目录
一、概述
Hive是基于Hadoop的一个数据仓库(Data Aarehouse,简称
数仓、DW),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。是用于存储、分析、报告的数据系统。这里只讲部署,相关概念可以参考我这篇文章:大数据Hadoop之——数据仓库Hive
Hive 架构
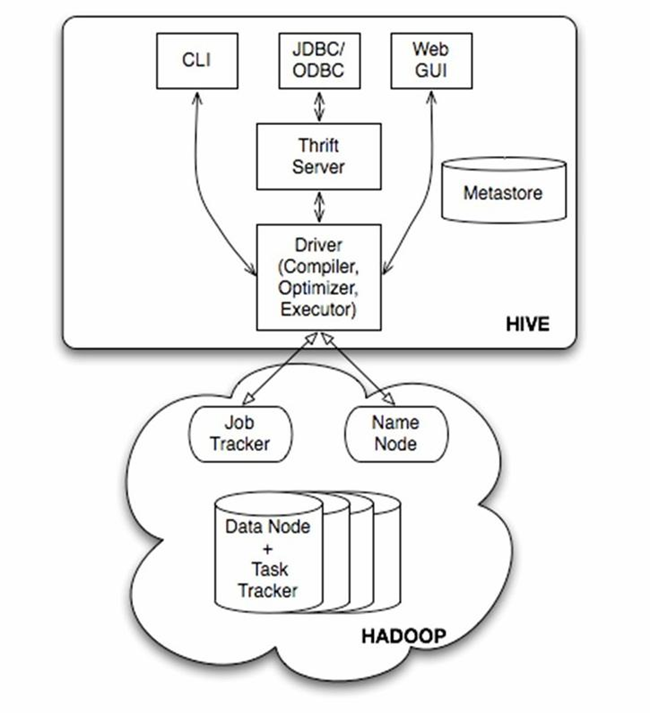
Hive 客户端架构
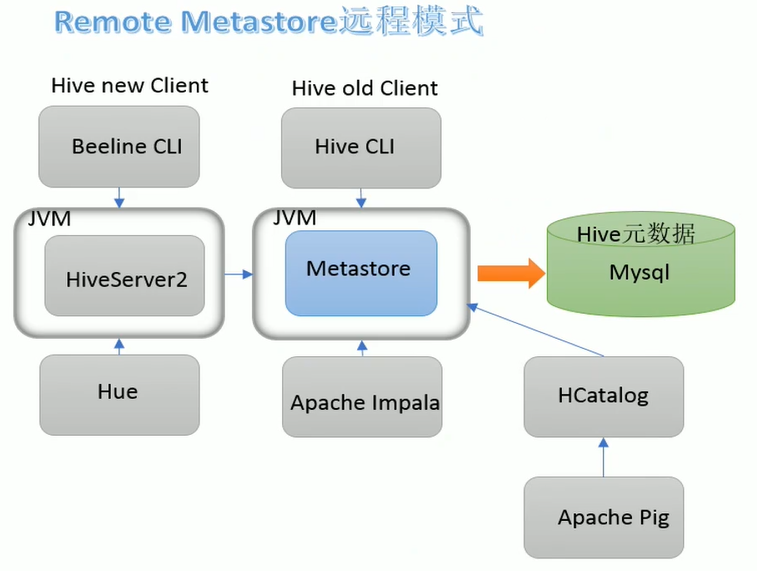
二、开始部署
因为hive依赖与Hadoop,所以这里是在把hive封装在Hadoop ha on k8s 编排中,关于更多,可以参考:【云原生】Hadoop HA on k8s 环境部署
1)构建镜像
Dockerfile
FROM myharbor.com/bigdata/centos:7.9.2009
RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
RUN export LANG=zh_CN.UTF-8
# 创建用户和用户组,跟yaml编排里的spec.template.spec.containers. securityContext.runAsUser: 9999
RUN groupadd --system --gid=9999 admin && useradd --system --home-dir /home/admin --uid=9999 --gid=admin admin
# 安装sudo
RUN yum -y install sudo ; chmod 640 /etc/sudoers
# 给admin添加sudo权限
RUN echo "admin ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
RUN yum -y install install net-tools telnet wget
RUN mkdir /opt/apache/
ADD jdk-8u212-linux-x64.tar.gz /opt/apache/
ENV JAVA_HOME=/opt/apache/jdk1.8.0_212
ENV PATH=$JAVA_HOME/bin:$PATH
ENV HADOOP_VERSION 3.3.2
ENV HADOOP_HOME=/opt/apache/hadoop
ENV HADOOP_COMMON_HOME=${HADOOP_HOME} \
HADOOP_HDFS_HOME=${HADOOP_HOME} \
HADOOP_MAPRED_HOME=${HADOOP_HOME} \
HADOOP_YARN_HOME=${HADOOP_HOME} \
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop \
PATH=${PATH}:${HADOOP_HOME}/bin
#RUN curl --silent --output /tmp/hadoop.tgz https://ftp-stud.hs-esslingen.de/pub/Mirrors/ftp.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz && tar --directory /opt/apache -xzf /tmp/hadoop.tgz && rm /tmp/hadoop.tgz
ADD hadoop-${HADOOP_VERSION}.tar.gz /opt/apache
RUN ln -s /opt/apache/hadoop-${HADOOP_VERSION} ${HADOOP_HOME}
ENV HIVE_VERSION 3.1.2
ADD hive-${HIVE_VERSION}.tar.gz /opt/apache/
ENV HIVE_HOME=/opt/apache/hive
ENV PATH=$HIVE_HOME/bin:$PATH
RUN ln -s /opt/apache/hive-${HIVE_VERSION} ${HIVE_HOME}
RUN chown -R admin:admin /opt/apache
WORKDIR /opt/apache
# Hdfs ports
EXPOSE 50010 50020 50070 50075 50090 8020 9000
# Mapred ports
EXPOSE 19888
#Yarn ports
EXPOSE 8030 8031 8032 8033 8040 8042 8088
#Other ports
EXPOSE 49707 2122
开始构建镜像
docker build -t myharbor.com/bigdata/hadoop-hive:v3.3.2-3.1.2 . --no-cache
### 参数解释
# -t:指定镜像名称
# . :当前目录Dockerfile
# -f:指定Dockerfile路径
# --no-cache:不缓存
docker push myharbor.com/bigdata/hadoop-hive:v3.3.2-3.1.2
2)添加 Metastore 服务编排
1、配置
hadoop/templates/hive/hive-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ include "hadoop.fullname" . }}-hive
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
helm.sh/chart: {{ include "hadoop.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
