目录
1. 数据处理 data process
Massachusetts数据为.tif或.tiff格式的文件。
是道路识别的遥感影像数据。
每一张image及其label都是1500 × 1500像素大小。
百度云链接:https://pan.baidu.com/s/1jNysFRDvRzH5bEx8fk-jzw
提取码:gr4i
数据集中的11128705_15.tiff及其对应的标签,因为在修改成png后无法正常使用,在实际使用过程中删除了,但在百度云盘里的未删除。请注意。
1.1. 类型转换 Raster to Png
不需要创建新的文件夹。
经过测试,.tiff图像可以直接改后缀为.png图像后仍然可用。
11128705_15.tiff更改成11128705_15.png后无法使用,在train-image文件夹中,已经将其和对应的label删除。
利用以下代码直接更改后缀.tiff或.tif为.png。
- image类是.tiff更改成.png
- label类是.tif更改成.png
针对不同的文件夹中的数据进行修改的时候,需要注意类型
import os
def replace_in_file_names(folder_path, old_str, new_str):
for filename in os.listdir(folder_path):
old_filename = os.path.join(folder_path, filename)
# 替换文件名中的指定字符串
new_filename = filename.replace(old_str, new_str)
# 使用替换的文件名构造新的完整路径
new_filepath = os.path.join(folder_path, new_filename)
# 重命名文件
os.rename(old_filename, new_filepath)
if __name__ == "__main__":
folder_path = r"D:\heao_Y23M10_model\Datasets\road_2\PNG\road_val_label" # 替换为文件夹的路径
old_str = "tif" # 要替换的字符串(image文件夹下是.tiff,label文件夹下是.tif)
new_str = "png" # 要替换为的字符串
replace_in_file_names(folder_path, old_str, new_str)
1.2. 边缘填充 Resize
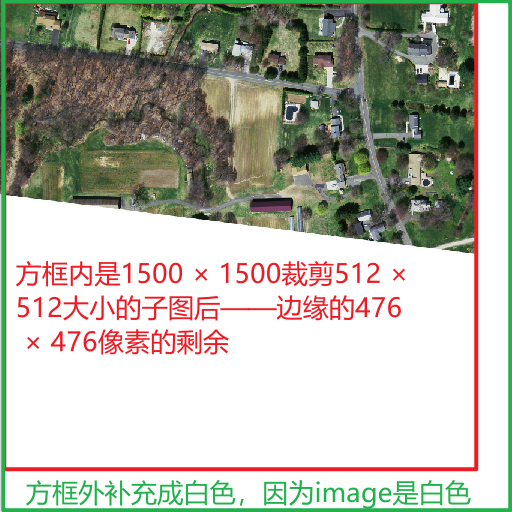
该道路影像是1500 × 1500大小的,博主目前使用的代码是针对512 × 整数倍的长宽图像进行裁剪的。多余的边角会被切掉。
导致的结果是1500 × 1500像素大小的图片裁剪后只能生成4张512 × 512大小的数据。
在预料中,即便边缘有一定的空缺,但是应该生成9张子图。
此外,需要注意image中的图片无图像区域填充的是255的白色,而label中的图片,无图像区域填充的是0的黑色。
| image | label |
|---|---|
 |
 |
因此决定按部就班的逐一进行图片的边缘填充,填充到512的3倍:1536 × 1536。
对每一个图片文件夹,都对应创建一个新的文件夹,来储存填充后的新图片。
1.2.1. 填充 Resize image
import os
from PIL import Image
def resize_image(image_path, target_width, target_height, output_folder):
"""将图像大小调整为目标宽度和高度,必要时用零填充。"""
image = Image.open(image_path)
width, height = image.size
# 计算所需的填充
pad_width = target_width - (width % target_width)
pad_height = target_height - (height % target_height)
# 用255填充图像
padded_image = Image.new('RGB', (width + pad_width, height + pad_height), (255, 255, 255))
padded_image.paste(image, (0, 0))
# 将填充的图像保存到输出文件夹
output_path = os.path.join(output_folder, os.path.basename(image_path))
padded_image.save(output_path)
def process_images_in_folder(input_folder, output_folder):
"""处理指定输入文件夹中的所有图像并保存到输出文件夹。"""
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
image_path = os.path.join(root, file)
width, height = Image.open(image_path).size
# 检查尺寸是否为 (512, 512) 的倍数
if width % width_height != 0 or height % width_height != 0:
# 调整图像大小并保存到输出文件夹
resize_image(image_path, width_height, width_height, output_folder)
print(f'调整大小并保存到 {output_folder}: {image_path}')
# 指定裁剪大小(可以设定成比128,256,512)
width_height = 512
# 指定输入文件夹
input_folder = r'D:\Datasets\road\source\road_train_image'
# 指定输出文件夹
output_folder = r'D:\Datasets\road\sorce_512Xint\train_image_512Xint'
# 调用函数执行
process_images_in_folder(input_folder, output_folder)
1.2.1. 填充 Resize label
import os
from PIL import Image
def resize_image(image_path, target_width, target_height, output_folder):
"""将图像大小调整为目标宽度和高度,必要时用零填充。"""
image = Image.open(image_path)
width, height = image.size
# 计算所需的填充
pad_width = target_width - (width % target_width)
pad_height = target_height - (height % target_height)
# 用0填充图像
padded_image = Image.new('RGB', (width + pad_width, height + pad_height), (0, 0, 0))
