前言
最近花了几天时间彻底研究透了步步高的 BPK 加密格式,写一篇博客记录一下研究的成果
本文只记录一些研究的步骤和研究成果,不是破解教程
之前的记录
步步高加密 APK 格式 BPK 研究 : 续
步步高家教机加密安装包 BPK 研究 (已弃坑)
什么是 BPK
步步高为其旗下搭载 StudyOS 定制 Android UI 的产品 "家教机"、"imoo 学生手机" 定制了一种特殊的 ZIP 格式,因为其 Magic 并非 PK,而是 BPK,因此以下将其称作 BPK
BPK 格式只能被 StudyOS 设备解析,并且 StudyOS 设备默认情况下拒绝安装非 BPK 软件
APK 和 ZIP
APK 和 ZIP 的区别
先上一张图
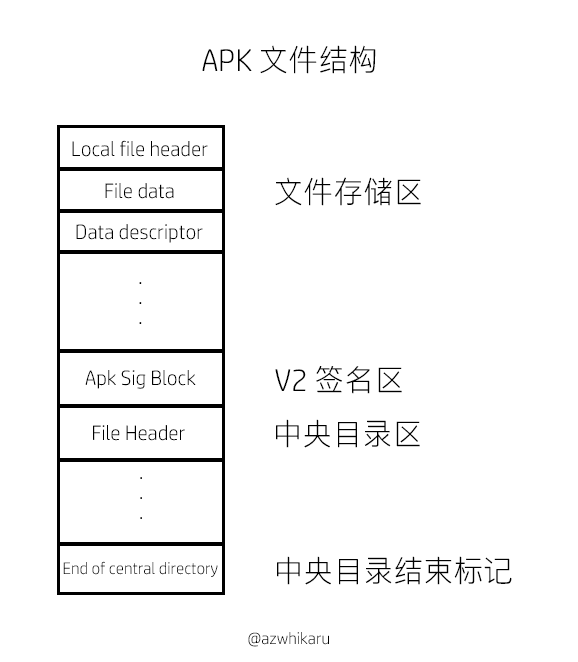
众所周知,APK 本质上就是一个 ZIP,其和 ZIP 文件几乎没有任何区别,唯一的区别就是在 Android 7.0 中,Google 为 APK 加入了 V2 签名,直到今天,它已经发展到了 V4
与 V1 签名不同的是,V2 及以上的签名方式是在 ZIP 的中央目录区 (Central Directory) 前面加入了一个单独的签名区:

不过,签名和 BPK 没有任何关系...
APK 文件结构总结
ZIP 文件的 3 个部分
既然 APK 本质上就是一个 ZIP,那么对 ZIP 的结构的了解也是必不可少的
ZIP 文件可以分为三部分,在一个 ZIP 文件中,从上到下依次为:
- File Entry 数据存储区
- Central Directory 中央目录区
- End of central directory 中央目录结束标记
ZIP 的三部分的结构如下:
End ofcentral directory 中央目录结束标记
为什么要从 ZIP 最下面的部分开始介绍?因为所有对 ZIP 的解析都是从最下面的中央目录结束标记开始的
为了表述方便,以下统一把中央目录结束标记称作 EOCD:
在 ZIP 的末尾,有且只有一个 EOCD。EOCD 的结构如下:
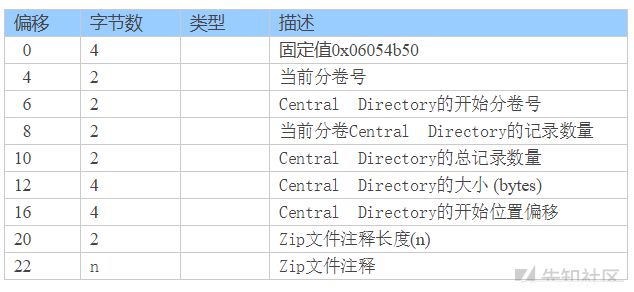
Central Directory (以下统一简称为 CD) 的记录数量、大小、开始位置偏移都在 EOCD 中,也就不难解释为什么 ZIP 要从最下方开始解析了,
EOCD 部分的 Magic 为 50 4B 05 06,因为 ZIP 中所有数据的存储都是使用小端序,从右往左,因此所有数据在解析的时候都要用小端序解析
如何解析 EOCD
一个 EOCD 的长度为 22 个字节,但是如果这个 ZIP 文件有注释,那么 EOCD 的偏移就不是从 -22 字节开始的了,这个时候要考虑到有注释的情况,
ZIP 文件的最大注释长度为 32768 字节,因此在解析 EOCD 的时候,我们可以从 ZIP 的末尾取 32768 + 22 个字节,然后遍历寻找 EOCD 标记
Central Directory 中央目录区
从 EOCD 中获取到 CD 的总记录数量、大小、开始位置偏移后,就可以跳到 CD 的开始偏移处解析 CD 部分的内容
File header 文件头
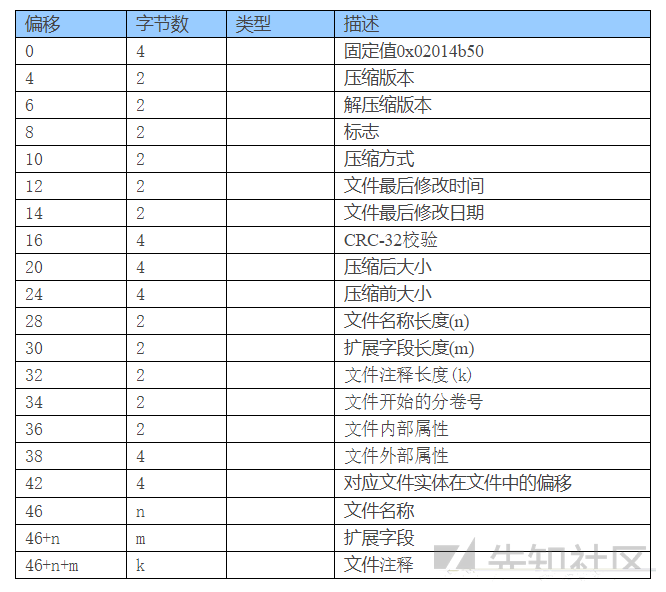
CD 区域文件头的标记为 50 4B 01 02
CD 区域的内容和 File Entry (以下统计简称为 FE) 部分是一一对应的,有几个文件/目录,就有几个 CD/FE,其中的第 42-46 的 4 个字节即是 FE 在文件中的开始位置偏移
CD 区域的长度为 46 + 文件名长度 + 扩展字段长度 + 文件注释长度
Digital Signature 数字签名
因为 APK 文件不涉及这部分,所以这部分略过...
如何解析 CD
CD 区域的开始偏移 (第一个 CD 记录的偏移) 可以在 EOCD 中获得,之后只需要从第一个 CD 区域的偏移 + 第一个 CD 区域的长度 + N 个 CD 的偏移... 即可遍历解析 CD 部分
File Entry 文件存储区
从 CD 中可以获得这个 CD 所对应的 FE 的起始位置偏移
Local file header 文件头
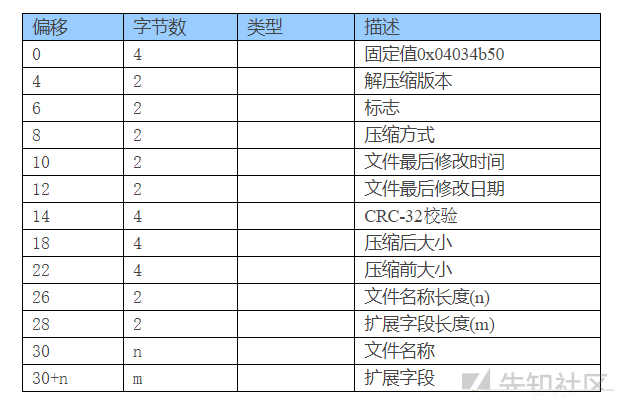
Local file header (以下统一简称为 LFH) 的标记为 50 4B 03 04
