起初没有人在意这场GC,直到它影响到了每一天!
前言
本文记录了一次排查FullGC导致的TP99过高过程,介绍了一些排查时思路,线索以及工具的使用,希望能够帮助一些新手在排查问题没有很好的思路时,提供一些思路,让小白也能轻松解决FullGC问题,文中实际提到的参数配置不一定适合其他业务场景,在调优自己的项目时还是需要实际试验过才能得出最佳参数配置
我也是小白,如有不合理的地方,欢迎大佬们进行指正
因为线上服务器,我们大部分是没有SSH权限的,没有办法直接执行命令获取容器信息,所以排查过程中只能借助平台提供的工具,平台提供的工具还是挺全的,本文主要用到的工具有: JDOS容器智能监控,JDOS进程查询,SGM容器监控信息,SGM方法调用查询
以下几个工具简单介绍:
http://sgm-server.jd.com/
http://jagile.jd.com/jdosCD/jdt/apps
JDOS容器智能监控: 查看容器的CPU,内存,磁盘,IO等信息
JDOS进程查询: 查看Java进程编号,执行常用的Java内存进程查看命令
SGM容器监控信息: 查看JVM虚拟机内存变更历史记录
SGM方法调用查询: 查看某一次关键接口调用的上下依赖,时间分布
起因 - 偶尔出现接口超时
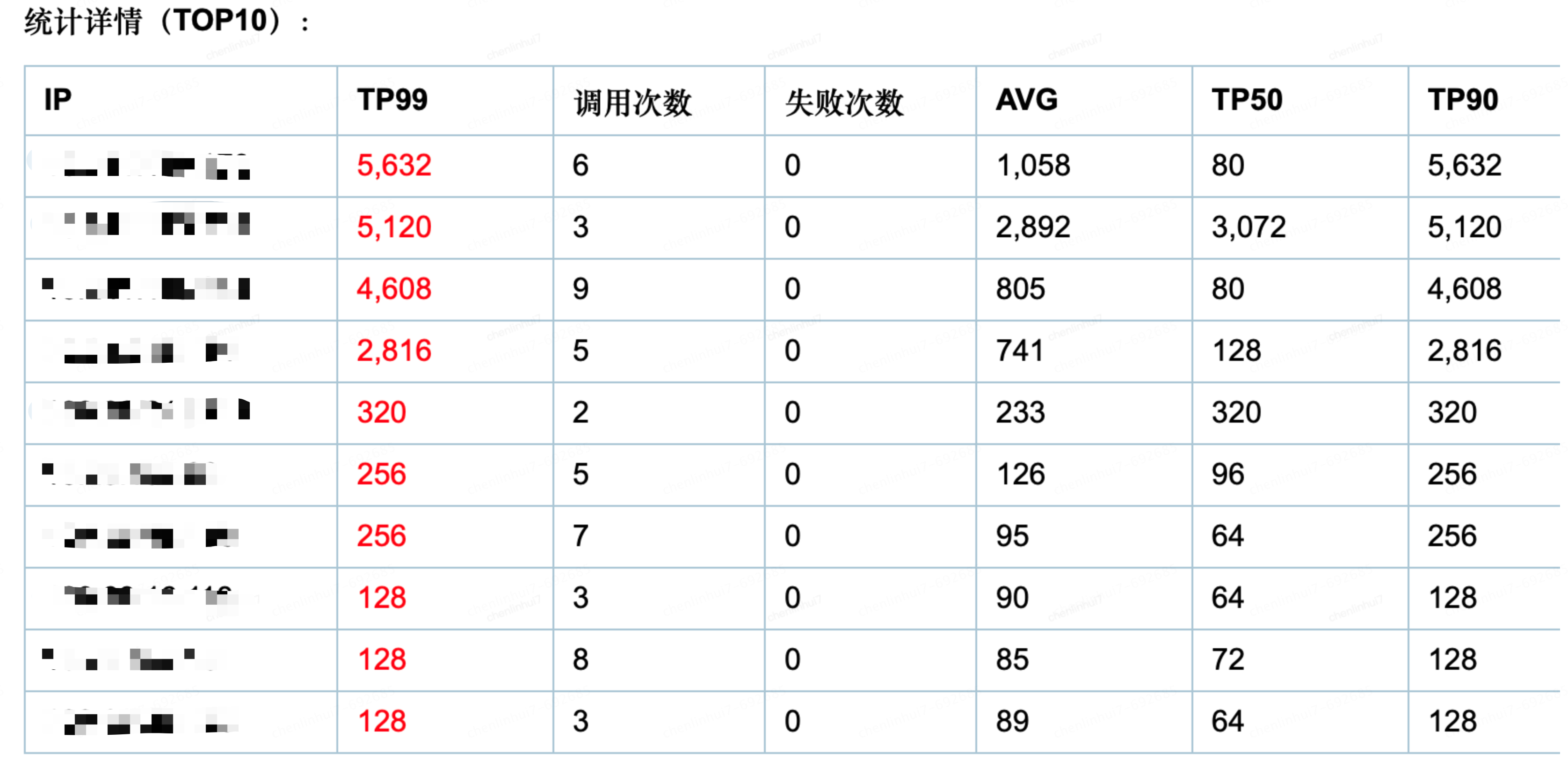
一开始偶尔会收到报警邮件,显示有些接口调用时间比较长,抽查了一些接口,发现大部分都是调用下游JSF时间比较长,导致响应比较慢,这时候就没太在意,接下来继续观察了几天,发现一个规律,大部分邮件都是每天10点
排查定位问题
-
首先确认了10点这个时间点有没有定时任务之类的操作,经过询问确定这个时间点是仓库出库高峰期,导致业务量出现峰值(调用量变大可能是激发FullGC问题,成为问题暴漏的导火线)
-
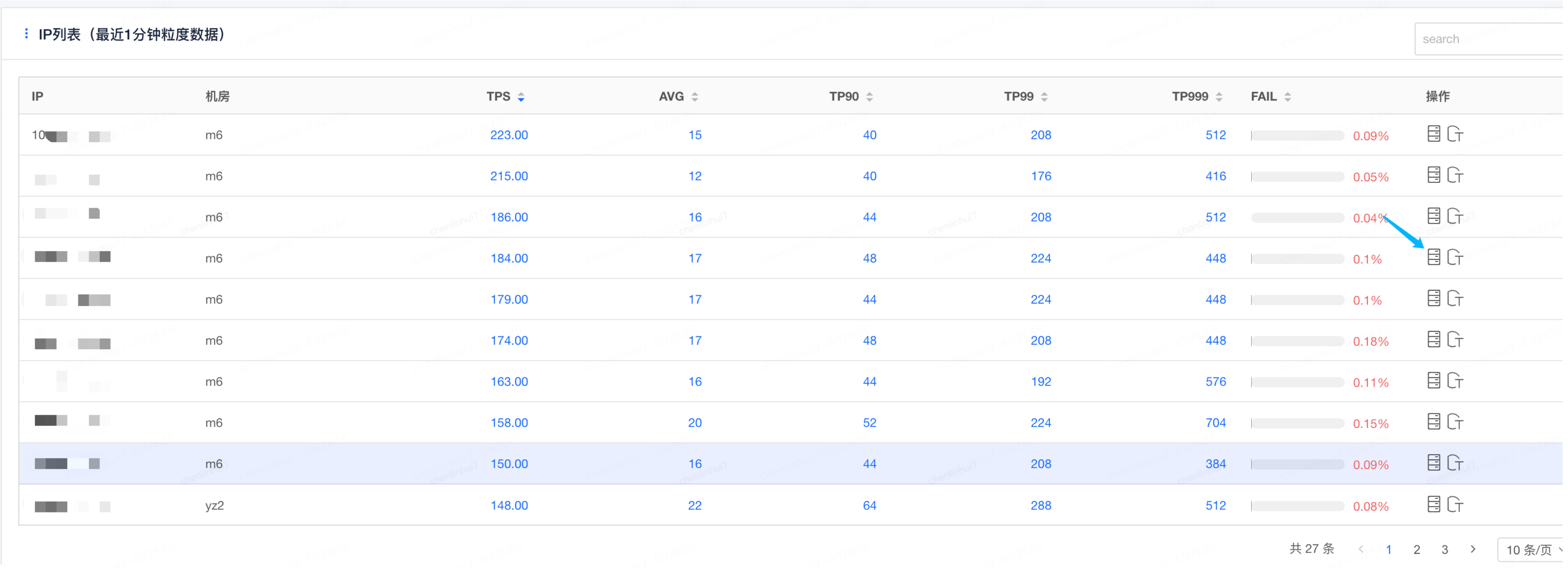
