一 概述
XGBoost提供梯度提升树(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题,相同的代码可以在主要分布式环境运行(Apache Hadoop,Apache Spark,Apache Flink)。
系统优化:
- 并行计算:支持并行计算。
- 树剪枝:用贪心算法来选择最佳分裂点,然后开始剪枝。
- 硬件优化:有效利用硬件资源。
算法增项:
- 正则化:防止过拟合。
- 稀疏意识:根据训练损失自动“学习”最佳缺失值并更有效地处理数据中不同类型的稀疏模式。
- 加权分位数草图:采用分布式加权分位数草图算法,有效地找到加权数据集中的最优分裂点。
- 交叉验证:每次迭代时都带有内置的交叉验证方法。
二 XGBoost简介
1 模型和参数
(1)模型
监督学习中的模型通常是指给定输入 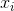 如何去预测输出
如何去预测输出 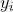 的数学结构。
的数学结构。
例:常见的线性模型

(2)参数
参数是模型需要从数据中学习的未确定部分。在线性回归问题中,参数是系数  。 通常使用
。 通常使用 
来表示参数。
2 目标函数:训练损失 + 正则
(1)概述
基于对
的不同理解,可以得到不同的问题,比如回归,分类,排序等。
目标函数以明确学习任务和相应的学习目标,如:reg:linear(回归:线性回归)、binary:logistic(二分类:逻辑二分类)。
评估指标:rmse、auc。
目标函数:L为误差函数, 
为正则化项

注:误差函数:模型预测与实际的误差;正则化项:树复杂度的惩罚。
(2)RMSE(均方根误差)
RMSE的值越小(具体情况和数据分布有关),表示模型的预测能力越好。

假设我们的测试数据集包含 5 个样本,其真实值和预测值如下:
| 真实值 | 预测值 |
|---|---|
| 200000 | 202000 |
| 250000 | 248000 |
| 300000 | 300000 |
| 350000 | 345000 |
| 400000 | 400000 |

(3)AUC(Area Under the Curve)
AUC 的取值范围在0到1之间,越接近1表示模型性能越好,越接近0.5表示模型的预测能力与随机猜测相当,小于 0.5 表示模型性能较差。
假设我们有 10 个样本,其中 4 个样本为正样本(点击),6个样本为负样本(未点击),使用模型对这些样本进行预测,并得到了每个样本属于正样本的概率。我们将这些样本按照预测概率从高到低排序,然后根据预测概率的排名计算 AUC。
例如,我们得到了以下 10 个样本的预测概率和实际标签:
| 预测概率 | 实际标签 | 排序 | 正样本排名之和 |
|---|---|---|---|
| 0.05 | 0 | 1 | 0 |
| 0.1 | 0 | 2 | 0 |
| 0.2 | 1 | 3 | 3 |
| 0.3 | 0 | 4 | 3 |
| 0.4 | 0 | 5 | 3 |
| 0.5 | 1 | 6 | 9 |
| 0.6 | 0 | 7 | 9 |
| 0.7 | 0 | 8 | 9 |
| 0.8 | 1 | 9 | 18 |
| 0.9 | 1 | 10 | 28 |

注:rank为正样本的排名和,m为正样本数量,n为负样本数量。
(4)正则化项

总的原则是我们想要一个 predictive(可预测)和 simple(简单)的模型。 两者之间的权衡也被称为机器学习中的 bias-variance tradeoff(偏差-方差权衡)。
-
损失函数 -> 拟合训练数据 -> bias较小 -> 防止欠拟合;
-
正则化 -> 简单的模型 + 额外参数 -> 拟合训练数据 -> 防止过拟合;
Bias 可理解为假设我们有无限多数据的时候,可以训练出最好的模型所拿到的误差。
Variance 是实际情况我们只有有限数据,其中随机性带来的误差。
3 Tree Ensembles(树集成)
树集成模型是一组 classification and regression trees (CART)。
案例:分类是否有人喜欢电脑游戏


树集成:多棵树的预测加到一起

数学公式表达:

K表示树的数目, f是函数空间 F 中的一个函数,FF表示CART的所有可能集合。
优化目标函数:

