ES中的日期类型
Elasticsearch 在索引创建之前并不是必须要创建索引的mapping。关系型数据库的思维就是在于写入数据之前,并不强制创建表结构。我们不用事先声明字段名称,字段类型以及长度等属性就可以直接向一个不存在的表中直接写入数据。
Elasticsearch把这种特性称之为dynamic mapping,也就是自动映射。Elasticsearch会根据你写入的字段的内容动态去判定字段的数据类型,这种自动映射的机制存在一些缺陷,比如在Elasticsearch中没有隐式类型转换,所以在自动映射的时候就会把字段映射为较宽的数据类型。比如你写入一个数字50,系统就会自动给你映射成long类型,而不是int 。一般企业中用于生产的环境都是使用手工映射,能保证按需创建以节省资源和达到更高的性能。
案例
假如我们有如下索引companys,其中date字段包含多种日期的格式,“yyyy-MM-dd”还有时间戳。如果按照dynamic mapping,采取自动映射器来映射索引。我们自然而然的都会感觉字段应该是一个date类型。
POST companys/_bulk
{"index":{}}
{"date": "2023-01-25 10:01:12", "company": "中国烟草", "income": 5700000}
{"index":{}}
{"date": "2023-01-25 10:01:13", "company": "华为", "income": 4034113.182}
{"index":{}}
{"date": "2023-01-26 10:02:11", "company": "苹果", "income": 7784.7252}
{"index":{}}
{"date": "2023-01-26 10:02:15", "company": "小米", "income": 185000}
{"index":{}}
{"date": "2023-01-26 10:01:23", "company": "阿里", "income": 1072526}
{"index":{}}
{"date": "2023-01-27 10:01:54", "company": "腾讯", "income": 6500}
{"index":{}}
{"date": "2023-01-28 10:01:32", "company": "蚂蚁金服", "income": 5000}
{"index":{}}
{"date": "2023-01-29 10:01:21", "company": "字节跳动", "income": 10000}
{"index":{}}
{"date": "2023-01-30 10:02:07", "company": "中国石油", "income": 18302097}
{"index":{}}
{"date": "1648100904", "company": "中国石化", "income": 32654722}
{"index":{}}
{"date": "2023-11-1 12:20:00", "company": "国家电网", "income": 82950000}
查看companys索引的mapping,会发现date被映射成text类型了
GET companys/_mapping
{
"companys" : {
"mappings" : {
"properties" : {
"company" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"date" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ratal" : {
"type" : "long"
}
}
}
}
}
原因
原因就在于对时间类型的格式的要求是绝对严格的。要求必须是一个标准的UTC时间类型。上述字段的数据格式如果想要使用,就必须使用yyyy-MM-ddTHH:mm:ssZ格式(其中T个间隔符,Z代表 0 时区),以下均为错误的时间格式(均无法被自动映射器识别为日期时间类型):
-
yyyy-MM-dd HH:mm:ss
-
yyyy-MM-dd
-
时间戳
坑一
看下面的索引通过自动映射把tmCreate字段会被映射成什么类型
PUT test_es/_doc/1
{
"tmCreate":"2023-7-12T14:00:00Z"
}
GET test_es/_mapping
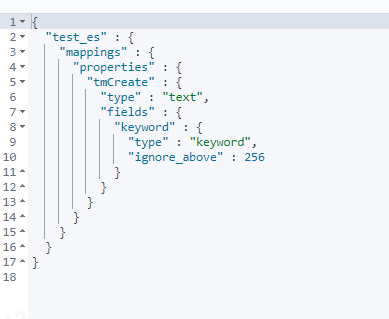
-
2023-7-12T14:00:00Z 错误
-
2023-07-12T14:00:00Z 正确
坑二
手工映射了日期类型,还是插入失败
PUT companys2
{
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
}
POST companys2/_bulk
{"index":{}}
{"date": "2023-01-30 10:02:07", "company": "中国石油", "income": 18302097}
{"index":{}}
{"date": "1648100904", "company": "中国石化", "income": 32654722}
{"index":{}}
{"date": "2023-11-1T12:20:00Z", "company": "国家电网", "income": 82950000}
{"index":{}}
{"date": "2023-01-30T10:02:07Z", "company": "中国石油", "income": 18302097}
{"index":{}}
{"date": "2023-01-25", "company": "中国烟草", "income": 5700000}
-
第一个(写入失败):2023-01-30 10:02:07
-
第二个(写入成功):1648100904
-
第三个(写入失败):2023-11-1T12:20:00Z
-
第四个(写入成功):2023-01-30T10:02:07Z
-
第五个(写入成功):2023-01-25
解决办法
对日期类型的字段增加一个属性
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
PUT companys/标签:index,01,company,income,时间,2023,date,格式,ES From: https://www.cnblogs.com/lovezhr/p/17622559.html
{
"mappings": {
"properties": {
"date":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"company":{
"type": "keyword"
},
"ratal":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}