第二部就是确认是数据库原因,还是业务代码,还是JSF下游接口达到极限原因,到这一步还是未知的,在这用到了SGM的接口调用查询工具,下图中我们看到,这次调用JSF也是挺高的(这个没有太好办法,除非让下游优化,所以暂时忽略),但是还有一个是logic,这个就是逻辑处理,如果没有那个FullGC提示,就需要去分析代码的处理是否有问题,这通过那行红色字体的提示,很显然我们确定了是FullGC导致的问题
-
我们去查看一下容器的FullGC情况,确实发现这个时间点的FullGC特别频繁,到此已经把问题范围定位到就是FullGC导致的
FullGC问题排查
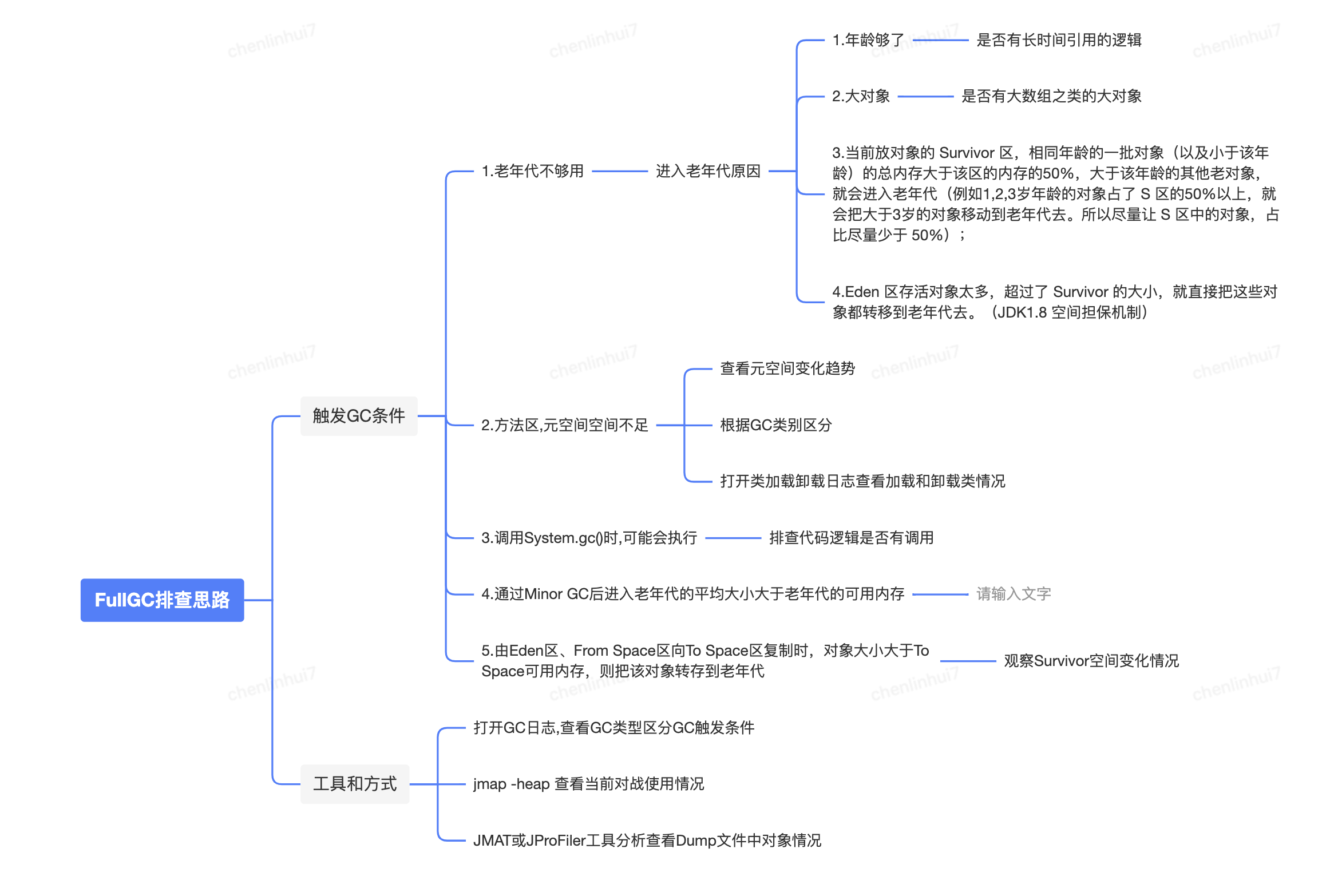
Full GC 触发条件:
到这里我们需要确定一个问题 : “触发FullGC的条件是什么?”,新手可以去博客搜索,当然最好是能记住这个知识点。注意这不是确定“什么原因导致的FullGC?”,因为这个问题原因太多了,我们要一步一步排查。 下面是我查到的资料,粘到这里供参考.
-
Minor GC触发条件:当Eden区满时,触发Minor GC。
-
Full GC触发条件:
- (1)调用System.gc()时,系统建议执行Full GC,但是不必然执
- (2)老年代空间不足
- (3)方法区空间不足
- (4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
- (5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代
这里在代码中并没有找到System.gc()的显示调用,一般我们也不会调用这个方法,所以我们直接看第二种情况,到SGM中查看老年代变化,结果发现老年代频繁达到90%,而这个时间正好可以跟上面GC时间对上.
