回复我们公众号“1号程序员”的“E005”可以获取原文下载地址。[关注并回复:【E005】]
摘要
前列腺癌是男性最常见的癌症,也是导致癌症死亡的主要原因。确定患者最佳治疗方案是一项挑战,肿瘤学家必须选择最有可能成功且最不可能出现毒性的治疗方案。国际预后标准依赖于非特异性和半定量工具,通常导致过度治疗和不足治疗。基于组织的分子生物标志物尝试解决了这个问题,但大多数标志物在前瞻性随机试验中的验证有限,并且处理成本昂贵,限制了广泛采用的障碍。因此,需要准确且可扩展的工具来支持治疗个性化。
本研究通过使用多模态深度学习架构预测长程临床结局,使用临床数据以及前列腺活检的数字组织病理学图像训练模型,展示了前列腺癌治疗的个性化。我们在数百个临床中心进行了五项三期随机试验的训练和验证。5654名随机患者(占7764名随机患者的71%)的组织病理学数据可用,随访时间的中位数为11.4年。与最常见的风险分层工具——国家癌症中心网络(NCCN)开发的风险组相比,我们的模型在所有终点指标上具有更好的区分性能,在一个保留的验证集中改善了9.2%到14.6%的相对性能。这种基于人工智能的工具改善了标准工具的预后能力,并允许肿瘤学家计算预测特定患者最可能的治疗结果,以确定最佳治疗方案。只需配备数字扫描仪和互联网接入,任何诊所都可以提供这种能力,从而实现全球范围内的治疗个性化。
引言
2020年,全球新发生了1,414,259例前列腺癌病例和375,304例死亡案例[1]。虽然前列腺癌通常是缓慢发展的,并且治疗可以达到治愈的效果,但由于过度治疗和不足治疗的负面影响,前列腺癌是导致全球癌症相关残疾的主要原因,也是男性癌症死亡的主要原因[2,3]。确定一个患者的最佳治疗方案很困难,需要考虑他们的整体健康状况、癌症特征、多种可能治疗的副作用情况、临床试验中涉及具有类似诊断的患者群体的结局数据,以及对他们预期未来结局的预测。这一挑战还因缺乏易于获取的预后工具来更好地对患者进行风险分层而变得更加复杂。
全球用于对患者进行风险分层的最常见系统之一是在上世纪90年代末发展起来的美国国家综合癌症网络(NCCN)或D'Amico风险分组系统。该系统基于前列腺数字直肠检查、血清前列腺特异性抗原(PSA)水平以及基于组织病理学评估的肿瘤活检分级。这个三级系统构成了全球治疗局部前列腺癌的基础推荐标准[4],但已多次证明其预后和区分性能不佳[5]。这在一定程度上是由于这些模型中核心变量的主观性和非特异性特征。例如,Gleason分级[6]是在20世纪60年代发展起来的,即使在专业的泌尿病理学家之间,它的观察者间再现性也不佳[7,8]。尽管已经创建了更新的临床病理风险分层系统,但它们的核心仍然包括三个变量:Gleason分数、T分期和PSA水平[9]。
近年来,基于组织的基因组生物标志物已经展示出优越的预后性能[10]。然而,几乎所有这些测试在拟定使用人群中都缺乏前瞻性随机临床试验的验证,并且由于成本、实验室要求和处理时间等原因,在美国以外的地区几乎没有被采用[11]。重要的是,仅基于队列研究数据而非随机临床试验开发的预后模型容易受到临床治疗决策所引起的选择偏差的影响,并且往往具有较不准确的临床和长期结局数据。因此,对于改进和更易获取的个体化前列腺癌治疗工具仍存在严重的临床需求[12]。
