@
目录安装maven
1,官网下载到本地,Binary是可执行版本,已经编译好可以直接使用。
Source是源代码版本,需要自己编译成可执行软件才可使用。
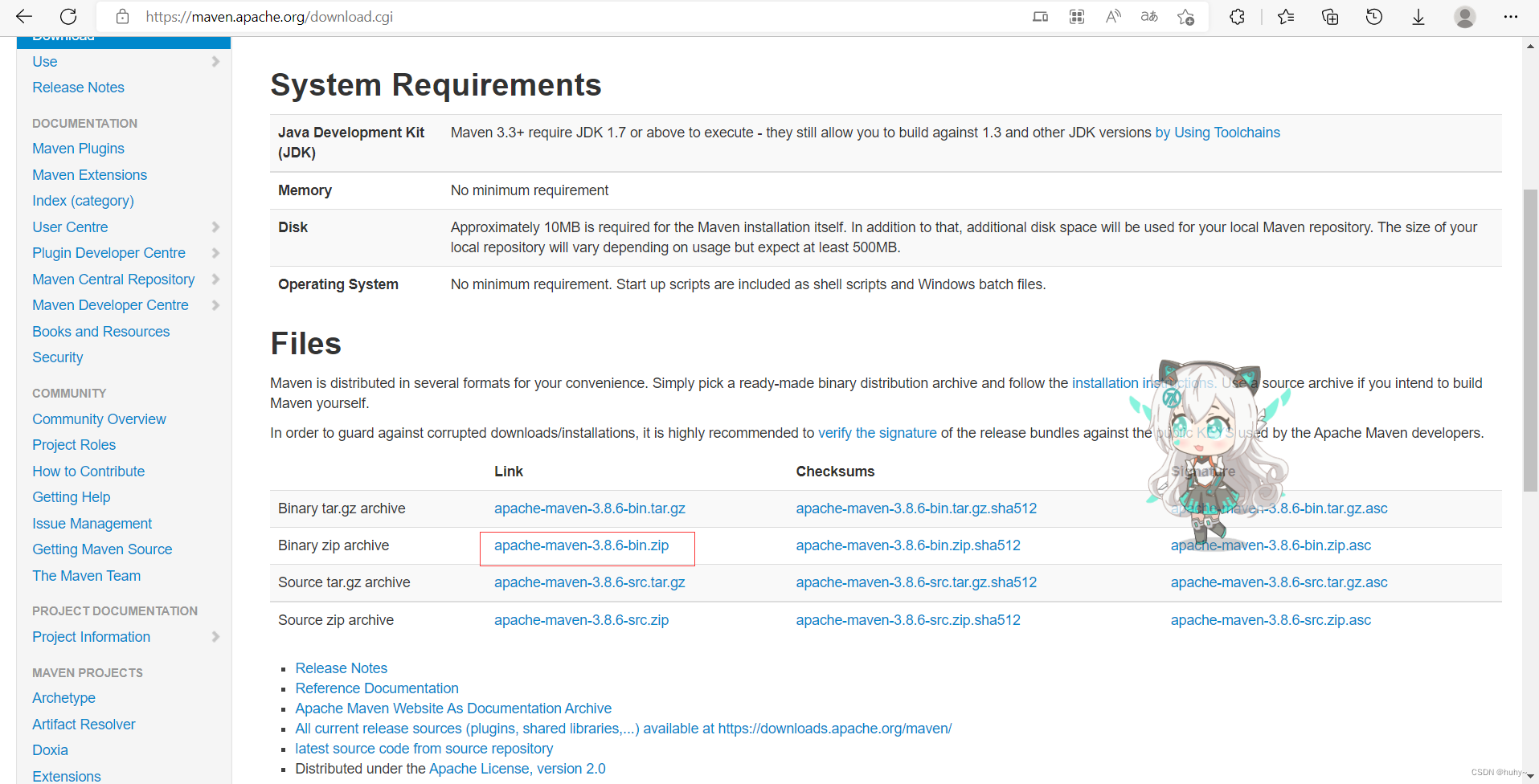
2,查看安装路径,配置环境变量
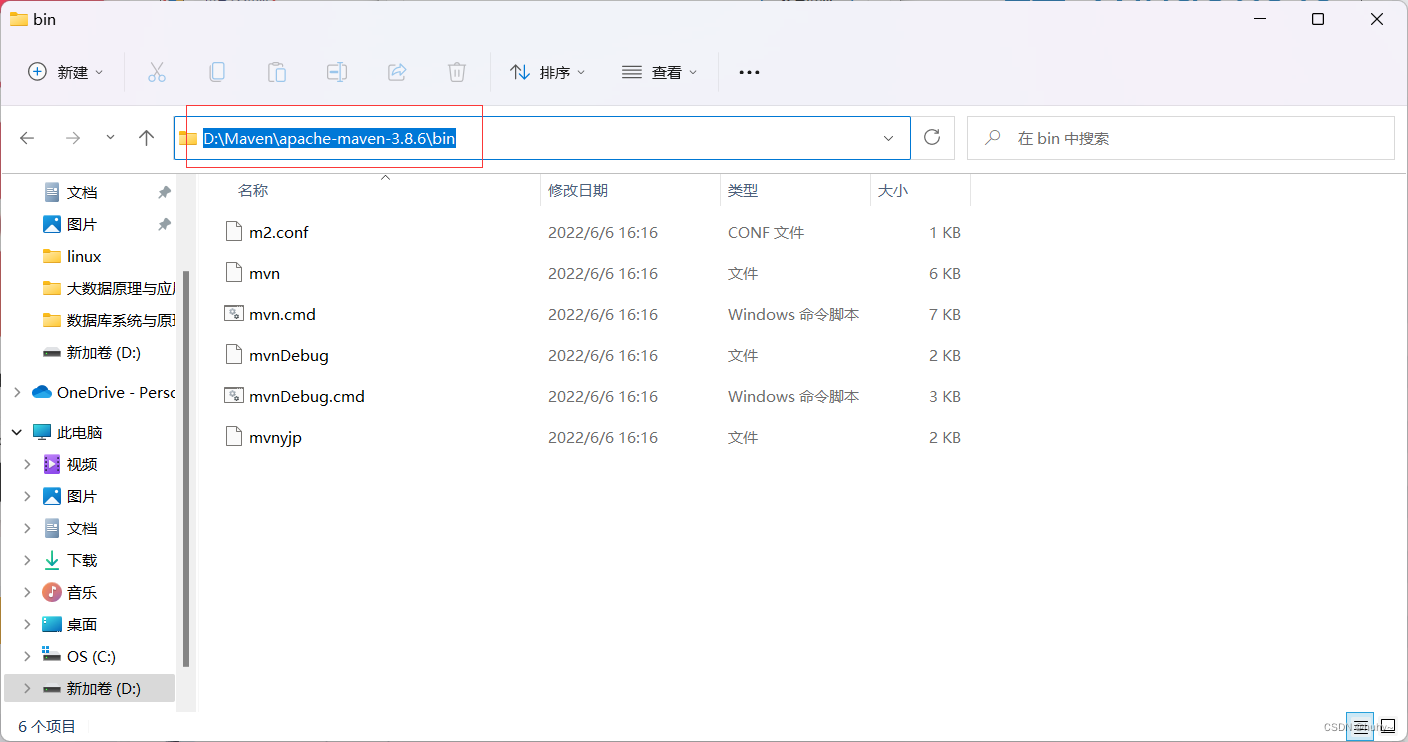