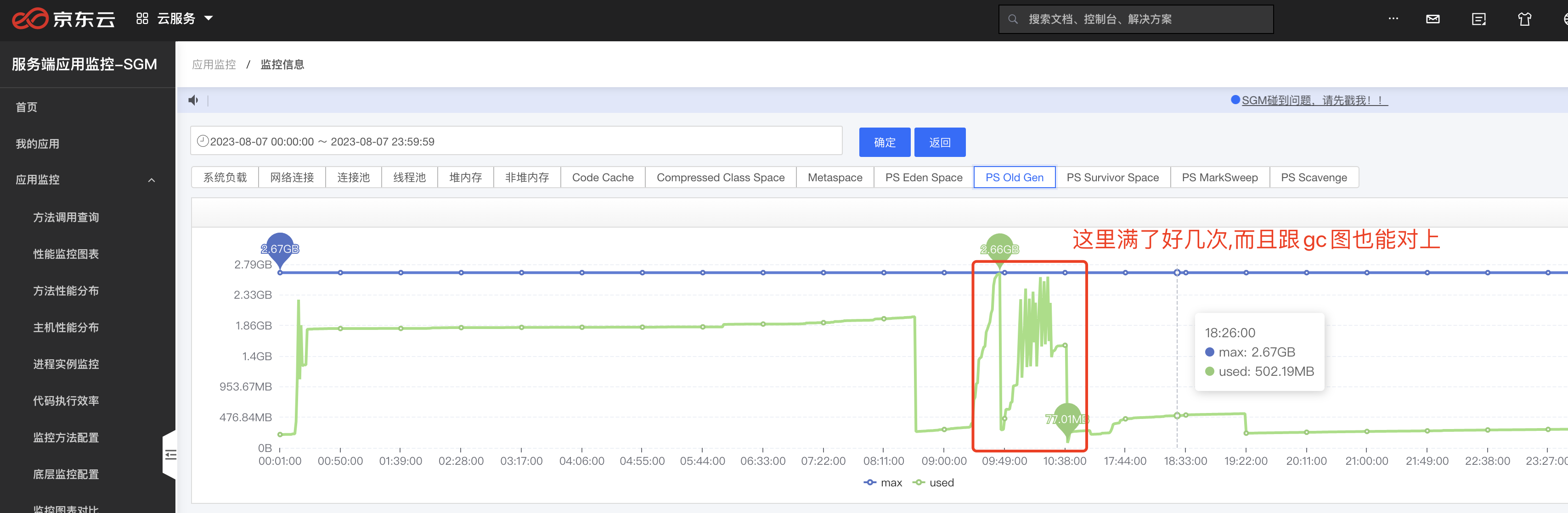
对象进入老年代的几种情况
我们都知道,老年代的对象应该是存活时间很长的对象,但是我们发现这些对象都在FullGC时被释放掉了,他们为什么到了老年代呢? 这时候我们需要确定的第二个问题是:“什么情况下对象会进入老年代?” 查资料后有以下几种情况
-
年龄够了: 躲过15次(默认配置是15次) minorGC 之后从新生代进入老年代;
-
大对象: 大对象直接进入老年代。有一个 JVM 参数 '-XX:PretenureSizeThreshold' 设置值为字节数,创建超过该大小的对象直接进入老年代,如果没有配置这个参数,这个值好像默认是1M。
-
动态年龄判断:当前放对象的 Survivor 区,相同年龄的一批对象(以及小于该年龄)的总内存大于该区的内存的50%,大于该年龄的其他老对象,就会进入老年代(例如1,2,3岁年龄的对象占了 S 区的50%以上,就会把大于3岁的对象移动到老年代去。所以尽量让 S 区中的对象,占比尽量少于 50%);