人工智能(AI)在医学领域展示了卓越的能力,涵盖了从医生级别的诊断[13]到工作流程优化[14]等多个用例,并有潜力支持癌症治疗[15,16]。随着数字组织病理学在临床中的采用不断增加[17],AI可以更广泛地应用于癌症患者的护理中。在基于组织病理学的预后学中,AI的应用已经取得了进展和进步,例如通过预测短期患者预后[18]或改进基于Gleason分级的术后外科样本的癌症分级准确性[19]。与标准的风险分层工具固定且基于少数变量不同,AI可以从跨多种形式的大量经过最小处理的数据中进行学习。与基因组生物标志物相比,利用数字图像的AI系统成本较低且可大规模扩展。此外,这些工具可以通过持续学习逐步改进,以优化测试性能和医疗价值。
在本研究中,我们展示了一种多模态人工智能(MMAI)系统可以用来满足局部前列腺癌易于获取和可扩展的预后需求。该MMAI系统具有成为可推广的全球数字AI生物标志物的潜力。我们利用数字组织病理学和临床数据的多模态深度学习,在五项NRG Oncology第III期随机临床试验中训练和验证了局部前列腺癌的预后生物标志物[20-24]。通过利用具有长期随访和标准化治疗信息的大型临床试验数据,我们的模型从中学习并训练出一些最准确的临床和结果数据。
结果
我们创建了一种独特的MMAI架构,可以接收表格化临床和图像数据,并利用自监督学习来利用大量可用数据进行训练。我们在一个由16,204个组织病理学切片(约16 TB的图像数据)和5,654名患者的临床数据组成的数据集上训练和验证了六个不同的模型,用于预测六个不同的二元结果,这些结果根据终点和时间范围的不同而有所变化(5年和10年的远处转移、5年和10年的生化失败、10年前列腺癌特异性生存和10年总生存)。值得注意的是,在5年和10年内准确预测远处转移对于识别可能患有更具侵袭性疾病并需要额外治疗的患者尤为重要。我们使用基于截尾事件的竞争风险下的敏感性和特异性的时间依赖接收器操作特征曲线(AUC)来衡量这些模型的性能,并将NCCN风险分组作为我们的基准比较器。在模型开发之前,来自所有五项临床试验的数据被分为训练集(80%)和验证集(20%)。当比较验证集的性能结果时,MMAI模型在所有测试的结果中始终优于NCCN风险分组。
对于每个患者,MMAI模型的输入包括临床变量,包括NCCN变量(综合Gleason分数、临床T分期、基线PSA),以及年龄、Gleason主要分级和Gleason次要分级,以及数字化的组织病理学切片(中位数为2张切片)。跨模态数据的联合学习是复杂的,涉及构建两个独立的机器学习流程,一个用于从病理图像数据中学习特征嵌入(图像流程),另一个用于从临床和图像数据中共同学习,并输出感兴趣结果的风险评分(融合流程,参见图1a)。我们对试验中的图像特征进行了标准化处理,以确保一致性。
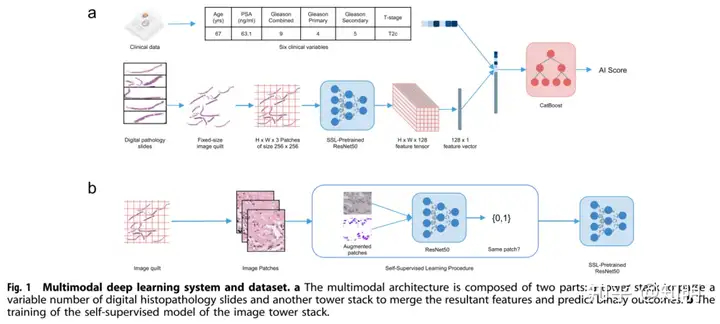
从数量不定的数字化组织病理学切片中有效学习相关特征涉及图像标准化和自监督预训练。对于每个患者,我们将其活检切片中的所有组织区域分割出来,并将它们合并成一个固定宽度和高度的大型图像,称为图像拼布(Supplementary Fig. 1)。然后,在图像拼布上叠加网格,将其切割成256×256像素大小的块,在其RGB通道上进行切块。然后,使用这些块来训练一个自监督学习模型[25],以学习在后续的AI任务中有用的组织形态学特征(图1b)。