LFH 中包含了文件的具体信息,它的内容和其对应的 CD 部分是一样的
File data 文件内容
在 LFH 之后,存储文件的具体内容,这部分的长度即为 CD 和 LFH 中的 "压缩后文件大小"
Data descriptor 数据描述符
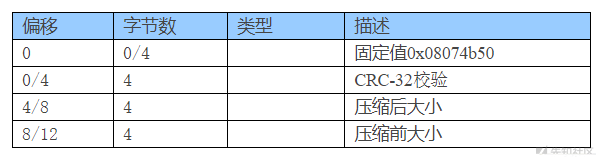
Data descriptor (以下统一检测为 DD) 的标记是 50 4B 07 08
如何解析 DD
不是每个 FE 都有 DD,识别其的方法是 LFH 中的第 6-8 个字节中的第 3 个 Bit 是否为 1
更简单地判断 FE 是否有 DD 的方法是直接用偏移判断,即 30(LFH 长度) + 文件名长度 + 扩展字段 + 压缩后文件大小,判断从这个偏移开始的 4 个字节是否为 DD 的标记即可
ZIP 的 3 个部分的总结
现在我们已经知道 ZIP 的 3 个结构的解析方法、数据结构,归纳一下:
| 标记 | 对应的结构 |
|---|---|
| 50 4B 05 06 | EOCD 标记 |
| 50 4B 01 02 | CD 标记 |
| 50 4B 03 04 | FE 标记 |
| 50 4B 07 08 | DD 标记 |
APK 和 BPK
ZIP 和 BPK 的区别
BPK 和 ZIP 最直观的区别即是 ZIP 文件的 3 个部分的 Magic
| ZIP 标记 | BPK 标记 | 对应的结构 |
|---|---|---|
| 50 4B 05 06 | 42 50 4B 05 | EOCD 标记 |
| 50 4B 01 02 | 42 50 4B 01 | CD 标记 |
| 50 4B 03 04 | 42 50 4B 03 | FE 标记 |
| 50 4B 07 08 | 42 50 4B 07 | DD 标记 |
逆向分析
通过对 service、framework 的逆向分析,可以得出 BPK 被加密的原理
因为新版本的 Android 将 ZIP 文件的解析放到了 libziparchive.so 中,用 IDA 反编译 so 库质量不怎么高,这里使用 Android 5 的步步高 StudyOS 来分析,旧版本 Android 版本对 ZIP 的解析放在 service 中
// java.util.zip.ZipFile
private static final int ENDSIGBBK = 88821826; // 42 50 4B 05
private static final int LOCSIGBBK = 55267394; // 42 50 4B 03
private static final byte[] xorCodeEOCD = "END_OF_CENTRAL_DIRECTORY_XOR_CODE_OF_BBK_APK_ENCRYPTION".getBytes();
private boolean bbkEncrypted;
private String comment;
private final LinkedHashMap<String, ZipEntry> entries;
private File fileToDeleteOnClose;
private final String filename;
private final CloseGuard guard;
private RandomAccessFile raf;
private void readCentralDir() throws IOException
{
long scanOffset = this.raf.length() - 22; // -22 = 减去 EOCD 大小
if(scanOffset < 0)
{ // 如果 -22 之后文件长度不够 (只有 EOCD)
throw new ZipException("File too short to be a zip file: " + this.raf.length()); // 输出 ZIP 文件太小
}
this.raf.seek(0 L); // 设置指针到 ZIP 文件的偏移 0
int headerMagic = Integer.reverseBytes(this.raf.readInt()); // 从 ZIP 文件中读取 4 个字节 (Int)。因为 ZIP 中使用小端序所以需要反转
if(headerMagic == ZipConstants.ENDSIG || headerMagic == ENDSIGBBK)