data:
hive-site.xml: |
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置hdfs存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!-- 所连接的 MySQL 数据库的地址,hive_local是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql-primary-headless.mysql:3306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>-->
<!--<value>com.mysql.jdbc.Driver</value>-->
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>WyfORdvwVm</value>
</property>
<!--元数据是否校验-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
<description>user name</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://{{ include "hadoop.fullname" . }}-hive-metastore.{{ .Release.Namespace }}.svc.cluster.local:9083</value>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
</configuration>
2、控制器
hadoop/templates/hive/hiveserver2-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ include "hadoop.fullname" . }}-hive-metastore
annotations:
checksum/config: {{ include (print $.Template.BasePath "/hadoop-configmap.yaml") . | sha256sum }}
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
helm.sh/chart: {{ include "hadoop.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
spec:
serviceName: {{ include "hadoop.fullname" . }}-hive-metastore
selector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
replicas: {{ .Values.hive.metastore.replicas }}
template:
metadata:
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
spec:
affinity:
podAntiAffinity:
{{- if eq .Values.antiAffinity "hard" }}
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
{{- else if eq .Values.antiAffinity "soft" }}
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 5
podAffinityTerm:
topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
{{- end }}
terminationGracePeriodSeconds: 0
initContainers:
- name: wait-nn
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
command: ['sh', '-c', "until curl -m 3 -sI http://{{ include "hadoop.fullname" . }}-hdfs-nn-{{ sub .Values.hdfs.nameNode.replicas 1 }}.{{ include "hadoop.fullname" . }}-hdfs-nn.{{ .Release.Namespace }}.svc.cluster.local:9870 | egrep --silent 'HTTP/1.1 200 OK|HTTP/1.1 302 Found'; do echo waiting for nn; sleep 1; done"]
containers:
- name: hive-metastore
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy | quote }}
command:
- "/bin/bash"
- "/opt/apache/tmp/hadoop-config/bootstrap.sh"
- "-d"
resources:
{{ toYaml .Values.hive.metastore.resources | indent 10 }}
readinessProbe:
tcpSocket:
port: 9083
initialDelaySeconds: 10
timeoutSeconds: 2
livenessProbe:
