作者:尚卓燃(PsiACE)
澳门科技大学在读硕士,Databend 研发工程师实习生
Apache OpenDAL(Incubating) Committer

随着架构的不断迭代和更新,大数据系统的查询目标也从大吞吐量查询逐步转移转向快速的交互式查询,对于查询的及时响应提出了更高要求。许多企业的数仓/数据湖中都有 PB 级的数据,其中绝大多数都属于旧有系统中的历史数据,很少更新,移动起来很麻烦,重新组织元数据也需要花费大量的时间。需要解决的问题是:如何在保证现有的数据和元数据不变的情况下加速查询。

上图是一个典型的使用 Databend 加速 Hive 查询的架构。用户使用 trino 、Spark 等引擎将数据纳入 Hive 进行管理,数据的存放位置则位于 S3 、GCS 、HDFS 等存储服务之中。引入 Databend 可以带来更好的查询性能。
和 trino 以及大多数支持 Hive Catalog / Connector 的查询引擎一样,Databend 可以复用 Hive 除了运行时(查询引擎)之外的其他组件,包括用于管理文件和底层存储的存储服务和管理 SQL 表到文件和目录映射的 Hive MetaStore 。
Databend 中的数据按三层进行组织:catalog -> database -> table ,catalog 作为数据最大一层,会包含所有的数据库和表。通过 CREATE CATALOG 语句,用户可以轻松创建 Hive Catalog 。在执行查询时,需要按 <catalog>.<database>.<table> 的格式指定到表。
SELECT * FROM <catalog>.<database>.<table>;
通过这种形式,用户无需向 Databend 中导入数据,就可以直接查询位于 Hive/Iceberg Catalog 中的数据,并获得 Databend 的性能保证。
Workshop :使用 Databend 加速 Hive 查询
接下来,让我们通过两个例子,了解 Databend 是如何加速不同存储服务下的 Hive 查询的。
使用 HDFS 存储
Hive + HDFS 的实验环境可以使用 https://github.com/PsiACE/databend-workshop/tree/main/hive-hdfs 中的环境搭建
docker-compose up -d
接下来,让我们一起准备数据:
- 进入 hive-server ,使用 beeline 连接:
docker-compose exec hive-server bash
beeline -u jdbc:hive2://localhost:10000
- 创建数据库、表和数据,注意,需要以 Parquet 格式存储:
CREATE DATABASE IF NOT EXISTS abhighdb;
USE abhighdb;
CREATE TABLE IF NOT EXISTS alumni(
alumni_id int,
first_name string,
middle_name string,
last_name string,
passing_year int,
email_address string,
phone_number string,
city string,
state_code string,
country_code string
)
STORED AS PARQUET;
INSERT INTO abhighdb.alumni VALUES
(1,"Rakesh","Rahul","Pingle",1994,"[email protected]",9845357643,"Dhule","MH","IN"),
(2,"Abhiram","Vijay","Singh",1994,"[email protected]",9987654354,"Chalisgaon","MH","IN"),
(3,"Dhriti","Anay","Rokade",1996,"[email protected]",9087654325,"Nagardeola","MH","IN"),