{ // 如果 4 个字节是 EOCD 标识 (文件只有 EOCD,没有 CD)
throw new ZipException("Empty zip archive not supported"); // 输出不支持空的 ZIP 文件
}
if(headerMagic == LOCSIGBBK)
{ // 如果 Sig 为 42 50 4B 03 (Local File Header)
this.bbkEncrypted = true; // 设置 bbkEncrypted Flag 为 true
}
else if(headerMagic != ZipConstants.LOCSIG)
{ // 如果 ZIP 的前 4 个字节既不是 BBK 加密文件头,也不是 ZIP 文件头
throw new ZipException("Not a zip archive"); // 返回不是 ZIP 文件
}
long stopOffset = scanOffset - 65536;
if(stopOffset < 0)
{
stopOffset = 0;
}
do { // 倒着扫描 ZIP
this.raf.seek(scanOffset); // 设置指针到循环扫描的偏移
int endSignature = Integer.reverseBytes(this.raf.readInt()); // 读取从当前偏移开始的 4 个字节
if((this.bbkEncrypted || endSignature != ZipConstants.ENDSIG) && (!this.bbkEncrypted || endSignature != ENDSIGBBK))
{ // 如果没有扫到 EOCD 标记
scanOffset--; // 扫描偏移 - 1
}
else
{
byte[] eocd = new byte[18]; // 如果扫到了 EOCD。新建一个长度为 18 的 byte 型数组
this.raf.readFully(eocd); // 读取从当前偏移开始的所有内容到变量 eocd 中
if(this.bbkEncrypted)
{ // 如果设置了 bbkEncrypted Flag,则解密 EOCD
for(int i = 0; i < 18; i++)
{
eocd[i] = (byte)(eocd[i] ^ xorCodeEOCD[i % xorCodeEOCD.length]); // 解密 EOCD
}
}
BufferIterator it = HeapBufferIterator.iterator(eocd, 0, eocd.length, ByteOrder.LITTLE_ENDIAN); // 从这里开始是获取几个 EOCD 里的参数,也是倒着找的
// 获取 EOCD 中的几个信息
int diskNumber = it.readShort() & 65535;
int diskWithCentralDir = it.readShort() & 65535;
int numEntries = it.readShort() & 65535;
int totalNumEntries = it.readShort() & 65535;
it.skip(4);
long centralDirOffset = it.readInt() & 4294967295 L;
int commentLength = it.readShort() & 65535;
if(numEntries != totalNumEntries || diskNumber != 0 || diskWithCentralDir != 0)
{ // 判断是否为分卷
throw new ZipException("Spanned archives not supported");
}
if(commentLength > 0)
{ // 如果有注释。下面是加解密注释的地方
byte[] commentBytes = new byte[commentLength];
this.raf.readFully(commentBytes);
if(this.bbkEncrypted)
{
for(int i2 = 0; i2 < commentLength; i2++)
{