tcpSocket:
port: 9083
initialDelaySeconds: 10
timeoutSeconds: 2
volumeMounts:
- name: hadoop-config
mountPath: /opt/apache/tmp/hadoop-config
- name: hive-config
mountPath: /opt/apache/hive/conf
securityContext:
runAsUser: {{ .Values.securityContext.runAsUser }}
privileged: {{ .Values.securityContext.privileged }}
volumes:
- name: hadoop-config
configMap:
name: {{ include "hadoop.fullname" . }}
- name: hive-config
configMap:
name: {{ include "hadoop.fullname" . }}-hive
3、Service
hadoop/templates/hive/metastore-svc.yaml
# A headless service to create DNS records
apiVersion: v1
kind: Service
metadata:
name: {{ include "hadoop.fullname" . }}-hive-metastore
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
helm.sh/chart: {{ include "hadoop.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
spec:
ports:
- name: metastore
port: {{ .Values.service.hive.metastore.port }}
nodePort: {{ .Values.service.hive.metastore.nodePort }}
type: {{ .Values.service.hive.metastore.type }}
selector:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-metastore
3)添加 HiveServer2 服务编排
1、控制器
hadoop/templates/hive/hiveserver2-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ include "hadoop.fullname" . }}-hive-hiveserver2
annotations:
checksum/config: {{ include (print $.Template.BasePath "/hadoop-configmap.yaml") . | sha256sum }}
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
helm.sh/chart: {{ include "hadoop.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
spec:
serviceName: {{ include "hadoop.fullname" . }}-hive-hiveserver2
selector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
replicas: {{ .Values.hive.hiveserver2.replicas }}
template:
metadata:
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
spec:
affinity:
podAntiAffinity:
{{- if eq .Values.antiAffinity "hard" }}
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
{{- else if eq .Values.antiAffinity "soft" }}
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 5
podAffinityTerm:
topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
{{- end }}
terminationGracePeriodSeconds: 0
initContainers:
- name: wait-hive-metastore
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
command: ['sh', '-c', "until (echo 'q')|telnet -e 'q' {{ include "hadoop.fullname" . }}-hive-metastore.{{ .Release.Namespace }}.svc.cluster.local {{ .Values.service.hive.metastore.port }} >/dev/null 2>&1; do echo waiting for hive metastore; sleep 1; done"]
containers:
- name: hive-hiveserver2
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy | quote }}
