大家好,这次大表哥给大家分享的是PG的表和索引的膨胀。
首先,为什么会出现表和索引的膨胀?
总所周知, Postgres SQL 实现的MVCC的机制不同于 oracle , mysql innodb 的 undo tablespace 的机制。 表上所用的更新和删除等操作的行为,都不会实际的删除或修改,而是标记为死元祖 (dead rows or dead tuples)。
先做一个小的实验 用 extension pgstattuple 观测一下:
dbtest@[local:/tmp]:1992=#111446 create extension pgstattuple; CREATE EXTENSION
我们创建一张表,插入10000条记录。观察一下 dead tuple , 这个时候是 0
dbtest@[local:/tmp]:1992=#111446 create table tab1 (id int , name varchar(128)); CREATE TABLE dbtest@[local:/tmp]:1992=#111446 insert into tab1 select id, md5(id::varchar) from generate_series(1,10000) as id; INSERT 0 10000 dbtest@[local:/tmp]:1992=#111446 select * from pgstattuple('tab1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 688128 | 10000 | 610000 | 88.65 | 0 | 0 | 0 | 5776 | 0.84 (1 row)
我们尝试删除10条记录: 我们可以看到 dead_tuple_count = 10, dead_tuple_percent = 0.09 = 1- 10/10000 也是符合我们的预期的
dbtest@[local:/tmp]:1992=#111446 delete from tab1 where id <= 10; DELETE 10 dbtest@[local:/tmp]:1992=#111446 select * from pgstattuple('tab1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 688128 | 9990 | 609390 | 88.56 | 10 | 610 | 0.09 | 5776 | 0.84 (1 row)
我们再来创建一个索引,检查一下索引的膨胀:
dbtest@[local:/tmp]:1992=#111446 create index concurrently idx_name on tab1(name); CREATE INDEX
我们可以看到这个索引的 avg_leaf_density 是 89.27
avg_leaf_density 这个指标的含义是 索引树的密度, 这个值越低, 说明索引的膨胀度越大
dbtest@[local:/tmp]:1992=#111446 select * from pgstatindex('idx_name');
version | tree_level | index_size | root_block_no | internal_pages | leaf_pages | empty_pages | deleted_pages | avg_leaf_density | leaf_fragmentation
---------+------------+------------+---------------+----------------+------------+-------------+---------------+------------------+--------------------
4 | 1 | 606208 | 3 | 1 | 72 | 0 | 0 | 89.27 | 0
(1 row)
我们这次删除5000条记录,查看 avg_leaf_density
dbtest@[local:/tmp]:1992=#111446 delete from tab1 where id <= 5000;
查询索引的avg_leaf_density 变成了 44.98, 大致是 之前的一半
dbtest@[local:/tmp]:1992=#111446 select * from pgstatindex('idx_name');
version | tree_level | index_size | root_block_no | internal_pages | leaf_pages | empty_pages | deleted_pages | avg_leaf_density | leaf_fragmentation
---------+------------+------------+---------------+----------------+------------+-------------+---------------+------------------+--------------------
4 | 1 | 606208 | 3 | 1 | 72 | 0 | 0 | 44.98 | 0
(1 row)
我们可以运行 vacuum 的命令, 删除一下死的元祖,但是表和索引的存储空间不会释放给本地磁盘, 这也就是我们之前说的表和索引的膨胀:
dbtest@[local:/tmp]:1992=#111446 SELECT pg_size_pretty(pg_relation_size('tab1')) as table_size, pg_size_pretty(pg_relation_size('idx_name')) as index_size;
table_size | index_size
------------+------------
672 kB | 592 kB
(1 row)
dbtest@[local:/tmp]:1992=#111446 vacuum tab1;
VACUUM
dbtest@[local:/tmp]:1992=#111446 SELECT pg_size_pretty(pg_relation_size('tab1')) as table_size, pg_size_pretty(pg_relation_size('idx_name')) as index_size;
table_size | index_size
------------+------------
672 kB | 592 kB
(1 row)
运行完vacuum 之后, 所有的死元祖应该都被清除掉了:
我们看到 dead_tuple_len 被重置为 0
dbtest@[local:/tmp]:1992=#111446 select * from pgstattuple('tab1');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
688128 | 5000 | 305000 | 44.32 | 0 | 0 | 0 | 345292 | 50.18
(1 row)
虽然这部分存储标记不能够释放给磁盘, 但是可以给后操作的数据提供重复使用的存储空间。
vacuum full 虽然会回收磁盘的空间,但是会锁定整个表或者数据库,这个显然不是我们所期望的。
在了解了表和索引的膨胀后, 下一步 我们如何监控数据库,表,索引的膨胀呢?