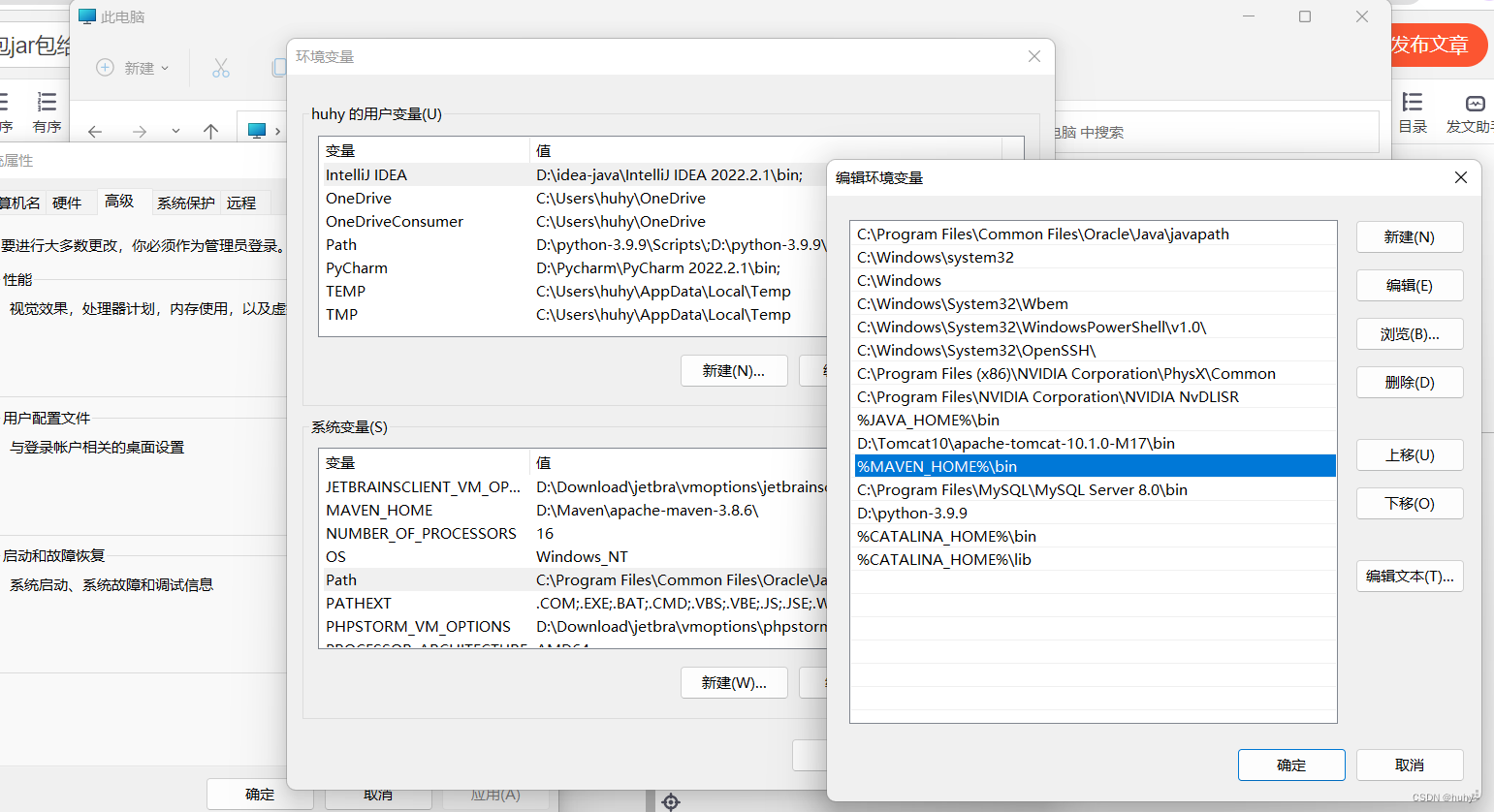
3,配置好环境变量
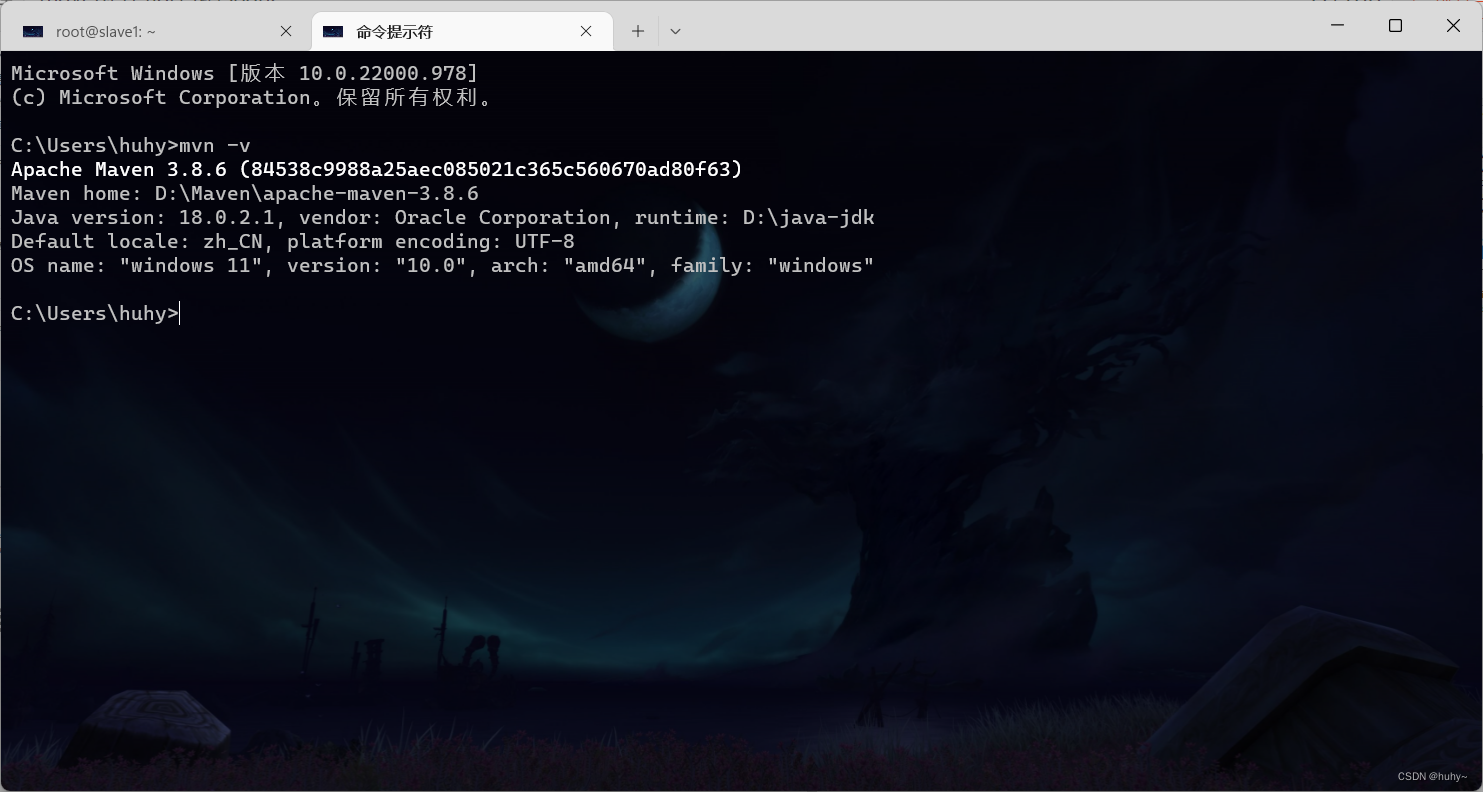
4,cmd测试
配置本地仓库
1,Maven文件夹内创建maven-repository文件夹,用作maven的本地库
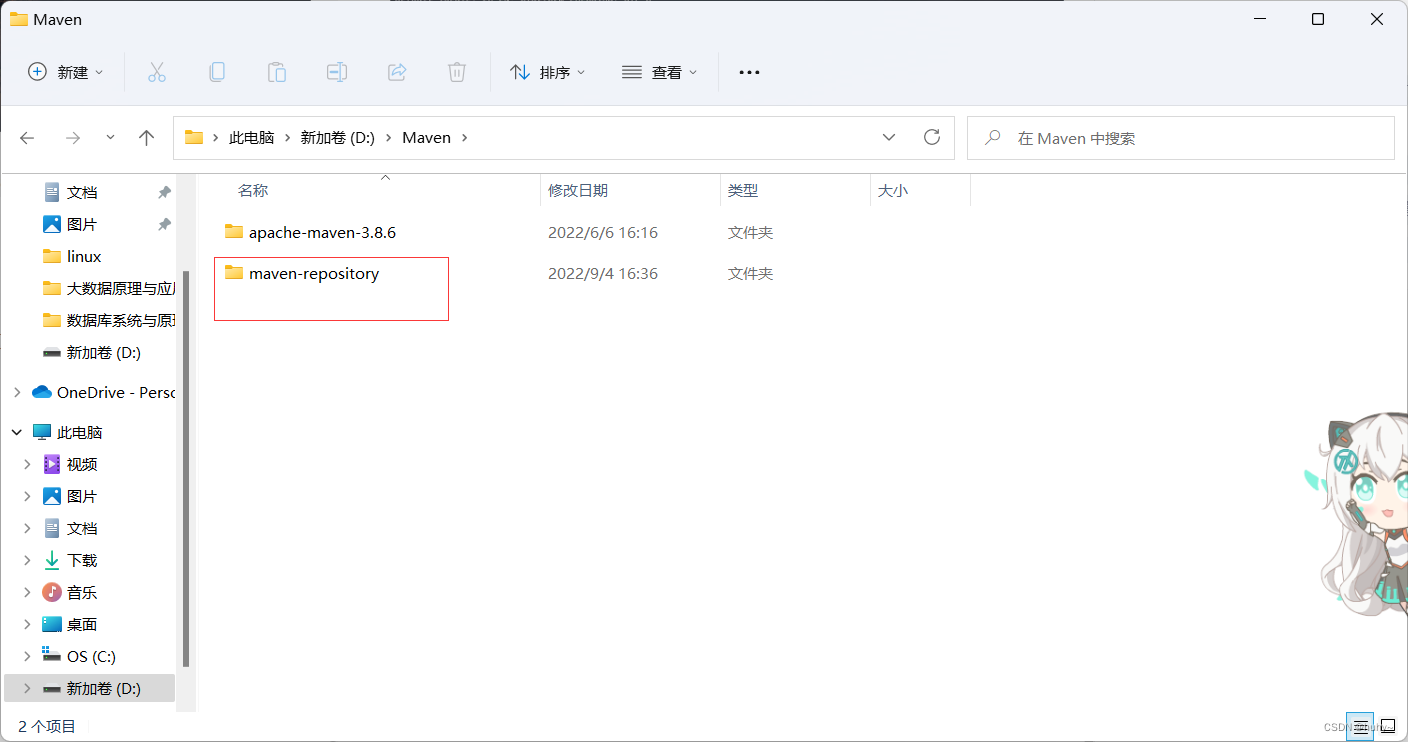
