\(\operatorname{Tarjan}\) 基础用法
目录\(\operatorname{Tarjan}\) 求最近公共祖先
前置芝士
最近公共祖先(Lowest Common Ancestor , LCA):一棵树中两个结点的 公共祖先里面,离根最远的那个被称为最近公共祖先。我们记点集 \(S=\{v_1,v_2,\dots,v_n\}\) 的最近公共祖先为 \(\operatorname{LCA}(v_1,v_2,\dots,v_n)\) 或 \(\operatorname{LCA}(S)\)。
性质:
- \(\operatorname{LCA}(\{u\}=u)\);
- \(u\) 是 \(v\) 的祖先当且仅当 \(\operatorname{LCA}(u,v)=u\);
- 若 \(u\) 和 \(v\) 互相都不是对方的祖先,则 \(u,v\) 分别处于 \(\operatorname{LCA}(u,v)\) 的两棵不同子树中;
- 前序遍历,\(\operatorname{LCA}(S)\) 出现在所有 \(S\) 中元素之前,后序遍历,\(\operatorname{LCA}(S)\) 出现在所有 \(S\) 中元素之后;
- 两点集的并的最近公共祖先为两点集各自最近公共祖先的最近公共祖先,即\(\operatorname{LCA}(A \cup B)=\operatorname{LCA}(\operatorname{LCA}(A),\operatorname{LCA}(B))\);
- 两结点的最近公共祖先一定在其这两点最短路上
- 设 \(d\) 为树上两点间的距离,\(h\) 为一个点到树根的距离,则 \(d_{uv}=h_u+h_v-2h(\operatorname{LCA}(u,v))\)
实现过程
请注意啦,\(\operatorname{Tarjan}\) 是一个离线算法,所以只能处理离线的 \(\operatorname{LCA}\) 询问,在线需要使用其它方法。但是 \(\operatorname{Tarjan}\) 可以在一次搜索后求出所有点对的 \(\operatorname{LCA}\),所以仍然具有研究价值。
- 首先我们要建立两个链表,\(edge\) 用来存树,而 \(qedge\) 用来存储一种查询关系,即对于一个点 \(u\),\(qedge\) 要记录点 \(u\) 都与哪些其它点存在询问;
- 接下来我们对整棵树开始 \(\operatorname{DFS}\),用 \(vis\) 记录是否访问过,用 \(fa_i\) 表示 \(i\) 的父亲,由于 \(\operatorname{DFS}\) 的基本思想是每次只关心当前这一级,所以我们认为当前搜到的点 \(u\) 就是以 \(u\) 为根的子树的根,
这句话看似是废话其实也是废话,这么写是为了提醒读者在搜索开始时要把这个点的父亲设置为自己,也就是非常容易遗忘的初始化操作; - 回溯的时候将 \(fa_v\) 设置为 \(u\),也就是逐级递归找爸爸;
- 在回溯期间,如果包含当前节点的查询的另一个结点也访问过了,就可以更新这两个点的 \(\operatorname{LCA}\) 了;
- 最后统计输出答案的时候,不要忘记使用刚刚我们学到的最后一个性质来辅助我们。
核心代码就长这样:
void Tarjan(int u) {// 递归每一层都处理当前节点的子树
fa[u] = u;// 初始化
vis[u] = true;
for (int i = head[u]; i; i = edge[i].next) {// 向下搜索
int v = edge[i].to;
if (!vis[v]) {
Tarjan(v);
fa[v] = u;
}
}
for (int i = qhead[u]; i; i = qedge[i].next) {
// 搜索并标记含有 u 结点的所有询问
int v = qedge[i].to;
if (vis[v]) {// 两个结点必须都被标记过
qedge[i].lca = find(v);// 标记 LCA
// 2n-1与2n的结果相同
if (i % 2) { qedge[i + 1].lca = qedge[i].lca; }
else { qedge[i - 1].lca = qedge[i].lca; }
}
}
}
例题
这就是个模板题,把上面那段代码套上去补完剩下的建图部分就可以了,所以不必过多赘述。
参考代码:
#include <iostream>
#include <cstdio>
using namespace std;
namespace SHAWN {
const int N = 1e6 + 7;
int head[N], cnt;