下面的脚本可以通过官网的wiki 或者 github 上获取到:
监控脚本的SQL还是很复杂的,感谢PG社区的力量!
监控数据库级别的膨胀: https://wiki.postgresql.org/wiki/Show_database_bloat
SELECT
current_database(), schemaname, tablename, /*reltuples::bigint, relpages::bigint, otta,*/
ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::float/otta END)::numeric,1) AS tbloat,
CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::BIGINT END AS wastedbytes,
iname, /*ituples::bigint, ipages::bigint, iotta,*/
ROUND((CASE WHEN iotta=0 OR ipages=0 THEN 0.0 ELSE ipages::float/iotta END)::numeric,1) AS ibloat,
CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytesFROM (
SELECT
schemaname, tablename, cc.reltuples, cc.relpages, bs,
CEIL((cc.reltuples*((datahdr+ma-
(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)) AS otta,
COALESCE(c2.relname,'?') AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages,
COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta -- very rough approximation, assumes all cols
FROM (
SELECT
ma,bs,schemaname,tablename,
(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr,
(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2
FROM (
SELECT
schemaname, tablename, hdr, ma, bs,
SUM((1-null_frac)*avg_width) AS datawidth,
MAX(null_frac) AS maxfracsum,
hdr+(
SELECT 1+count(*)/8
FROM pg_stats s2
WHERE null_frac<>0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename
) AS nullhdr
FROM pg_stats s, (
SELECT
(SELECT current_setting('block_size')::numeric) AS bs,
CASE WHEN substring(v,12,3) IN ('8.0','8.1','8.2') THEN 27 ELSE 23 END AS hdr,
CASE WHEN v ~ 'mingw32' THEN 8 ELSE 4 END AS ma
FROM (SELECT version() AS v) AS foo
) AS constants
GROUP BY 1,2,3,4,5
) AS foo
) AS rs
JOIN pg_class cc ON cc.relname = rs.tablename
JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema'
LEFT JOIN pg_index i ON indrelid = cc.oid
LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid) AS smlORDER BY wastedbytes DESC
监控表级别的膨胀:
https://github.com/ioguix/pgsql-bloat-estimation/blob/master/table/table_bloat.sql
/* WARNING: executed with a non-superuser role, the query inspect only tables and materialized view (9.3+) you are granted to read.
