引言
如果您仔细分析过任何一个网站的请求日志,您肯定会发现一些可疑的流量,那可能就是爬虫流量。根据Imperva发布的《2023 Imperva Bad Bot Report》在2022年的所有互联网流量中,47.4%是爬虫流量。与2021年的42.3%相比,增长了5.1%。在这些爬虫流量中,30.2%是恶意爬虫,比2021年的27.7%增长了2.5%。
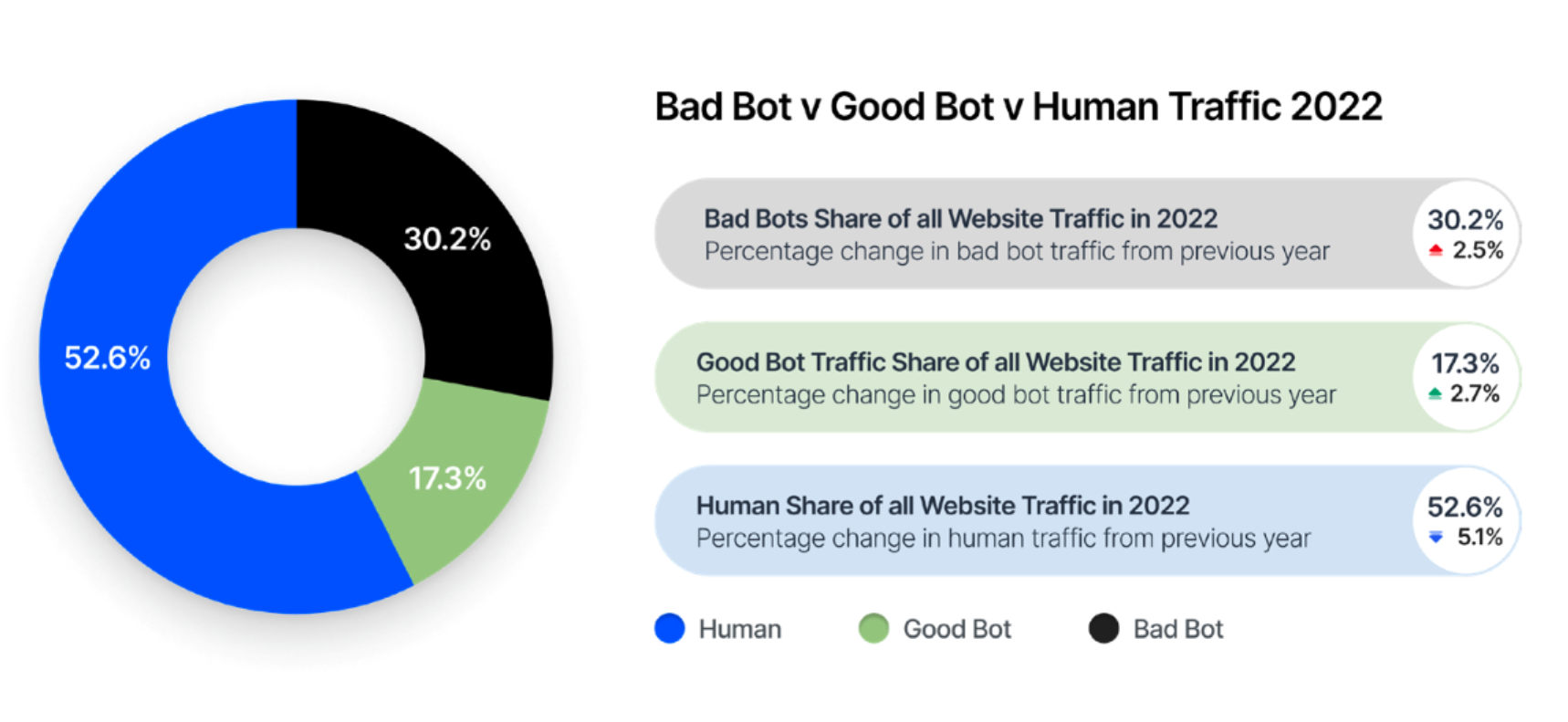
从国内外公开的数据中可以得出,恶意爬虫几乎出现在各个行业,无论是传统行业、泛互联网,还是政企、金融等,都各种程度遭受着爬虫的攻击,并且爬虫流量还在逐年增长。
大部分正常的爬虫可以帮助我们提高生产力,而恶意的爬虫不仅会造成数据泄漏还会影响正常用户体验。合适的反爬服务可识别恶意爬虫并拦截,京东云WAF的BOT管理提供了多种爬虫防护功能。
恶意爬虫的危害
爬虫(Web Crawler),又称网络爬虫、网络蜘蛛、网页蜘蛛,是一种自动化程序或脚本,用于在互联网上自动地获取网页内容,并从中提取信息。
爬虫分为合法爬虫和非法爬虫或恶意爬虫。合法爬虫是遵守网络道德和法律规定,以合法、合规和友好的方式运行的网络爬虫。这些爬虫在进行数据采集和信息获取时,遵循网站的robots.txt协议,尊重网站的隐私政策和使用条款,以及遵守相关的法律法规。合法爬虫的目的通常是为了收集网站上公开可见的信息,并且爬取的频率和速率是合理且可控的。这些爬虫的使用符合网站的访问规则,不会对网站造成严重的带宽压力或资源浪费。例如平时我们用的百度、必应等搜索引擎就离不开爬虫,搜索引擎爬虫每天会在网络上爬取大量的网页进行分析处理收收录,当用户通过关键词搜索时,就会按照一定的排序把相关的网页快照展现给用户。
恶意爬虫是一类不遵守网络道德和法律规定,以非法、破坏性或有害的方式运行的网络爬虫。这些爬虫通常不遵循网站的 robots.txt 协议、不尊重网站的隐私政策,以及不遵守网站的使用条款和服务协议。恶意爬虫的目的可能包括但不限于:
- 漏洞探测:攻击者利用爬虫程序扫描网站寻找漏洞,利用漏洞可实现网站提权安装后门等。
- 数据盗取:攻击者部署爬虫非法的方式获取网站的敏感数据、个人信息、商业机密等,可用于欺诈、垃圾邮件、身份盗窃等不良用途。
- 刷票、薅羊毛:攻击者通过爬虫程序抢优惠券、秒杀商品等,影响活动效果。密码撞库:大规模暴力破解或撞击密码,获取用户账户的访问权限,对网站用户的账户安全造成严重威胁。
- 暴力破解:攻击者利用大规模僵死网络,高速、大规模攻击网站,导致服务器过载、带宽浪费,影响网站的正常运行。
综上,恶意爬虫对网站和企业影响严重,轻则影响网站正常运行重则影响企业正常运营。因此,通过部署反爬服务阻止恶意爬虫请求,保护网站免受威胁非常重要。京东云WAF Bot管理提供了多种爬虫防护手段,可有效帮你应对各种爬虫。
