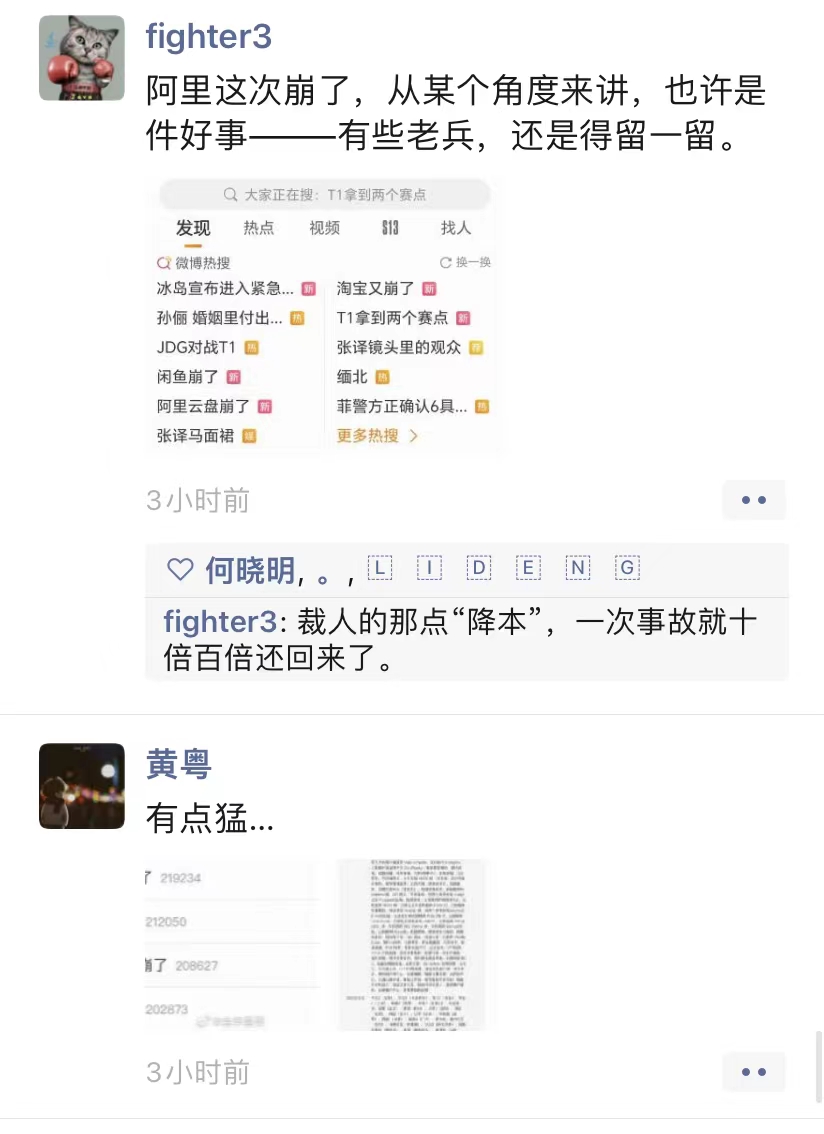
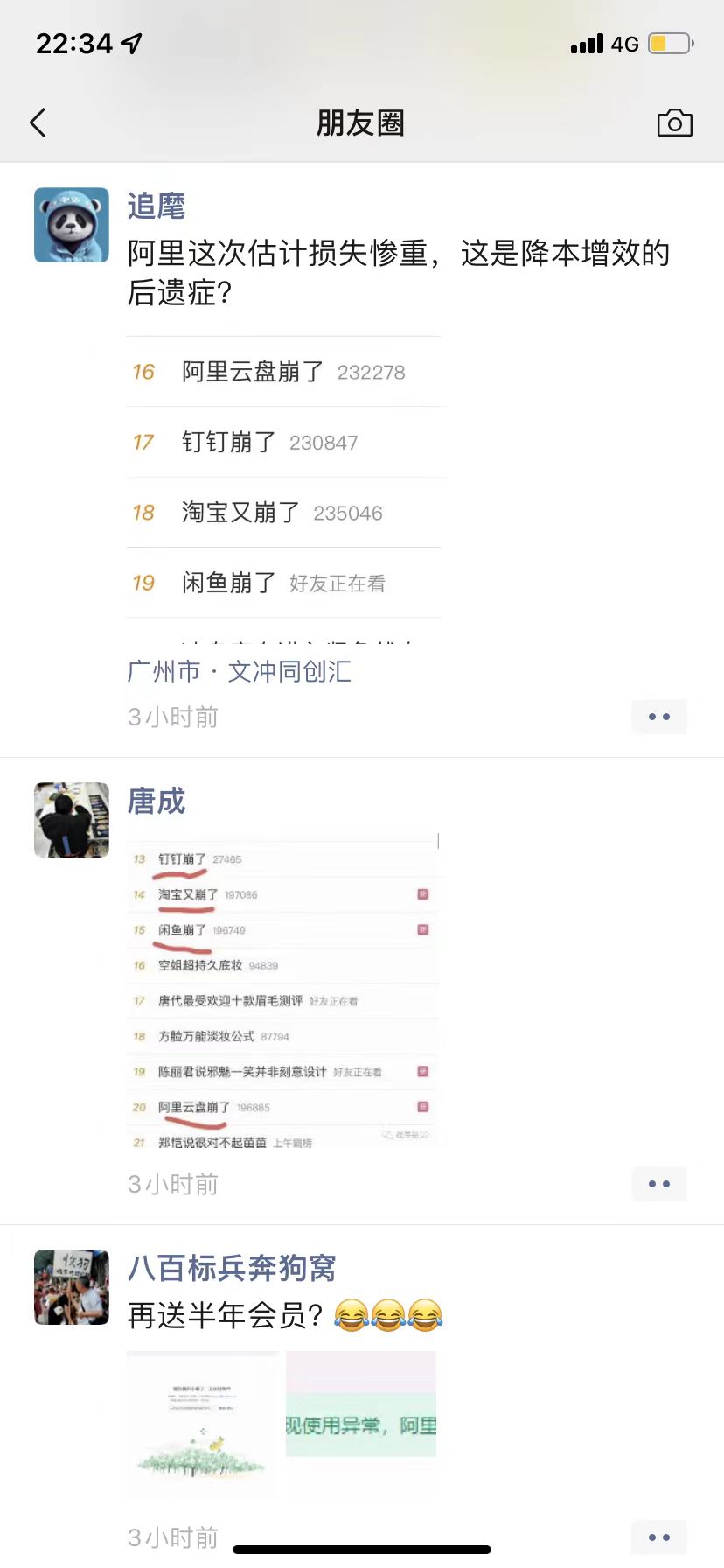
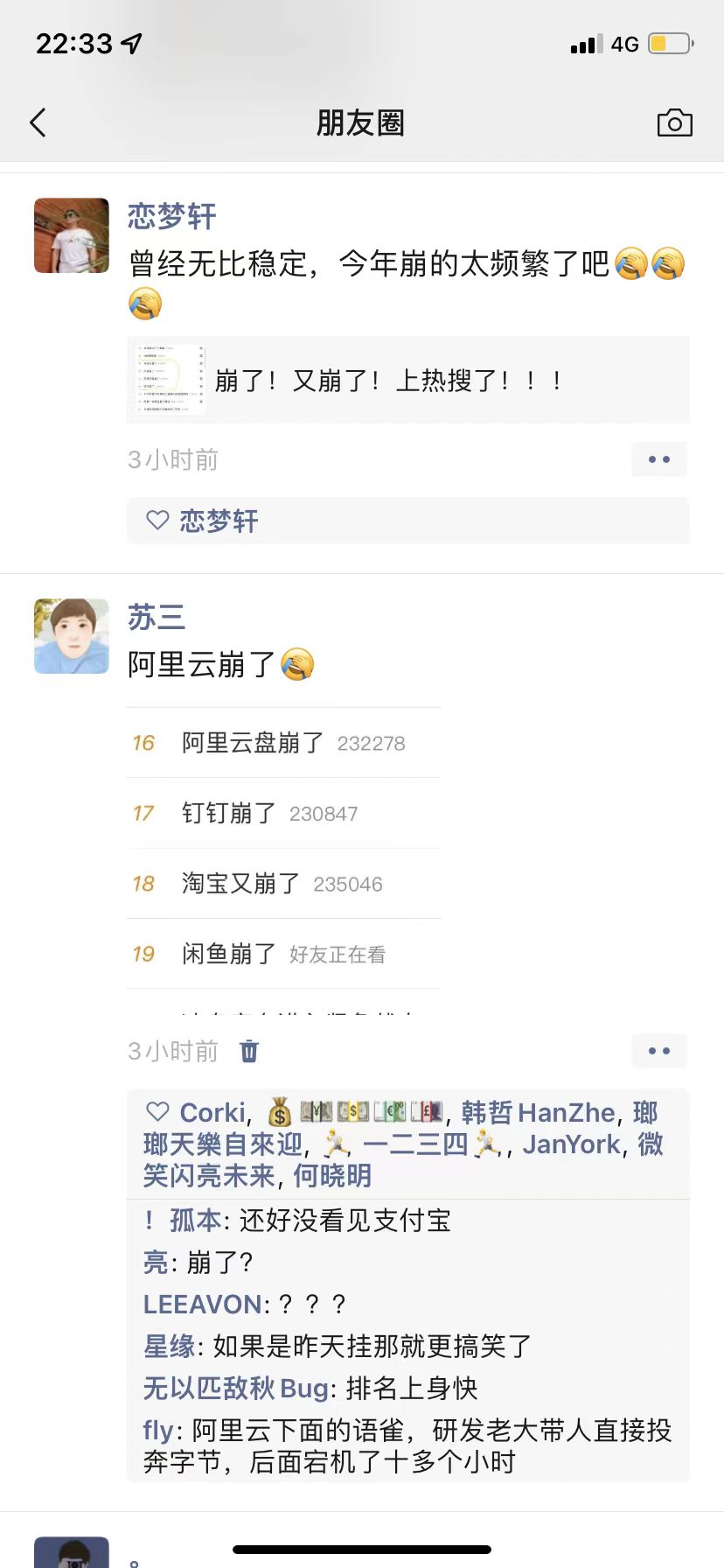
大家都在评论这件事故,说明了它的严重性,影响范围太大了。
3 事件的过程
阿里云对此公告称,2023年11月12日17:44起,阿里云监控发现云产品控制台访问及API调用出现异常,阿里云工程师正在紧急介入排查。
18:54阿里云再度公告,经过工程师处理,杭州、北京等地域控制台已恢复,其他地域控制台服务逐步恢复中。

而最新流出的截图显示,阿里工程师通过分批重启组件服务,大部分地域控制台服务已恢复访问。
据悉,此次受影响产品包括企业级分布式应用服务、消息队列MQ、微服务引擎、链路追踪、应用高可用服务、应用实时监控服务、Prometheus监控服务、消息服务、消息队列Kafka版、机器学习、图像搜索、智能推荐AlRec等。
