语音识别技术是指机器自动将人的语音转成文字的技术,又称自动语音识别 (Automatic Speech Recognition, ASR)技术。行业内常用“语音识别”来代指自动语音识别,后文都将使用这一代称。
一、语音识别场景
语音识别按实际应用场景主要分为近场语音识别和远场语音识别。
1.1 近场语音识别
近场语音识别主要指手持产品这种场景,比如手机上的语音智能产品——讯飞输入法的 语音输入功能,可拾音距离<1m,正常拾音距离范围≤10cm。
近场语音识别流程,以讯飞输入法的语音输入为例:在近场识别中,用户是可以手动来对语音产品进行操控的,大概的流程如下:用户手动单击开始说话按钮→打开麦克风→交互界面显示出话筒和说话界面→产品系统同时开始检测人声→接收用户语音开始识别→若没有检测到声音或者声音连续x秒截止→检测识别流程结束。
近场语音识别交互流程图如图1-1所示。
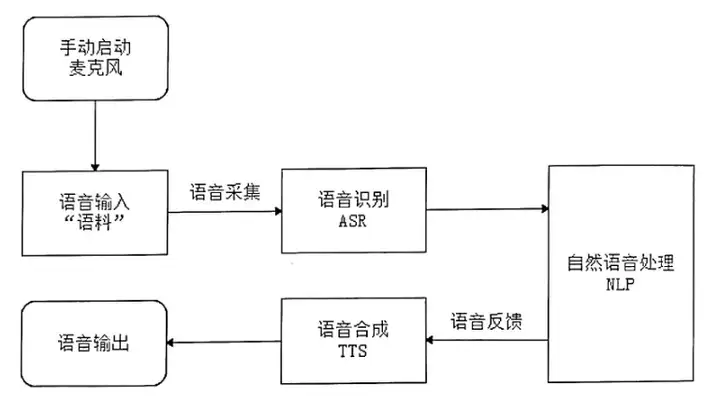 图1 近场语音识别交互流程
图1 近场语音识别交互流程
1.2 远场语音识别
远场语音识别主要指“使用麦克风阵列前端处理算法”这种场景,可拾音距离一般≤10m, 正常拾音距离范围为1m~5m。
远场语音识别相对于近场语音识别的区别在于:
- 远场语音识别需要借助语音激活检测(Voice Active Detection, VAD) 和语音唤醒(Voia Trigger, VT)
- 在近场语音识别中,用户是单击按钮后才开始说话的,单击操作起到了VT的放果,同时由 于信噪比比较高,可以不需要借助VAD,通过简单的算法便可判断出是否有语音。
从用户的角度来说,真正意义上的语音识别是可以解放双手语音输入的,因此我们一般认为远场语音识别才是未来真正的人机交互方式。
 图2 远场语音识别交互过程
图2 远场语音识别交互过程
二、语音识别流程
人工智能语音识别技术通过这几十年的发展,尤其是深度学习技术的大举应用,语音识别流程结构进行了一次重大的变化。
2.1 传统语音识別流程
1990年到2010年,传统语音识别流程主要包含如下4个步骤: 预处理、 编码、 解码、输出识别结果。
 图3 传统语音识别流程
图3 传统语音识别流程
2.2 深度学习语音识别流程
2010年后,由于深度学习大火,并且在图像和语音领域取得了很大的成果,使得深度学习语音识别成为主流语音识别方式。深度学习语音识别其实就是使用深度神经网络模型替换传统语音识别的各节点的步骤, 以此通过更简洁的方式获取识别结果,并提高识别成功率。深度学习语音识别主要有以下几种形式:
2.2.1 Tandem结构
基于DNN+FIMV+GMM(深度神经网络+隐马尔科夫模型+混合高斯模型)的Tandem结构的语音识别技术出现在2011年前后。
相对于传统语音识别,在Tandem结构中,我们使用DNN来提取特征。 针对DNN的输入可以是 “连续若干帧的滤波器组输出”或“语音信号波形”,输出是上下文有关因素的分布。这其实就是一个多分类的问题,如果上下文有关的因素有上千个,那么这就是一个千分类问题。因为DNN是监督学习,所以它需要目标输出值或者标签,通常这个标准答案是由GMM-FIMM获得的。我们训练好DNN模型之后,从DNN的隐含层获取声学特征。 传统的声学特征提取为13维的MFCC序列,我们在DNN中设置一个维度比较小的层,通常也就几十维,并以它作为语音信号的输出,得到的特征就可以代替MFCC序列。 使用DNN来提取特征,其优点在于DNN的输入可以采用连续的帧,因而可以更好地利用上下文的信息,以提升识别成功率。
