梨视频ajax双重抓包
B站学爬虫记录
页面抓包
这个页面下拉到底会刷出24个新视频,这是ajax随机加载的。
下拉到底抓到数据
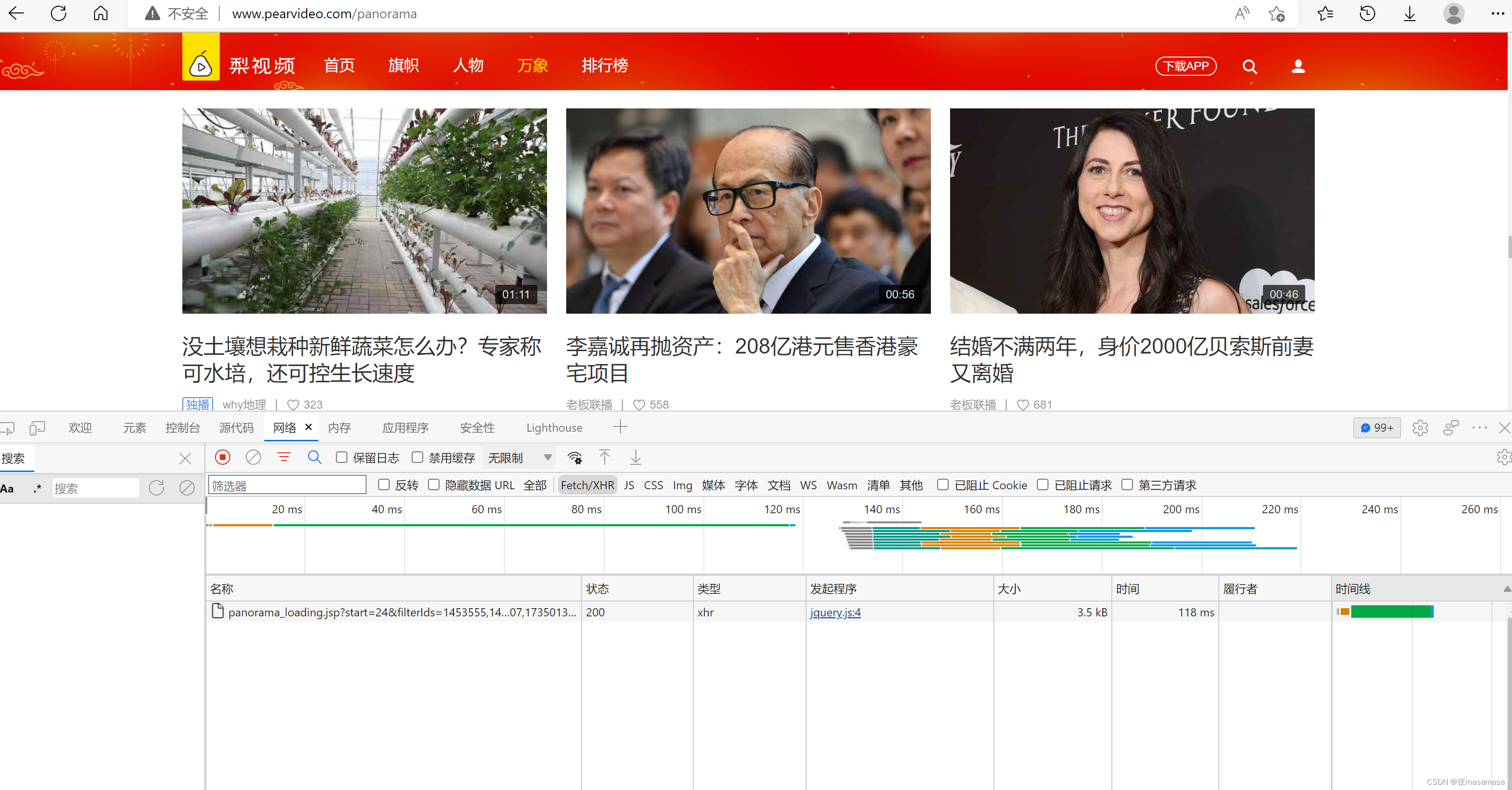
查看数据包,请求为http://www.pearvideo.com/panorama_loading.jsp?

