摘要
本文提出了一种简单有效的连续学习策略,利用了深度模型压缩、关键权重选择和渐进网络扩展的原则并进行整合。
方法的优点:避免遗忘、允许模型扩展,同时可以通过之前的积累建立更好的模型。
动机
作者通过权重修剪、临界权重选择以及渐进网络扩展结合深度模型压缩的思想进行设计,并将其称为CPG。
作者提到正则化或者回放的方法虽然能减轻遗忘,但是并不能保证之前任务的准确率。一个有效的方法是通过增加节点等来扩大网络,但这会导致模型高度冗余。为了解决这个问题,作者每次都会对当前任务进行模型压缩去除冗余。
picking:通过设置mask挑选关键权重。
compacting:修剪部分不重要的权重并重新训练剩余权重。
growing:将以前释放的权重用于新任务,如果在使用所有释放的权重时还没有达到性能目标,就扩大结构,将释放和扩大的权重都用于新任务的训练。
方法总览
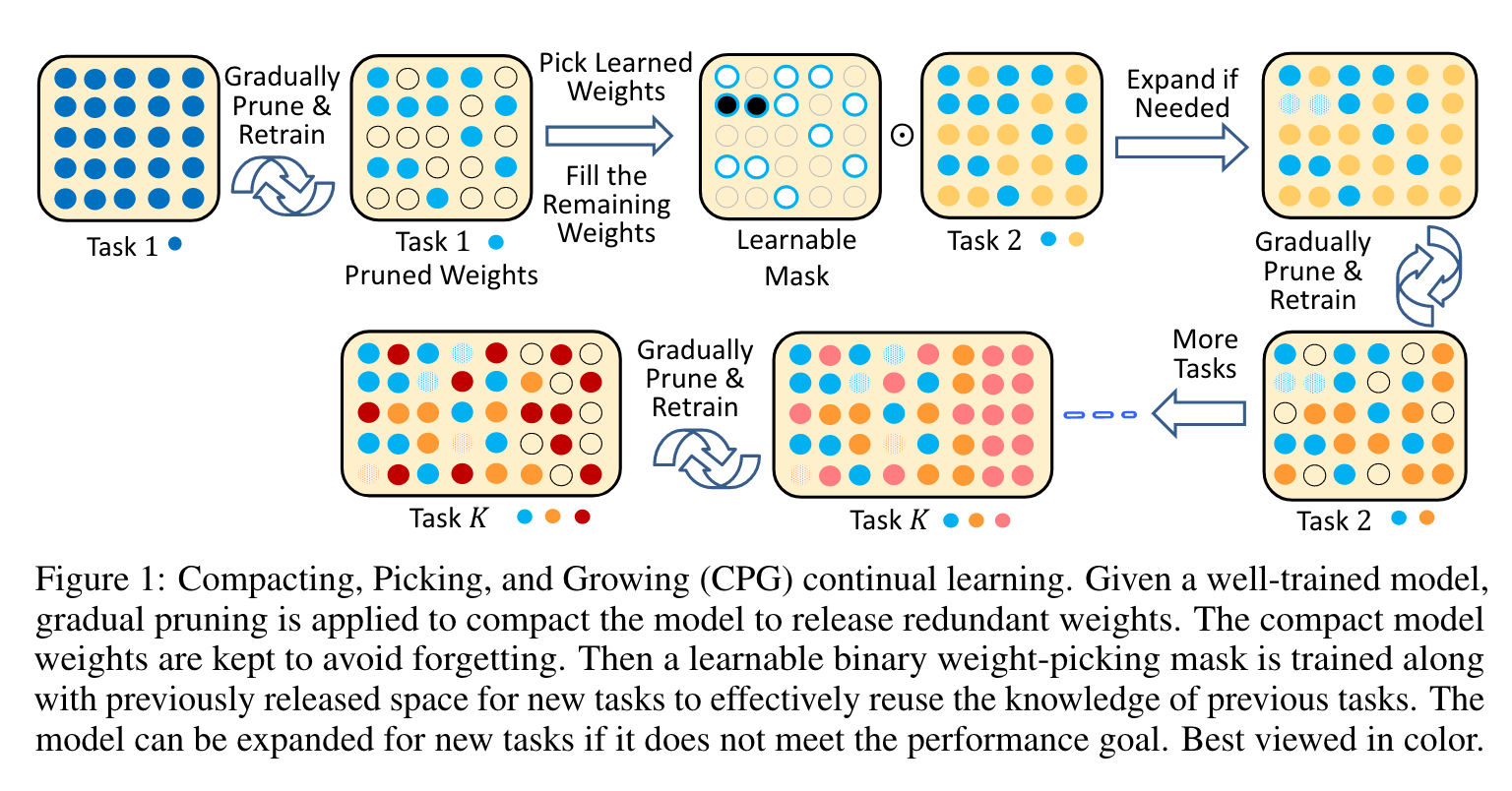