* This query is compatible with PostgreSQL 9.0 and more
*/
SELECT current_database(), schemaname, tblname, bs*tblpages AS real_size,
(tblpages-est_tblpages)*bs AS extra_size,
CASE WHEN tblpages > 0 AND tblpages - est_tblpages > 0
THEN 100 * (tblpages - est_tblpages)/tblpages::float
ELSE 0
END AS extra_pct, fillfactor,
CASE WHEN tblpages - est_tblpages_ff > 0
THEN (tblpages-est_tblpages_ff)*bs
ELSE 0
END AS bloat_size,
CASE WHEN tblpages > 0 AND tblpages - est_tblpages_ff > 0
THEN 100 * (tblpages - est_tblpages_ff)/tblpages::float
ELSE 0
END AS bloat_pct, is_na
-- , tpl_hdr_size, tpl_data_size, (pst).free_percent + (pst).dead_tuple_percent AS real_frag -- (DEBUG INFO)
FROM (
SELECT ceil( reltuples / ( (bs-page_hdr)/tpl_size ) ) + ceil( toasttuples / 4 ) AS est_tblpages,
ceil( reltuples / ( (bs-page_hdr)*fillfactor/(tpl_size*100) ) ) + ceil( toasttuples / 4 ) AS est_tblpages_ff,
tblpages, fillfactor, bs, tblid, schemaname, tblname, heappages, toastpages, is_na
-- , tpl_hdr_size, tpl_data_size, pgstattuple(tblid) AS pst -- (DEBUG INFO)
FROM (
SELECT
( 4 + tpl_hdr_size + tpl_data_size + (2*ma)
- CASE WHEN tpl_hdr_size%ma = 0 THEN ma ELSE tpl_hdr_size%ma END
- CASE WHEN ceil(tpl_data_size)::int%ma = 0 THEN ma ELSE ceil(tpl_data_size)::int%ma END
) AS tpl_size, bs - page_hdr AS size_per_block, (heappages + toastpages) AS tblpages, heappages,
toastpages, reltuples, toasttuples, bs, page_hdr, tblid, schemaname, tblname, fillfactor, is_na
-- , tpl_hdr_size, tpl_data_size
FROM (
SELECT
tbl.oid AS tblid, ns.nspname AS schemaname, tbl.relname AS tblname, tbl.reltuples,
tbl.relpages AS heappages, coalesce(toast.relpages, 0) AS toastpages,
coalesce(toast.reltuples, 0) AS toasttuples,
coalesce(substring(
array_to_string(tbl.reloptions, ' ')
FROM 'fillfactor=([0-9]+)')::smallint, 100) AS fillfactor,
current_setting('block_size')::numeric AS bs,
CASE WHEN version()~'mingw32' OR version()~'64-bit|x86_64|ppc64|ia64|amd64' THEN 8 ELSE 4 END AS ma,
24 AS page_hdr,
23 + CASE WHEN MAX(coalesce(s.null_frac,0)) > 0 THEN ( 7 + count(s.attname) ) / 8 ELSE 0::int END
+ CASE WHEN bool_or(att.attname = 'oid' and att.attnum < 0) THEN 4 ELSE 0 END AS tpl_hdr_size,
sum( (1-coalesce(s.null_frac, 0)) * coalesce(s.avg_width, 0) ) AS tpl_data_size,
bool_or(att.atttypid = 'pg_catalog.name'::regtype)
OR sum(CASE WHEN att.attnum > 0 THEN 1 ELSE 0 END) <> count(s.attname) AS is_na
FROM pg_attribute AS att
JOIN pg_class AS tbl ON att.attrelid = tbl.oid
JOIN pg_namespace AS ns ON ns.oid = tbl.relnamespace
LEFT JOIN pg_stats AS s ON s.schemaname=ns.nspname
AND s.tablename = tbl.relname AND s.inherited=false AND s.attname=att.attname
LEFT JOIN pg_class AS toast ON tbl.reltoastrelid = toast.oid
WHERE NOT att.attisdropped
AND tbl.relkind in ('r','m')
GROUP BY 1,2,3,4,5,6,7,8,9,10
ORDER BY 2,3
) AS s
) AS s2
) AS s3
-- WHERE NOT is_na
-- AND tblpages*((pst).free_percent + (pst).dead_tuple_percent)::float4/100 >= 1
ORDER BY schemaname, tblname;
监控索引级别的膨胀: https://github.com/ioguix/pgsql-bloat-estimation/blob/master/btree/btree_bloat.sql
-- WARNING: executed with a non-superuser role, the query inspect only index on tables you are granted to read.
-- WARNING: rows with is_na = 't' are known to have bad statistics ("name" type is not supported).