commentBytes[i2] = (byte)(commentBytes[i2] ^ xorCodeEOCD[(i2 + 18) % xorCodeEOCD.length]);
}
}
this.comment = new String(commentBytes, 0, commentBytes.length, StandardCharsets.UTF_8);
}
RAFStream rafStream = new RAFStream(this.raf, centralDirOffset); // 读取 centralDir 偏移开始的地方
BufferedInputStream bufferedStream = new BufferedInputStream(rafStream, 4096); // 读取 4096 个字节
byte[] hdrBuf = new byte[46];
for(int i3 = 0; i3 < numEntries; i3++) // 解析每个 CD 记录
{
ZipEntry newEntry = new ZipEntry(hdrBuf, bufferedStream, StandardCharsets.UTF_8); // 调用 zipEnrty 方法解析 CD 和 FE 部分
if(newEntry.localHeaderRelOffset >= centralDirOffset)
{
throw new ZipException("Local file header offset is after central directory");
}
String entryName = newEntry.getName();
if(this.entries.put(entryName, newEntry) != null)
{
throw new ZipException("Duplicate entry name: " + entryName);
}
}
return;
}
} while (scanOffset >= stopOffset);
throw new ZipException("End Of Central Directory signature not found");
}
// java.util.zip.ZipEntry
private static final int CENSIGBBK = 21712962;
private static final byte[] xorCodeCDE = "CENTRAL_DIRECTORY_XOR_CODE_OF_BBK_APK_ENCRYPTION".getBytes();
private boolean bbkEncrypted;
String comment;
long compressedSize;
int compressionMethod;
long crc;
long dataOffset;
byte[] extra;
int gpbf;
long localHeaderRelOffset;
int modDate;
String name;
int nameLength;
long size;
int time;
public ZipEntry(byte[] cdeHdrBuf, InputStream cdStream, Charset defaultCharset) throws IOException
{
this.crc = -1 L;
this.compressedSize = -1 L;
this.size = -1 L;
this.compressionMethod = -1;
this.time = -1;
this.modDate = -1;
this.nameLength = -1;
this.localHeaderRelOffset = -1 L;
this.dataOffset = -1 L;
this.gpbf = -1;
this.bbkEncrypted = false;
Streams.readFully(cdStream, cdeHdrBuf, 0, cdeHdrBuf.length);
BufferIterator it = HeapBufferIterator.iterator(cdeHdrBuf, 0, cdeHdrBuf.length, ByteOrder.LITTLE_ENDIAN); // 读取 Central Directory