int qhead[N], qcnt;
struct node { int to, next, lca; };
node edge[N], qedge[N];
int n, m, s;
int fa[N];
bool vis[N];
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
inline void qadd(int u, int v) {
qedge[++qcnt].next = qhead[u];
qedge[qcnt].to = v;
qhead[u] = qcnt;
}
int find(int x) {
return x == fa[x] ? x : fa[x] = find(fa[x]);
}
void Tarjan(int u) {
fa[u] = u;
vis[u] = true;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!vis[v]) {
Tarjan(v);
fa[v] = u;
}
}
for (int i = qhead[u]; i; i = qedge[i].next) {
int v = qedge[i].to;
if (vis[v]) {
qedge[i].lca = find(v);
if (i % 2) { qedge[i + 1].lca = qedge[i].lca; }
else { qedge[i - 1].lca = qedge[i].lca; }
}
}
}
int work()
{
cin >> n >> m >> s;
for (int i = 1, x, y; i < n; ++i) {
cin >> x >> y;
add(x, y); add(y, x);
}
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
qadd(x, y); qadd(y, x);
}
Tarjan(s);
for (int i = 1; i <= m; ++i) {
cout << qedge[i << 1].lca << '\n';
}
return 0;
}
}
signed int main() {
ios :: sync_with_stdio(false);
cin.tie(nullptr);
return SHAWN :: work();
}
\(\operatorname{Tarjan}\) 求割点、割边
前置芝士
割点:在一个无向连通图 \(G(V,E)\) 中,删去结点 \(u\) 和与它相连的边后,若该图变为非连通图,则称结点 \(u\) 为该图的割点(关节点)。
割边:在一个无向连通图 \(G(V,E)\) 中,删去边 \(e\) 后,若该图变为非连通图,则称边 \(e\) 为该图的割边(桥)。
如下图中的 \(2\) 点和 \(6\) 点为割点,边 \((1,2)\) 和边 \((6,7)\) 为割边:
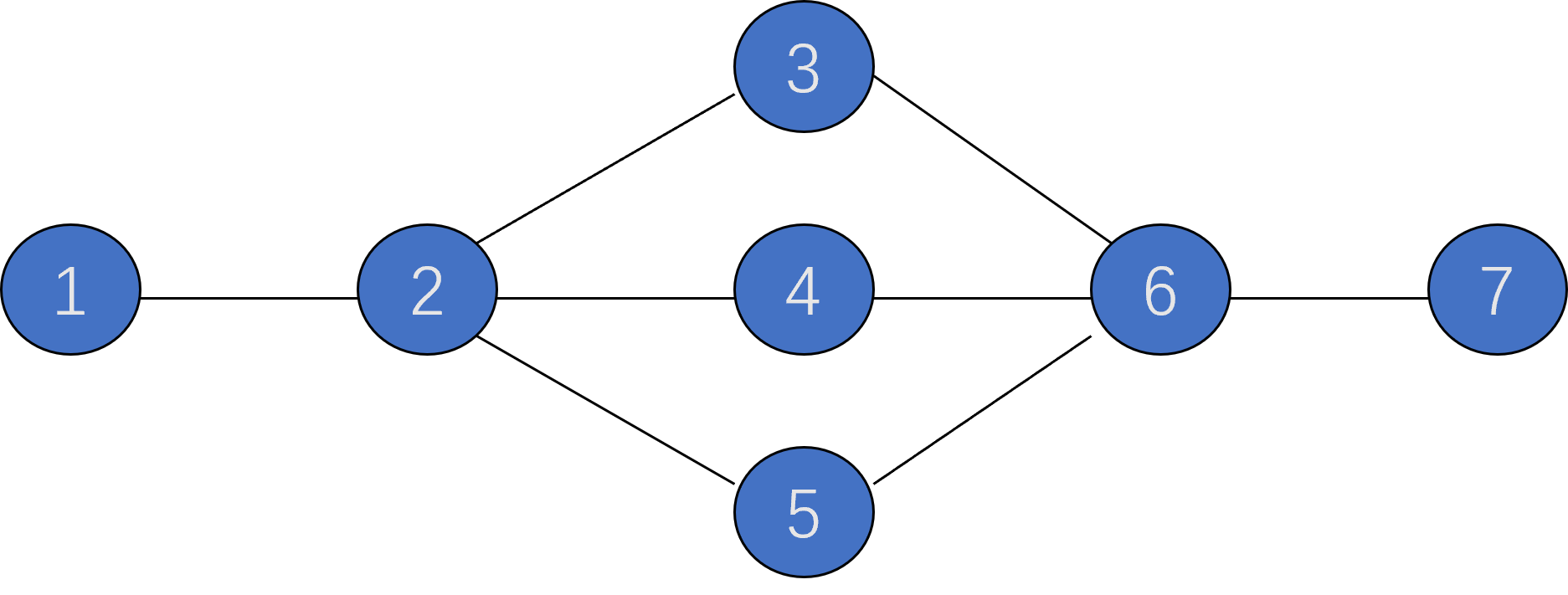
重连通图:一个不含割点的连通图称为重连通图(双连通图)。重连通无向图重每对顶点之间至少存在两条路径,下图就是一个重连通图:

一些性质:
- 两个割点之间的边不一定是割边
- 割边的两个端点不一定都是割点,但一定有一个是割点
\(\operatorname{Tarjan}\) 求割点
比方说我们对刚刚这个图求割点:
我们从结点 \(2\) 开始深度优先遍历,可以得到如下深度优先生成树,实线边构成树边,虚线边构成回边:

设原图为 \(G(V,E)\),其深度优先生成树为 \(T(V,E)\) ,则 \(G\) 和 \(T\) 具有如下的性质:
- \(\forall u \in V(T)\) ,要么是根,要么不是根
- \(u\) 为根时,\(u\) 是割点 $\Leftrightarrow $ \(u\) 有 \(2\) 棵或 \(2\) 棵以上的子树
- \(u\) 不为根时,\(u\) 是割点 $\Leftrightarrow $ \(u\) 存在儿子 \(v\) 使得 \(low_v \ge dfn_u\)
我们发现性质里有一些陌生的东西,\(dfn\) 和 \(low\),这两个东西分别叫做深度优先数和最低深度优先数。我们在刚刚 \(\operatorname{DFS}\) 遍历的时候按照 \(\operatorname{DFS}\) 序给每个结点打上时间戳,这些时间戳就是深度优先数,我们用 \(dfn\) 数组来存储它。如上图生成树中,\(dfn_2=1\),\(dfn_1=2\),\(dfn_3=3\),\(dfn_4=5\),\(dfn_5=6\),\(dfn_6=4\),\(dfn_7=7\)。而最低深度优先数 \(low\) 则表示从结点 \(u\) 出发能到达的点的最小深度优先数,其决定式如下:
\[low_u=min\left\{\begin{matrix} dfn_u\\ low_v(u,v\in V(T),v是u的孩子)\\ dfn_v(u,v\in V(T),(u,v)是一条回边) \end{matrix}\right. \]那么知道了这些我们再回过头去看刚刚第三个性质,当 \(v\) 是 \(u\) 的儿子且 \(low_v<dfn_u\) 时,以 \(v\) 为根节点的子树中必然有节点与 \(u\) 的祖先有回边,如果 \(u\) 的任意儿子都满足这个特点时,\(u\) 显然不是割点。
参考代码:
namespace SHAWN {
const int N = 2e5 + 7;// 双向边开二倍空间
int head[N], cnt;
struct edge{ int to, next; }edge[N];
int dfn[N], low[N];
bool used[N], flag[N];
int n, m, res, tim;
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u, int fa) {
used[u] = true;
low[u] = dfn[u] = ++tim;
int child = 0;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!used[v]) {
if (fa == u) { ++child; }
Tarjan(v, u);
// 如果v是u的孩子
low[u] = min(low[u], low[v]);
// 如果u不是根且low[u] >= dfn[u]就是割点
if (fa != u && low[v] >= dfn[u] && !flag[u]) {
flag[u] = true;
++res;
}
}
// 如果(u,v)是一条回边
else if (fa != v) {
low[u] = min(low[u], dfn[v]);
}
}
// 如果u是根且有两个或两个以上子树就是割点
if (fa == u && child >= 2 && !flag[u]) {
flag[u] = true;
++res;
}
}
int work()
{
cin >> n >> m;
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
add(x, y); add(y, x);
}
// 不保证连通所以要多次跑
for (int i = 1; i <= n; ++i) {
if (!used[i]) {
tim = 0;
Tarjan(i, i);
}
}
cout << res << '\n';
for (int i = 1; i <= n; ++i) {
if (flag[i]) { cout << i << ' '; }
}
return 0;
}
}
\(\operatorname{Tarjan}\) 求割边
设原图为 \(G(V,E)\),其深度优先生成树为 \(T(V,E)\) ,则 \(G\) 和 \(T\) 满足如下定理:
\(\exists u,v \in T\),\(u\) 是 \(v\) 的双亲,\(u,v\) 之间的边不是有重边,则 \((u,v)\) 是割边 $\Leftrightarrow $ \(u\) 到 \(v\) 的边不是重边且 \(v\) 或 \(v\) 的子孙结点中没有指向 \(u\) 或着 \(u\) 的祖先的回边。即 \((u,v)\) 是割边 \(\Leftrightarrow\) \(dfn_u<low_v\)。
然后我们把刚刚代码稍微改一改就出来了,像这样:
void Tarjan(int u, int fa) {
par[u] = fa;
low[u] = dfn[u] = ++tim;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!dfn(v)) {
Tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
flag[v] = true;
++res;
}
}
else if (dfn[v] < dfn[u] && v != fa) }{
low[u] = min(low[u], dfn[v]);
}
}
}
最后当 \(flag_u\) 为真时,边 \((u,par_u)\) 就是割边。
参考代码:
namespace SHAWN {
const int N = 1e4 + 7;
int head[N], cnt;