-- This query is compatible with PostgreSQL 8.2 and after
SELECT current_database(), nspname AS schemaname, tblname, idxname, bs*(relpages)::bigint AS real_size,
bs*(relpages-est_pages)::bigint AS extra_size,
100 * (relpages-est_pages)::float / relpages AS extra_pct,
fillfactor,
CASE WHEN relpages > est_pages_ff
THEN bs*(relpages-est_pages_ff)
ELSE 0
END AS bloat_size,
100 * (relpages-est_pages_ff)::float / relpages AS bloat_pct,
is_na
-- , 100-(pst).avg_leaf_density AS pst_avg_bloat, est_pages, index_tuple_hdr_bm, maxalign, pagehdr, nulldatawidth, nulldatahdrwidth, reltuples, relpages -- (DEBUG INFO)
FROM (
SELECT coalesce(1 +
ceil(reltuples/floor((bs-pageopqdata-pagehdr)/(4+nulldatahdrwidth)::float)), 0 -- ItemIdData size + computed avg size of a tuple (nulldatahdrwidth)
) AS est_pages,
coalesce(1 +
ceil(reltuples/floor((bs-pageopqdata-pagehdr)*fillfactor/(100*(4+nulldatahdrwidth)::float))), 0
) AS est_pages_ff,
bs, nspname, tblname, idxname, relpages, fillfactor, is_na
-- , pgstatindex(idxoid) AS pst, index_tuple_hdr_bm, maxalign, pagehdr, nulldatawidth, nulldatahdrwidth, reltuples -- (DEBUG INFO)
FROM (
SELECT maxalign, bs, nspname, tblname, idxname, reltuples, relpages, idxoid, fillfactor,
( index_tuple_hdr_bm +
maxalign - CASE -- Add padding to the index tuple header to align on MAXALIGN
WHEN index_tuple_hdr_bm%maxalign = 0 THEN maxalign
ELSE index_tuple_hdr_bm%maxalign
END
+ nulldatawidth + maxalign - CASE -- Add padding to the data to align on MAXALIGN
WHEN nulldatawidth = 0 THEN 0
WHEN nulldatawidth::integer%maxalign = 0 THEN maxalign
ELSE nulldatawidth::integer%maxalign
END
)::numeric AS nulldatahdrwidth, pagehdr, pageopqdata, is_na
-- , index_tuple_hdr_bm, nulldatawidth -- (DEBUG INFO)
FROM (
SELECT n.nspname, i.tblname, i.idxname, i.reltuples, i.relpages,
i.idxoid, i.fillfactor, current_setting('block_size')::numeric AS bs,
CASE -- MAXALIGN: 4 on 32bits, 8 on 64bits (and mingw32 ?)
WHEN version() ~ 'mingw32' OR version() ~ '64-bit|x86_64|ppc64|ia64|amd64' THEN 8
ELSE 4
END AS maxalign,
/* per page header, fixed size: 20 for 7.X, 24 for others */
24 AS pagehdr,
/* per page btree opaque data */
16 AS pageopqdata,
/* per tuple header: add IndexAttributeBitMapData if some cols are null-able */
CASE WHEN max(coalesce(s.null_frac,0)) = 0
THEN 2 -- IndexTupleData size