-
剩的总量太多: Eden 区存活对象太多,超过了 Survivor 的大小,就直接把这些对象都转移到老年代去。(JDK1.8 空间担保机制)
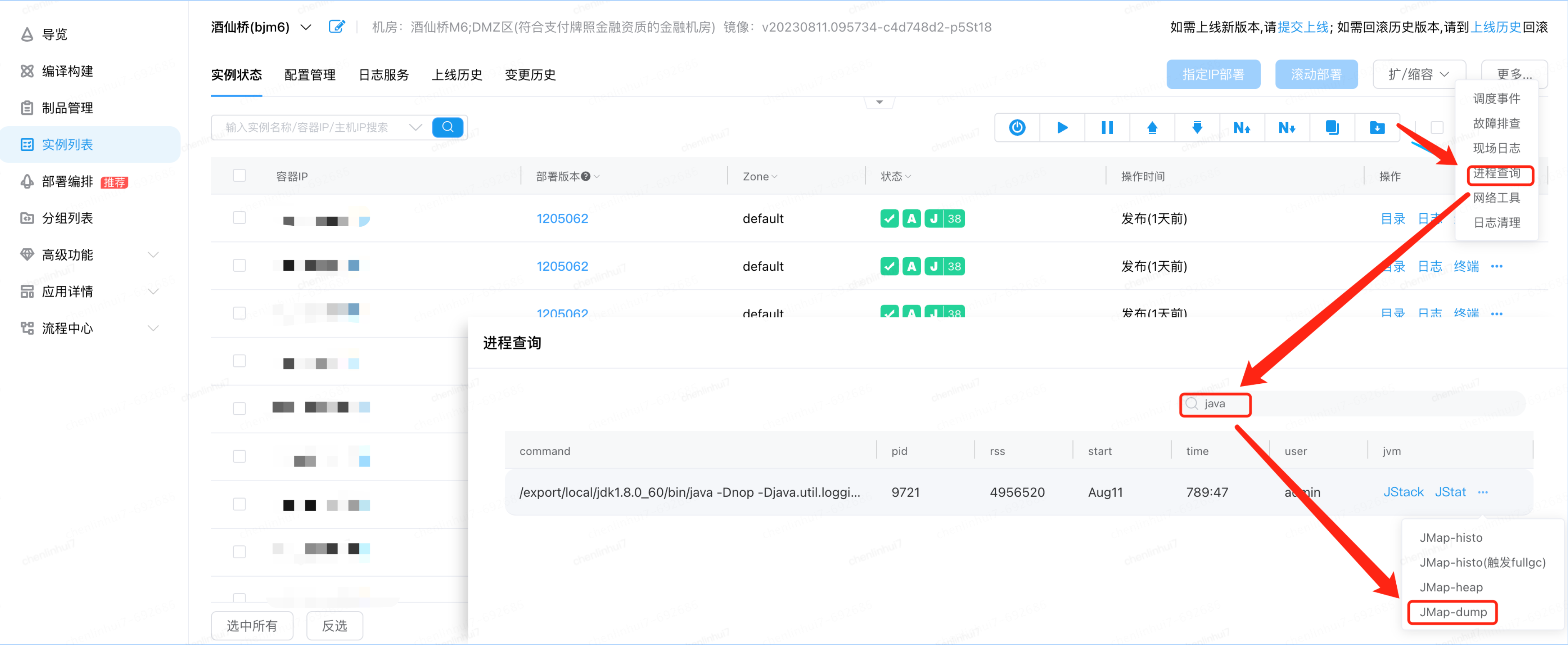
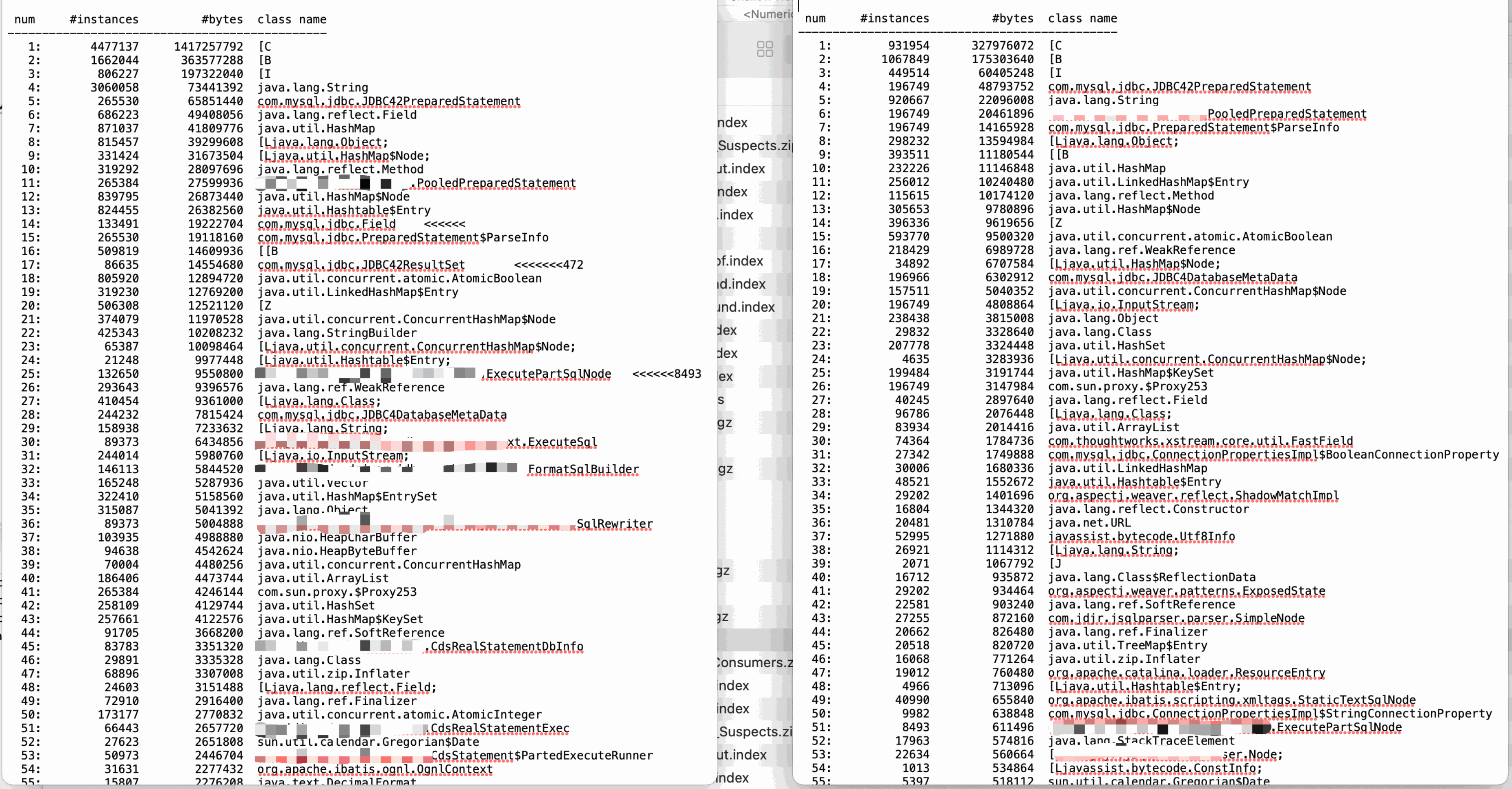
首先分析第一种情况,如果出现大批量这样的对象,代码中出现了长时间引用(例如:静态Map只加不删),但是我们可以看到,这些对象在每次FullGC都被释放掉了,说明这批对象存活的时间并不长, 而且代码排查也没发现这种代码,暂时排除这种情况(这的代码因为是工具包的代码,所以没有太深纠,这为续集留个伏笔). 第二种情况,大对象,我们到JDOS下载下来JMap-dump内存快照和JMap-Histo对象统计信息,经过对FullGC钱dump分析,结合GC前GC后对象统计结果,并没有发现大量的大对象,这个基本也排除