command:
- "/bin/bash"
- "/opt/apache/tmp/hadoop-config/bootstrap.sh"
- "-d"
resources:
{{ toYaml .Values.hive.metastore.resources | indent 10 }}
readinessProbe:
tcpSocket:
port: 10000
initialDelaySeconds: 10
timeoutSeconds: 2
livenessProbe:
tcpSocket:
port: 10000
initialDelaySeconds: 10
timeoutSeconds: 2
volumeMounts:
- name: hadoop-config
mountPath: /opt/apache/tmp/hadoop-config
- name: hive-config
mountPath: /opt/apache/hive/conf
securityContext:
runAsUser: {{ .Values.securityContext.runAsUser }}
privileged: {{ .Values.securityContext.privileged }}
volumes:
- name: hadoop-config
configMap:
name: {{ include "hadoop.fullname" . }}
- name: hive-config
configMap:
name: {{ include "hadoop.fullname" . }}-hive
2、Service
hadoop/templates/hive/hiveserver2-svc.yaml
# A headless service to create DNS records
apiVersion: v1
kind: Service
metadata:
name: {{ include "hadoop.fullname" . }}-hive-hiveserver2
labels:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
helm.sh/chart: {{ include "hadoop.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
spec:
ports:
- name: metastore
port: {{ .Values.service.hive.hiveserver2.port }}
nodePort: {{ .Values.service.hive.hiveserver2.nodePort }}
type: {{ .Values.service.hive.hiveserver2.type }}
selector:
app.kubernetes.io/name: {{ include "hadoop.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/component: hive-hiveserver2
4)修改values.yaml
hadoop/values.yaml
image:
repository: myharbor.com/bigdata/hadoop-hive
tag: v3.3.2-3.1.2
pullPolicy: IfNotPresent
# The version of the hadoop libraries being used in the image.
hadoopVersion: 3.3.2
logLevel: INFO
# Select antiAffinity as either hard or soft, default is soft
antiAffinity: "soft"
hdfs:
nameNode:
replicas: 2
pdbMinAvailable: 1
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "2048Mi"
cpu: "1000m"
dataNode:
# Will be used as dfs.datanode.hostname
# You still need to set up services + ingress for every DN
# Datanodes will expect to
externalHostname: example.com
externalDataPortRangeStart: 9866
externalHTTPPortRangeStart: 9864
replicas: 3
pdbMinAvailable: 1
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "2048Mi"
cpu: "1000m"
webhdfs:
enabled: true
jounralNode:
replicas: 3
pdbMinAvailable: 1
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "2048Mi"
cpu: "1000m"
hive:
metastore:
replicas: 1
pdbMinAvailable: 1
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "2048Mi"
cpu: "1000m"
hiveserver2:
replicas: 1
pdbMinAvailable: 1
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "1024Mi"
cpu: "500m"