(4,"Vimal","","Prasad",1995,"[email protected]",9876574646,"Kalwadi","MH","IN"),
(5,"Kabir","Amitesh","Shirode",1996,"[email protected]",9708564367,"Malegaon","MH","IN"),
(6,"Rajesh","Sohan","Reddy",1994,"[email protected]",8908765784,"Koppal","KA","IN"),
(7,"Swapnil","","Kumar",1994,"[email protected]",8790654378,"Gurugram","HR","IN"),
(8,"Rajesh","","Shimpi",1994,"[email protected]",7908654765,"Pachora","MH","IN"),
(9,"Rakesh","Lokesh","Prasad",1993,"[email protected]",9807564775,"Hubali","KA","IN"),
(10,"Sangam","","Mishra",1994,"[email protected]",9806564775,"Hubali","KA","IN"),
(11,"Sambhram","Akash","Attota",1994,"[email protected]",7890678965,"Nagpur","MH","IN");
SELECT * FROM abhighdb.alumni;

由于 HDFS 支持需要使用 libjvm.so 和 Hadoop 的若干 Jar 包,请确保你安装了正确的 JDK 环境并配置相关的环境变量:
export JAVA_HOME=/path/to/java
export LD_LIBRARY_PATH=${JAVA_HOME}/lib/server:${LD_LIBRARY_PATH}
export HADOOP_HOME=/path/to/hadoop
export CLASSPATH=/all/hadoop/jar/files
参考 Deploying a Standalone Databend ,使用带有 HDFS 特性的 Databend 分发(databend-hdfs-*),部署一个单节点的 Databend 实例。
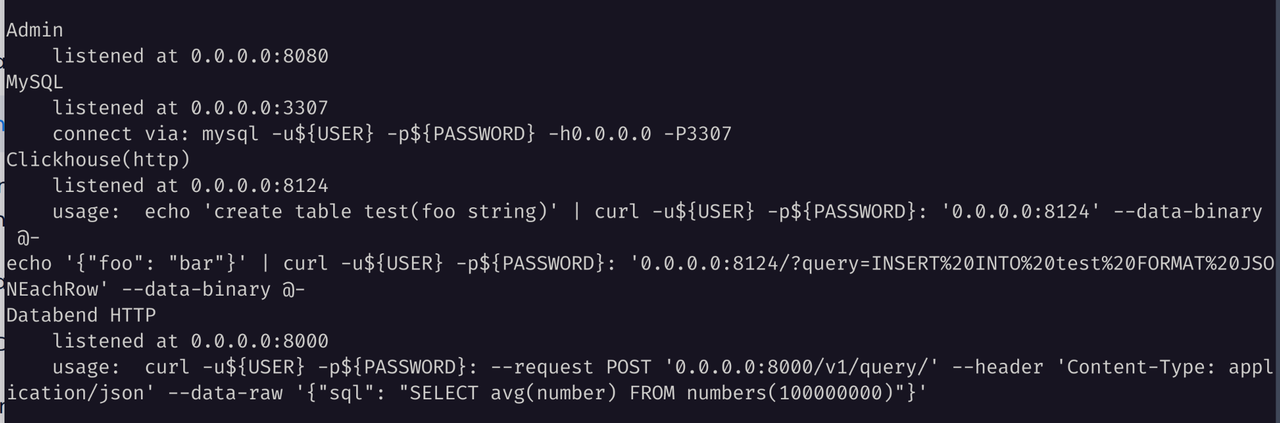
通过 BendSQL 连接这个 Databend 实例,然后创建对应的 Hive Catalog ,记得要通过 CONNECTION 字段为其配置对应的存储后端:
CREATE CATALOG hive_hdfs_ctl TYPE = HIVE CONNECTION =(
METASTORE_ADDRESS = '127.0.0.1:9083'
URL = 'hdfs:///'
NAME_NODE = 'hdfs://localhost:8020'
);
在上面的语句中,我们创建了一个底层存储使用 HDFS 的 Hive Catalog:
-
通过
TYPE指定创建 Hive 类型的 Catalog 。 -
CONNECTION用于指定 HIVE 相关的存储/元数据访问信息,可以阅读 Docs | Connection Parameters 了解更多相关信息。METASTORE_ADDRESS对应 Hive MetaStore 的地址URL对应 HDFS 的 PathNAME_NODE则对应 HDFS 的 Name Node 地址
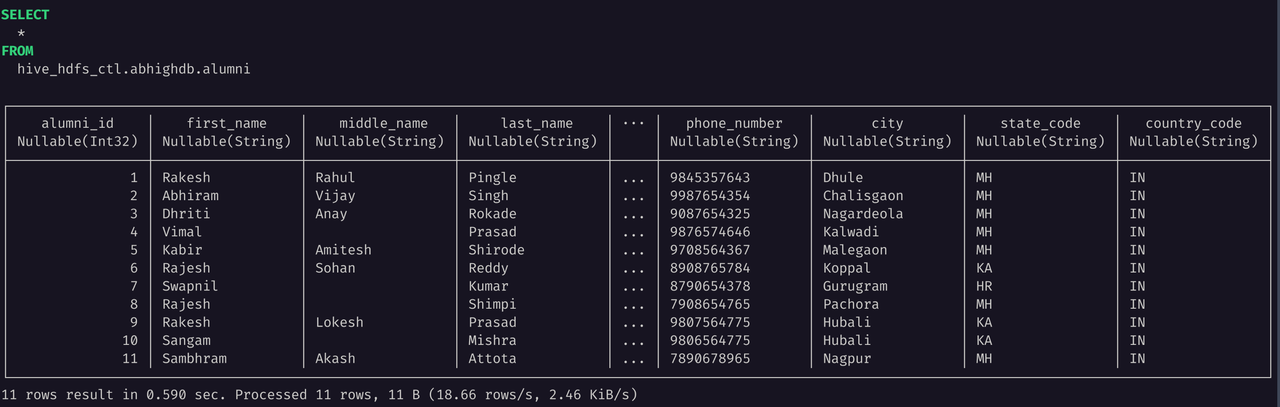
让我们尝试运行一个简单的 SELECT 查询,验证其是否能够正常工作:
SELECT * FROM hive_hdfs_ctl.abhighdb.alumni;
使用 S3-like 对象存储
Trino + Hive + MinIO 的实验环境可以使用 https://github.com/sensei23/trino-hive-docker/ 进行搭建。
cd docker-compose
docker build -t my-hive-metastore .
