多表查询02
4.表复制
- 自我复制数据(蠕虫复制)
有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以用此法为表创建海量数据
-- 为了对某个sql语句进行效率测试,我们需要海量数据时,可以用此法为表创建海量数据
CREATE TABLE my_tab01(
id INT ,
`name` VARCHAR(32),
sal DOUBLE,
job VARCHAR(32),
deptno INT
)
DESC my_tab01
SELECT * FROM my_tab01
-- 演示如何自我复制
-- 1.先把emp表的记录复制到my_tab01
INSERT INTO my_tab01
(id,`name`,sal,job,deptno)
SELECT empno,ename,sal,job,deptno FROM emp;
-- 2.自我复制
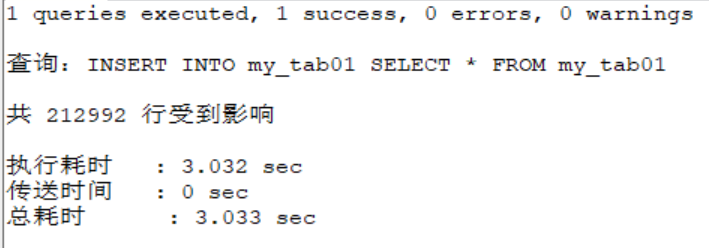
INSERT INTO my_tab01
SELECT * FROM my_tab01;
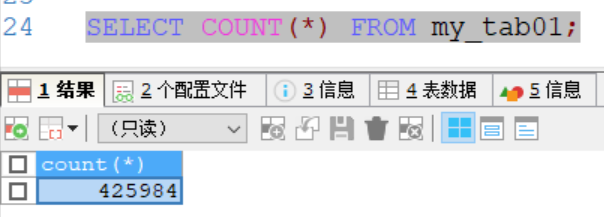
SELECT COUNT(*) FROM my_tab01;
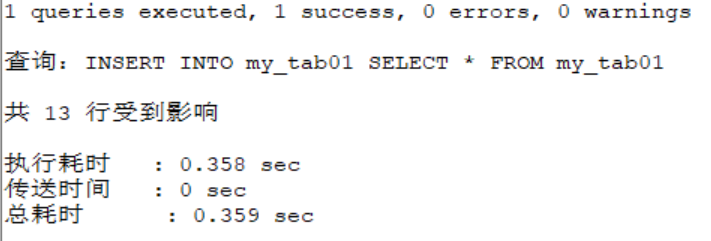
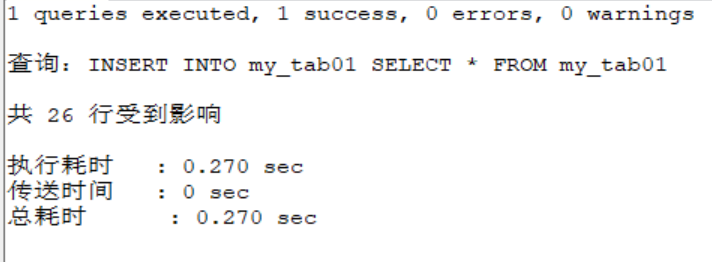
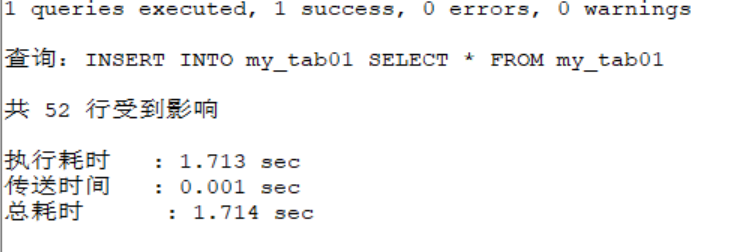
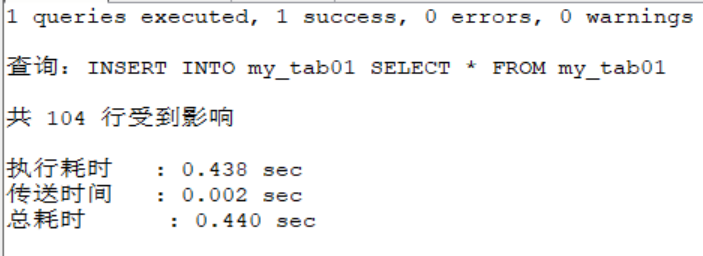
.....