padded_image.paste(image, (0, 0))
# 将填充的图像保存到输出文件夹
output_path = os.path.join(output_folder, os.path.basename(image_path))
padded_image.save(output_path)
def process_images_in_folder(input_folder, output_folder):
"""处理指定输入文件夹中的所有图像并保存到输出文件夹。"""
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
image_path = os.path.join(root, file)
width, height = Image.open(image_path).size
# 检查尺寸是否为 (512, 512) 的倍数
if width % width_height != 0 or height % width_height != 0:
# 调整图像大小并保存到输出文件夹
resize_image(image_path, width_height, width_height, output_folder)
print(f'调整大小并保存到 {output_folder}: {image_path}')
# 指定裁剪大小(可以设定成比128,256,512)
width_height = 512
# 指定输入文件夹
input_folder = r'D:\Datasets\road\source\road_train_image'
# 指定输出文件夹
output_folder = r'D:\Datasets\road\sorce_512Xint\train_image_512Xint'
# 调用函数执行
process_images_in_folder(input_folder, output_folder)
1.3. 批量裁剪 Clip
原始图片是1500 × 1500大小。填充后为1536。其中image都在边缘填充白色,label都在边缘填充黑色。
一般深度学习模型采用256 × 256,512 × 512,1024 × 1024的大小。
本次代码复现采用512 × 512大小。
利用下述代码裁剪成没有重叠区域的大小,因为前期已经调整了图片为1536 × 1536像素大小,最后一张图一定会被合乎其理的裁剪成9张512 × 512大小的子图。
from PIL import Image
import os
import numpy as np
def crop_and_pad_images(input_folder, output_folder, target_width, target_height):
# 遍历文件夹下的所有文件
for filename in os.listdir(input_folder):
input_file_path = os.path.join(input_folder, filename)
# 判断是否为图片文件
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
try:
# 打开图片
with Image.open(input_file_path) as img:
width, height = img.size
# 计算裁剪的行数和列数
num_rows = height // target_height
num_cols = width // target_width
for i in range(num_rows):
for j in range(num_cols):
left = j * target_width
upper = i * target_height
right = left + target_width
lower = upper + target_height
# 裁剪图像
cropped_img = img.crop((left, upper, right, lower))
# 创建新图像并填充空白区域
padded_img = Image.new('RGB', (target_width, target_height), (0, 0, 0))
padded_img.paste(cropped_img, (0, 0))
# 构造新文件名
new_filename = f"{os.path.splitext(filename)[0]}_{i}_{j}.png"
output_file_path = os.path.join(output_folder, new_filename)
# 保存裁剪且填充后的图像
padded_img.save(output_file_path)
print(f'图片 {filename} 裁剪并填充成功,保存为 {new_filename}')
except Exception as e:
print(f'处理图片 {filename} 时发生错误: {str(e)}')
# 指定文件夹路径和输出文件夹路径
input_folder_path = r'D:\Datasets\road\sorce_512Xint\train_label_512Xint'
output_folder_path = r'D:\Datasets\road\clip_512\train_label_512'
# 指定裁剪后的目标长宽
target_width = 512
target_height = 512
# 调用函数裁剪并填充图片
crop_and_pad_images(input_folder_path, output_folder_path, target_width, target_height)
1.4. 波段缩减 3bands to 1band
对TransUnet作者的数据进行解析。
官方的npz文件中,label使用的是单波段的图像,而道路数据集中使用的是3通道的标签,同时,对背景和不同的类别使用0,1,2,···这样的序列值。
而道路数据集中的label背景是0,道路是255,同时是3个波段的。
因此需要对label图像处理,只保留一个波段,同时处理0和255的值分别为0和1的二值图。
import os
import cv2
import numpy as np
from pathlib import Path
def process_images(input_folder, output_folder):
# 如果输出文件夹不存在,创建它
Path(output_folder).mkdir(parents=True, exist_ok=True)
for filename in os.listdir(input_folder):
if filename.endswith('.png'):
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, filename)
# 读取图像
image = cv2.imread(input_path, cv2.IMREAD_UNCHANGED)
# 将像素值为255的替换为1
image[image == 255] = 1