yarn:
resourceManager:
pdbMinAvailable: 1
replicas: 2
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "2048Mi"
cpu: "2000m"
nodeManager:
pdbMinAvailable: 1
# The number of YARN NodeManager instances.
replicas: 1
# Create statefulsets in parallel (K8S 1.7+)
parallelCreate: false
# CPU and memory resources allocated to each node manager pod.
# This should be tuned to fit your workload.
resources:
requests:
memory: "256Mi"
cpu: "500m"
limits:
memory: "2048Mi"
cpu: "1000m"
persistence:
nameNode:
enabled: true
storageClass: "hadoop-ha-nn-local-storage"
accessMode: ReadWriteOnce
size: 1Gi
local:
- name: hadoop-ha-nn-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/hadoop-ha/nn/data/data1"
- name: hadoop-ha-nn-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/hadoop-ha/nn/data/data1"
dataNode:
enabled: true
enabledStorageClass: false
storageClass: "hadoop-ha-dn-local-storage"
accessMode: ReadWriteOnce
size: 1Gi
local:
- name: hadoop-ha-dn-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data1"
- name: hadoop-ha-dn-1
host: "local-168-182-110"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data2"
- name: hadoop-ha-dn-2
host: "local-168-182-110"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data3"
- name: hadoop-ha-dn-3
host: "local-168-182-111"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data1"
- name: hadoop-ha-dn-4
host: "local-168-182-111"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data2"
- name: hadoop-ha-dn-5
host: "local-168-182-111"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data3"
- name: hadoop-ha-dn-6
host: "local-168-182-112"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data1"
- name: hadoop-ha-dn-7
host: "local-168-182-112"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data2"
- name: hadoop-ha-dn-8
host: "local-168-182-112"
path: "/opt/bigdata/servers/hadoop-ha/dn/data/data3"
volumes:
- name: dfs1
mountPath: /opt/apache/hdfs/datanode1
hostPath: /opt/bigdata/servers/hadoop-ha/dn/data/data1
- name: dfs2
mountPath: /opt/apache/hdfs/datanode2
hostPath: /opt/bigdata/servers/hadoop-ha/dn/data/data2
- name: dfs3
mountPath: /opt/apache/hdfs/datanode3
hostPath: /opt/bigdata/servers/hadoop-ha/dn/data/data3
journalNode:
enabled: true
storageClass: "hadoop-ha-jn-local-storage"
accessMode: ReadWriteOnce
size: 1Gi
local:
- name: hadoop-ha-jn-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/hadoop-ha/jn/data/data1"
- name: hadoop-ha-jn-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/hadoop-ha/jn/data/data1"
- name: hadoop-ha-jn-2