4 增量训练
Xgboost所要学习的就是这些 fi方法,每个方法中定义树的结构以及叶子节点的分数。这比传统最优化问题要更难,传统最优化问题我们可以通过梯度来解决。而且我们无法在一次训练所有的树。
使用增量(additive)训练的方式:每一步我们都是在前一步的基础上增加一棵树,而新增的这棵树是为修复上一颗树的不足。

经过泰勒展开并简化后的目标函数:

引入正则化函数后的目标函数:

树分裂:


在每次迭代中首先计算 gᵢ(损失函数的一阶微分)、hᵢ(损失函数的二阶微分) ,並使用贪婪算法计算 Gain 並找出最优分支做新增,并对负 Gain 的分支做剪枝。
注1:Gj为一阶梯度累加,Hj为二阶梯度累加(也叫cover,样本覆盖率)。
注2:构建树后,XGBoost 会执行一个可选的“修剪”步骤,从底部(叶子所在的位置)开始一直向上到根节点,查看增益是否低于 gamma,低于gamma将会被裁剪。
5 AllReduce
XGBoost Rabit是基于AllReduce规约开发的分布式计算框架。它基于消息传递接口(Message Passing Interface,MPI)和全局同步原语,允许在多台计算机上并行执行 XGBoost 的训练任务。Rabit 提供了跨节点通信、任务调度和数据分布等功能,使得 XGBoost 可以高效地利用分布式计算资源。