struct edge { int to, next; }edge[N];
struct node { int a, b; };
int dfn[N], low[N];
int n, m, tim;
struct cmp{
bool operator() (const node &x, const node &y) const {
if (x.a != y.a) { return x.a > y.a; }
else { return x.b > y.b; }
}
};
priority_queue<node, vector<node>, cmp> q;
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u, int fa) {
low[u] = dfn[u] = ++tim;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!dfn[v]) {
Tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
q.push({u,v});
}
}
else if (dfn[v] < dfn[u] && v != fa) {
low[u] = min(low[u], dfn[v]);
}
}
}
int work()
{
cin >> n >> m;
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
add(x, y); add(y, x);
}
for (int i = 1; i <= n; ++i) {
if (!dfn[i]) {
Tarjan(i, i);
}
}
while (!q.empty()) {
auto it = q.top(); q.pop();
cout << it.a << ' ' << it.b << '\n';
}
return 0;
}
}
例题
题目分析
题目要求我们删掉一个点使得给定的两个点不连通,那么其实我们就是要找一个满足要求的割点,如下图标黑的点就是题目给定的两个点:

点 \(1\) 是一个割点,我们删除点 \(1\) 即可使得 \(2,4\) 两点不连通,但是并非任意割点都满足要求,比方说下面这张图:

点 \(3\) 和点 \(4\) 都是图中的割点,但是删去 \(4\) 并不能使得目标点 \(1,7\) 不连通,所以只有点 \(3\) 是符合条件的点,那么我们就要去筛选割点中符合要求的点。
怎么筛呢?其实我们想一想建立 \(\operatorname{DFS}\) 树的过程,我们从题中给定的一个点开始搜,那么对于一个符合条件的割点来讲,题中给定的另一个点一定在这个符合条件的割点的子树中。所以在搜的时候加个判断条件就好了。本题因为不能删去根,所以不用考虑根是割点的情况,那么代码也就非常简单:
#include <iostream>
#include <cstdio>
using namespace std;
namespace SHAWN {
const int N = 1e6 + 7;
int head[N], cnt;
struct edge { int to, next; }edge[N];
int n, tim, x, y;
int dfn[N], low[N];
bool vis[N], flag[N];
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u, int fa) {
low[u] = dfn[u] = ++tim;
vis[u] = true;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!vis[v]) {
Tarjan(v, u);
low[u] = min(low[u], low[v]);
// 这里多加一个u!=x和dfn[y]>=dfn[v]的特判就OK了
if (fa != u && low[v] >= dfn[u] && u != x && dfn[y] >= dfn[v]) {
flag[u] = true;
}
}
else if (fa != v) {
low[u] = min(low[u], dfn[v]);
}
}
}
int work()
{
cin >> n;
while (cin >> x >> y && x && y) {
add(x, y); add(y, x);
}
cin >> x >> y;
Tarjan(x, x);
for (int i = 1; i <= n; ++i) {
if (flag[i]) {
cout << i << '\n';
return 0;
}
}
cout << "No solution\n";