一旦训练完成,自监督学习模型将图像拼布的块作为输入,并为每个块输出一个128维向量表示。将所有与原始块具有相同空间方向的向量连接在一起,得到一个特征张量,我们称之为特征拼布,它将最初庞大的图像拼布有效地压缩成一个紧凑的表示,以便于后续的学习。在连接之前,将该特征拼布进行平均,进一步将表示压缩为每个患者的一个128维特征向量。表格化临床数据与图像流程的输出进行连接。然后将连接向量输入到CatBoost分类器[26]中,模型输出所需任务的风险评分。
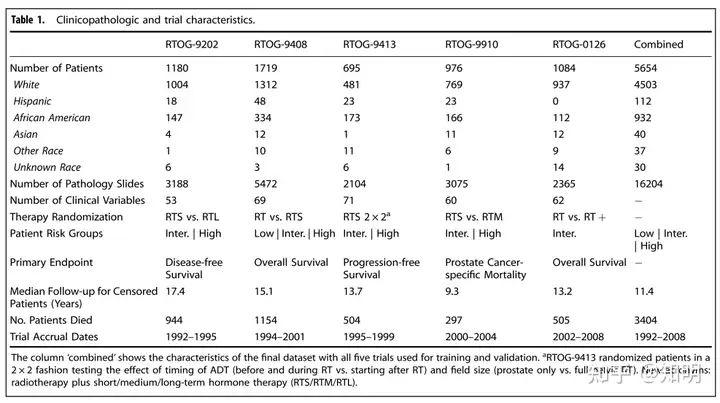
经过NRG Oncology(由国家癌症研究所(NCI)资助的国家临床试验网络(NCTN)组织)的批准,我们从五个大型多国家的随机III期临床试验中组建了一个独特的数据集,这些试验涉及局部前列腺癌患者(NRG/RTOG-9202、9408、9413、9910和0126)。所有患者都接受了确定性的外部放射治疗(RT),部分患者还同时使用了雄激素剥夺疗法(ADT)。RT与短期ADT的联合治疗持续4个月,中期ADT持续36周,长期ADT持续28个月(表1)。在这五个试验中,共有7,764名符合条件的随机患者,其中有5,654名患者具有高质量的数字化组织病理学图像数据。这代表了来自16,204张治疗前和治疗后前列腺组织的16.1 TB病理学图像数据。
自监督学习模型的内部数据表示如图2所示。我们将整个数据集的图像补丁输入自监督学习模型,并提取模型特征——模型输出的128维向量,对应每个补丁。我们使用均匀流形近似和投影算法(UMAP)27对这些特征进行处理,将它们从128维投影到二维平面上,并将每个补丁绘制为一个个体点。相邻的数据点表示模型认为相似的图像补丁。UMAP将特征向量分组为25个簇,其中一些簇以不同颜色显示,我们请一位病理学家解释了与簇质心最近的20个邻近图像补丁,并尝试识别每个簇观察到的趋势。图2中的插图显示了与簇质心在特征空间上接近的示例图像补丁(以及病理学家的描述),所有25个簇的完整解释显示在附图2中。
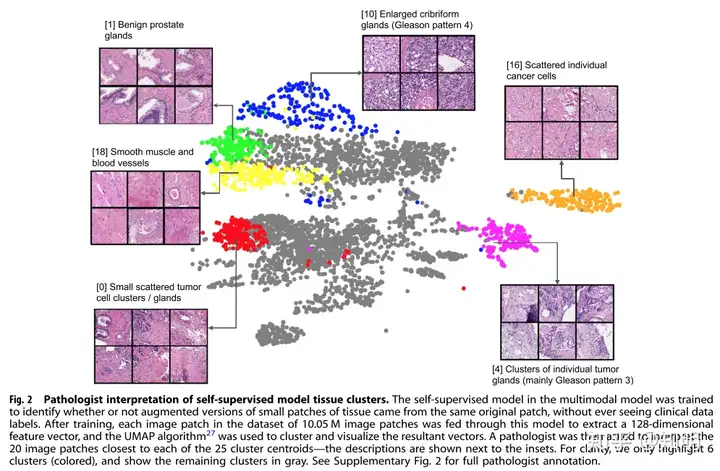
图2:病理学家对自我监督模型组织簇的解释。多模态模型中的自我监督模型经过训练,可以识别经过增强处理的小组织补丁是否来自同一个原始补丁,而无需查看临床数据标签。训练后,数据集中的每个图像补丁都通过该模型进行处理,提取一个128维特征向量,然后使用UMAP算法27对得到的向量进行聚类和可视化。然后,要求一位病理学家解释与25个簇质心最接近的20个图像补丁,描述显示在插图旁边。为了清晰起见,我们只突出显示了6个簇(着色),其余的簇显示为灰色。完整的病理学家注释请参见附图2。
使用病理图像、NCCN变量(综合Gleason评分、T分期、基线PSA)、年龄、Gleason一级和Gleason二级等因素开发的MMAI预后模型,在所有临床终点和时间范围上与最常用的NCCN风险分层工具相比,在整个保留的测试集上表现出更优越的辨别能力。