# 仅保留第一个波段
output_image = image[:, :, 0]
# 保存处理后的图像
cv2.imwrite(output_path, output_image)
if __name__ == "__main__":
# 替换为实际的输入文件夹路径
input_folder = r"D:\Datasets\road\clip_512\train_label_512"
# 替换为实际的输出文件夹路径
output_folder = r"D:\Datasets\road\clip_512\train_label_512_1band"
process_images(input_folder, output_folder)
1.5. 筛选图像 Choose
在检查图形时发现,label和image并不是完全对应的,有些在image上是空白的区域,在label上仍然是有道路勾画的。
这种情况仅发生在train-image文件夹中。
推测:label是路网数据,可能不是实际手绘,而是取自测绘部门,并不能完全贴合。
为了在一定程度上避免这种情况造成的恶劣影响,我们对裁剪后的image进行了一些筛选。
无法依据label进行筛选;仅能在一定程度上消除影响。
- 如果裁剪后的image上像素值为255(即:全白)的点占据全部像素点比例的60%,则将这张影像和对应文件夹中的label删除。
import os
from PIL import Image
def calculate_pixel_percentage(image_path):
image = Image.open(image_path)
width, height = image.size
total_pixels = width * height
# 将图像转换为 RGB 模式(如果尚未)
if image.mode != 'RGB':
image = image.convert('RGB')
# 计算每个通道中值为 255 的像素数
count_channel_255 = sum(1 for pixel in image.getdata() if pixel == (255, 255, 255))
# 计算值为 255 的像素百分比
percentage_255 = (count_channel_255 / total_pixels) * 100
return percentage_255
def record_high_percentage_pngs(folder_path, output_file):
high_percentage_images = []
for filename in os.listdir(folder_path):
if filename.endswith(".png"):
image_path = os.path.join(folder_path, filename)
percentage_255 = calculate_pixel_percentage(image_path)
if percentage_255 > 60:
high_percentage_images.append((filename, percentage_255))
# 将信息写入输出文件
with open(output_file, 'w') as file:
for filename, percentage in high_percentage_images:
file.write(f"{filename}\n")
def read_file_names(filename):
"""
读取txt文档中的文件名列表
"""
file_names = []
with open(filename, 'r') as file:
for line in file:
file_names.append(line.strip())
return file_names
def delete_files(folder1, folder2, file_names):
"""
在两个文件夹中查找并删除文件
"""
successful_deletions = []
failed_deletions = []
for file_name in file_names:
try:
# 在第一个文件夹中查找并删除文件
file_path1 = os.path.join(folder1, file_name)
if os.path.exists(file_path1):
os.remove(file_path1)
successful_deletions.append("Image: " + file_name)
else:
failed_deletions.append("Image: " + file_name)
except Exception as e:
failed_deletions.append(f"Error deleting {file_name}: {str(e)}")
for file_name in file_names:
try:
# 在第二个文件夹中查找并删除文件
file_path2 = os.path.join(folder2, file_name)
if os.path.exists(file_path2):
os.remove(file_path2)
successful_deletions.append("Label: " + file_name)
else:
failed_deletions.append("Label: " + file_name)
except Exception as e:
failed_deletions.append(f"Error deleting {file_name}: {str(e)}")
return successful_deletions, failed_deletions
def main(folder1, folder2, folder_path, output_file):
record_high_percentage_pngs(folder_path, output_file)
# 读取txt文档中的文件名列表
file_names = read_file_names(output_file)
# 删除文件并处理异常
successful_deletions, failed_deletions = delete_files(folder1, folder2, file_names)
# 打印结果
print("Successfully deleted files:")
for file_name in successful_deletions:
print(file_name)
print("\nFailed to delete files:")
for file_name in failed_deletions:
print(file_name)
if __name__ == "__main__":
# 文件夹路径
# image图像的路径,也将使用它来计算一张image上空白区域的比例
folder_path1 = r"D:\Datasets\road_2\4_choice_test - Success Choice 测试成功\image"