return 0;
}
}
signed int main() {
ios :: sync_with_stdio(false);
cin.tie(nullptr);
return SHAWN :: work();
}
2、割边 [CEOI2005] Critical Network Lines
题目分析
与上一道题一样,我们显然可以看出来题目想让我们求出满足下面条件的割边——删掉这条边后剩下的两个连通块中至少一个块只包含 \(A\) 类点或 \(B\) 类点。比如下图(图中边上的数字是编号不是边权):

这幅图中的割边有 \(1,4,5,6,8\) 五条,而符合题目条件的只有 \(1,6,8\) 这三条。我们发现,当一个割边满足条件当且仅当它连接的一个节点在深度优先生成树中的子树内只包含一类点。所以我们在 \(\operatorname{Tarjan}\) 求割边的时候,每找到一条割边 \((u,v)\),我们就检查一下以 \(v\) 为根结点的子树内 \(A\) 和 \(B\) 类结点各自的数量,当其中一个个数为 \(0\) 或者全满,就是要求的边,打上标记并给计数的答案加一就可以了。求数量的过程,可以在 \(\operatorname{DFS}\) 的时候递归计算。下面是 AC 代码:
#include <iostream>
#include <cstdio>
using namespace std;
namespace SHAWN {
const int N = 2e6 + 7;
// 请注意这里一定要开二倍空间,要不然会寄
int head[N], cnt;
struct edge { int to, next; }edge[N];
int n, m, a, b, tim, res;
int dfn[N], low[N], acnt[N], bcnt[N], par[N];
// acnt[i]表示i结点子树中A类点数量,bcnt同理
// par用来记每个结点在dfs生成树中的父亲
bool flag[N];
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u, int fa) {
low[u] = dfn[u] = ++tim;
par[u] = fa;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!dfn[v]) {
Tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
if (!acnt[v] || !bcnt[v] || acnt[v] == a || bcnt[v] == b) {
// A类或B类有一个为0或全满就说明符合要求
flag[v] = true;
++res;
}
}
acnt[u] += acnt[v]; bcnt[u] += bcnt[v];
// 从下向上递归统计子树情况
}
else if (dfn[v] < dfn[u] && fa != v) {
low[u] = min(low[u], dfn[v]);
}
}
}
int work()
{
cin >> n >> m >> a >> b;
for (int i = 1, x; i <= a; ++i) { cin >> x; acnt[x] = 1; }
for (int i = 1, x; i <= b; ++i) { cin >> x; bcnt[x] = 1; }
// 最开始每个点的子树就是自己
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
add(x, y); add(y, x);
}
Tarjan(1, 0);
cout << res << '\n';
for (int i = 1; i <= n; ++i) {
if (flag[i]) {
cout << i << ' ' << par[i] << '\n';
}
}
return 0;
}
}
signed int main() {
ios :: sync_with_stdio(false);
cin.tie(nullptr);
return SHAWN :: work();
}
\(\operatorname{Tarjan}\) 求强连通分量
前置芝士
强连通:在有向图 \(G\) 中,如果两个顶点 \(u_i,u_j\) 间 \((u_i \ne u_j)\) 有一条从 \(u_i\) 到 \(u_j\) 的有向路径,同时还有一条从 \(u_j\) 到 \(u_i\) 的有向路径,则称两个顶点强连通(Strongly Connected, SC)。
强连通图:有向图 \(G\) 中,若任意两点强连通,则称 \(G\) 是一个强连通图。