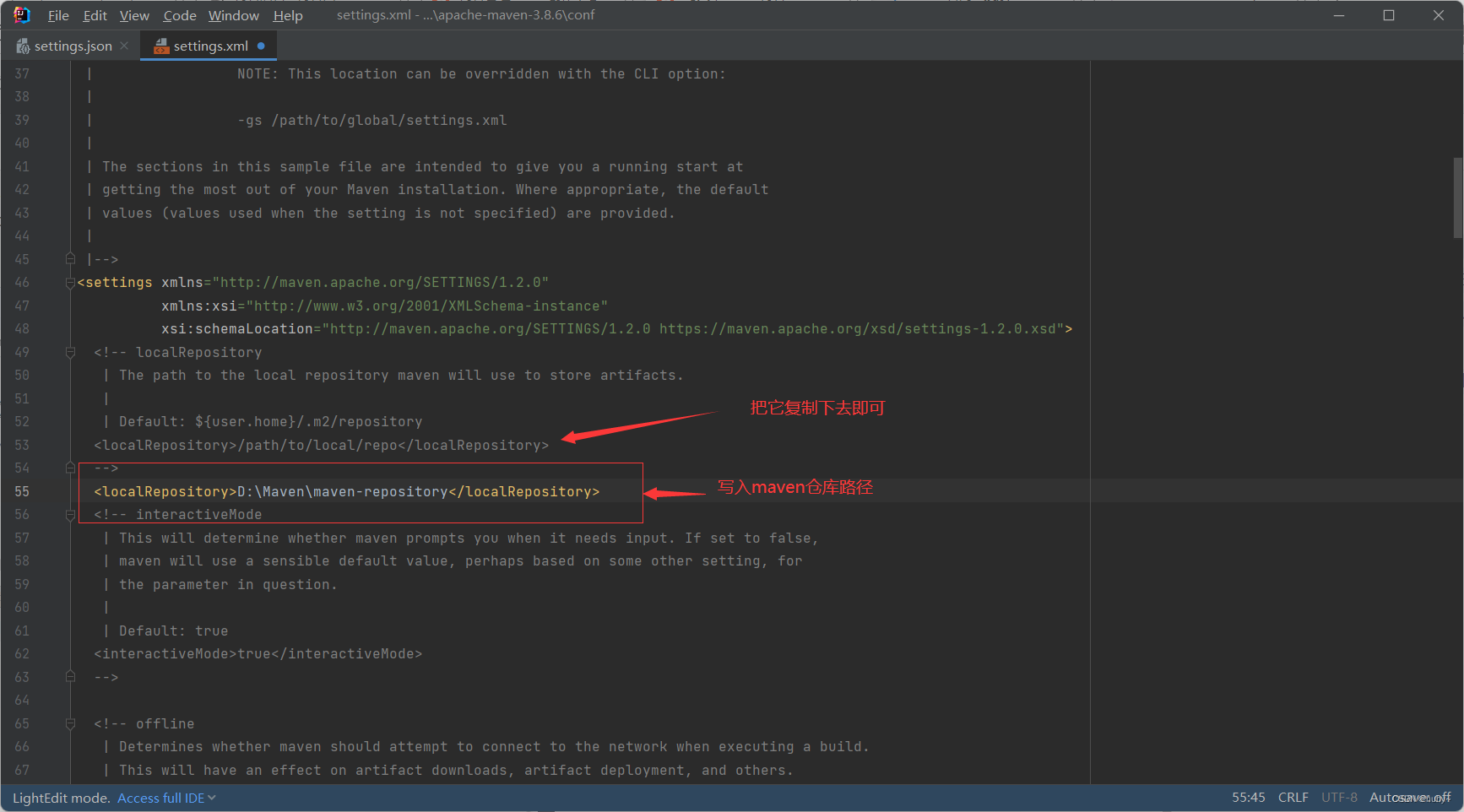
2,D:\Maven\apache-maven-3.8.6\conf下找到settings.xml文件,找到节点localRepository,在注释外添加仓库路径
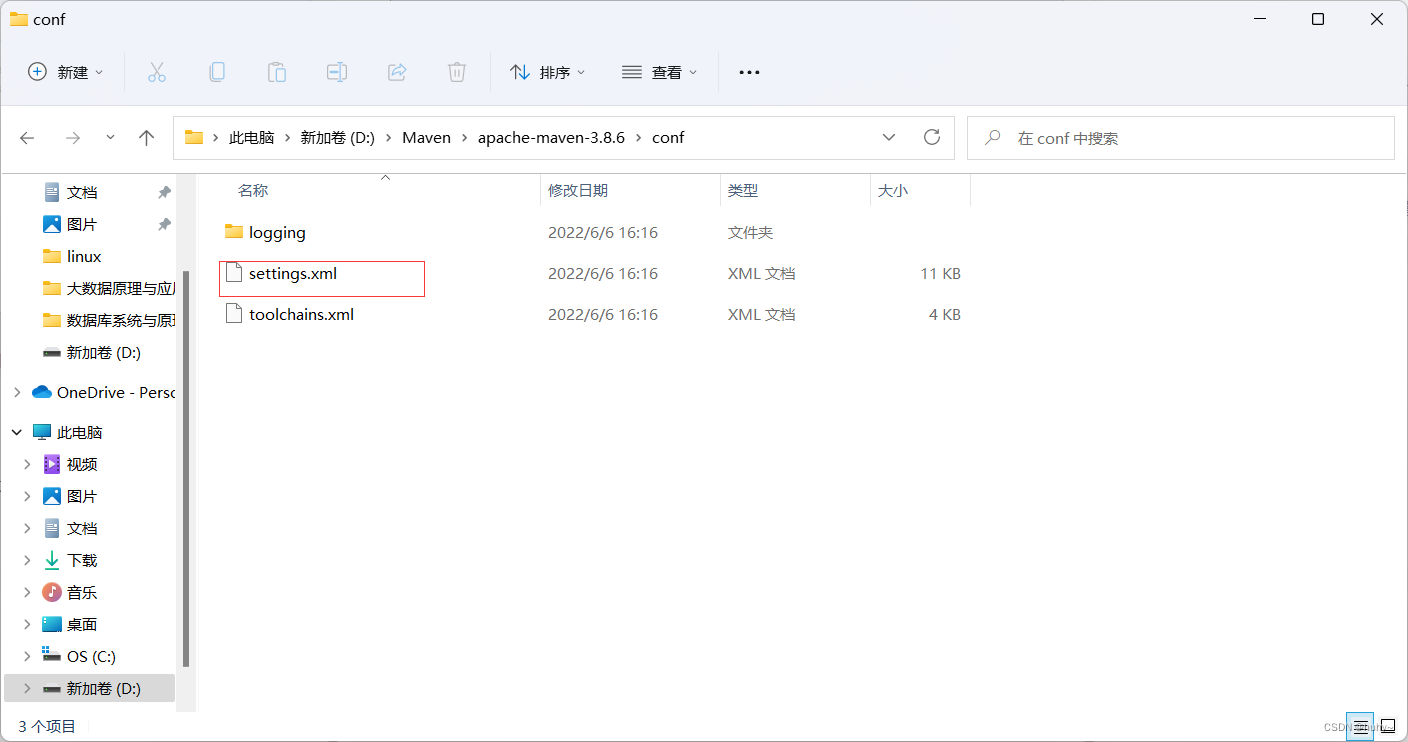