docker-compose up -d
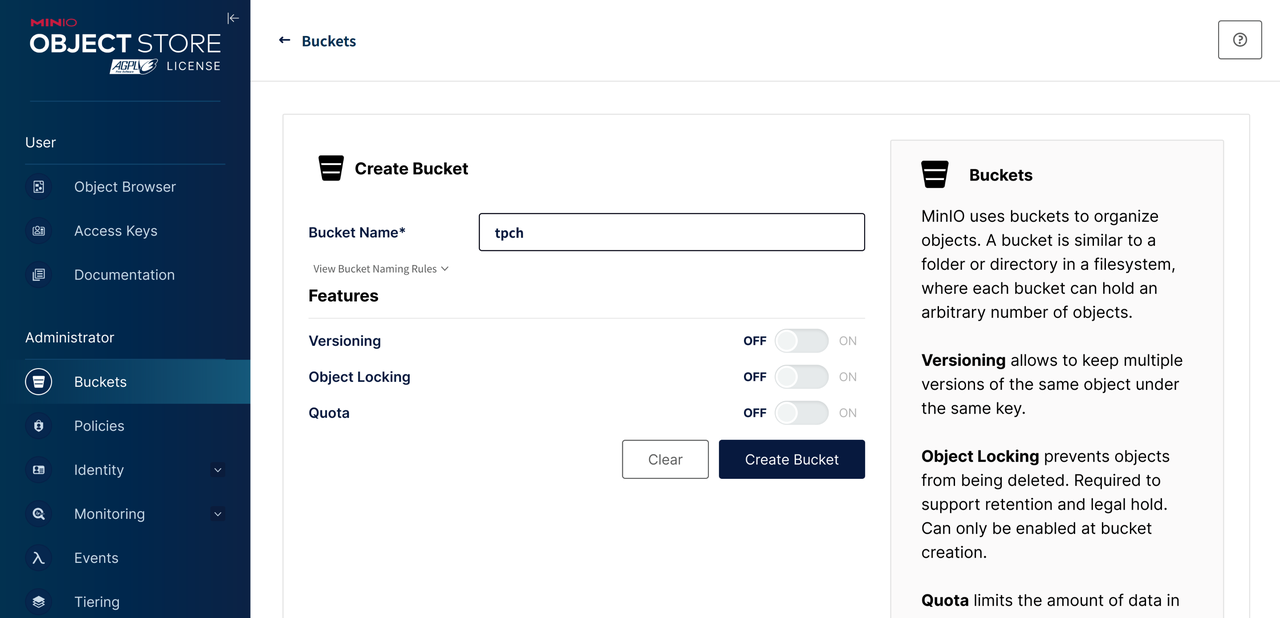
在执行完 docker-compose up -d 等前置步骤后,先进入 MinIO 控制面板,创建一个名为 tpch 的 Bucket 。
运行下述命令可以打开 trino 命令行工具:
docker container exec -it docker-compose-trino-coordinator-1 trino
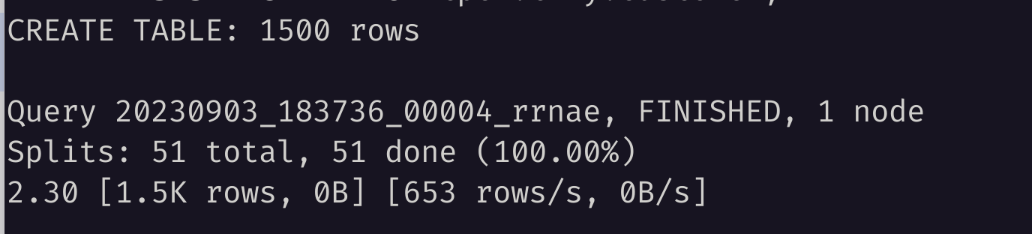
接着创建一个小型的 TPCH 客户表。注意,为了满足 Databend 使用要求,这里需要使用 Parquet 格式:
CREATE SCHEMA minio.tpch
WITH (location = 's3a://tpch/');
CREATE TABLE minio.tpch.customer
WITH (
format = 'PARQUET',
external_location = 's3a://tpch/customer/'
)
AS SELECT * FROM tpch.tiny.customer;
查询对应的 Hive 元数据,可以看到像下面这样的信息:
DB_ID | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME
-------+---------------------------+----------+------------+------------+-----------
1 | file:/user/hive/warehouse | default | public | ROLE | hive
3 | s3a://tpch/ | tpch | trino | USER | hive
参考 Deploying a Standalone Databend 部署一个单节点的 Databend 实例。
通过 BendSQL 连接这个 Databend 实例,然后创建对应的 Hive Catalog ,记得要通过 CONNECTION 字段为其配置对应的存储后端:
CREATE CATALOG hive_minio_ctl
TYPE = HIVE