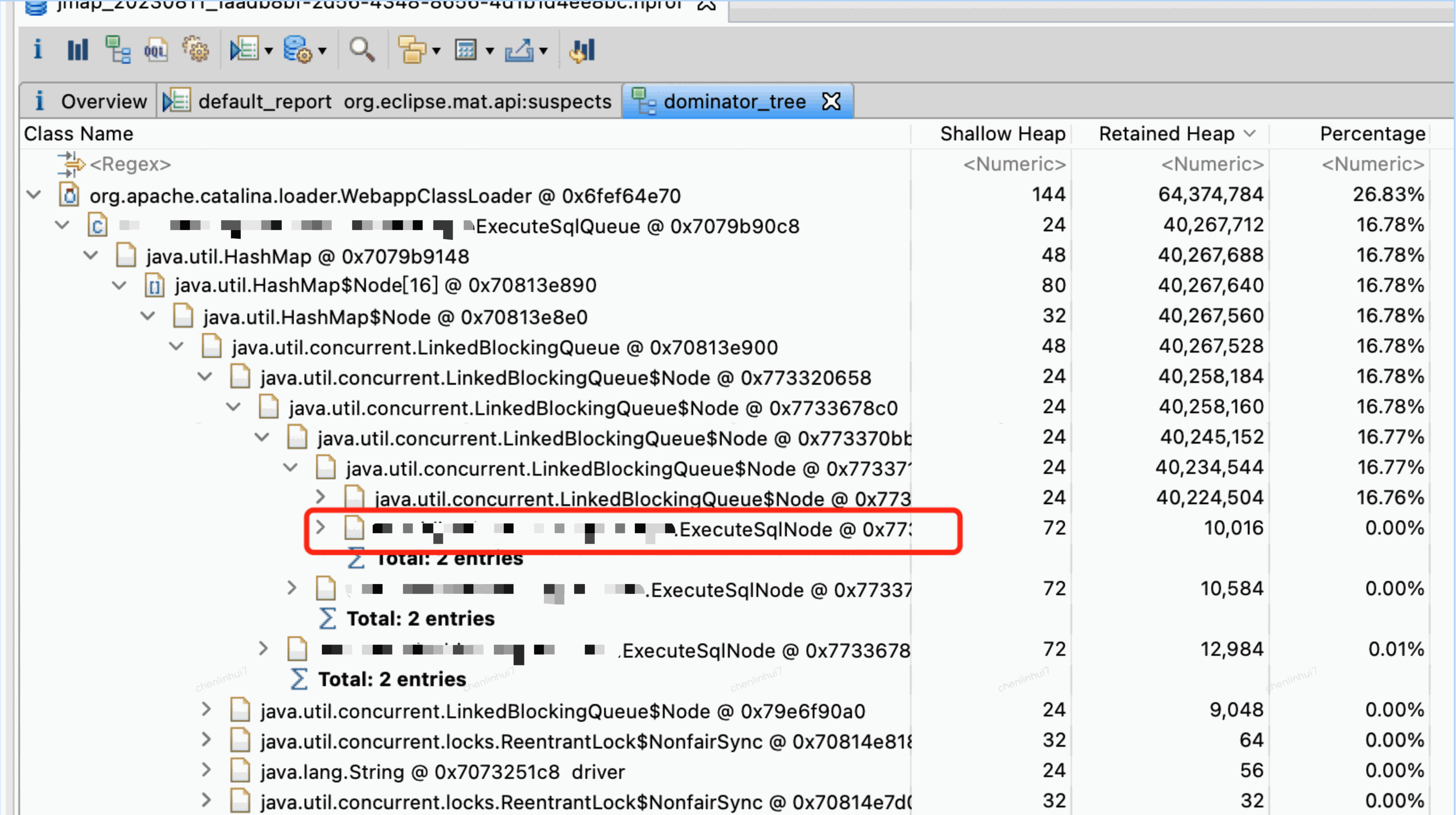
通过JMAT(Eclipse Memory Analysis Tools)导入dump文件进行分析,内存泄漏问题一般我们直接选Leak Suspects即可,mat给出了内存泄漏的建议。另外也可以选择Top Consumers来查看最大对象报告。和线程相关的问题可以选择thread overview进行分析。除此之外就是选择Histogram类概览来自己慢慢分析,大家可以搜搜mat的相关教程。
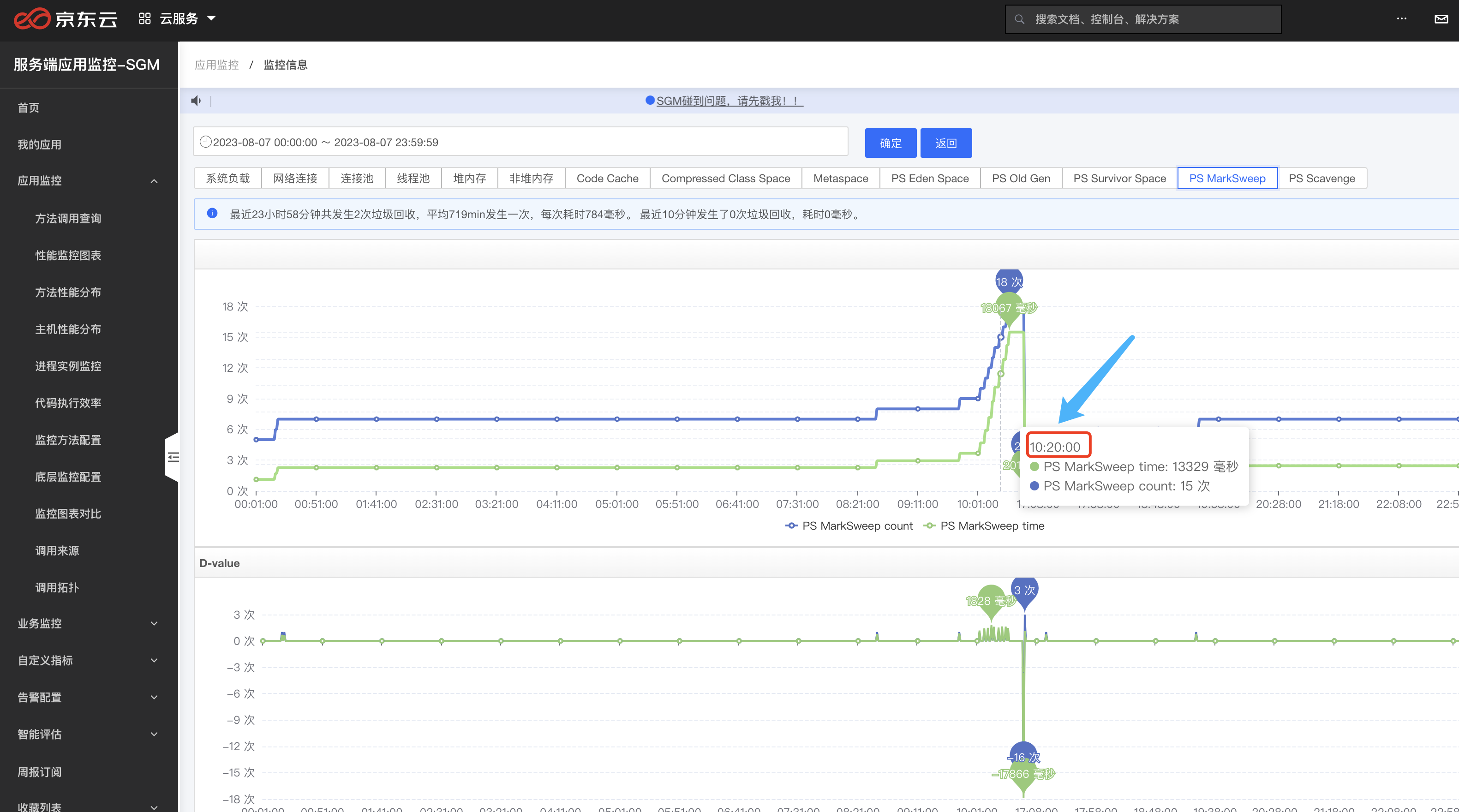
接下来就是第三种和第四种情况,这时候我们需要取查看年轻代三块区域的变化,尤其是Survivor区域,下图是当时一个情况,S区大小一直在变化,而且基本一致保持在50%以上,这时候想到了一个JVM高版本