ELSE 2 + (( 32 + 8 - 1 ) / 8) -- IndexTupleData size + IndexAttributeBitMapData size ( max num filed per index + 8 - 1 /8)
END AS index_tuple_hdr_bm,
/* data len: we remove null values save space using it fractionnal part from stats */
sum( (1-coalesce(s.null_frac, 0)) * coalesce(s.avg_width, 1024)) AS nulldatawidth,
max( CASE WHEN i.atttypid = 'pg_catalog.name'::regtype THEN 1 ELSE 0 END ) > 0 AS is_na
FROM (
SELECT ct.relname AS tblname, ct.relnamespace, ic.idxname, ic.attpos, ic.indkey, ic.indkey[ic.attpos], ic.reltuples, ic.relpages, ic.tbloid, ic.idxoid, ic.fillfactor,
coalesce(a1.attnum, a2.attnum) AS attnum, coalesce(a1.attname, a2.attname) AS attname, coalesce(a1.atttypid, a2.atttypid) AS atttypid,
CASE WHEN a1.attnum IS NULL
THEN ic.idxname
ELSE ct.relname
END AS attrelname
FROM (
SELECT idxname, reltuples, relpages, tbloid, idxoid, fillfactor, indkey,
pg_catalog.generate_series(1,indnatts) AS attpos
FROM (
SELECT ci.relname AS idxname, ci.reltuples, ci.relpages, i.indrelid AS tbloid,
i.indexrelid AS idxoid,
coalesce(substring(
array_to_string(ci.reloptions, ' ')
from 'fillfactor=([0-9]+)')::smallint, 90) AS fillfactor,
i.indnatts,
pg_catalog.string_to_array(pg_catalog.textin(
pg_catalog.int2vectorout(i.indkey)),' ')::int[] AS indkey
FROM pg_catalog.pg_index i
JOIN pg_catalog.pg_class ci ON ci.oid = i.indexrelid
WHERE ci.relam=(SELECT oid FROM pg_am WHERE amname = 'btree')
AND ci.relpages > 0
) AS idx_data
) AS ic
JOIN pg_catalog.pg_class ct ON ct.oid = ic.tbloid
LEFT JOIN pg_catalog.pg_attribute a1 ON
ic.indkey[ic.attpos] <> 0
AND a1.attrelid = ic.tbloid
AND a1.attnum = ic.indkey[ic.attpos]
LEFT JOIN pg_catalog.pg_attribute a2 ON
ic.indkey[ic.attpos] = 0
AND a2.attrelid = ic.idxoid
AND a2.attnum = ic.attpos
) i
JOIN pg_catalog.pg_namespace n ON n.oid = i.relnamespace
JOIN pg_catalog.pg_stats s ON s.schemaname = n.nspname
AND s.tablename = i.attrelname
AND s.attname = i.attname
GROUP BY 1,2,3,4,5,6,7,8,9,10,11
) AS rows_data_stats
) AS rows_hdr_pdg_stats
) AS relation_stats
ORDER BY nspname, tblname, idxname;
从监控中发现了膨胀率高的表和索引之后, 想从磁盘上彻底释放物理存储空间,可以选择如下的方式
1)vacuum full 表名 – 会有独占锁,阻塞所有的DDL,DML 的命令操作,需要数据库的维护窗口, 有downtime 的要求。 一般不会建议生产这样做
2)Cluster 命令: 基于指定的索引作为聚簇重新对标进行编排。 示例语法: CLUSTER employees USING employees_ind;
这个操作也是需要独占锁的,会阻塞该表上的所有DDL,DML.