图3显示了验证集的模型性能结果。在图3a和d-h中,蓝色柱代表训练于特定终点时间范围的MMAI模型的性能,灰色柱代表相应的NCCN模型的性能。图3b显示了MMAI相对于NCCN在各种结果上的改善情况,以及来自五个单独试验的验证集子集的情况。可以看到,我们的模型在所有测试的结果中都始终优于NCCN模型,AUC的相对改善幅度在9.2%至14.6%之间。此外,除了RTOG-9910中对10年生化失败的预测外,所有试验子集一致显示出相对于NCCN的改善。与其他试验相比,该试验的事件发生率较低,随访时间较短,并且所有患者都接受了激素治疗。由于随访时间较短,患者恢复睾酮和前列腺特异性抗原水平的可能性较低,因此不太可能出现生化失败的情况。
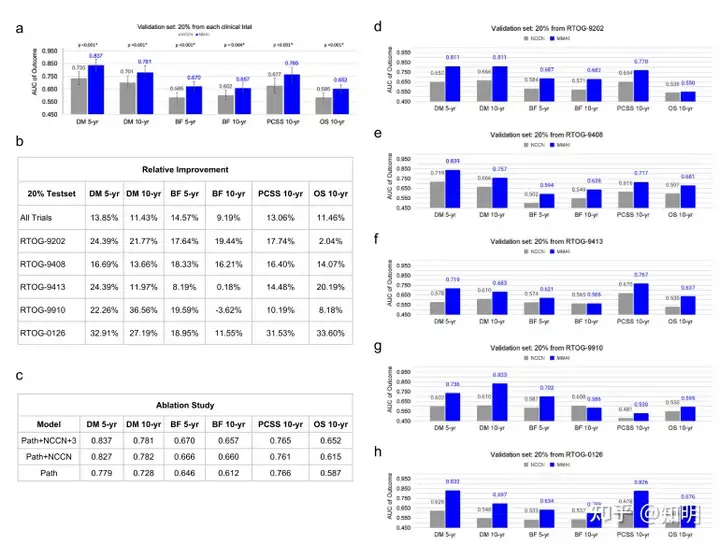
图3:多模态深度学习系统与NCCN风险分组在试验和结果方面的比较。 a)性能结果报告了MMAI(蓝色柱)和NCCN(灰色柱)模型的时间依赖接收者操作特征曲线下面积(AUC),包括95%的置信区间和双侧p值。比较是在5年和10年时间点上进行的,涉及以下二元结果:远处转移(DM),生化失败(BF),前列腺癌特异性生存(PCSS)和总体生存(OS)。 b)总结了MMAI模型相对于NCCN模型在不同结果上的改善情况,并根据验证集中每个试验数据的性能进行了细分。相对改善由(AUCMMAI - AUCNCCN)/ AUCNCCN给出。 c)消融研究展示了模型在依次减少的数据输入集上进行训练时的性能,包括仅病理图像(path),病理图像+ NCCN变量(path + NCCN),以及病理图像+ NCCN变量+年龄+ Gleason一级+ Gleason二级(path + NCCN + 3)。 d-h)在验证集的各个临床试验子集上的性能比较 - 这五个试验共同组成了(a)中显示的整个验证集。
为了评估各种数据组成部分的增量效益,我们进行了消融研究,顺序地删除数据特征,以了解它们对系统整体性能的影响。我们使用以下数据设置训练了额外的MMAI模型:仅病理图像、病理图像+ NCCN变量(组合的Gleason评分、T分期、基线PSA值)以及病理图像+ NCCN变量+三个附加变量(年龄、Gleason一级、Gleason二级)。每个附加数据组件都改善了性能,而完整的设置(病理图像和六个临床变量)产生了最佳结果(图3c)。对于所有结果,包括5年远处转移(AUC为0.84 vs. 0.74,p值<0.001),5年生化失败(AUC为0.67 vs. 0.59,p值<0.001),10年前列腺癌特异性生存(AUC为0.77 vs. 0.68,p值<0.001)和10年总体生存(AUC为0.65 vs. 0.59,p值<0.001),MMAI预后模型与NCCN模型相比具有更好的判别能力。
在随后的分析中,为了评估模型在预定使用环境中的表现,我们在验证集中移除了任何有术后前列腺组织的患者(n = 931;移除患者中的71%来自NRG/RTOG 9408)。表2总结了性能评估结果。MMAI预后模型与NCCN模型相比,在所有结果中均具有更好的判别能力,包括5年远处转移(AUC为0.83 vs. 0.72,p值<0.001),5年生化失败(AUC为0.69 vs. 0.61,p值<0.001),10年前列腺癌特异性生存(AUC为0.77 vs. 0.67,p值<0.001)和10年总体生存(AUC为0.65 vs. 0.57,p值<0.001)。
标签:模态,NCCN,Gleason,模型,临床试验,患者,随机化,图像,数据 From: https://www.cnblogs.com/sqchi1991/p/17659894.html