特性,会自动打开UseAdaptiveSizePolicy(动态调整),查资料后发现,好多人反应这个参数会导致对象跨过S区,直接跑到老年代的情况,我们看到在调用量持续很高的情况,尽然调整到了17M,这肯定会导致容纳不下当时存活的对象
UseAdaptiveSizePolicy开关参数-XX:+UseAdaptiveSizePolicy是一个开关参数,当这个参数打开之后,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomics)。
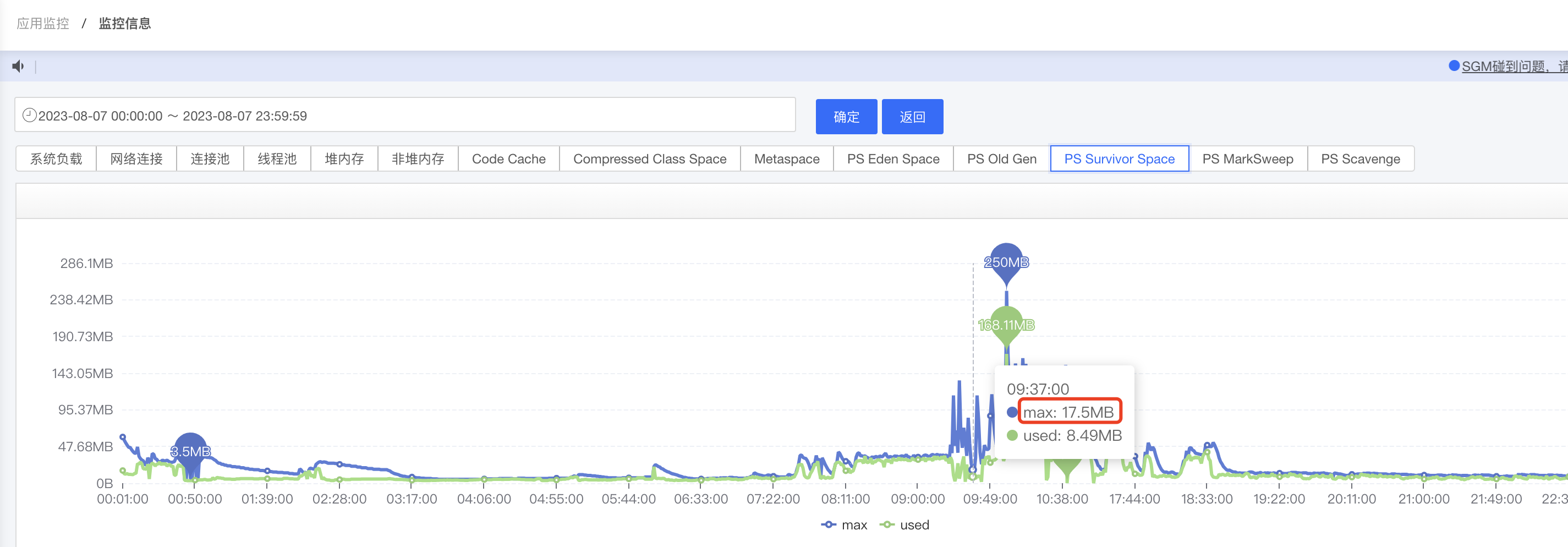
定位到UseAdaptiveSizePolicy问题
既然这有问题,我们尝试关闭一下这个参数看下效果,下面是老年代,S区和FullGC,在关闭前和关闭后的效果,关闭之后S区大多数时间有充足的空间,而且,老年代和FullGC图也安稳了很多 关闭AdaptiveSizePolicy的方式