host: "local-168-182-112"
path: "/opt/bigdata/servers/hadoop-ha/jn/data/data1"
volumes:
- name: jn
mountPath: /opt/apache/hdfs/journalnode
service:
nameNode:
type: NodePort
ports:
dfs: 9000
webhdfs: 9870
nodePorts:
dfs: 30900
webhdfs: 30870
nameNode1:
type: NodePort
ports:
webhdfs: 9870
nodePorts:
webhdfs: 31870
nameNode2:
type: NodePort
ports:
webhdfs: 9870
nodePorts:
webhdfs: 31871
dataNode:
type: NodePort
ports:
webhdfs: 9864
nodePorts:
webhdfs: 30864
resourceManager:
type: NodePort
ports:
web: 8088
nodePorts:
web: 30088
resourceManager1:
type: NodePort
ports:
web: 8088
nodePorts:
web: 31088
resourceManager2:
type: NodePort
ports:
web: 8088
nodePorts:
web: 31089
journalNode:
type: ClusterIP
ports:
jn: 8485
nodePorts:
jn: ""
hive:
metastore:
type: NodePort
port: 9083
nodePort: 31183
hiveserver2:
type: NodePort
port: 10000
nodePort: 30000
securityContext:
runAsUser: 9999
privileged: true
5)开始部署
# 更新
helm upgrade hadoop-ha ./hadoop -n hadoop-ha
# 重新安装
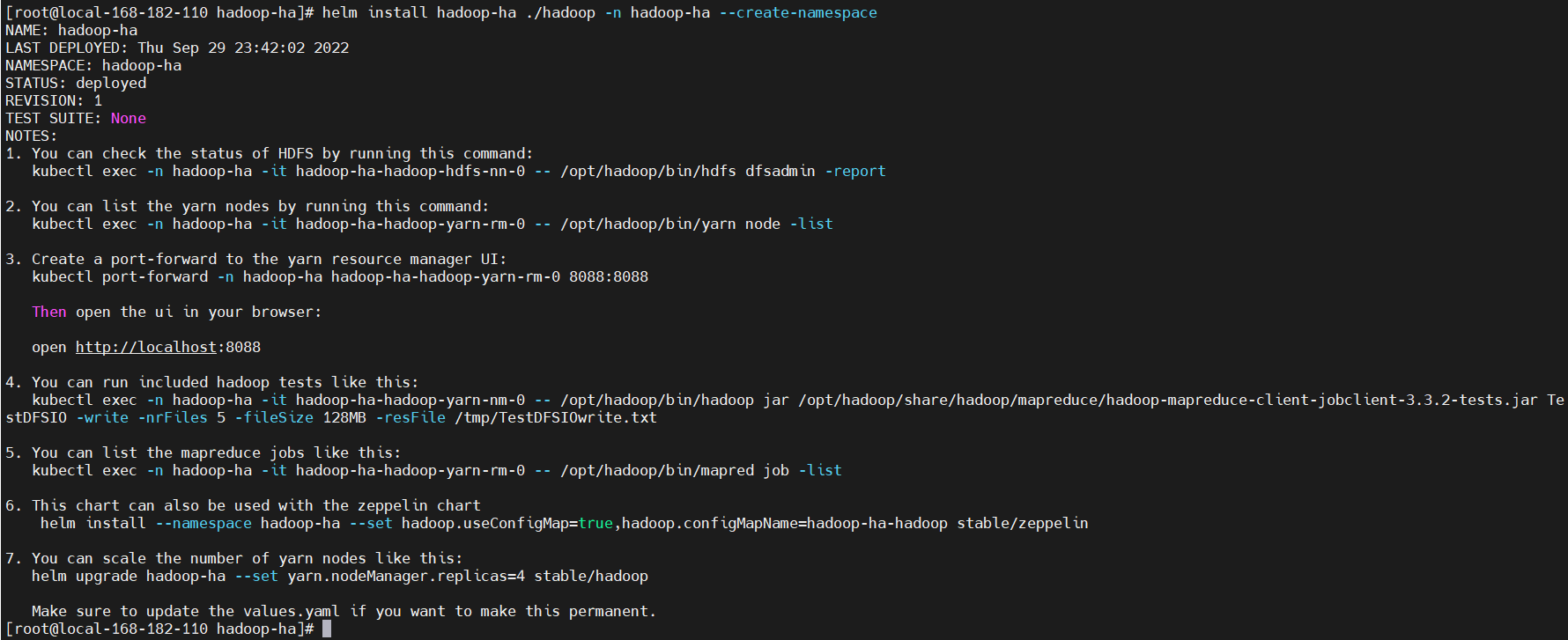
helm install hadoop-ha ./hadoop -n hadoop-ha --create-namespace
# 更新
helm upgrade hadoop-ha ./hadoop -n hadoop-ha
NOTES
NAME: hadoop-ha
LAST DEPLOYED: Thu Sep 29 23:42:02 2022
NAMESPACE: hadoop-ha
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. You can check the status of HDFS by running this command:
kubectl exec -n hadoop-ha -it hadoop-ha-hadoop-hdfs-nn-0 -- /opt/hadoop/bin/hdfs dfsadmin -report
2. You can list the yarn nodes by running this command:
kubectl exec -n hadoop-ha -it hadoop-ha-hadoop-yarn-rm-0 -- /opt/hadoop/bin/yarn node -list
3. Create a port-forward to the yarn resource manager UI:
kubectl port-forward -n hadoop-ha hadoop-ha-hadoop-yarn-rm-0 8088:8088
Then open the ui in your browser:
open http://localhost:8088
4. You can run included hadoop tests like this:
kubectl exec -n hadoop-ha -it hadoop-ha-hadoop-yarn-nm-0 -- /opt/hadoop/bin/hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.2-tests.jar TestDFSIO -write -nrFiles 5 -fileSize 128MB -resFile /tmp/TestDFSIOwrite.txt
5. You can list the mapreduce jobs like this:
kubectl exec -n hadoop-ha -it hadoop-ha-hadoop-yarn-rm-0 -- /opt/hadoop/bin/mapred job -list
6. This chart can also be used with the zeppelin chart
helm install --namespace hadoop-ha --set hadoop.useConfigMap=true,hadoop.configMapName=hadoop-ha-hadoop stable/zeppelin
7. You can scale the number of yarn nodes like this:
helm upgrade hadoop-ha --set yarn.nodeManager.replicas=4 stable/hadoop
Make sure to update the values.yaml if you want to make this permanent.