可以发现有三个参数,start等于刷新时界面已有视频数目(24、48......),filterIds是随机抽出的视频id,mrd是random随机数。

(视频id如下)

数据包里含有视频页面的链接
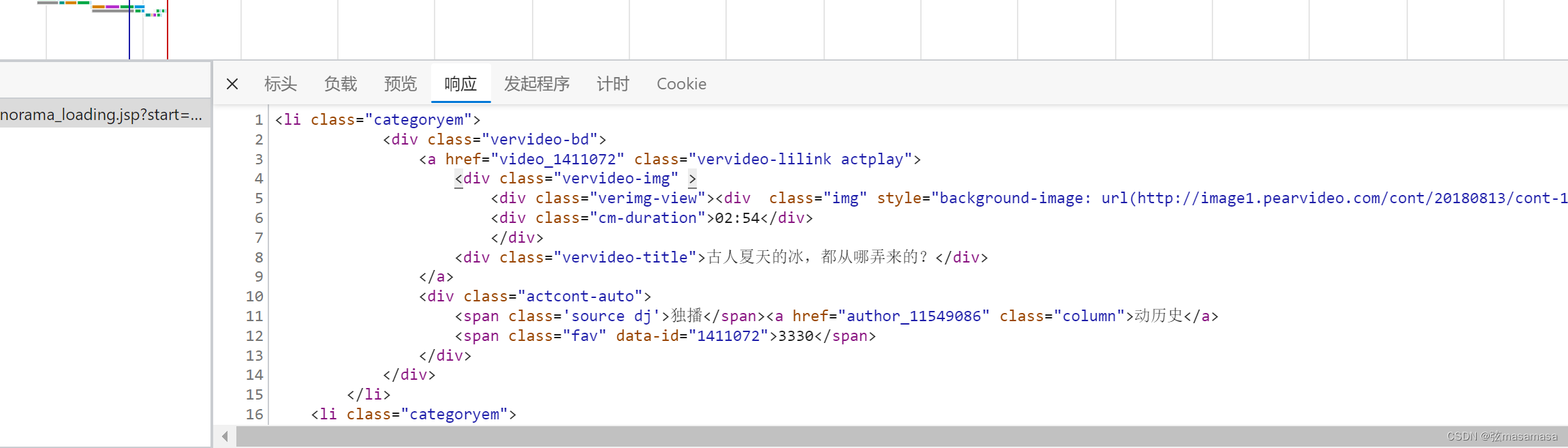
提取li的列表(xpath有点不好用,用了beautifulsoup)
def search_video(i):
url='http://www.pearvideo.com/panorama_loading.jsp?'
ids=str(random.randint(1453246,1780000))
for _ in range(23):
ids+=f',{random.randint(1453246,1780000)}'
params={
'start':24*i,
'filterIds': ids,
'mrd': str(random.uniform(0, 1))
}
html = requests.get(url, headers=headers,params=params).text
soup=BeautifulSoup(html,'html.parser')
li_list = soup.find_all('li',{'class','categoryem'})
for li in li_list:
get_video_url(li)
视频抓包
由于视频也是ajax加载,需要再次抓包。
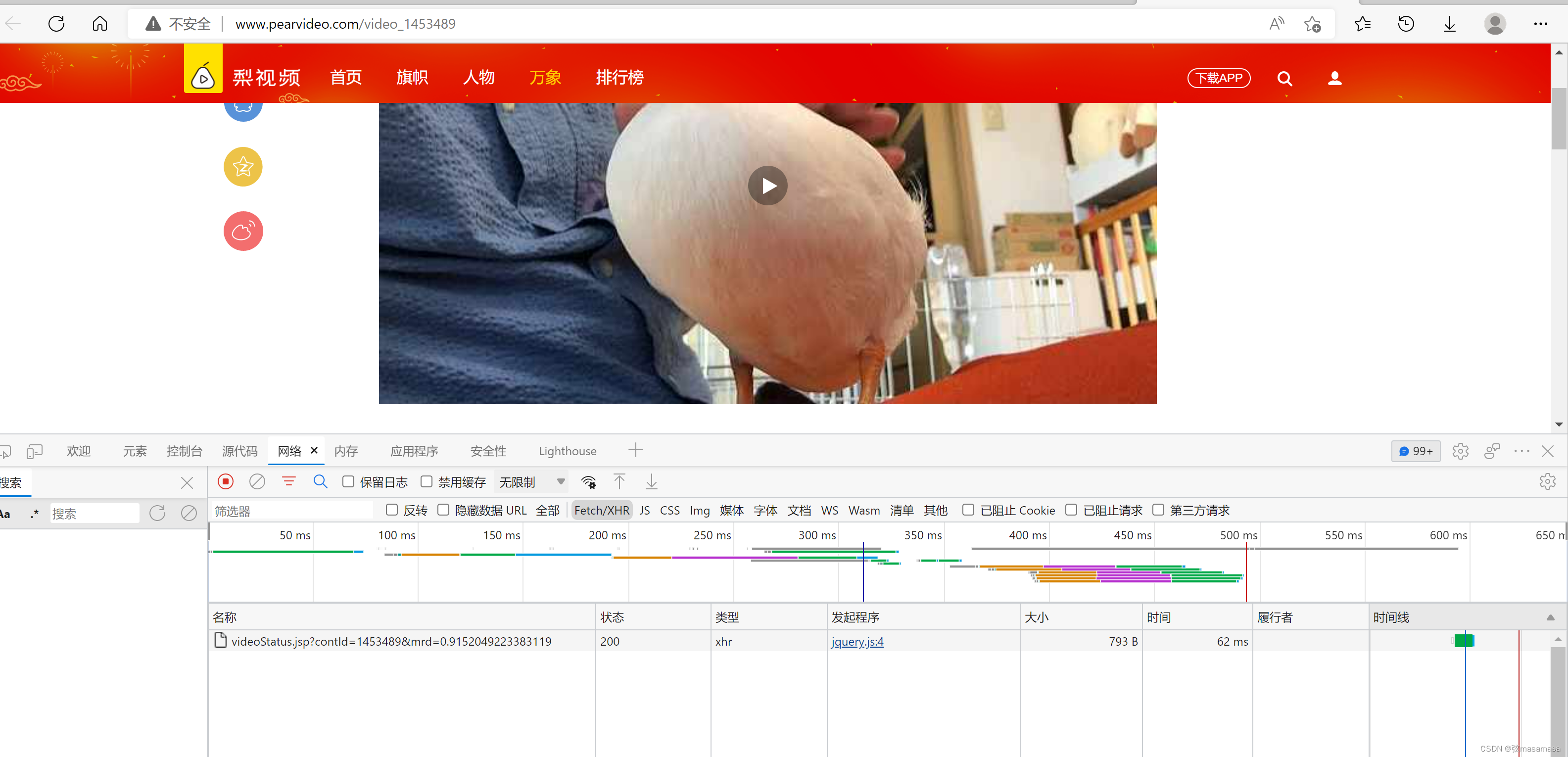
两个参数:视频id和随机数


