[更新于 2023 年 7 月 23 日: 添加 Llama 2。]
文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研究克服了这些困难,并且友好的交互页面能让每个人尝试这些模型。如 ChatGPT 的服务,已经把亮点放在强大的模型如 GPT-4,并且引发了爆发式的开源替代品变成主流如 Llama。我们认为这些技术将持续很长一段时间,并且会越来越集成到日常产品中。
这篇博客分成一下几个部分:
文本生成的简明背景
文本生成模型本质上是以补全文本或者根据提示词生成文本为目的训练的。补全文本的模型被称之为条件语言模型 (Causal Language Models),有著名的例子比如 OpenAI 的 GPT-3 和 Meta AI 的 Llama。
下面你最好要了解型微调,这是把一个大语言模型中的知识迁移到另外的应用场景的过程,我们称之为一个 下游任务 。这些任务的形式可以是根据提示的。模型越大,就越能泛化到预训练数据中不存在,但是可以在微调中学习到的提示词上。
条件语言模型有采用基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。这个优化过程主要基于答复文本的自然性和忠实性,而不是答复的检验值。解释 RLHF 的工作原理超出了本博客的范围,但是你可以在 这里 了解。
举例而言,GPT-3 是一个条件 基本 语言模型,作为 ChatGPT 的后端,通过 RLHF 在对话和提示文本上做微调。最好对这些模型做区分。
在 Hugging Face Hub 上,你可以同时找到条件语言模型和在提示文本上微调过的条件语言模型 (这篇博客后面会给出链接)。Llama 是最早开源,并且能超过闭源模型的大语言模型之一。一个由 Together 领导的研究团队已经复线了 Llama 的数据集,称之为 Red Pajama,并且已经在上面训练和微调了大语言模型。你可以在 这里 了解。以及在 Hugging Face Hub 上找到 模型。截止本博客写好的时候,三个最大的开源语言模型和其许可证分别为 MosaicML 的 MPT-30B,Salesforce 的 XGen 和 TII UAE 的 Falcon,全都已经在 Hugging Face Hub 上开源了。
最近,Meta 开放了 Llama 2,其许可证允许商业用途。截止目前 Llama 2 能在各种指标上超过任何其他开源模型。Llama 2 在 Hugging Face Hub 上的 checkpoint 在 transformers 上兼容,并且最大的 checkpoint 人们都可以在 HuggingChat 上尝试。你可以通过 这篇博客 学习到如何在 Llama 2 上微调,部署和做提示词。
第二种文本生成模型通常称之为文本到文本的生成模型。这些模型在文本对的数据集上训练,这些数据集或者是问答形式,或者是提示和反馈的形式。最受欢迎的是 T5 和 BART (目前为止以及不是最新的技术了)。Google 最近发布了 FLAN-T5 系列的模型。FLAN 是最近为提示任务设计的技术,而 FLAN-T5 便是完全由 T5 用 FLAN 微调得到的模型。目前为止,FLAN-T5 系列的模型是最新的技术,并且开源,可以在 Hugging Face Hub 上看到。注意这和用条件语言模型在提示任务的微调下是不一样的,尽管其输入和输出形式类似。下面你能看到这些模型的原理。
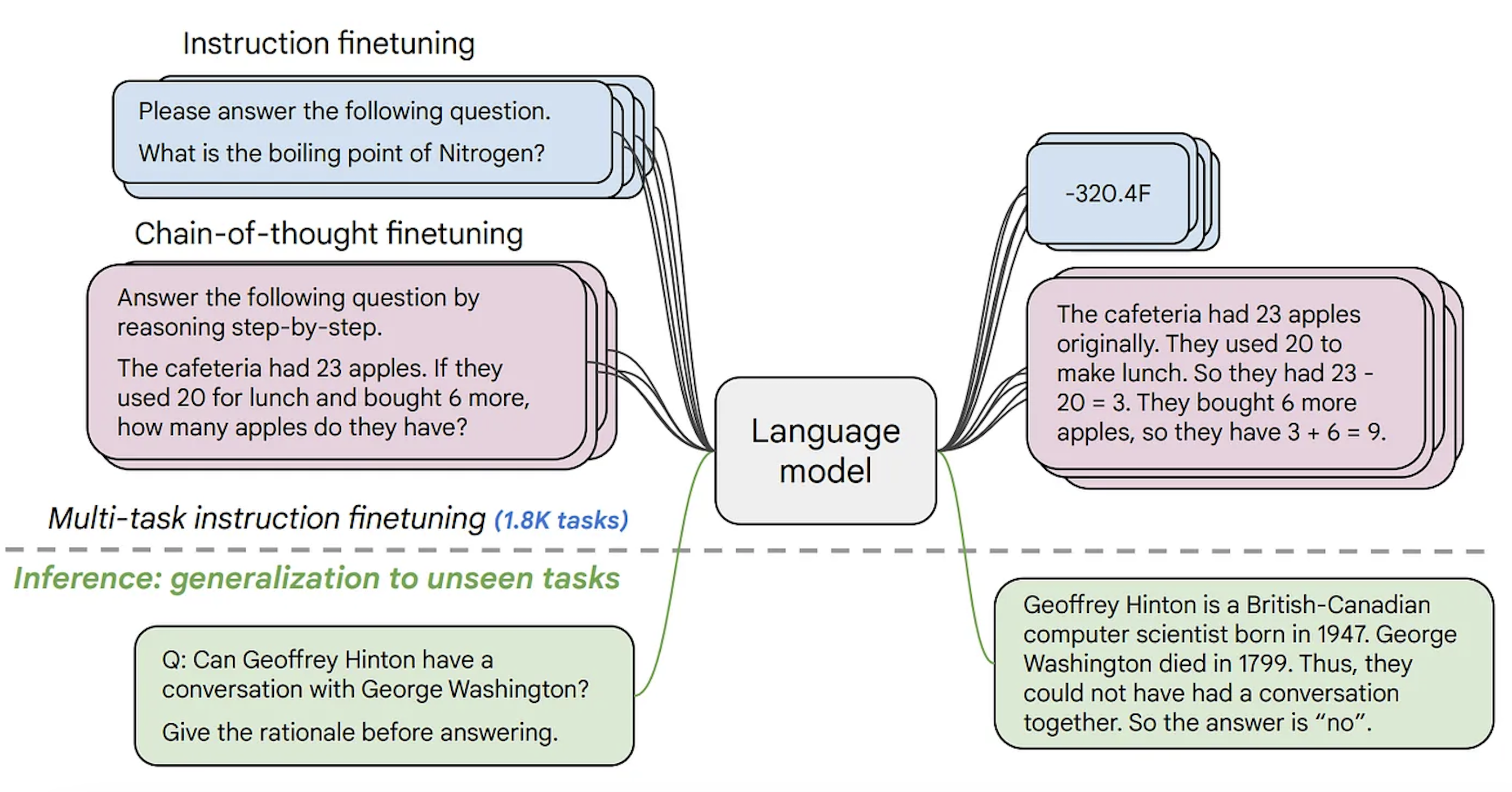
拥有更多开源的文本生成模型能让公司保证其数据隐私,部署下游更快,并且减少购买闭源 API 的支出。Hugging Face Hub 上所有开源的条件语言模型都能在 这里 找到,并且文本到文本的生成模型都能在 这里 找到。