什么是正则化?
正则化是在机器学习中防止过拟合,提高模型的泛化能力的一种技术,我们训练模型就是对目标函数求解,而目标函数就是误差函数(损失函数)加正则化项,正则化项当中的 λ 被称为正则化系数,越大,这个限制越强。需要值得注意的是,正则化往往用在线性函数上面,如线性回归、逻辑回归,SVM等,复杂的神经网络可能无法使用。
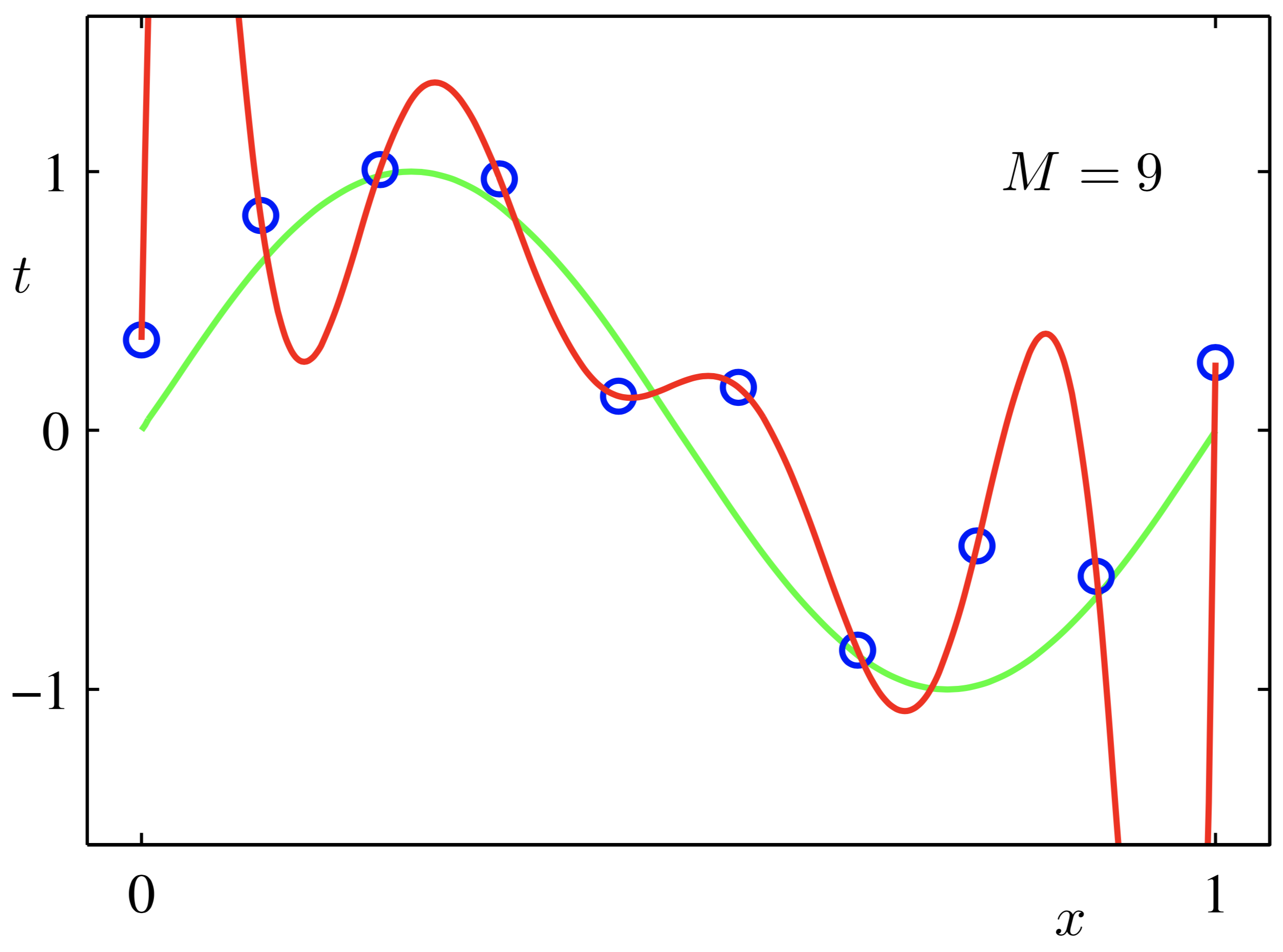
正则化如何限制模型能力?
线性模型:一般正则项到特殊

M是模型的阶次(表现形式是数据的维度),比如M=2,就是一个平面(二维)内的点,这里我们主要探究q的取值。

当M=2时,即W={W1,W2};横坐标是1,纵坐标是W2,绿线是俯视图的其中一条等高线。而z轴(垂直于平面)的值就是正则化项的取值。

蓝色圆圈上的点就是我们寻找误差函数的过程,红色圈圈是是正则化项的表示,这两者组成的是我们的目标函数,也就是说考虑这两项使得目标函数最优。二次正则项(左图)的优势是处处可导,方便计算,且保留原始维度(特征);一次正则项(有图)可以降低维度,得到稀疏的权重矩阵,,但是不是处处可微的,计算有一些麻烦。
神经网络
early stopping
Early stopping是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
具体做法:每个epoch(或每N个epoch)结束后,在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练,将停止之后的权重作为网络的最终参数。
缺点:缺点显而易见,可能没训练到理想的误差值就停止了,不能做出很复杂的判断。
Dropout
Dropout 指的是在训练过程中每次按一定的概率(比如50%)随机地“删除”一部分隐藏单元(神经元),所谓删除就是将神经元的激活函数设为0,让其不起作用。
它消除或者减弱了神经元节点间的联合,降低了网络对单个神经元的依赖,从而增强了泛化能力。
参考链接:https://charlesliuyx.github.io/2017/10/03/%E3%80%90%E7%9B%B4%E8%A7%82%E8%AF%A6%E8%A7%A3%E3%80%91%E4%BB%80%E4%B9%88%E6%98%AF%E6%AD%A3%E5%88%99%E5%8C%96/#Why-amp-What-正则化
标签:机器,函数,模型,epoch,学习,正则,化项,神经元 From: https://www.cnblogs.com/HOI-Yzy/p/16743184.html