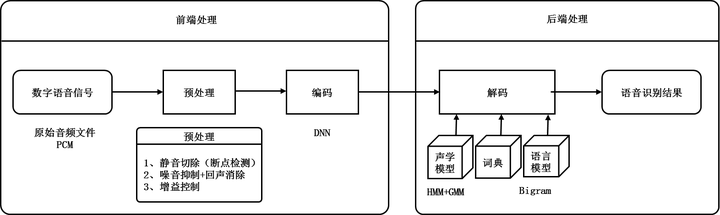 图4 Tandem结构深度学习语音识别流程
图4 Tandem结构深度学习语音识别流程
2.2.2 Hybrid结构
基于DNN+HMM(深度神经网络+隐马尔科夫模型)的Hybrid结构的语音识别出现在2013年前后。
Hybrid结构用DNN替换了GMM来对输入语音信号的观察概率进行建模。训练DNN-HIMM 模型之前,需要先得到每一帧语音在DNN上的目标输出值(标签)。为此需要通过事先训练好的GM-HIMM模型在训练语料上进行强制对齐。即要训练一个DNN-FIMM声学模型,首先需要训练一个GMM-HMM声学模型,并基于Viterbi算法给每个语音帧打上一个HMM状态标签, 然后以此状态标签训练一个基于DNN训练算法的DNN模型。最后用DNN替换GMM-FMM模型 中计算观察概率的GMM部分,但保留转移概率等部分。
与传统的GMM采用单帧特征作为输入不同,DNN是将相邻的若干帧进行拼接来得到一个 含更多信息的输入向量。这样DNN相比GMM更加能够提升识别成功率。
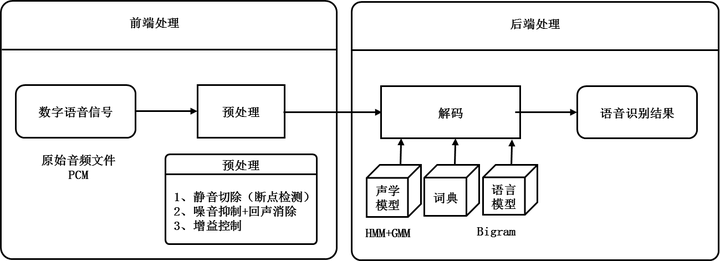 图5 Hybrid结构深度学习语音识别流程
图5 Hybrid结构深度学习语音识别流程
2.2.3 Grapheme 结构
2015年前后,基于LSTM+CTC(长短时记忆网络+连接时序分类模型)的端到端语音识别受到了广泛关注。
相对于Hybrid结构的语音识别,Grapheme结构使用LSTM-CTC模型替换DNN-FIM模型。 LSTM模型是RNN的改进,用以替换DNN-HMM模型中的DNN部分,CTC ( Connectionist Temporal Classification, 可以理解为基于神经网络的时序类分类)模型则替换另一部分HMM模型。
由于语音信号的非平稳性,我们只能做短时傅里叶变换,这就造成了一个句子会有很多帧,且输出序列中的一个词往往对应了好几帧,最终导致输出的长度远小于输入的长度。那么如何解决这个问题呢?为此引入了CTC模型的概念。CTC模型不需要对数据对齐和一一标注,这样就不用再依赖HMM模型,只需要一个输入序列(语音信号波形)和一个输出序列即可进行训练,直接输出序列预测的概率。
LSMT-CTC模型的运行原理图如下图所示(以“皮卡丘” 为例)
 图6 LSMT-CTC模型的运行原理图
图6 LSMT-CTC模型的运行原理图
CTC模型相对HMM模型更简洁,不需要再逐帧判别,大部分输入帧的输出为空,小部分输入帧的输出为音素
标签:GMM,AI,模型,DNN,语音,CTC,识别 From: https://www.cnblogs.com/jiyukai/p/17590800.html