Rabit AllReduce支持对连续内存单元简单的sum max min 操作,也支持自定义的 reduce 操作来对不同节点中的类的数据成员合并。xgboost 的分布式算法主要用到了自定义的 reduce 操作来合并计算特征候选分割点的统计量,以及合并由候 选分割点得到的区间内样本的统计量。
所以,xgboost的num_workers最大为executor核心数*executor最大数量。
| spark环境 | executor核心数 | executor最大数量 |
|---|---|---|
| Spark2 | spark.executor.cores | spark.dynamicAllocation.maxExecutors |
| Spark3 | spark.executor.cores | spark.executor.instances |
运行过程:
1 当一个xgboost任务提交到yarn上时,先在driver端启动一个RabitTracker,RabitTracker提供N个end point给worker连接。
2 然后通过yarnclient向RM请求资源来创建AM。
3 RM先在NM上创建一个container,并在这个container里面启动任务的AM。
4 AM根据资源配置向RM请求具体执行的容器。
5 AM申请到容器之后,会将boost程序发送到容器并启动,同时管理这些容器。
6 每一个xgboost通过rabit框架和rabitTracker通信完成注册,rabitTracker将这些rabit编号并形成环形网络结构。
7 那么AM监控和管理容器的运行情况,rabittracker协调xgboost的运作。
运行日志:
23/08/28 16:30:25 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 16:30:25,573 DEBUG Recieve start signal from 11.11.101.69; assign rank 0
23/08/28 16:30:25 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 16:30:25,660 DEBUG Recieve start signal from 11.11.101.69; assign rank 1
# ......
23/08/28 16:30:26 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 16:30:26,283 DEBUG Recieve start signal from 11.11.103.72; assign rank 8
23/08/28 16:30:26 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 16:30:26,371 DEBUG Recieve start signal from 11.11.103.72; assign rank 9
23/08/28 16:30:36 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 16:30:36,732 INFO @tracker All of 10 nodes getting started
23/08/28 17:15:03 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 17:15:03,372 INFO [0] train-auc:0.734405
# ......
23/08/28 19:21:39 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:39,710 INFO [9] train-auc:0.760338
23/08/28 19:21:40 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:40,836 DEBUG Recieve shutdown signal from 1
23/08/28 19:21:40 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:40,837 DEBUG Recieve shutdown signal from 2
23/08/28 19:21:40 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:40,837 DEBUG Recieve shutdown signal from 0
# ...
23/08/28 19:21:41 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:41,592 INFO @tracker All nodes finishes job
23/08/28 19:21:41 INFO RabitTracker$TrackerProcessLogger: 2023-08-28 19:21:41,593 INFO @tracker 10264.8599551 secs between node start and job finish
23/08/28 19:21:42 INFO XGBoostSpark: Rabit returns with exit code
三 如何控制训练拟合
1 概述
- 树数量、数深度
- 特征相关:特征处理、数量和质量
- 正则化
- 剪枝
2 树数量、数深度
-
tree_method[default=auto]:XGBoost 中使用的树构建算法。
- approx算法是一种基于近似分裂的算法,它使用贪心算法来选择最佳分裂点,从而减少计算量。这种算法在数据集较小或特征较少时表现更好。
- hist算法是一种基于直方图的算法,它将训练数据集按照特征值分桶,并计算每个桶中样本的统计信息,然后在每个桶上进行分裂。这种算法可以减少计算量,并提高训练速度,特别是在数据集较大时。
-
num_round:训练轮次。每次迭代都加新的树去优化之前的树。
-
max_depth [default=6]:树的最大深度。如果max_depth设置得太小,可能会导致欠拟合,而如果设置得太大,则可能会导致过拟合。
-
sketch_eps[default=0.03]:控制稀疏近似算法的精度,当tree_method为
approx时生效。它决定了计算每个特征的直方图时使用的桶的数量。较小的值会导致更多的桶,从而提高了精度,但也增加了内存和计算成本。较大的值会减少桶的数量,降低了精度,但可以节省内存和计算时间。 -
max_bin[default=256]:控制分箱(binning)的最大数量,当tree_method为
hist时生效。增加这个数字可以提高分割的最优性,但代价是增加计算时间。
3 特征数量与质量
- 特征处理:无需归一化和one_hot编码;
- 特征数量:加更多相关特征来提升拟合;
- 特征质量:修复异常特征来提升拟合,包括label和features。
4 正则化
-
alpha[default=0]:L1 regularization,增加该值会让模型更加收敛。
-
lambda [default=1]:L2 regularization
-
eta (learning_rate) [default=0.3]:更新中使用步长收缩来防止过度拟合。
-
max_delta_step [default=0]:允许每个叶子输出的最大增量步长。 如果该值设置为0,则表示没有约束。实际上,这意味着叶子值不能大于 max_delta_step * eta。
5 剪枝
- gamma (min_split_loss)[default=0] :在树的叶节点上进行进一步划分所需的最小损失减少。 gamma越大,算法越保守。
- min_child_weight[default=1]:指每个决策树节点的最小样本权重和。如果某个节点的样本权重和小于min_child_weight,则不会再分裂该节点,这有助于防止过拟合。min_child_weight越大,算法越保守。
6 总结:XGBoost调参策略
-
设置学习率为0.1,使用早停法得到迭代次数
-
固定学习率和迭代次数
-
调节max_depth和min_child_weight参数
-
调节gamma
-
调节 subsample 和 colsample_bytree
-
正则化参数alpha
-
调低学习率和调高迭代次数
四 特征重要性
1 概述
- 权重(Weight):通过累加每个特征在所有样本上的权重来计算。权重越大的特征,其重要性越高。
- 预测增益(Gain):在构建决策树的过程中,XGBoost通过计算每个特征在分裂节点时的预测增益来评估其重要性。
- 覆盖度(Cover):覆盖度是指每个特征在所有分裂节点上的覆盖次数的累加。覆盖度越高的特征,其重要性越高。
2 权重(weight)特征重要性
计算方式:指每个特征在所有树中被使用的次数之和。
使用场景:衡量一个特征被选择为分裂特征的频率。数值型特征分值会更好,因为变数更多,树分裂时可切割的空间越大。
3 增益(Gain)特征重要性
计算方式:指每个特征在所有树中的平均增益之和。增益是通过计算每个分裂点的损失减少量得到的。
使用场景:衡量一个特征在模型中对损失函数的贡献程度。它适用于判断哪些特征对于模型的性能提升起到了更大的作用。

