首先网上有很多关于这个课程的介绍,所以不直接陈述详细内容了,写一些自己的理解,可能不会仅限于当前机器学习编译课程,可能会用到TVM的理解。网上诸多大佬都有阐述,例如蓝色大佬的https://www.zhihu.com/people/lan-se-52-30/posts
1.1 什么是机器学习编译
其实就是机器学习+编译
1.1.1 机器学习
首先机器学习、深度学习我都不会(只有一点点了解),那么既然都不会机器学习、深度学习一类的东西,这里的机器学习有什么作用呢。
整个机器学习编译课程体系、TVM体系中,这里的机器学习是指深度学习或者机器学习等各种学习训练之后的结果、模型。
所以不会机器学习(应该没啥大问题。
1.1.2 编译
c++编译器等传统编译器都可以理解,将我们自己写的c++代码,编译成一个可以运行的.exe文件,可以在cpu上运行
这里将编译可以看出一个过程,一个翻译c++的过程,c++代码为输入,经过编译之后,生成可以在cpu上运行的.exe文件。
那么机器学习编译中的编译是指:将机器学习的结果、模型编译为在硬件(CPU、GPU、NPU)上可以运行的一个东西。
编译只是一个过程(感性理解),有输入,有输出,类似于一个函数;
传统编译器中
输入为c++代码,输出为在CPU上运行的.exe文件
机器学习编译、AI编译器
输入为深度学习、机器学习的结果、模型,输出为在各种芯片上的可运行的东西。
传统编译器和机器学习编译、AI编译应该有很多不一样的东西,但是大体思想我认为是一样的
1.1.3 机器学习编译的目的
首先因为机器学习编译整个过程是输入一个深度学习、机器学习的模型,输出一个可在硬件上运行的东西。
那么涉及到
- 输入:深度学习、机器学习模型
- 处理过程:编译过程
- 输出:硬件
多对多
总体过程是一个多对多的过程,何为多对多
1.1.3.1 输入的多样性
多种深度学习、机器学习模型,至少有(pytorch、tensorflow),其他的模型我也没了解过,不同种类的模型数据结构不同,格式不同,表达方式不同。这种输入的多样性(可以理解为c++、java、go等多种语言)
1.1.3.2 输出的多样性
硬件很多,好多芯片(NPU、CPU、GPU),既然可以编译到CPU上,也可以编译到其他芯片上
编译过程
输入多种类型、输出多种类型,那么这个编译过程肯定要支持将多种输入分别转换为多种输出。
两种方式
各写各的
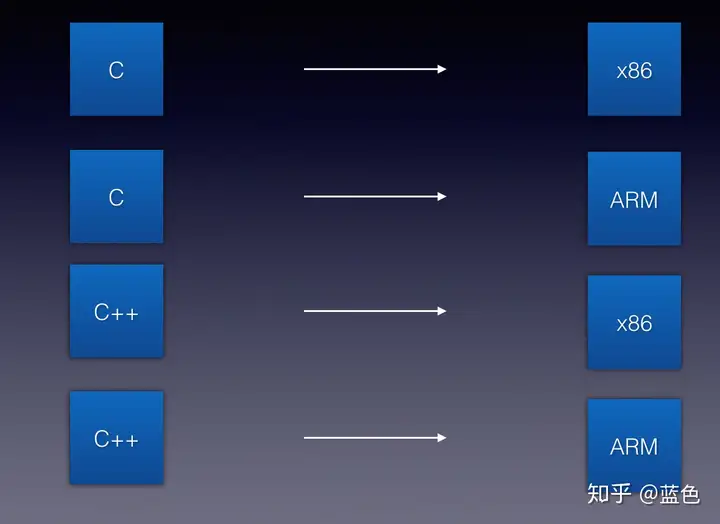
对n种输入都写一个编译过程,对每种输入分别有m个目标芯片,那么总共要写n * m种编译过程(太繁琐),蓝色大佬的图只画了一部分
通用的编译过程
将每种输入都转化为同一种格式,然后将这个格数再转化为不同目标芯片可运行的东西。
总共需要的东西:将n种输入处理为同一种格式的方法,将同一种格式处理为m个芯片可以运行的方法,总共n+m

总结
机器学习编译:采用通用的编译过程,将不同种类的输入(各种深度学习模型)先转化为同一种格式(IR ,Intermediate Representation) , 也叫中间表达,然后将中间表达IR转化为不同芯片支持的东西。
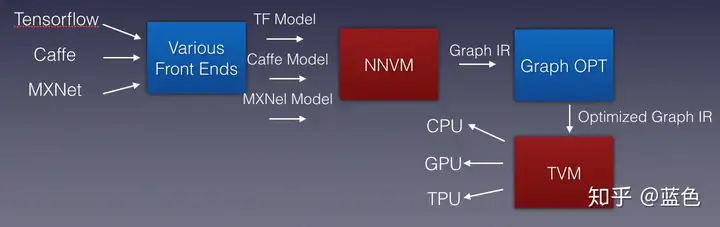
1.2 整个编译过程如何打通
这个将不同输入的神经网络、深度学习、机器学习模型转化为可在不同芯片上运行的过程,是AI编译器来做的,我们比较关心的东西是:
1.2.1 多种输入模型如何转换为IR
虽然说在现实中,我们可能不需要关系这个东西,直接调API即可,但理解万岁。
不同的输入代表不同的格式、语法语义,但是都有个共同的特点,支持AST,可以理解为一个计算图,语法设计都离不开AST(我猜的),可以利用这个AST,将不同的语法用AST遍历,转化为相同的计算图 Graph IR。只有这个Graph IR设计一下即可。