恶意爬虫防护——京东云WAF Bot管理
京东云WAF Bot管理支持对爬虫程序进行甄别分类,并采取针对性的流量管理策略,例如,放行搜索引擎蜘蛛流量,对恶意爬取商品信息、秒杀价格、库存信息等核心数据进行阻断,还可以应对恶意机器人程序爬取带来的资源消耗、查询业务数据等问题。
京东云WAF提供了常见爬虫UA库,提供11大类上百种商业爬虫防护,可快速高效拦截这类爬虫。
京东云WAF提供了恶意IP惩罚,结合Web攻击防护利用大数据算法,可及时识别并拦截恶意IP扫描行为,有效防护漏扫描、文件遍历等爬虫行为。
京东云WAF反爬虫引擎利用算法和模型自动学习并分析网站请求流量,提供了宽松、正常、严格3种等级的防护模式,并支持配置配置观察、人机交互、拦截返回自定义页面等,可有效防护数据类爬虫和刷券类爬虫。
京东云WAF提供了账户安全,通过提取请求中的账号和密码自动分析,可有效防护弱密码探测、暴力破解和撞库攻击。
京东云WAF提供了IDC威胁情报,可拦截云上有过恶意行为的IP访问;伪造蜘蛛情报,可拦截伪装成搜索引擎蜘蛛的爬虫请求。
京东云WAF提供了伪造UA评分,可识别恶意爬虫伪装成浏览器的请求行为。
京东云WAF提供了自定义BOT规则,支持多种条件叠加、同时还可以叠加前端技术、叠加威胁情报,结合多维度频次统计,可灵活支持多种业务场景下的爬虫行为,为攻防对抗提供了可配性。
2023年H1,京东云WAF帮助云上多个客户防护了上亿次爬虫攻击,攻击的峰值QPS达到20W+/s。攻击的手段和目的也多种多样,有挂小区基站IP池的、有伪装成正常用户的、有常态化扫描探测的、有刷优惠券的、有刷特价商品的、有爬商品价格的。
前段时间云WAF有个客户发优惠券,刚开始的时候刷子利用公有云的函数服务和云主机刷券,客户开启云WAF的IDC威胁情报轻松应对;刷子升级了策略使用了小区基站IP池伪装成Chrome浏览器用户大量的请求优惠券接口,指导客户开启了反爬虫引擎并配置了自定义Bot规则,平时的峰值QPS只有2K,发券时候峰值QPS打到了11W。5分钟进来1405W请求,云WAF拦截了1401W。其中被反爬虫引擎识别了59%,被自定义BOT规则拦截了38%,被威胁情报拦截了3%,识别并拦截恶意爬虫率达到99.7%。
总结
互联网上一半的流量来自于爬虫,如果您的网站没发现爬虫行为或者您的网站正遭受恶意爬虫攻击,那么您可以试试云WAF的爬虫管理,不仅可以帮您发现爬虫行为还可以帮您防护爬虫攻击。详细可以参考:官网文档。
标签:网站,WAF,爬虫,恶意,防护,京东 From: https://www.cnblogs.com/Jcloud/p/17681856.html作者:京东科技 李文强
来源:京东云开发者社区 转载请注明来源