强连通分量(Strongly Connected Components, SCC):极大的强连通子图。

如图是一个强连通图,图上的强连通分量有三个:\(a-b-c-d,e,f\)。
缩点:因为强连通图中任意两点连通,所以在不考虑路径长度只考虑连通性的情况下,可以将一个强连通分量压缩成一个点来进行处理,这样就可以缩小图的规模。
实现过程
我们算法的主要过程与步骤如下:
- 从根开始向下搜索,实时更新 \(dfn\) 和 \(low\),每搜到一个点就入栈;
- 当 \(v\) 未被访问过,我们继续深搜,在回溯过程中,用 \(low_v\) 更新 \(low_u\),当回溯到某一个点 \(u\) 使得 \(dfn_u=low_u\) 时,弹栈直到把自己也弹出来,这些弹出来的元素就是一个强连通分量;
- 当 \(v\) 被访问过且已经在栈中,就像前面一样用 \(dfn_v\) 更新 \(low_u\);
- 当 \(v\) 被访问过且不在栈中,不操作。
下面给出一个例子来帮助读者理解这一过程:

- 如图 (a),从 \(1\) 开始搜,\(1\) 入栈,\(dfn_1=low_1=1\);
- 如图 (b),搜到 \(2\),\(2\) 入栈,搜到 \(3\),\(3\) 入栈,搜到 \(4\),\(4\) 入栈,接下来通过返祖边搜到了 \(2\),\(low_4=2\);
- 如图 (c),返回 \(3\),\(low_3=2\),返回 \(2\),\(low_2=2\),此时 \(low_2=dfn_2=2\),所以找到了一个强连通分量,弹栈直到自己得到连通分量 \(\{2,3,4\}\);
- 如图 (d),返回 \(1\),搜到 \(5\) 入栈,搜到 \(6\) 入栈,连向 \(3\) 有一条横向边,但 \(3\) 不在栈里,所以不管,搜到 \(7\) 入栈,然后搜不下去了,\(low_7=dfn_7=7\),弹栈直到自己得到连通分量 \(\{7\}\);
- 如图 (e),返回 \(6\),\(low_6=dfn_6=6\),弹栈知直到自己得到连通分量 \(\{6\}\),回到 \(5\),访问过了但是 \(dfn\) 和 \(low\) 更新后没变,搜到 \(8\),接下来通过返祖边搜到了 \(1\),\(low_8=1\);
- 如图 (f),返回 \(5\),\(low_5=1\),返回 \(1\),前向边搜到 \(8\),更新后没变所以不管,返回 \(1\),\(low_1=dfn_1=1\),弹栈直到自己得到连通分量 \(\{1,5,8\}\)。
代码大概就长这样:
namespace SHAWN {
const int N = 1e5 + 10;
int head[N], cnt;
struct edge { int to, next; }edge[N];
int n, m, tim, top, idx;
int dfn[N], low[N], st[N], size[N], scc[N];
bool chkin[N];
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u) {
low[u] = dfn[u] = ++tim;
st[++top] = u;// 搜到就入栈
chkin[u] = true;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!dfn[v]) {
Tarjan(v);
low[u] = min(low[u], low[v]);
}
else if (chkin[v]) {
low[u] = min(low[u], dfn[v]);
}
}
if (low[u] == dfn[u]) {
//low[u]=dfn[u]时弹栈直到自己
int v; ++idx;
do {
v = st[top--];
scc[v] = idx;
chkin[v] = false;
++size[idx];
} while (v != u);
}
}
int work()
{
cin >> n >> m;
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
add(x, y);
}
for (int i = 1; i <= n; ++i) {
if (!dfn[i]) {
Tarjan(i);
}
}
int ans = 0;
for (int i = 1; i <= idx; ++i) {
ans += (size[i] > 1);
}
cout << ans << '\n';
for (int i = 1; i <= n; ++i) {
cout << scc[i] << ' ';
}
return 0;
}
}