localRepository节点用于配置本地仓库,本地仓库其实起到了一个缓存的作用,它的默认地址是 C:\Users\用户名.m2。
当我们从maven中获取jar包的时候,maven首先会在本地仓库中查找,如果本地仓库有则返回;如果没有则从远程仓库中获取包,并在本地库中保存。
此外,我们在maven项目中运行mvn install,项目将会自动打包并安装到本地仓库中。
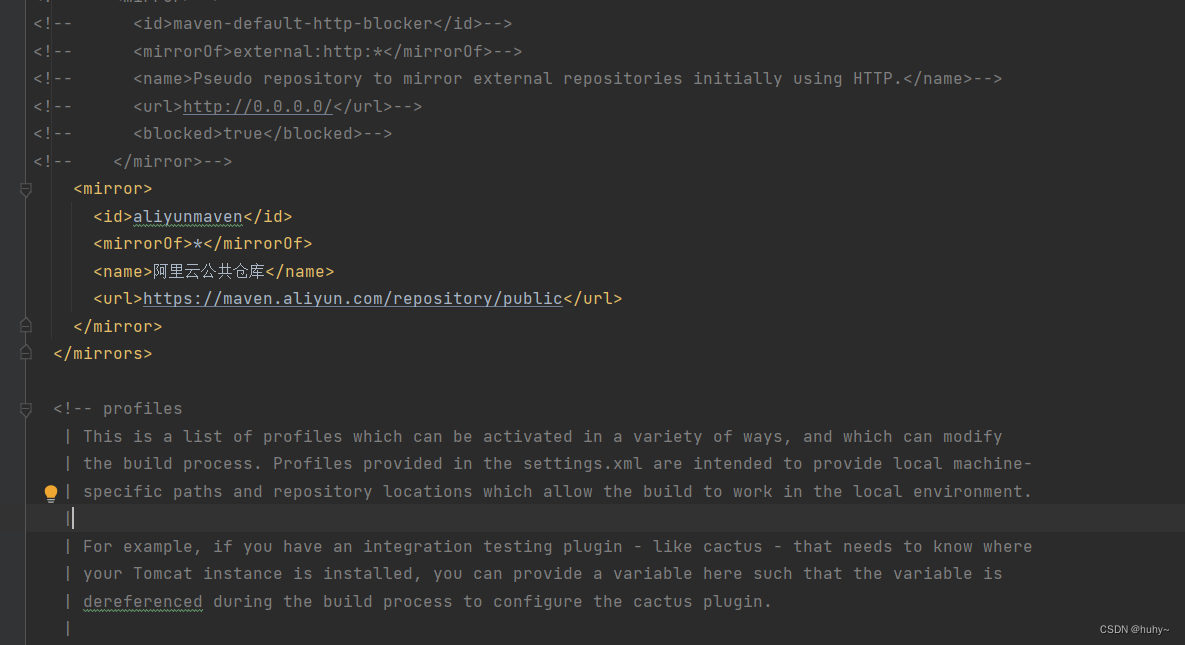
配置镜像
可以去官网查看
1.在settings.xml配置文件中找到mirrors节点添加如下配置(注意要添加在
#代码如下
<!-- 阿里云仓库 -->
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