# label图像的路径,也将根据txt文档中记录的文件名,同步的与image删除相对应的label图
folder_path2 = r"D:\Datasets\road_2\4_choice_test - Success Choice 测试成功\label"
# 输出image路径里空白像素大于60%的图片的名字
output_file = r"D:\Datasets\road_2\4_choice_test - Success Choice 测试成功\output1012_2.txt"
main(folder_path1, folder_path2, folder_path1, output_file)
1.6. 转换格式 Transform to npz
复现代码快速的原则是将个人数据尽可能转换成原始代码使用的格式。
这也是为何前期使用大量的进程将.tiff --> .png --> 512 X int倍.png --> 512*512.png --> image-3bands label-1band的处理原因。
import os
import numpy as np
from PIL import Image
# 获取文件夹下所有文件的文件名
def get_file_names_in_directory(directory):
file_names = []
for root, dirs, files in os.walk(directory):
for file in files:
file_names.append(file)
return file_names
# 拼接文件夹路径和文件名到新的列表中
def join_folder_and_file_names(folder_path, file_names):
# 初始化一个空列表来存放拼接后的完整路径
full_paths = []
# 使用os.path.join()拼接文件夹路径和文件名
for file_name in file_names:
full_path = os.path.join(folder_path, file_name)
full_paths.append(full_path)
return full_paths
# 调用函数读取PNG图像并转换为float32的NumPy数组
def read_png_image(filepath):
try:
# 读取PNG图像
image = Image.open(filepath)
# 将图像转换为float32类型的NumPy数组
image_array = np.array(image).astype(np.float32) / 1.0
return image_array
except Exception as e:
print("Error:", str(e))
return None
# 示例用法
if __name__ == "__main__":
# image文件夹路径
image_path = r"D:\Trnasformer\T02_STUnet\data\Satellite dataset Ⅰ (global cities)\image"
# label文件夹路径
label_path = r"D:\Trnasformer\T02_STUnet\data\Satellite dataset Ⅰ (global cities)\label"
# 保存npz文件的文件夹路径
npz_save_path = r"D:\Trnasformer\T02_STUnet\data\Satellite dataset Ⅰ (global cities)\npz_save_path"
# 读取所有文件的名字
file_names = get_file_names_in_directory(image_path)
# 计算列表的长度
list_length = len(file_names)
# 拼接image和label以及输出文件的完整路径
image_full_paths = join_folder_and_file_names(image_path, file_names)
label_full_paths = join_folder_and_file_names(label_path, file_names)
npz_save_paths = join_folder_and_file_names(npz_save_path, file_names)
for i in range(list_length):
# 读取图片中的数组
image_array = read_png_image(image_full_paths[i])
label_array = read_png_image(label_full_paths[i])
npz_file_name = npz_save_paths[i]
np.savez(npz_file_name, image=image_array, label=label_array)
if i > 0 and i % 50 == 0:
print(f"已经完成了 {i} 组图像的处理。")
print(f"已经完成了 {i} 组图像的处理。")
1.7. 读取列表 Read Files To List
npz文件的名字需要被读取到txt文档中(去除npz后缀)。
可以依据下述代码进行。
import os
def get_file_names_without_extension(directory):
file_names = []
for root, dirs, files in os.walk(directory):
for file in files:
# 去除后缀
file_name, _ = os.path.splitext(file)
file_names.append(file_name)
# 不去除后缀
# file_names.append(file)
return file_names
def write_to_txt(file_names, output_file):
with open(output_file, 'w') as f:
for file_name in file_names:
f.write(file_name + '\n')
# 示例用法
if __name__ == "__main__":
# 用于测试的文件夹路径
directory_path = r"D:\heao_Y23M10_model\Datasets\road_2\5_npz_files\test_npz"
# 获取文件夹下所有文件的文件名(不带后缀)
file_names = get_file_names_without_extension(directory_path)
# 输出到一个新文件夹
output_file_path = r"D:\heao_Y23M10_model\Datasets\road_2\6_npzFiles_txt\test_txt\test.txt"
if file_names:
# 将文件名写入txt文本
write_to_txt(file_names, output_file_path)
# print("不带扩展名的文件名写入:", output_file_path)
else:
print("未找到文件", output_file_path)