int sig = it.readInt(); // 读取 Central Directory 的前 4 个字节 (Int)
if(sig == CENSIGBBK)
{ // Sig 是否等于 42 50 4B 01
this.bbkEncrypted = true; // 设置 bbkEncrypted Flag 为 True
for(int i = 4; i < 46; i++)
{ // 解密 Central Directory 的前 42 个字节 (前 4 个字节为 Sig)
cdeHdrBuf[i] = (byte)(cdeHdrBuf[i] ^ xorCodeCDE[(i - 4) % xorCodeCDE.length]);
}
}
else if(sig != ZipConstants.CENSIG)
{ // 如果 Sig 既不等于 BPK 也不等于 ZIP
ZipFile.throwZipException("Central Directory Entry", sig); // 报错
}
it.seek(8);
this.gpbf = it.readShort() & 65535;
if((this.gpbf & 1) != 0)
{
throw new ZipException("Invalid General Purpose Bit Flag: " + this.gpbf); // 读取通用标志位,判断是否有 Data desc
}
// 获取 EOCD 中的几个数据
Charset charset = defaultCharset;
charset = (this.gpbf & 2048) != 0 ? StandardCharsets.UTF_8 : charset;
this.compressionMethod = it.readShort() & 65535;
this.time = it.readShort() & 65535;
this.modDate = it.readShort() & 65535;
this.crc = it.readInt() & 4294967295 L;
this.compressedSize = it.readInt() & 4294967295 L;
this.size = it.readInt() & 4294967295 L;
this.nameLength = it.readShort() & 65535;
int extraLength = it.readShort() & 65535;
int commentByteCount = it.readShort() & 65535;
it.seek(42);
this.localHeaderRelOffset = it.readInt() & 4294967295 L; // 获取 Local File Header 的偏移
byte[] nameBytes = new byte[this.nameLength]; // 获取文件名
Streams.readFully(cdStream, nameBytes, 0, nameBytes.length);
// 如果有加密 flag 则解密文件名
if(this.bbkEncrypted)
{
for(int i2 = 0; i2 < this.nameLength; i2++)
{
nameBytes[i2] = (byte)(nameBytes[i2] ^ xorCodeCDE[((i2 + 46) - 4) % xorCodeCDE.length]); // 解密文件名
}
}
if(containsNulByte(nameBytes))
{ // 如果文件名为空
throw new ZipException("Filename contains NUL byte: " + Arrays.toString(nameBytes));
}
this.name = new String(nameBytes, 0, nameBytes.length, charset);
if(extraLength > 0)
{ // 如果有扩展字段
this.extra = new byte[extraLength]; // 解密扩展字段
Streams.readFully(cdStream, this.extra, 0, extraLength);
if(this.bbkEncrypted)
{
for(int i3 = 0; i3 < extraLength; i3++)