而受影响地域涵盖华北2 (北京)、华北6 (乌兰察布)、 华北1 (青岛)、华东2(上海)、华南2(河源)、华北3(张家口)、中国香港、印度(孟买)、美国(硅谷)、华南1(深圳)、英国(伦敦)、韩国(首尔)、日本(东京)、阿联酉(迪拜)、西南1 (成都)、华南3 (广州)、新加坡、澳大利亚 (悉尼)、马来西亚(吉隆坡)、 华北5 (呼和浩特)、 印度 尼西亚(雅加达)、美国 (弗吉尼亚)、菲律宾 (马尼拉)、泰国(曼谷)、华东1(杭州)、华南1金融云。
这并非阿里云首次出现大面积故障。
目前是什么原因,还不得而知。
4 我以前的经历
因此,我们如果有高并发的业务场景,务必要做高可用,异地多活的设计。
我们之前做游戏平台的时候,为了保证游戏登录接口的高可用,为了防止机房网络的问题,比如:整个机房突然断电,或者机房遇到某些不可逆的因素,比如:发生地震或者洪灾,导致这个机房挂了。
为了保证机房出现问题时,尽可能小的影响用户。
我们在做系统设计的时候,使用了异地多活的架构,将用户流量负载到了三个机房:深圳机房、天津机房和成都机房。
其中深圳机房占了40%的流量,天津机房占了30%的流量,成都机房占了30%的流量。
并且选择了阿里云和亚马逊云两个不同的云服务厂商。
我们那段时间,还真的遇到过某个机房整个停电的问题。
不好幸好做了异地多活的设计,如果一个机房挂了,流量可以切到另外两个机房当中,将用户的影响降低最低。
当然关于异地多活问题,感兴趣的小伙伴,可以加我微信找我私聊。
最后
欢迎加入苏三知识星球【Java突击队】,一起学习。
星球中有很多独家的干货内容,比如:Java后端学习路线,分享实战项目,源码分析,百万级系统设计,系统上线的一些坑,MQ专题,真实面试题,每天都会回答大家提出的问题,免费修改简历,免费回答工作中的问题。
星球目前开通了9个优质专栏:技术选型、系统设计、工作经验分享、工作实战、底层原理、Spring源码解读、痛点问题、高频面试题 和 性能优化。

加入星球如果不满意,3天内包退。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。