4 覆盖率(Cover)特征重要性
计算方式:指每个特征在所有树中的平均覆盖率之和。覆盖率是样本在每个分裂点上的数量。
使用场景:衡量一个特征在模型中的覆盖范围,即参与了更多的样本分裂。它适用于判断哪些特征对于模型的覆盖范围最广,即样本分布的广泛性。
5 控制有特征重要性分数特征数量
常见控制参数:
(1)根据样本使用特征的情况,调节特征重要性计算方式:weight、gain、cover
(2)调节colsample_bylevel和colsample_bytree参数
- colsample_bylevel[default=1]:指在每一级的树构建过程中,对特征进行随机采样的比例
- colsample_bytree[default=1]:指在构建每棵树时,对特征进行随机采样的比例
(3)max_depth [default=6]:树的最大深度。假设max_depth为4时,1棵树只能包含2^4-1=15个特征
案例:
# max_depth=4 colsample_bylevel=1 colsample_bytree=1
zeroCount:869 nonZeroCount:54
# max_depth=4 colsample_bylevel=0.6 colsample_bytree=1
zeroCount:862 nonZeroCount:61
# max_depth=4 colsample_bylevel=0.6 colsample_bytree=0.6
zeroCount:849 nonZeroCount:74
# max_depth=10 colsample_bylevel=1 colsample_bytree=1
zeroCount:329 nonZeroCount:594
# max_depth=10 colsample_bylevel=0.6 colsample_bytree=0.6
zeroCount:307 nonZeroCount:616
五 踩坑指南
1 目标函数不正确
# reg:logistic的label值只能是0或者1
ml.dmlc.xgboost4j.java.XGBoostError: [19:27:06] /xgboost/src/objective/regression_obj.cc:98: Check failed: Loss::CheckLabel(y) label must be in [0,1] for logistic regression
2 近似树方法
# 这个警告信息是来自于XGBoost库中的gbtree.cc文件,它提示在分布式训练中自动选择了“approx”树方法。
# 在XGBoost中,有两种树方法:精确方法和近似方法。
# 1.精确方法需要在每个节点上计算所有的候选分裂点,因此计算成本非常高。
# 2.近似方法则使用一些启发式算法来减少计算成本,但可能会导致精度损失.
# 在分布式训练中,由于数据量较大,使用精确方法可能会导致计算时间过长,因此XGBoost库会自动选择近似方法。
# 这个警告信息只是提醒用户在分布式训练中使用了近似方法,可能会导致精度损失。
WARNING: /xgboost/src/gbm/gbtree.cc:128: Tree method is automatically selected to be 'approx' for distributed training.
3 process_type参数在xgboost4j-spark不存在
在XGBoost中,process_type参数用于指定训练过程中使用的计算资源类型,它有两个可选值:default和update。
default:默认值。在这种模式下,XGBoost使用的是传统的梯度提升算法(Gradient Boosting Decision Tree),它会在每次迭代中使用所有的训练数据来更新模型。update:在这种模式下,XGBoost使用的是增量学习算法(Incremental Learning),它会在每次迭代中只使用一部分训练数据来更新模型。这种算法可以更加高效地处理大规模数据集,同时也可以支持在线学习。
因此,default模式适用于数据集较小或者内存资源充足的情况,而update模式则适用于数据集较大或者内存资源受限的情况。
具体查看源码:BoosterParams
4 booster参数在xgboost4j-spark不存在
结论:booster在xgboost4j-spark只能为gbtree。
在XGBoost中,booster参数指弱学习器的类型,它有三个可选值:gbtree、dart和gblinear。
gbtree(Gradient Boosted Trees):默认booster类型,它基于梯度提升决策树(Gradient Boosting Decision Tree)的算法。每棵树都是在前一棵树的残差基础上构建,通过拟合负梯度来最小化损失函数。dart(Dropout Regularized Trees):XGBoost引入的一种新型booster类型。它在gbtree的基础上加入了dropout正则化技术,以防止过拟合并提高模型的泛化能力。在一些特定的场景下可能会提供更好的性能,例如对于较小的数据集或者需要进行模型的正则化和防止过拟合的情况。
具体查看源码:XGBoost2MLlibParams
5 IRabitTracker指定python运行环境
报错日志:
# xgboost 1.5.1
# ..../tracker20069399715812878.py", line 67
23/08/31 12:33:09 INFO RabitTracker$TrackerProcessLogger: assert magic == kMagic, f"invalid magic number={magic} from {self.host}"
23/08/31 12:33:09 INFO RabitTracker$TrackerProcessLogger: ^
23/08/31 12:33:09 INFO RabitTracker$TrackerProcessLogger: SyntaxError: invalid syntax
23/08/31 12:33:09 INFO RabitTracker$TrackerProcessLogger: Tracker Process ends with exit code 1
23/08/31 12:44:45 ERROR XGBoostSpark: the job was aborted due to
ml.dmlc.xgboost4j.java.XGBoostError: XGBoostModel training failed
at ml.dmlc.xgboost4j.scala.spark.XGBoost$.postTrackerReturnProcessing(XGBoost.scala:750)
at ml.dmlc.xgboost4j.scala.spark.XGBoost$.trainDistributed(XGBoost.scala:624)
at ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier.train(XGBoostClassifier.scala:199)
at ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier.train(XGBoostClassifier.scala:40)
# xgboost 1.6.2
# ..../tracker7358922665113301957.py", line 24
23/08/31 16:18:42 INFO RabitTracker$TrackerProcessLogger: def __init__(self, sock: socket.socket) -> None:
23/08/31 16:18:42 INFO RabitTracker$TrackerProcessLogger: ^
23/08/31 16:18:42 INFO RabitTracker$TrackerProcessLogger: SyntaxError: invalid syntax
23/08/31 16:18:42 INFO RabitTracker$TrackerProcessLogger: Tracker Process ends with exit code 1
23/08/31 16:21:19 ERROR XGBoostSpark: the job was aborted due to
ml.dmlc.xgboost4j.java.XGBoostError: XGBoostModel training failed.
at ml.dmlc.xgboost4j.scala.spark.XGBoost$.trainDistributed(XGBoost.scala:435)
at ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier.train(XGBoostClassifier.scala:196)
at ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier.train(XGBoostClassifier.scala:35)
at org.apache.spark.ml.Predictor.fit(Predictor.scala:151)
查阅源码查看python使用:
// ml.dmlc.xgboost4j.scala.spark.XGBoost.scala文件
private[scala] def getTracker(nWorkers: Int, trackerConf: TrackerConf): IRabitTracker = {
val tracker: IRabitTracker = trackerConf.trackerImpl match {
case "scala" => new RabitTracker(nWorkers)
case "python" => new PyRabitTracker(nWorkers, trackerConf.hostIp, trackerConf.pythonExec)
case _ => new PyRabitTracker(nWorkers) // 默认为python
}
tracker
}
// 注:
// 1. RabitTracker:无训练日志打印
// 2. PyRabitTracker:默认使用系统python命令,需指定pythonExec为sparkConf.get("spark.pyspark.python")
spark python参数设置:
# 默认值:spark.pyspark.python=/usr/bin/python3
spark.yarn.dist.archives=hdfs://xxx/pyenv/py3.7.zip#pyenv
spark.pyspark.python=./pyenv/py3.7/bin/python
代码传参:
// python环境
val pythonExec: String = sparkConf.get("spark.pyspark.python")
// 训练参数
var paramMap: Map[String, Any] = Map()
// 忽略其他参数设置
// ......
// tracker配置
paramMap = paramMap + ("tracker_conf" -> new TrackerConf(0, "python", pythonExec = pythonExec))
// xgb分类器
val classifier: XGBoostClassifier = new XGBoostClassifier(paramMap)
6 spark3升级:屏障执行模式无法使用动态资源。
Barrier执行模式的核心思想是在作业的不同阶段引入屏障(barrier),以确保在达到某个特定条件之前,所有任务都必须等待。
Barrier execution mode does not support dynamic resource allocation for now. You can disable dynamic resource allocation by setting Spark conf "spark.dynamicAllocation.enabled" to "false".
7 spark3升级:XGBoost的num_workers相关
# 错误1:num_workers超过最大值
org.apache.spark.scheduler.BarrierJobSlotsNumberCheckFailed: [SPARK-24819]: Barrier execution mode does not allow run a barrier stage that requires more slots than the total number of slots in the cluster currently. Please init a new cluster with more resources(e.g. CPU, GPU) or repartition the input RDD(s) to reduce the number of slots required to run this barrier stage.
# 错误2:num_workers设置为最大后,但spark资源不足,导致无法获得足量资源。
org.apache.spark.SparkException: Fail resource offers for barrier stage 5 because only 29 out of a total number of 30 tasks got resource offers. This happens because barrier execution currently does not work gracefully with delay scheduling. We highly recommend you to disable delay scheduling by setting spark.locality.wait=0 as a workaround if you see this error frequently.