idea配置maven
1,在全局设置maven的配置文件位置
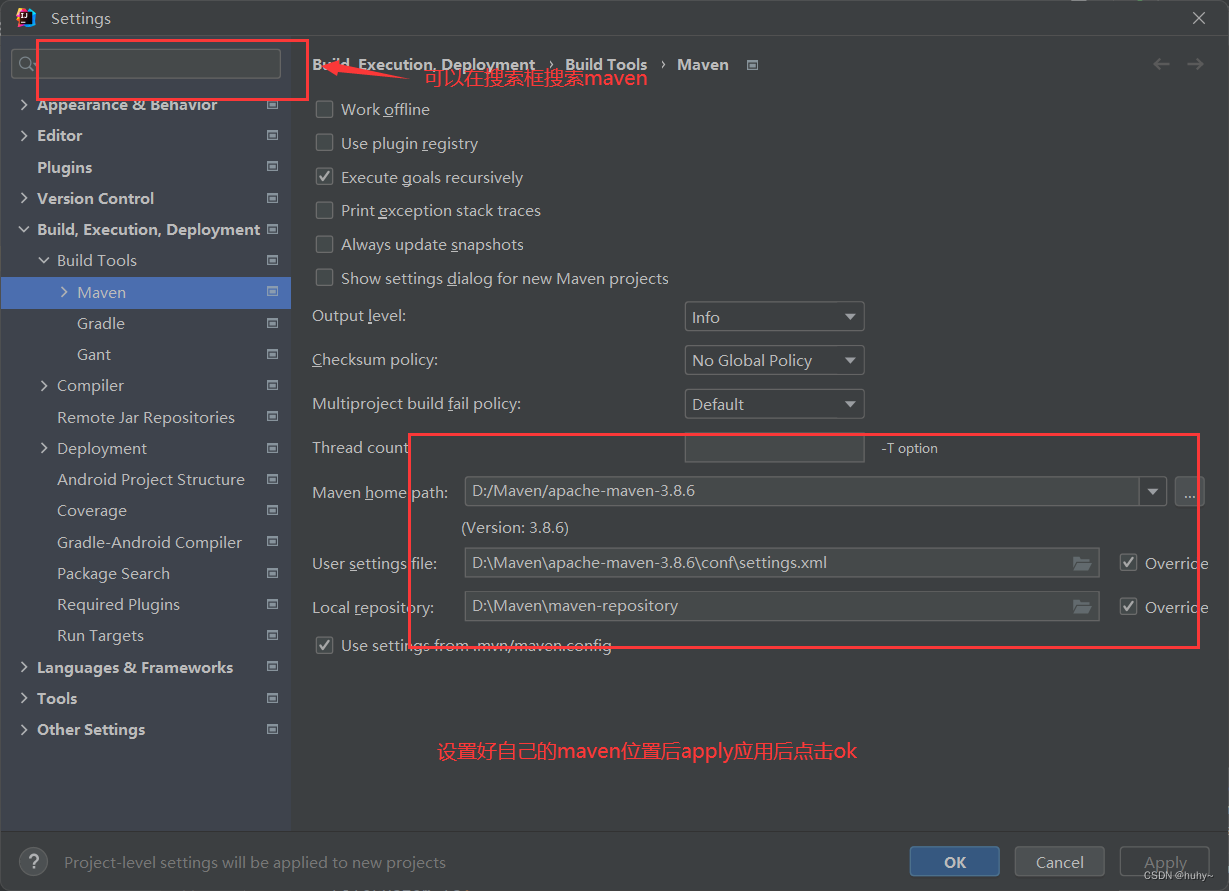
2,设置maven文件位置
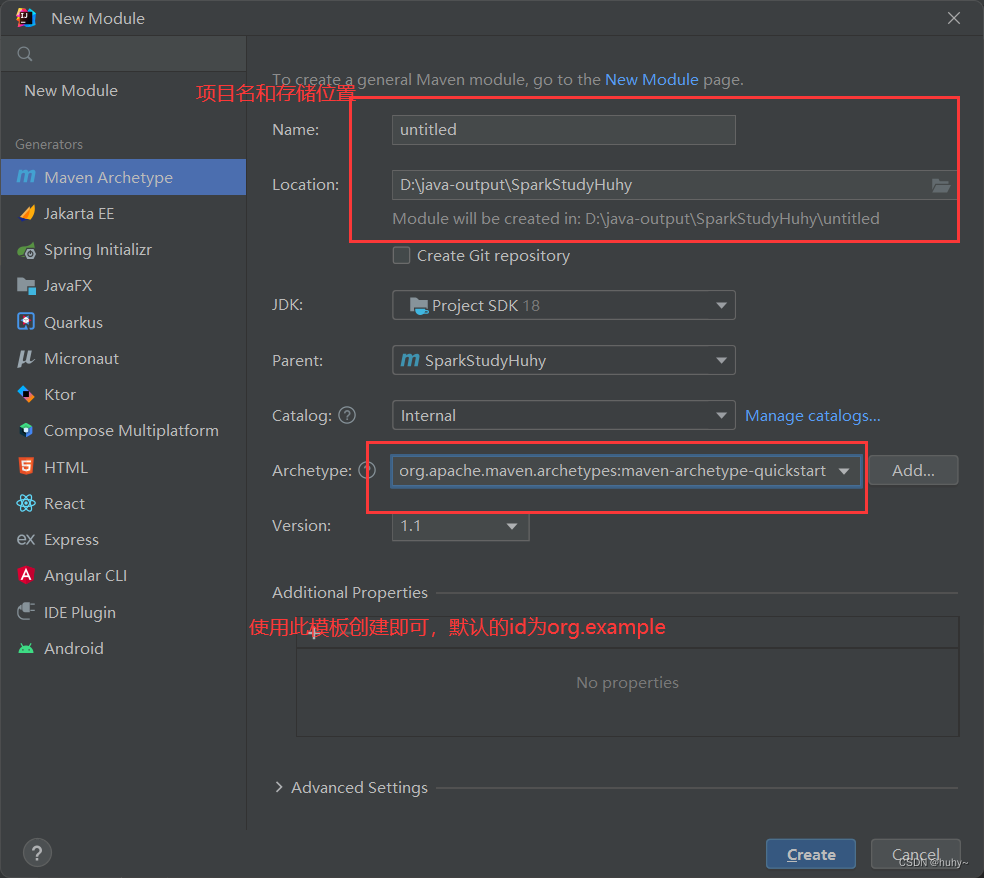
3,创建一个maven项目,如果创建的时候太慢,可以提前把所需要的插件下载下来放到自己的本地仓库中!!