CONNECTION =(
METASTORE_ADDRESS = '127.0.0.1:9083'
URL = 's3://tpch/'
AWS_KEY_ID = 'minio'
AWS_SECRET_KEY = 'minio123'
ENDPOINT_URL = 'http://localhost:9000'
);
在上面的语句中,我们创建了一个底层存储使用 MinIO 的 Hive Catalog:
-
通过
TYPE指定创建 Hive 类型的 Catalog 。 -
CONNECTION用于指定 HIVE 相关的存储/元数据访问信息,可以阅读 Docs | Connection Parameters 了解更多相关信息。METASTORE_ADDRESS对应 Hive MetaStore 的地址URL则对应 MinIO 的 Bucket 或者 PathAWS_KEY_ID和AWS_SECRET_KEY则对应访问时的校验,这里使用了 MinIO 服务的用户名和密码ENDPOINT_URL是 MinIO 对象存储服务的 API 端点
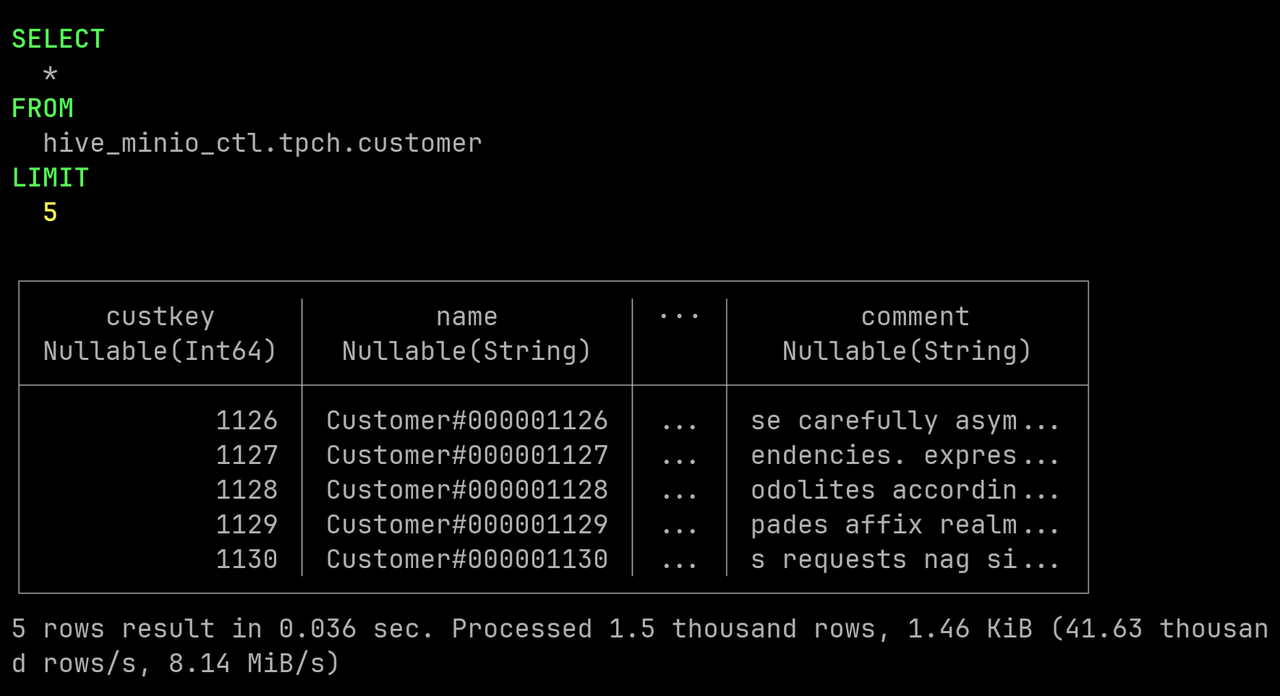
让我们尝试运行一个简单的 SELECT 查询,验证其是否能够正常工作:
SELECT * FROM hive_minio_ctl.tpch.customer LIMIT 5;
提示
- 要使用 SQL 语句创建带有多种存储支持的 Hive Catalog,推荐使用 v1.2.100-nightly 及以后版本。
- 不再需要从 toml 文件进行配置就可以获得多源数据目录能力。
- 如果需要获取 HDFS 存储服务支持,则需要部署或者编译带有 HDFS 特性的 Databend ,比如 databend-hdfs-v1.2.100-nightly-x86_64-unknown-linux-gnu.tar.gz 。
- 对于 Hive Catalog ,Databend 目前只支持查询 Parquet 格式的数据,且只支持 SELECT,不支持其他 DDL 、DML 和 UDFs 。
- Databend 的语法与 Hive 并不完全兼容,关于 SQL 兼容性相关的内容,可以查看 Docs | SQL Conformance 。