首先对模型进行剪枝,然后使用mask挑选对新任务同样重要的关键权重,联合之前释放的权重一起学习新任务。如果还未达到目标,可以通过在模型中增加滤波器或节点来扩展架构,之后重复渐进式地修改。
具体方法
task1
对模型进行渐进式修改。注意这不是一次性修剪权重到修剪率目标,而是删除一部分权重并重新训练模型以迭代恢复性能,直到达到修剪标准。经过逐步修剪后,模型权重可以分为两部分:一部分为任务1所保留;另一部分被释放,可以被后续任务所采用。
task k to k+1
假定在task k已经有一个模型可以处理task 1~k,设其权重为\(W_{1:k}^P\),task k释放的权重为\(W_k^E\)。在task k+1,要学的是一个Mask M,对\(W_{1:k}^P\)进行挑选。这里是用的是piggyback这篇论文的方法(Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights)学习一个实值mask,通过设置threshold得到二值化的M。M与释放的权重一起参与学习新的数据集。需要注意的是,由于二进制掩码M是不可微分的,在训练二进制掩码M时,我们在反向传播中更新实值掩码M;然后用阈值对M进行量化,并应用于前向传播。如果性能不能满足条件,模型架构可以增长以囊括更多的权重进行训练。注意M和\(W_k^E\)都是在调整的,而\(W_{1:k}^P\)是固定的以记忆旧任务。
Compaction of task k+1
M和\(W_k^E\)学好后,固定M的同时使用gradual pruning得到\(W_{k+1}^P\)以及\(W_{k+1}^E\)。

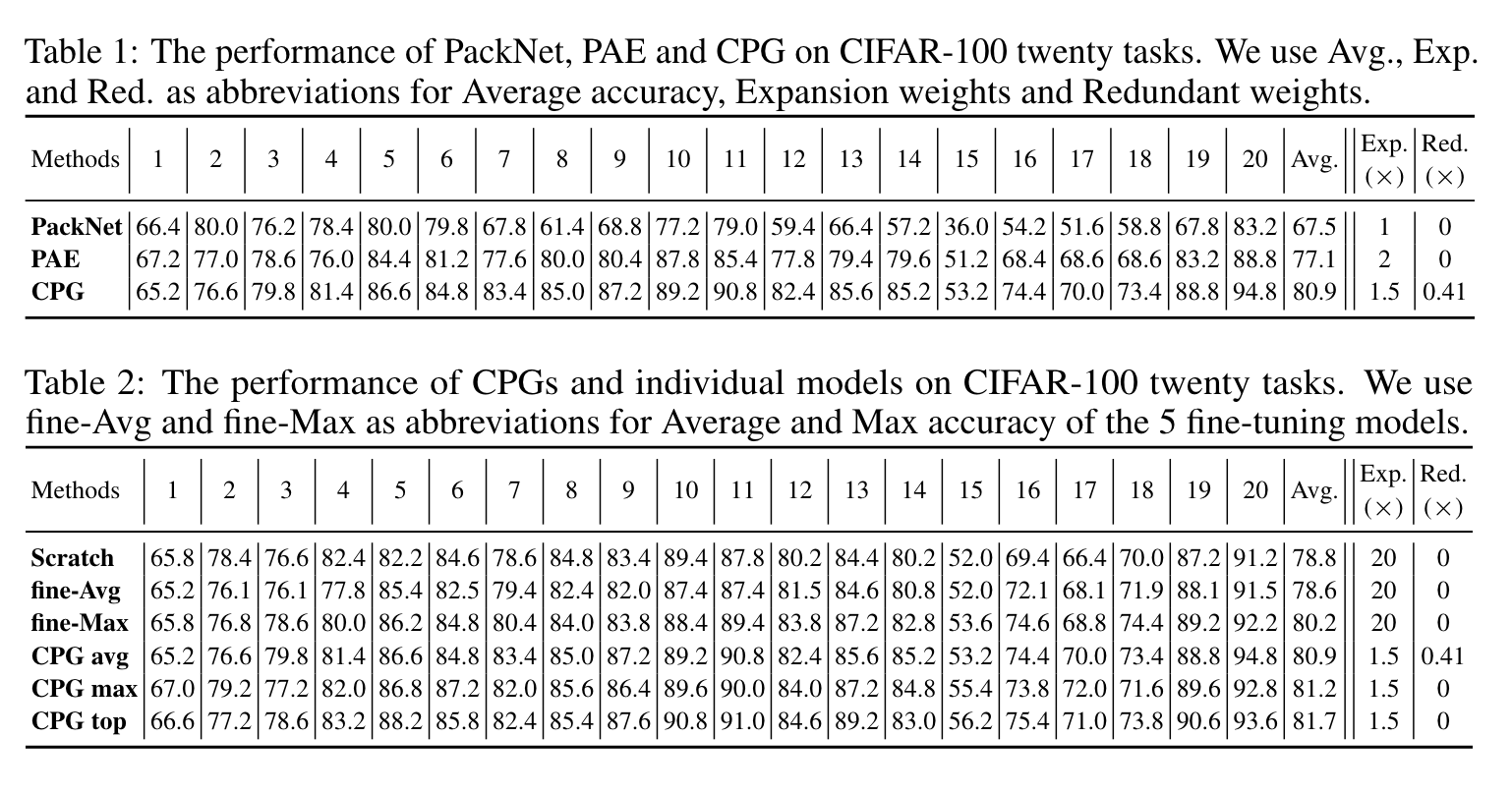
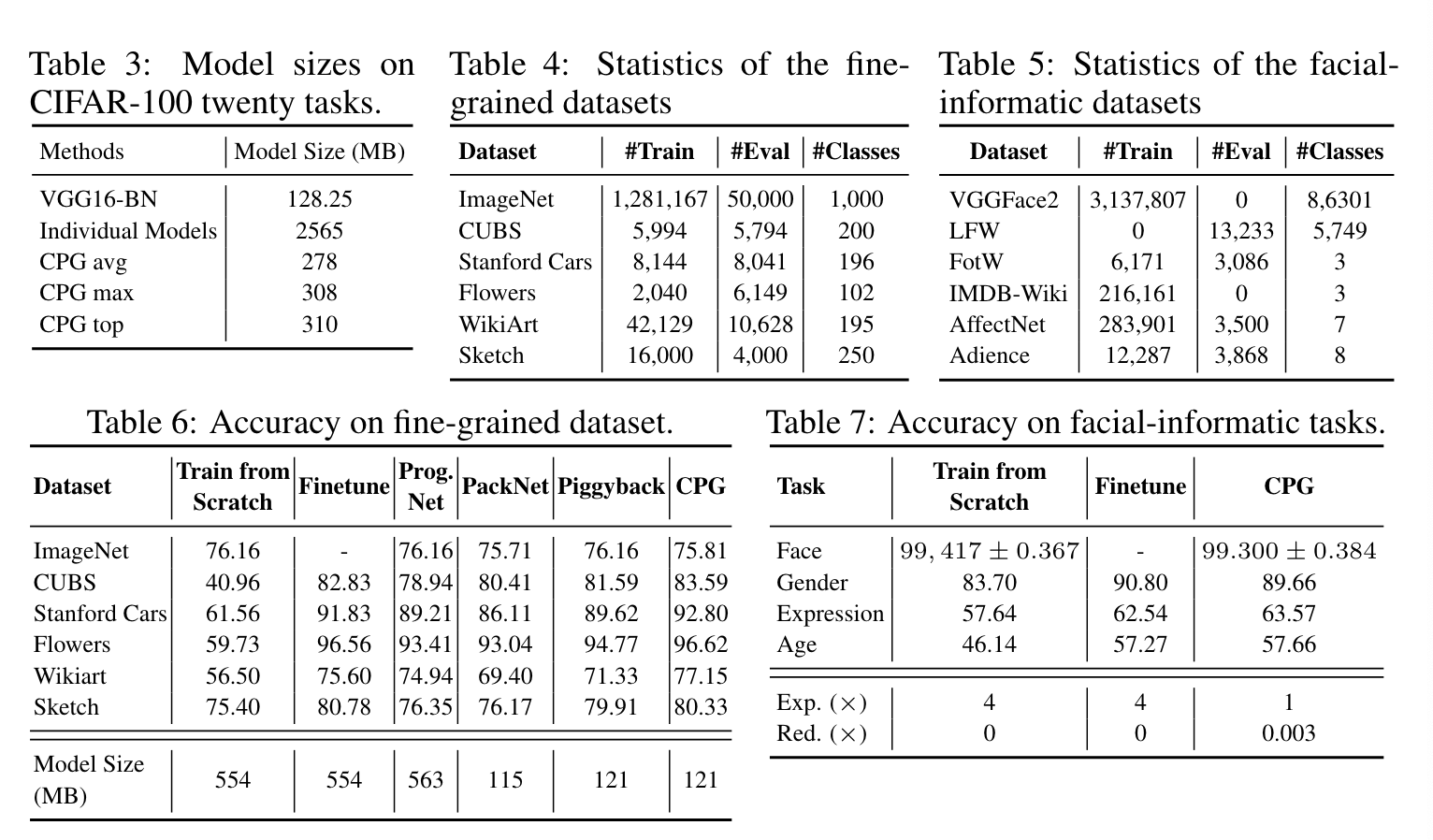
实验