- 思考:如何删掉一张表的重复记录
-- 如何删掉一张表的重复记录
-- 1.先创建一张表 my_tab02
CREATE TABLE my_tab02 LIKE emp; -- 这个语句将 emp表的结构(列),复制到my_tab02
DESC my_tab02;
-- 2.让my_tab02 有重复的记录
INSERT INTO my_tab02
SELECT * FROM emp;
SELECT * FROM my_tab02;
-- 3.考虑去重
/*
思路:
(1)先创建一张临时表 my_tmp,该表的结构和 my_tab02 一样
(2)把 my_tab02 的记录通过 distinct 关键字处理后,把记录复制到 my_tmp
(3)清除掉 my_tab02 的记录
(4)把 my_tmp 的记录复制到 my_tab02 中
(5)drop 掉 my_tmp表
*/
-- 3.1 先创建一张临时表 my_tmp,该表的结构和 my_tab02 一样
CREATE TABLE my_tmp LIKE my_tab02;
-- 3.2 把 my_tab02 的记录通过 distinct 关键字处理后,把记录复制到 my_tmp
INSERT INTO my_tmp
SELECT DISTINCT * FROM my_tab02;
-- 3.3 清除掉 my_tab02 的记录
DELETE FROM my_tab02;
-- 3.4 把 my_tmp 的记录复制到 my_tab02 中
INSERT INTO my_tab02
SELECT * FROM my_tmp;
-- 3.5 drop 掉 my_tmp表
DROP TABLE my_tmp;
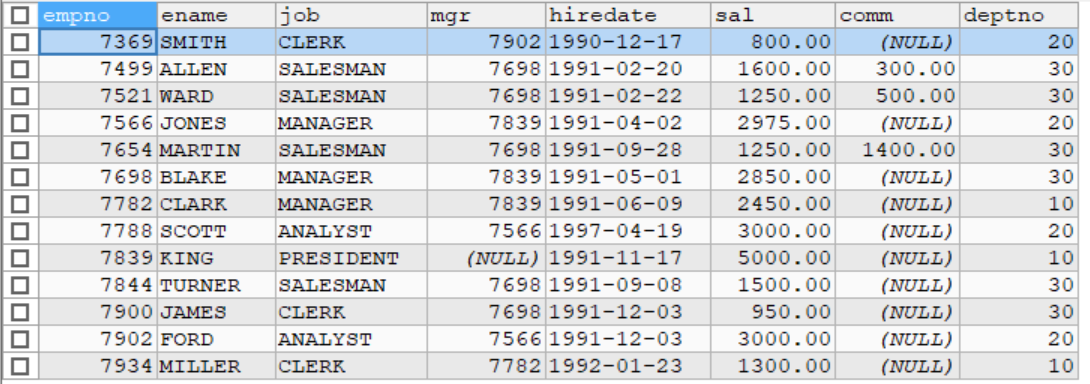
SELECT * FROM my_tab02;
5.合并查询
- 介绍
有时候在实际应用中,为了合并多条select语句的结果,可以使用集合操作符号union、union all、
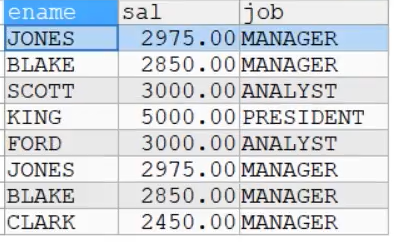
5.1union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会取消重复行

5.2union
该操作符与union all相似。但是会自动去掉结果集中的重复行

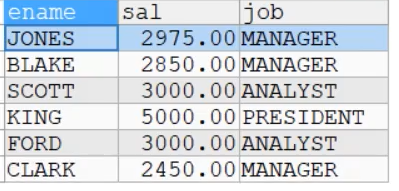
6.外连接
前面我们学习的查询,是利用where子句对两张表或者多张表,形成的笛卡尔集进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的就不显示
比如:列出部门名称和这些部门的员工名称和工作,同时要求显示出那些没有员工的部门
-- 外连接
-- 比如:列出部门名称和这些部门的员工名称和工作,同时要求显示出那些没有员工的部门
-- 使用我们学过的多表查询的SQL,看看效果如何?