开启:-XX:+UseAdaptiveSizePolicy(JDK1.8 Parallel Scavenge收集器默认)
关闭:-XX:-UseAdaptiveSizePolicy
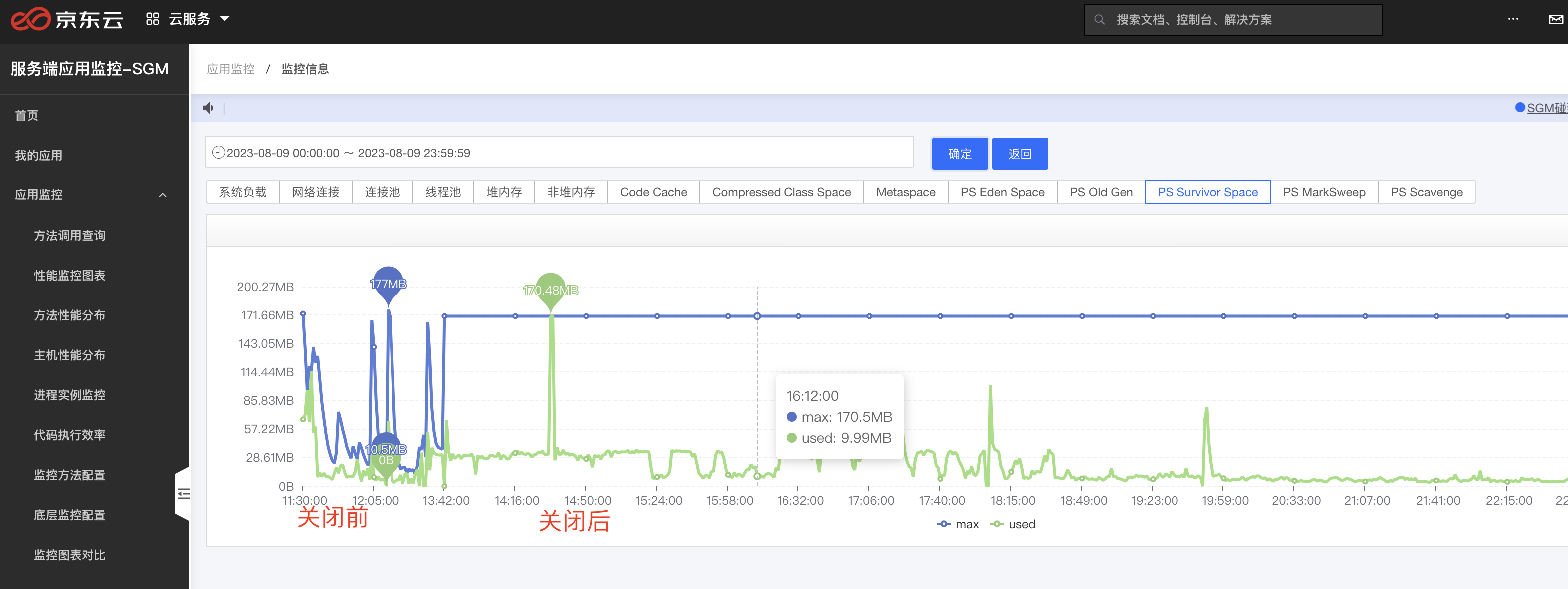

发现新的问题
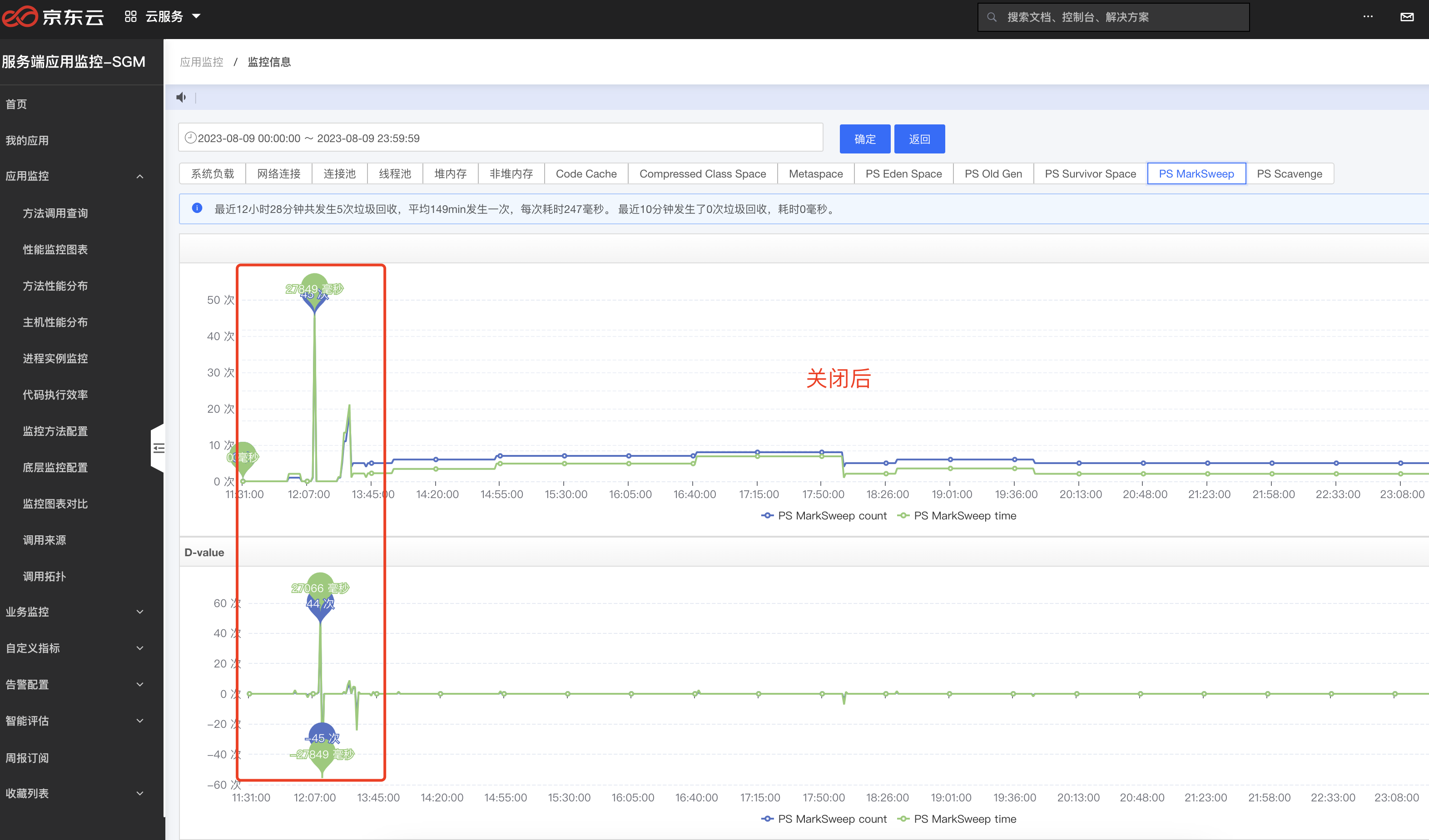
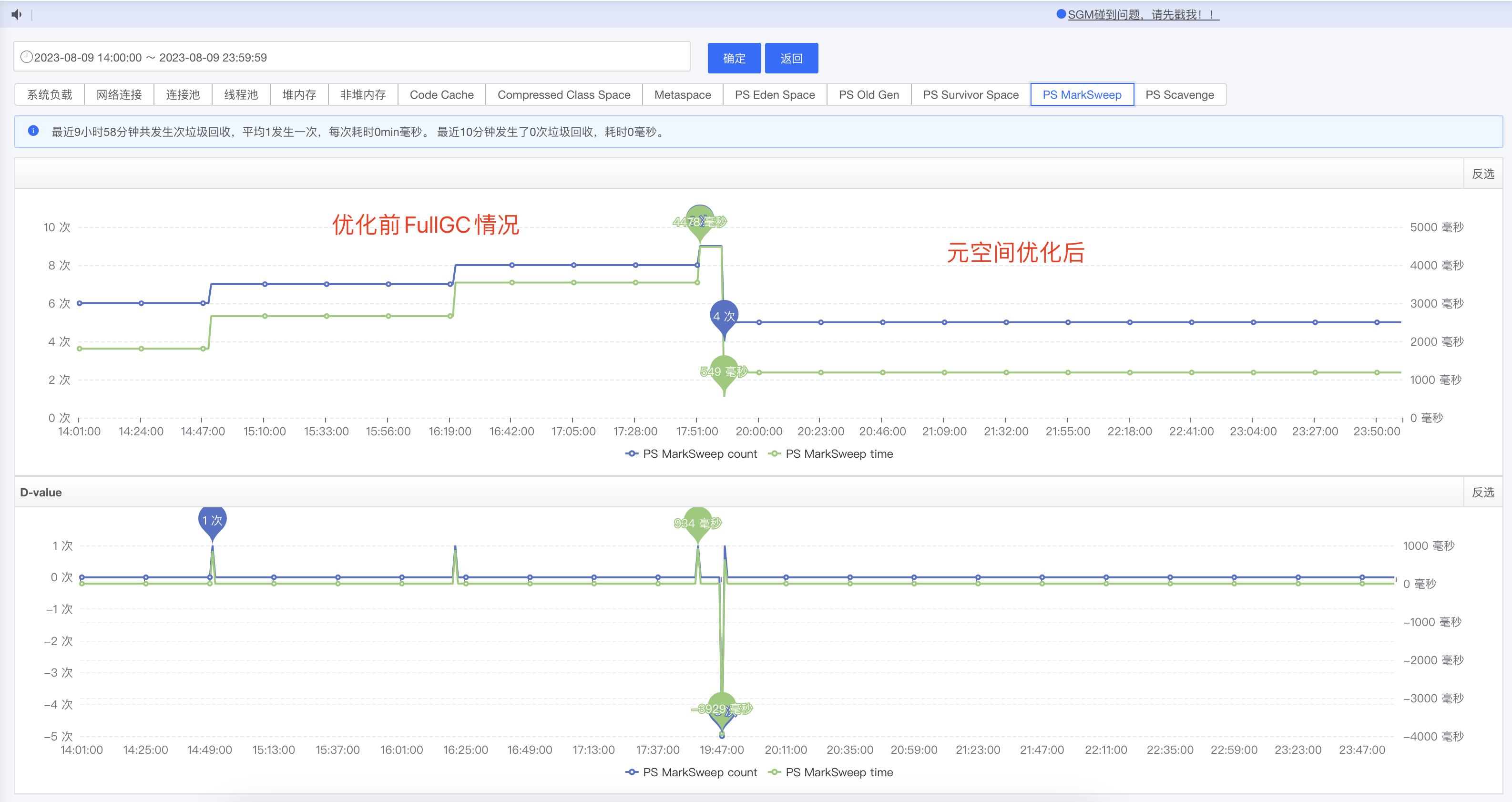
上图中虽然已经安稳了很多,但是还是有一点小问题,频繁FullGC虽然没有了,但是一个小时还是会出现一次FullGC,而且这时候老年代还没有满,这种频率的FullGC,理论上也是不允许的. 我们回到第一个问题,FullGC触发条件,第三个,我们赶紧看了下永久代,也就是元空间,如下图,这一看不得了,元空间也在频繁变动,而且达到300M左右时会触发一次FullGC释放掉.