3)recreate table or reindex : 相当于重建表和索引。
如果选择重建表的话 是类似于 create table tab_new as select * from tab_old, 然后在 创建相关索引,最后进行表名的 rename 切换。还需注意表的权限:需要重新赋权。
另外这个也是需要应用系统的维护窗口时间的。
如果选择重建索引的话, 类似于 reindex CONCURRENTLY index_name, 需要注意的是需要2倍的索引存储空间,进行online的索引重建。
4) pg_repack 插件: 相比于vacuum 和 cluster 等需要独占锁的重量级的操作,pg_repack 是一个相对轻量级的在线去除表和索引膨胀的工具。
不会对目标表进行锁定。
下面我们来看一下 pg_repack 这个 extension , 项目首页的地址: https://reorg.github.io/pg_repack/
pg_repack 是项目 pg_reorg 的一个分支,很遗憾pg_reorg 这个项目在2011年的时候停摆了。
目前 pg_repack 支持的PG 版本是 PostgreSQL version PostgreSQL 9.4, 9.5, 9.6, 10, 11, 12, 13
目前来说 PG 14, 以及最新的PG 15版本 是不支持的, 安装的时候会报错: 指针类型的错误
INFRA [postgres@wqdcsrv3352 pg_repack]# make
make[1]: Entering directory `/opt/postgreSQL/pg_repack/bin'
gcc -std=gnu99 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -I/opt/postgreSQL/pg15/include -DREPACK_VERSION=1.4.7 -I. -I./ -I/opt/postgreSQL/pg15/include/postgresql/server -I/opt/postgreSQL/pg15/include/postgresql/internal -D_GNU_SOURCE -c -o pgut/pgut-fe.o pgut/pgut-fe.c
pgut/pgut-fe.c: In function ‘get_username’:
pgut/pgut-fe.c:652:2: warning: implicit declaration of function ‘getpwuid’ [-Wimplicit-function-declaration]
pw = getpwuid(geteuid());
^
pgut/pgut-fe.c:652:5: warning: assignment makes pointer from integer without a cast [enabled by default]
pw = getpwuid(geteuid());
^
pgut/pgut-fe.c:653:16: error: dereferencing pointer to incomplete type
ret = (pw ? pw->pw_name : NULL);
^
make[1]: *** [pgut/pgut-fe.o] Error 1
make[1]: Leaving directory `/opt/postgreSQL/pg_repack/bin'
make: *** [all] Error 2

我们从git-hub上下载一下项目: git clone https://github.com/reorg/pg_repack.git
INFRA [postgres@wqdcsrv3352 postgreSQL]# git clone https://github.com/reorg/pg_repack.git
Cloning into 'pg_repack'...
remote: Enumerating objects: 3399, done.
remote: Counting objects: 100% (102/102), done.
remote: Compressing objects: 100% (53/53), done.
remote: Total 3399 (delta 58), reused 81 (delta 49), pack-reused 3297
Receiving objects: 100% (3399/3399), 1.03 MiB | 0 bytes/s, done.
Resolving deltas: 100% (2138/2138), done.
安装项目: 这里需要在root用户下 手动的export 一下PG_HOME 的环境变量, 使得 pg_config 可以读到 PG 实例的安装路径
INFRA [postgres@wqdcsrv3352 pg_repack]# make
INFRA [postgres@wqdcsrv3352 pg_repack]# sudo su -
Last login: Mon Jul 18 15:51:58 CST 2022 on pts/2
INFRA [root@wqdcsrv3352 ~]# export PG_HOME=/opt/postgreSQL/pg12
INFRA [root@wqdcsrv3352 ~]# cd /opt/postgreSQL/pg_repack
INFRA [root@wqdcsrv3352 pg_repack]# export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$PG_HOME/bin
INFRA [root@wqdcsrv3352 pg_repack]# make install
安装完毕后, 我们模拟一张表 数据量1000000, 删除500000 数据测试一下:
postgres@[local:/tmp]:1999=#54672 create table tab (id int not null primary key , name varchar(100));
CREATE TABLE
postgres@[local:/tmp]:1999=#54672 create index concurrently idx_name on tab(name);
CREATE IND
Load 进入 1000000 数据,查看存储空间的使用情况:
postgres@[local:/tmp]:1999=#54672 insert into tab select id , md5(id::varchar) from generate_series(1,1000000) as id;
INSERT 0 1000000