例题
1、P2341 USACO03FALL / HAOI2006 受欢迎的牛 G
我们考虑如何建模。一只奶牛喜欢另一只奶牛可以表示为有向图上的一条有向边,因为爱慕关系具有传递性,所以能和其余所有点都连通的结点就是一个可行答案。我们如何去优化这个问题呢?考虑在强连通分量中,因为所有点都互相连通,所以我们可以进行缩点。缩点后如果只有一个出度为 \(0\) 的点,那么答案就是这个强连通分量中包含的结点个数。如果有多个出度为 \(0\) 的点或根本没有出度为 \(0\) 的点,就没有明星牛。这怎么理解呢?缩点以后点内奶牛不再互相爱慕,对于整个图,只有不爱慕别的牛的牛才能成为明星奶牛(看看,多不好),但如果大家都不爱慕别的牛了显然也不符合要求,所以我们有了这样的判断。那么代码就是上面的题小改了一下:
#include <iostream>
#include <cstdio>
using namespace std;
namespace SHAWN {
const int N = 5e4 + 7;
int head[N], cnt;
struct edge { int to, next; }edge[N];
int n, m, tim, top, idx, cont, ans;
int dfn[N], low[N], size[N], sta[N], scc[N], diag[N];
bool chkin[N];
inline void add(int u, int v) {
edge[++cnt].next = head[u];
edge[cnt].to = v;
head[u] = cnt;
}
void Tarjan(int u) {
low[u] = dfn[u] = ++tim;
sta[++top] = u;
chkin[u] = true;
for (int i = head[u]; i; i = edge[i].next) {
int v = edge[i].to;
if (!dfn[v]) {
Tarjan(v);
low[u] = min(low[u], low[v]);
}
else if (chkin[v]) {
low[u] = min(low[u], dfn[v]);
}
}
if (low[u] == dfn[u]) {
int v; ++idx;
do {
v = sta[top--];
scc[v] = idx;
chkin[v] = false;
++size[idx];
} while (v != u);
}
}
int work()
{
cin >> n >> m;
for (int i = 1, x, y; i <= m; ++i) {
cin >> x >> y;
add(x, y);
}
for (int i = 1; i <= n; ++i) {
if (!dfn[i]) {
Tarjan(i);
}
}
for (int i = 1; i <= n; ++i) {
for (int j = head[i]; j; j = edge[j].next) {
int v = edge[j].to;
if (scc[i] != scc[v]) {
++diag[scc[i]];
}
}
}
for (int i = 1; i <= idx; ++i) {
if (!diag[i]) {
++cont;
ans += size[i];
}
}
if (cont == 1) { cout << ans << '\n'; }
else { cout << "0\n"; }
return 0;
}
}
signed int main() {
ios :: sync_with_stdio(false);
cin.tie(nullptr);
return SHAWN :: work();
}
总结
我们总共总结了 \(\operatorname{Tarjan}\) 算法的三种主要用法,其实与其说它是一种算法,不如说它是一种 \(\operatorname{DFS}\) 时的思想,也就是通过对于图上点先后访问关系来形成一棵 \(\operatorname{DFS}\) 生成树,用回溯的方法在树上对点对之间的关系进行操作和处理,最终得到我们想要的最近公共祖先,割点,割边或者强连通分量。而我们在运用这些方法的时候也要做到灵活变通,仔细考虑题目中给定的点边关系,然后再将统计答案的步骤加入到搜索的过程中来通过递归和筛选得到我们想要的答案。
以上内容如有错误或不严谨的地方,请各位巨佬指正,orz
参考文献
- 汪星明 Tarjan相关算法及其应用
- OI-Wiki 最近公共祖先
- 江屿 tarjan算法求LCA
- OI-Wiki 割点和桥
- OI-Wiki 强连通分量
- 洛谷网校《深入浅出程序设计竞赛进阶篇》