tips: 这里是没有配置元空间的大小的,也没有配置元空间的理论上元空间无限大,不会满,查询资料后解释是,元空间也会根据当前已使用进行动态调整,当达到上次调整值90%后就会FullGC,所以每次FullGC元空间大小在200M到500M不等
元空间内存排查
这时猜测可能是代码中出现了大量的动态类的声明,想要定位哪些类需要jvm启动参数加上打印类加载和卸载的参数,顺带把GC日志开关也打开
-XX:+TraceClassUnloading -XX:+TraceClassLoading -XX:+PrintGCDetails

打开后查看日志发现一个频繁加载和卸载的类[com.googlecode.aviator.Expression], 经查询资料,这个是aviator 工具的一个规则引擎类,在加载规则时会动态加载一个类,默认不使用缓存,可以打开缓存防止频繁声明新类
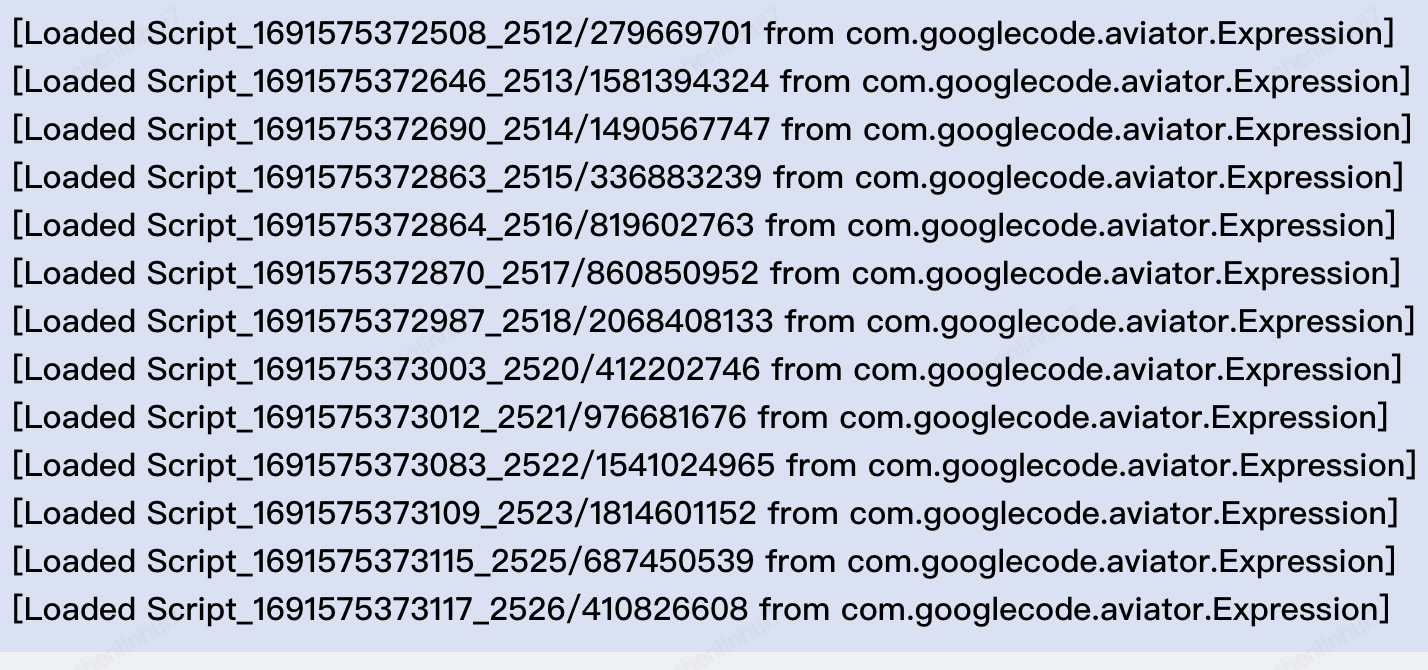
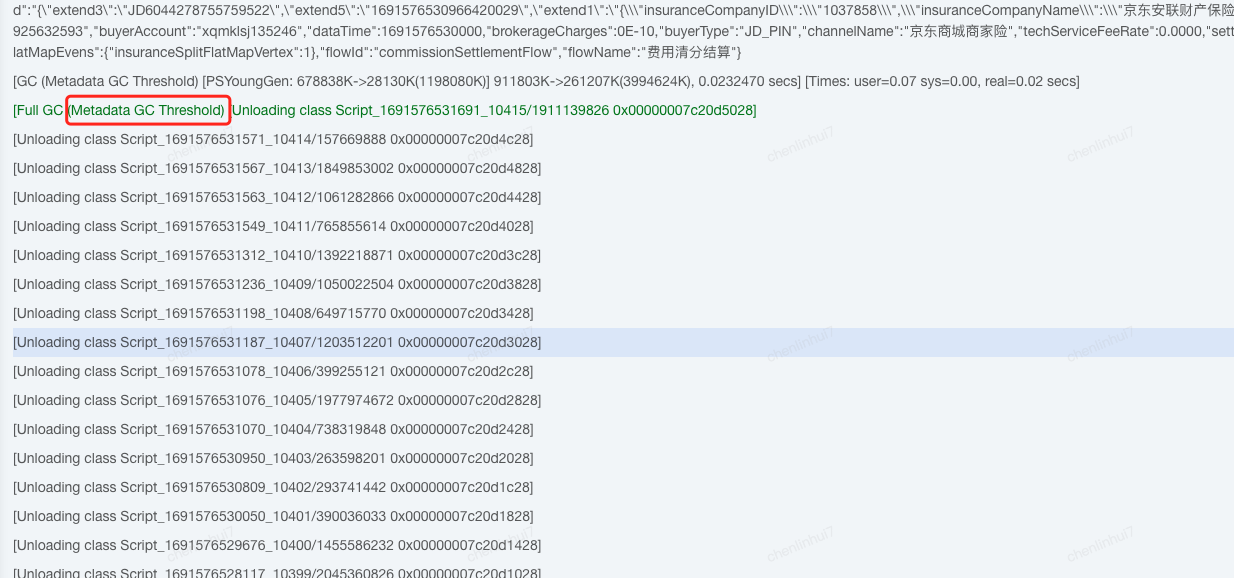
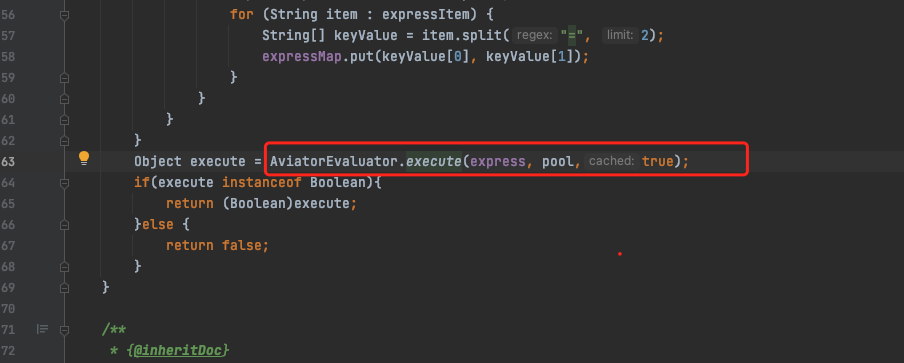
修改代码后重新部署,一小时一次的FullGC也没了,如下图
总结
发现的问题: 问题一: AdaptiveSizePolicy导致对象提前进入老年代,老年代增长速度快,导致频繁FullGC 解决方式: 关闭:-XX:-UseAdaptiveSizePolicy
问题二: 元空间不断增长,导致一小时一次FullGC 解决方式: 修改逻辑代码防止频繁加载新类
在排查问题时尽可能先找直接原因,缩小排查跨度,不要一步就想知道根本原因,每个线索都要问个为什么,不正常的现象肯定是有原因的.
下面是FullGC排查思路参考脑图
标签:调用,遇到,对象,排查,FullGC,GC,当小白,年代 From: https://www.cnblogs.com/Jcloud/p/17651490.html作者:京东保险 陈林辉
来源:京东云开发者社区 转载请注明来源