postgres@[local:/tmp]:1999=#54672 SELECT pg_size_pretty(pg_relation_size('tab')) as table_size, pg_size_pretty(pg_relation_size('tab_pkey')) as index_size_pk, pg_size_pretty(pg_relation_size('idx_name')) as index_size_name;
table_size | index_size_pk | index_size_name
------------+---------------+-----------------
65 MB | 21 MB | 73 MB
(1 row)
我们删除 800000 的数据, 再次观察存储空间:符合我们的预期,不会从磁盘释放空间
postgres@[local:/tmp]:1999=#54672 delete from tab where id <= 800000;
DELETE 800000
postgres@[local:/tmp]:1999=#54672 SELECT pg_size_pretty(pg_relation_size('tab')) as table_size, pg_size_pretty(pg_relation_size('tab_pkey')) as index_size_pk, pg_size_pretty(pg_relation_size('idx_name')) as index_size_name;
table_size | index_size_pk | index_size_name
------------+---------------+-----------------
65 MB | 21 MB | 73 MB
(1 row)
我们查看表和索引的膨胀率: (参考上面的超级长的大SQL查询)
表的膨胀率: extra_pct (膨胀率) = 80.00959923206143 , 膨胀的空间 54624256/1024*1024= 52MB
current_database | schemaname | tblname | real_size | extra_size | extra_pct | fillfactor | bloat_size | bloat_pct | is_na
------------------+--------------------+-------------------------+-----------+------------+--------------------+------------+------------+--------------------+-------
postgres | public | tab | 68272128 | 54624256 | 80.00959923206143 | 100 | 54624256 | 80.00959923206143 | f
索引的膨胀率: (参考上面的超级长的大SQL查询)
idx_name (膨胀率) = 86.26444159178433 , 膨胀的空间 66060288/10241024= 63MB
tab_pkey (膨胀率) = 82.040072859745 , 膨胀的空间 18448384/10241024= 17.59MB
current_database | schemaname | tblname | idxname | real_size | extra_size | extra_pct | fillfactor | bloat_size | bloat_pct
| is_na
------------------+------------+------------------+-----------------------------------------------+-----------+------------+---------------------+------------+------------+-----------------
----+-------
postgres | public | tab | idx_name | 76578816 | 66060288 | 86.26444159178433 | 90 | 64946176 | 84.80958493795
464 | f
postgres | public | tab | tab_pkey | 22487040 | 18448384 | 82.040072859745 | 90 | 17997824 | 80.03642987249
545 | f
计算完膨胀的空间后,我们来 repack 一下这个表和上面的索引:
postgres@[local:/tmp]:1999=#60868 CREATE EXTENSION pg_repack;
CREATE EXTENSION
INFRA [postgres@wqdcsrv3352 bin]# ./pg_repack -k -d postgres -t tab -h /tmp -p 1999
INFO: repacking table "public.tab"
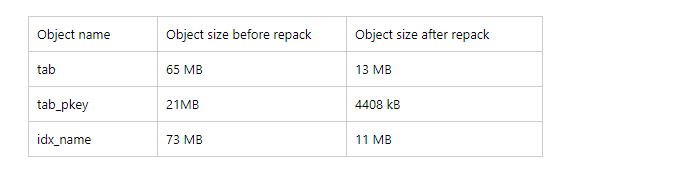
收集完膨胀的空间后,我们再来查看一下:明显收缩后的空间正如之前我们之前预期计算的膨胀空间一样
postgres@[local:/tmp]:1999=#62527 SELECT pg_size_pretty(pg_relation_size('tab')) as table_size, pg_size_pretty(pg_relation_size('tab_pkey')) as index_size_pk, pg_size_pretty(pg_relation_size('idx_name')) as index_size_name;
table_size | index_size_pk | index_size_name
------------+---------------+-----------------
13 MB | 4408 kB | 4408 kB
(1 row)
最后我们在简单地说一下 repack 的工作原理:
repack 实际上是创建了一张临时表, 并在原始表上创建触发器捕获数据变化,同步到临时表中, 并在临时表中重新创建索引,最后进行临时表和原始表的切换。
工作原理和mysql 的 pt-online-schema-change 的工具是十分类似的.
由于是触发器的同步原理,行级触发器的性能是最大的瓶颈,虽然可以在线repack, 我们依然要选择一个业务低峰期来处理。
转载自:https://www.modb.pro/db/439013
标签:index,END,tuple,ELSE,索引,pg,膨胀,size,PG From: https://www.cnblogs.com/lovezhr/p/17736186.html