{
byte[] bArr = this.extra;
bArr[i3] = (byte)(bArr[i3] ^ xorCodeCDE[(((this.nameLength + 46) + i3) - 4) % xorCodeCDE.length]);
}
}
}
if(commentByteCount > 0)
{ // 如果注释长度不为 0
byte[] commentBytes = new byte[commentByteCount]; // 解密注释部分
Streams.readFully(cdStream, commentBytes, 0, commentByteCount);
if(this.bbkEncrypted)
{
for(int i4 = 0; i4 < commentByteCount; i4++)
{
commentBytes[i4] = (byte)(commentBytes[i4] ^ xorCodeCDE[((((this.nameLength + 46) + extraLength) + i4) - 4) % xorCodeCDE.length]);
}
}
this.comment = new String(commentBytes, 0, commentBytes.length, charset);
}
}
从上面的代码中,我们已经可以得到了加解密 EOCD、CD 部分的方法,其核心部分为一个异或运算
byte[] xorCode = "...".getBytes();
ByteBuffer zipContents = inEOCD;
for(int i = 4; i < zipContents.capacity(); i++)
{
byte tmp = inEOCD.get(i);
byte[] bArr = xorCode;
zipContents = zipContents.put(i, (byte)(bArr[(i - 4) % bArr.length] ^ tmp));
}
return zipContents;
ZIP 和 BPK 的加解密
在上面,我们已经得到了 EOCD 和 CD 部分的加解密方法,而我们从 BPK 文件中可以推测出,FE 和 DD 部分也是被类似的方法加密的,只是异或用的字典不同
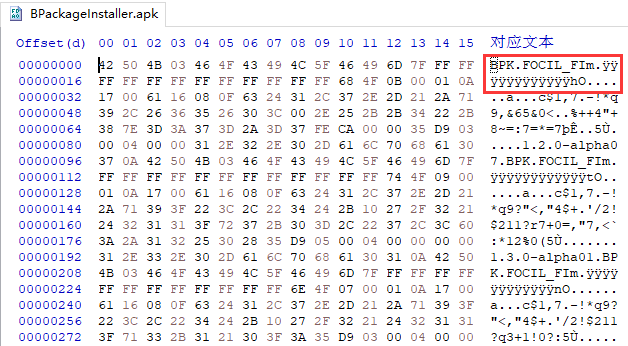
由 EOCD 和 CD 的异或字典可以猜出,FE 和 DD 部分的异或字典为
byte[] xorCodeLFH = "LOCAL_FILE_HEADER_XOR_CODE_OF_BBK_APK_ENCRYPTION".getBytes();
byte[] xorCodeDS = "DATA_DESCRIPTOR_XOR_CODE_OF_BBK_APK_ENCRYPTION".getBytes();
DD 部分可以使用以上方法加解密,不过 BPK 的 FE 部分还经过了其他处理
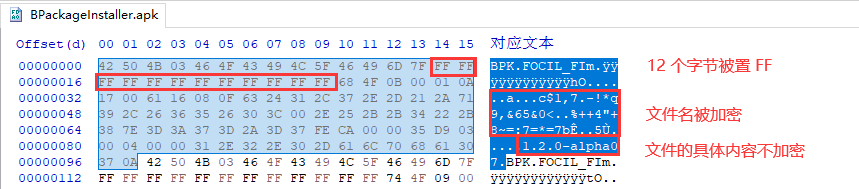
BPK 的 LFH 部分从的 14-26 字节中的 12 个字节被置 FF,所以在解密时,这部分的数据只能从 CD 中取得并还原到 LFH 中,加密时可以直接忽略,置空即可
文件名的加解密方法在上面的代码中都有了,而文件内容不加密,由此可以得到 BPK 的 FE 部分加密规则为:
取 LFH 的前 28 个字节异或,28 个字节中的第 14-26 个字节置空,LFH 的 28-30 字节 (即扩展字段长度) 不加密,文件名单独加密
如果这个 FE 有 DD,则 LFH 的第 14-26 个字节置 00,否则置 FF
以上就是 BPK 加密到 APK 的方法,因为加密均使用异或方式,可以完美解密,唯一要特殊处理的部分就是 LFH 中被置空的地方,要从 CD 里拿数据替换过来
后记
研究 BPK 的加解密花了 5 天吧,一开始死磕新系统的 libziparchive.so,IDA 看伪代码异常痛苦,后来想到老系统的直接在 service 里,Java 比伪代码舒服多了...
我对逆向、破解的兴趣始于研究步步高家教机,那么,把本文献给几年前的自己,和步步高家教机
2023/08/22
标签:加密,步步高,ZIP,int,EOCD,BPK,CD,byte From: https://www.cnblogs.com/azwhikaru/p/17659672.html