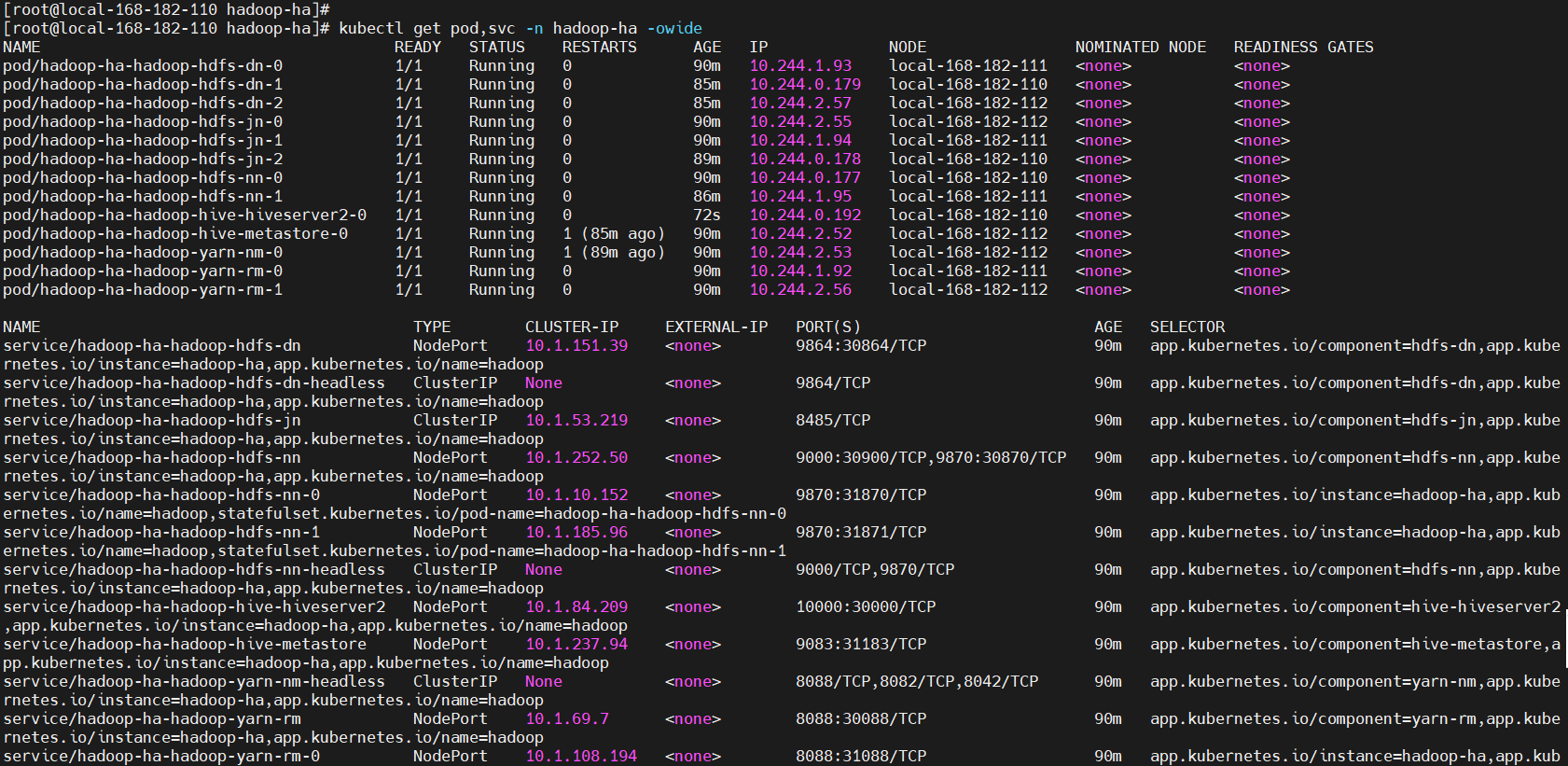
6)测试验证
查看
kubectl get pods,svc -n hadoop-ha -owide
测试
beeline -u jdbc:hive2://localhost:10000 -n admin
create database test;
CREATE TABLE IF NOT EXISTS test.person_1 (
id INT COMMENT 'ID',
name STRING COMMENT '名字',
age INT COMMENT '年龄',
likes ARRAY<STRING> COMMENT '爱好',
address MAP<STRING,STRING> COMMENT '地址'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
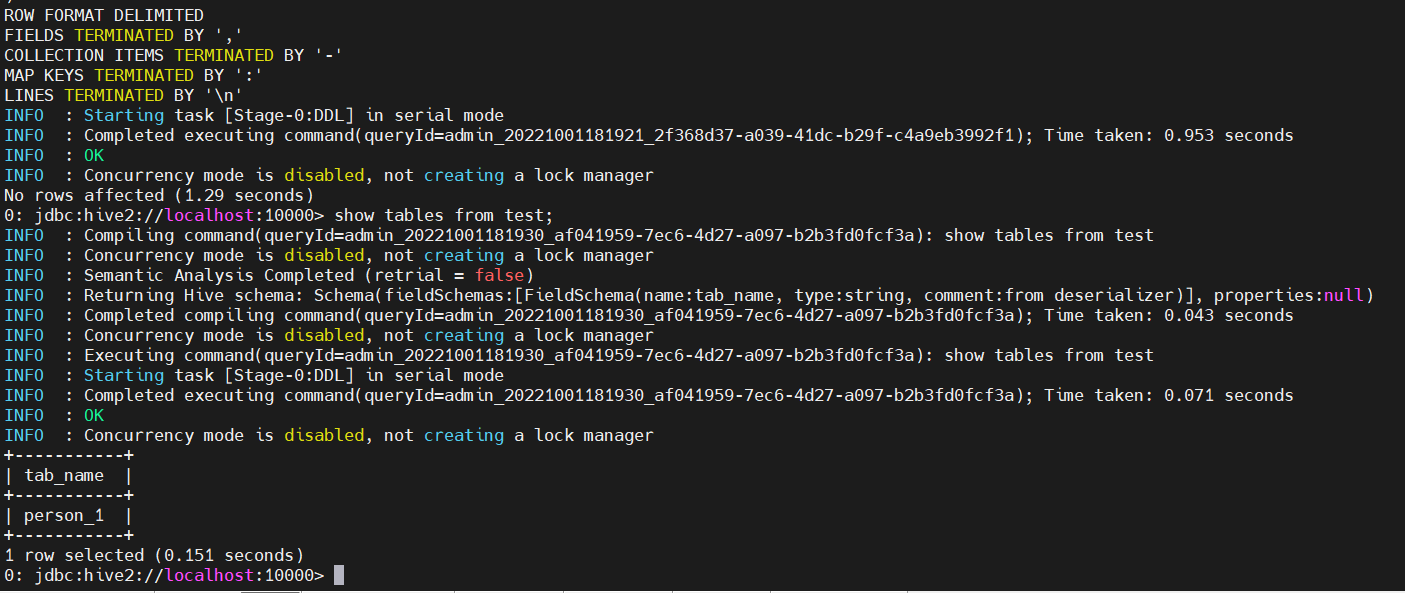
7)卸载
helm uninstall hadoop-ha -n hadoop-ha
kubectl delete pod -n hadoop-ha `kubectl get pod -n hadoop-ha|awk 'NR>1{print $1}'` --force
kubectl patch ns hadoop-ha -p '{"metadata":{"finalizers":null}}'
kubectl delete ns hadoop-ha --force
rm -fr /opt/bigdata/servers/hadoop-ha/{nn,dn,jn}/data/data{1..3}/*
git下载地址:https://gitee.com/hadoop-bigdata/hadoop-ha-on-k8s
这里只是把hive相关的部分编排列出来了,有疑问的小伙伴欢迎给我留言,对应的修改也提交到git上了,有需要的小伙伴自行下载,hive的编排部署就先到这里了,后续会持续分享【云原生+大数据】相关的教程,请小伙伴耐心等待~
标签:原生,ha,name,kubernetes,hadoop,hive,Hive,io,k8s From: https://www.cnblogs.com/liugp/p/16747557.html