SELECT dname,ename,job
FROM emp,dept
WHERE emp.deptno = dept.deptno
ORDER BY dname
-- 原先的办法只能显示有员工的记录,如果有一个部门没有员工,就无法显示该部门
如下:只能显示三个部门
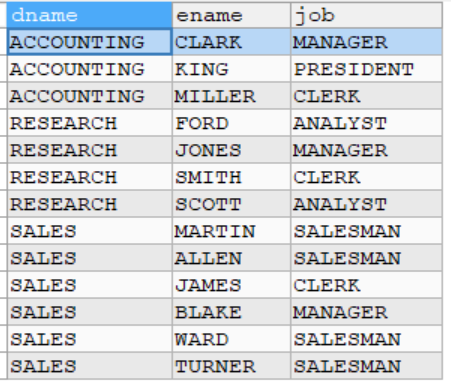
这时候就需要用到外连接
- 外连接
-
左外连接(如果左侧的表完全显示,我们就说是左外链接)
select ... from 表1 left join 表2 on 条件表1就是左表 ,表2就是右表
左侧的表完全显示是指,即使左边的表跟右边的表没有匹配上,也会将左侧的表完全显示
-
右外连接(如果右侧的表完全显示,我们就说是右外链接)
select ... from 表1 right join 表2 on 条件表1为左表 ,表2为右表
右侧的表完全显示是指,即使右边的表跟左边的表没有匹配上,也会将右侧的表完全显示
例子
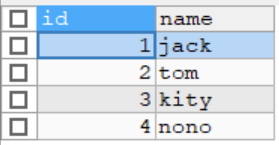
先创建两张表stu,exam
-- 创建 stu
CREATE TABLE stu(
id INT,
`name` VARCHAR(32)
);
INSERT INTO stu VALUES(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
SELECT * FROM stu;
-- 创建 exam
CREATE TABLE exam(
id INT,
grade INT
);
INSERT INTO exam VALUES(1,56),(2,76),(11,8);
SELECT * FROM exam;
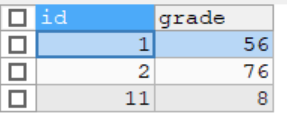
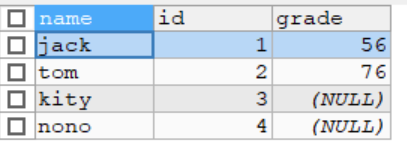
要求1:使用左连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号 )
-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号)
SELECT `name`,stu.id,grade
FROM stu,exam
WHERE stu.id = exam.id
-- 改成左外连接
SELECT `name`,stu.id,grade
FROM stu LEFT JOIN exam
ON stu.id = exam.id
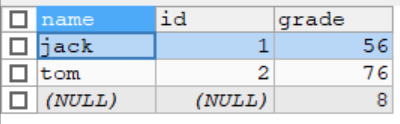
要求2:右连接(显示所有成绩,如果没有名字匹配就显示空)
-- 右外连接
SELECT `name`,stu.id,grade
FROM stu RIGHT JOIN exam
ON stu.id = exam.id
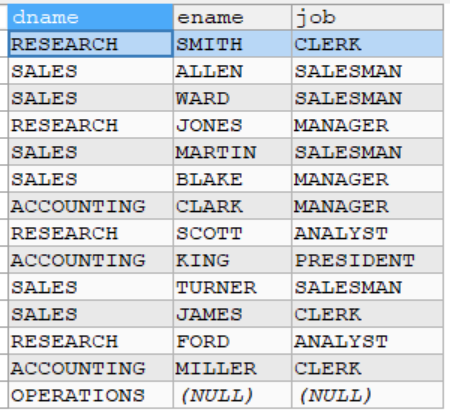
例子2
列出部门名称和这些部门的员工信息(名字和工作),同时列出那些没有员工的部门
- 使用左外连接实现
- 使用右外连接实现
-- 列出部门名称和这些部门的员工信息(名字和工作),同时列出那些没有员工的部门
-- 1. 使用左外连接实现
SELECT dname,ename,job
FROM dept LEFT JOIN emp
ON dept.deptno = emp.deptno
-- 2. 使用右外连接实现
SELECT dname,ename,job
FROM emp RIGHT JOIN dept
ON dept.deptno = emp.deptno
在实际的开发中绝大多数情况下使用的是前面学过的连接
标签:02,多表,--,day06,stu,tab02,my,id,SELECT From: https://www.cnblogs.com/liyuelian/p/16758516.html