4,修改pom文件,文件中有hadoop和spark需要的依赖,可根据网址去复制
切记要对应好你hadoop集群和spark、jdk的版本
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkStudyHuhy</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>SparkStudyHuhy</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
<build>
<finalName>SparkStudyCases</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
如果出现报红的情况,可以试着重新加载一下依赖
5,创建java文件,代码实现查看hdfs路径、两次查看文件内容,上传文件等
,注意查看代码中的参数,在命令会中调用方法
case "2cat":doubleCat(args);break;
case "load":copyFileWithProgress(args);break;
case "1ls":listStatus(args);break;
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
public class FileSystemAPIMain {
public static void main(String[] args) {
new FileSystemAPIMain().start(args);
}
private void start(String[] args) {
String choice=args[0];
switch (choice){
case "2cat":doubleCat(args);break;
case "load":copyFileWithProgress(args);break;
case "1ls":listStatus(args);break;
}
//doubleCat(args);
//copyFileWithProgress(args);
//listStatus(args);
}
private void cat(String[] args) {
String uri = args[1];
Configuration conf = new Configuration();
FileSystem fs;
InputStream in = null;
try {
fs = FileSystem.get(URI.create(uri), conf);
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
}catch (Exception e) {
System.err.println(e.toString());
} finally {
IOUtils.closeStream(in);
}
}
private void doubleCat(String[] args) {
String uri = args[1];
Configuration conf = new Configuration();
FileSystem fs;
FSDataInputStream in = null;
try {
fs = FileSystem.get(URI.create(uri), conf);
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0);
IOUtils.copyBytes(in, System.out, 4096, false);
}catch (Exception e) {
System.err.println(e.toString());
} finally {
IOUtils.closeStream(in);
}
}
private void copyFileWithProgress(String[] args) {
String src = args[1];
String dst = args[2];
Configuration conf = new Configuration();
FileSystem fs;
InputStream in = null;
OutputStream out = null;
try {
in = new BufferedInputStream(new FileInputStream(src));
fs = FileSystem.get(URI.create(dst), conf);
// out = fs.create(new Path(dst), new Progressable() {
// @Override
// public void progress() {
// System.out.print("*");
// }
// });
out = fs.create(new Path(dst), () -> System.out.print("*"));
IOUtils.copyBytes(in, out, 4096, false);
}catch (Exception e) {
System.err.println(e.toString());
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
private void listStatus(String[] args) {
String uri = args[1];
Configuration conf = new Configuration();
Path[] paths = new Path[args.length-1];
