问题背景
公司里有很多需要跑批数据的场景,这些数据几十万到几千万不等,目前我们采用的是分页查询,但是分页查询有个深度分页问题,上百万的数据就会查询的很慢
常规解决方案
- 全量查询
- 分页查询
- 流式查询
- 游标查询
1. 全量查询
默认情况下,全量查询的话系统会把所有结果集存储在内存中,在数据库中准备了大概200w的数据:
<select id="listUser" resultType="com.sun.ddd.infra.po.User">
select * from user
</select>
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("全量查询");
List<User> users = userService.listUser();
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + users.size());
}
全量查询:21757:代码行数:2778523
利用JDK自带的java VisualVM监控全量查询时的内存占用情况

- 可以很明显的看出
200w的数据一次性查询占用总体内存1500MB,这个内存占用还是很大的,如果还有其他服务在运行,很容易导致OOM
2. 分页查询
为了解决全量查询占用内存过大,可能导致OOM问题,我们可以选择使用分页查询,这样就不会导致内存溢出问题了
@Override
public List<User> pageUser(Integer pageNum, Integer pageSize) {
pageNum = (pageNum - 1) * pageSize;
return userDao.pageUser(pageNum, pageSize);
}
<select id="pageUser" resultType="com.sun.ddd.infra.po.User">
select * from user limit #{pageNum},#{pageSize}
</select>
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("分页查询");
int pageCount = 0;
for (int i = 1; i < 1000; i++) {
List<User> users1 = userService.pageUser(i, 2000);
pageCount = pageCount + users1.size();
}
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + pageCount);
}
分页查询:285343:代码行数:1998000
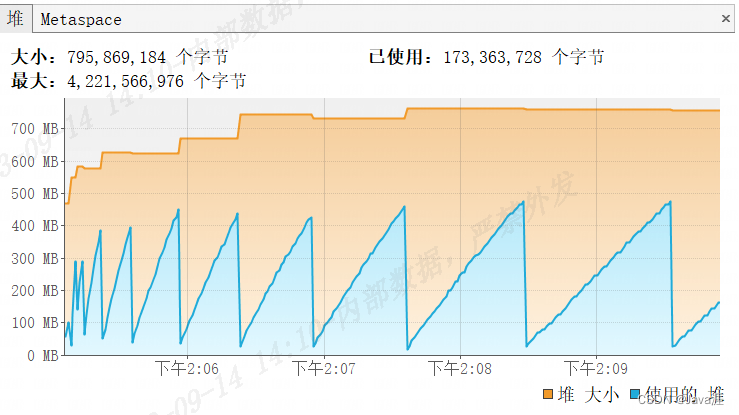
- 使用分页后,查询内存使用情况,最多占用内存不到
500MB,是全量查询占用内存的1/3不到,但是由于深度分页和多次与数据库连接的缘故,导致整个查询时间很长,长达280s,如果数据更多点查询时间则更多
3. 流式查询
那有没有什么方式,可以查的又快,占用内存又小呢?答案当然是有的了
客户端 JDBC 发起 SQL 查询,等待服务端准备数据。MySQL 服务端会向 JDBC 代表的客户端内核源源不断的输送数据,直到客户端请求 Socket 缓冲区满,这时的 MySQL服务端会阻塞。对于 JDBC 客户端而言,数据每次读取都是从本机器的内核缓冲区,所以性能会更快一些。类似服务端向客户端不断push的过程
是否使用流式的标志:
/**
* We only stream result sets when they are forward-only, read-only, and the
* fetch size has been set to Integer.MIN_VALUE
*
* @return true if this result set should be streamed row at-a-time, rather
* than read all at once.
*/
protected boolean createStreamingResultSet() {
return ((this.query.getResultType() == Type.FORWARD_ONLY) && (this.resultSetConcurrency == java.sql.ResultSet.CONCUR_READ_ONLY)
&& (this.query.getResultFetchSize() == Integer.MIN_VALUE));
}
其中我们只要关注this.query.getResultFetchSize() == Integer.MIN_VALUE,对应xml配置就是fetchSize="-2147483648"
<select id="listUserByStream" fetchSize="-2147483648" resultType="com.sun.ddd.infra.po.User">
select * from user
</select>
这里mapper接口不需要返回值,因为数据都存储在ResultHandler<User>中了
void listUserByStream(ResultHandler<User> handler);
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("流式查询");
AtomicInteger totalCount = new AtomicInteger(0);
userService.listUserByStream(context -> {
// 处理查询结果
context.getResultObject();
totalCount.incrementAndGet();
});
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + totalCount.get());
}
流式查询:9967:代码行数:2778523
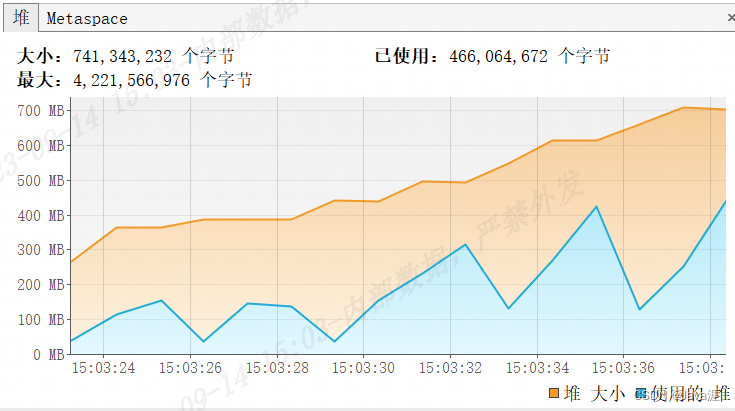
-
同样是
200w数据,可以明显看出查询时间只要9s多,占用内存也保持在500MB之内4. 游标查询
客户端
JDBC发起SQL查询,等待服务端准备数据。服务端数据准备完成后,进行数据传输,它允许应用程序在数据库服务器上打开一个游标并按需检索数据,而不是一次性获取整个结果集,类似客户端向服务端分批pull的过程。mapper接口层接收参数方式使用Cursor<User>Cursor<User> listUserByCursor();<select id="listUserByCursor" fetchSize="-2147483648" resultType="com.sun.ddd.infra.po.User"> select * from user </select>@Test @Transactional public void test() { StopWatch stopWatch = new StopWatch(); stopWatch.start("游标查询"); AtomicInteger totalCountCursor = new AtomicInteger(0); Cursor<User> users2 = userService.listUserByCursor(); for (User user : users2) { totalCountCursor.incrementAndGet(); } stopWatch.stop(); System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + totalCountCursor.get()); }由于Cursor是一条条查,所以会关闭会话,需要在方法上加@Transactional即可
游标查询:9813:代码行数:2778523
-
从测试结果来看,查询
200w条数据时间跟流式查询差不多,占用的内存也不到500MB
总结:
| 查询方式 | 数据条数 | 查询时间 | 占用内存 |
|---|---|---|---|
| 全量查询 | 2778523 | 21757 | 1600MB |
| 分页查询 | 1998000 | 285343 | 500MB |
| 流式查询 | 2778523 | 9967 | 450MB |
| 游标查询 | 2778523 | 9813 | 550MB |
推荐使用流式查询,游标查询还跟指定数据库有关
标签:分页,StopWatch,大批量,查询,stopWatch,全量,mybatis,内存 From: https://www.cnblogs.com/sun2020/p/17702696.html