for(int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i+1]);
}
try {
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for(Path p : listedPaths) {
System.out.println(p);
}
}catch (Exception e) {
System.err.println(e.toString());
} finally {
}
}
}
打包jar包
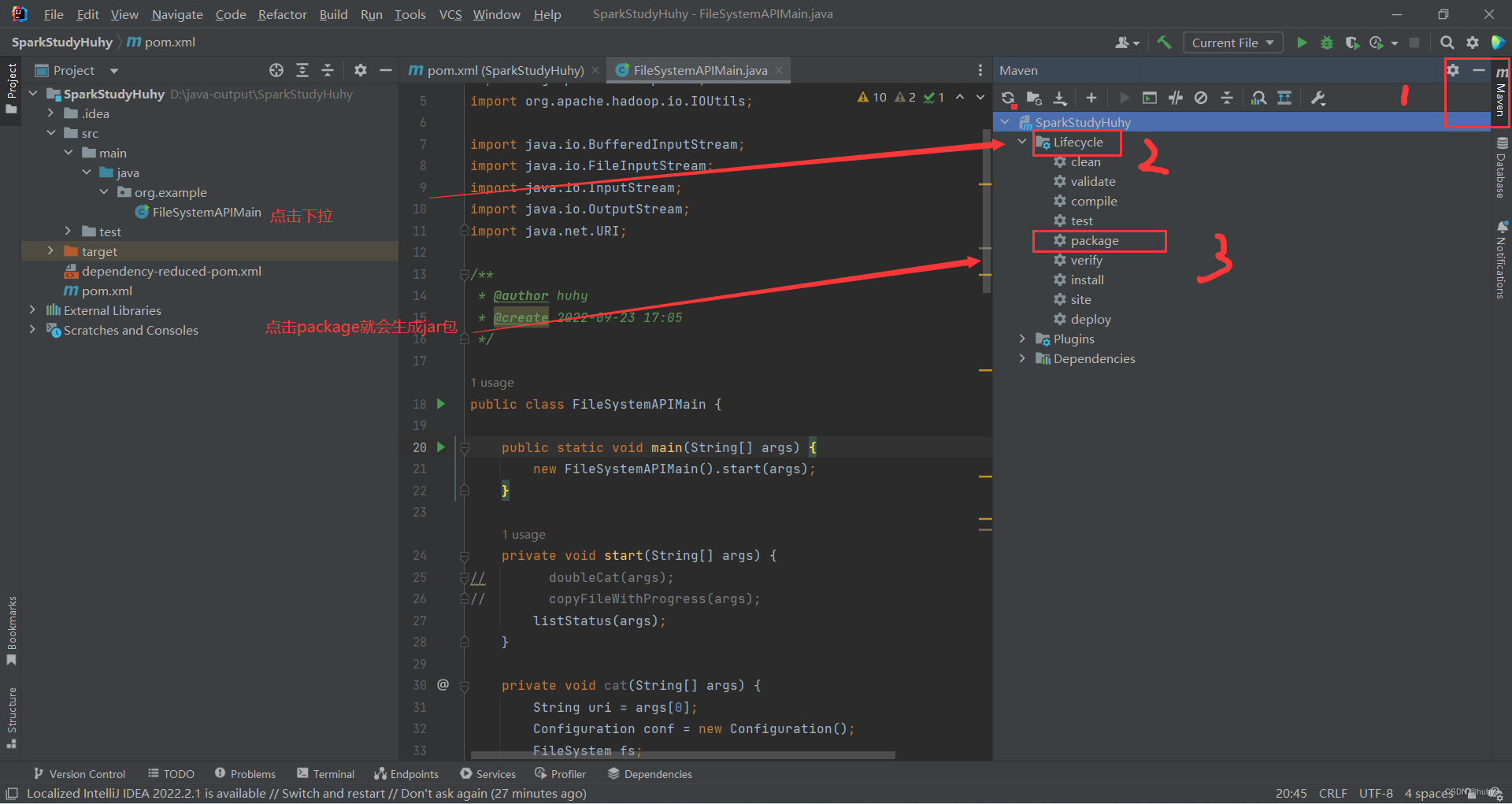
如果说项目修改了要重新打包jar包就需要点击clean再点击package
1,查看jar包
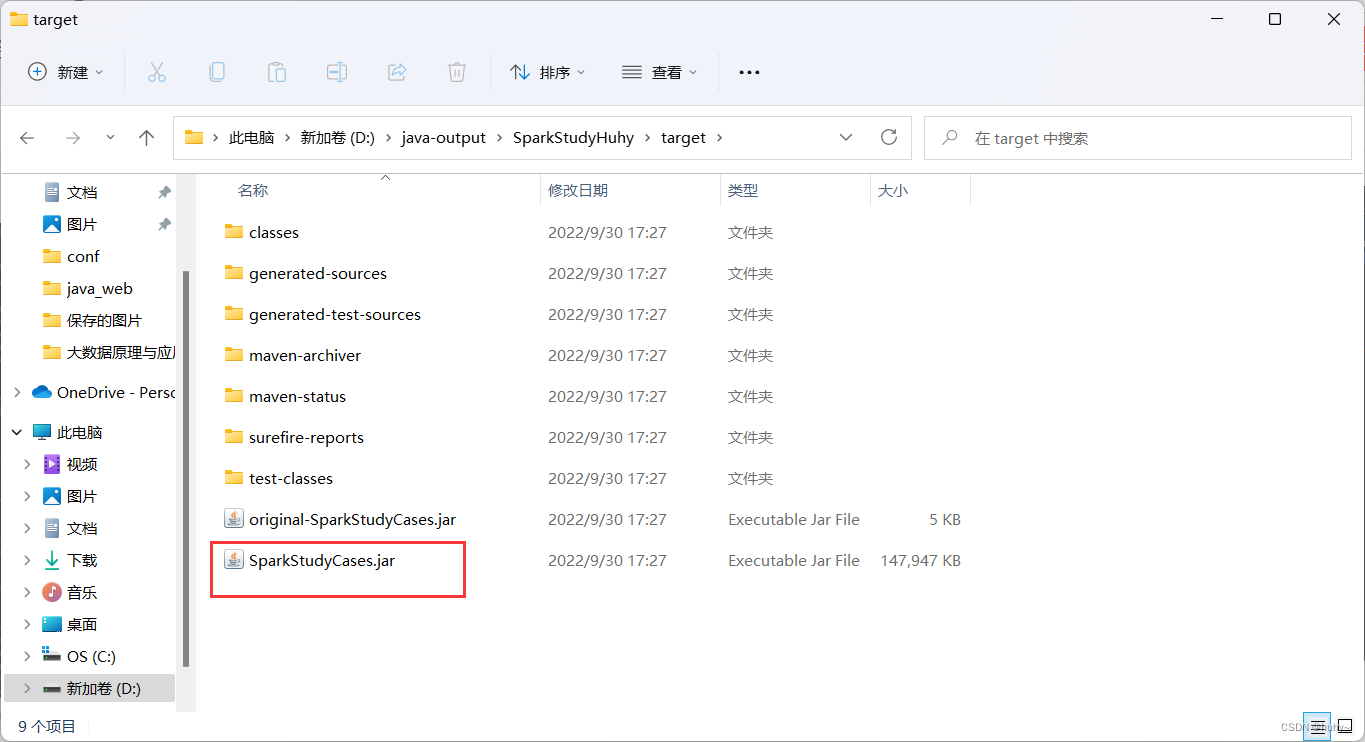
2,上传到我们的集群中使用
测试
root目录下执行
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar /
调用listStatus(args)查看hdfs根目录下的文件
root@master:~# /usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar 1ls /
22/10/06 09:09:45 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hdfs://master:8020/spark-logs
hdfs://master:8020/tmp
hdfs://master:8020/user
hdfs://master:8020/usr
22/10/06 09:09:46 INFO ShutdownHookManager: Shutdown hook called
22/10/06 09:09:46 INFO ShutdownHookManager: Deleting directory /tmp/spark-350d914b-afea-4244-8e74-aa16f3cc2ac4
root@master:~#
调用doubleCat(args)方法两次查看文件内容
首先把需要查看内容的文件上传到hdfs路径上
root@master:~# ls
hadoop-3.3.0.tar jdk-8u241-linux-x64.tar.gz snap SparkStudyCases.jar test.sh
hoyeong.txt profile.sh spark-3.3.0-bin-hadoop3.tgz start.sh
root@master:~# cat hoyeong.txt
zzzzzz
root@master:~# hadoop fs -cat /user/hoyeong.txt
zzzzzz
root@master:~#
两次查看hdfs上的文件内容
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar 2cat /user/hoyeong.txt
root@master:~# /usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar 2cat /user/hoyeong.txt
22/10/06 09:15:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
zzzzzz
zzzzzz
22/10/06 09:15:03 INFO ShutdownHookManager: Shutdown hook called
22/10/06 09:15:03 INFO ShutdownHookManager: Deleting directory /tmp/spark-f2b42e1b-df61-49a6-8619-bd99df6986c1
root@master:~#
调用copyFileWithProgress(args)上传本地文件到hdfs
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar load hoyeong.txt /test/hoyeong.txt
需要注意的是上传的路径是已经存在的,load是代码中指定的参数,和上面的2cat,1ls一样
root@master:~# ls
hadoop-3.3.0.tar jdk-8u241-linux-x64.tar.gz snap SparkStudyCases.jar test.sh
hoyeong.txt profile.sh spark-3.3.0-bin-hadoop3.tgz start.sh
root@master:~# /usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.FileSystemAPIMain SparkStudyCases.jar load hoyeong.txt /test/hoyeong.txt
22/10/06 09:19:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
**22/10/06 09:19:50 INFO ShutdownHookManager: Shutdown hook called
22/10/06 09:19:50 INFO ShutdownHookManager: Deleting directory /tmp/spark-e3e4c25d-032b-4537-a87b-5ef467843f30
root@master:~# hadoop fs -ls /test/
Found 1 items
-rw-r--r-- 3 root supergroup 7 2022-10-06 09:19 /test/hoyeong.txt
root@master:~#