数据中含有视频链接

可以复制cURL然后直接转化出headers。网址:https://curlconverter.com/。注意转换出来不要留cookie
提取视频链接(注意这里是json)
def get_video_url(li):
name = li.find('div',{'class':'vervideo-title'}).text+'.mp4'
# 抓包ajax
id_num = str(li.find('a')['href']).split('_')[1]
ajax_url = 'https://www.pearvideo.com/videoStatus.jsp?'
params = {
'contId': id_num,
'mrd': str(random.random())
}
ajax_headers = {
"User-Agent": ua.random,
# 加了之后不会显示视频下架
'Referer': f'https://www.pearvideo.com/video_{id_num}'
}
dic_obj = requests.get(url=ajax_url, params=params,
headers=ajax_headers).json()
video_url = dic_obj["videoInfo"]['videos']["srcUrl"]
# 注意这里不能直接上id,需要转化
# 此处视频地址做了加密即ajax中得到的地址需要加上cont-,并且修改一段数字为id才是真地址
# 真地址:"https://video.pearvideo.com/mp4/third/20201120/cont-1708144-10305425-222728-hd.mp4"
# 伪地址:"https://video.pearvideo.com/mp4/third/20201120/1606132035863-10305425-222728-hd.mp4"
secret = video_url.split('/')[-1].split('-')[0]
video_url = video_url.replace(str(secret), f'cont-{id_num}')
dic = {
'name': name.replace('"','”').replace(",",","),
'url': video_url,
}
urls.append(dic)
源代码
import asyncio
import aiohttp
import requests
from lxml import etree
import random
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from multiprocessing.dummy import Pool
ua = UserAgent(verify_ssl=False)
headers = {
'User-Agent': ua.random,
}
def search_video(i):
url='http://www.pearvideo.com/panorama_loading.jsp?'
ids=str(random.randint(1453246,1780000))
for _ in range(23):
ids+=f',{random.randint(1453246,1780000)}'
params={
'start':24*i,
'filterIds': ids,
'mrd': str(random.uniform(0, 1))
}
html = requests.get(url, headers=headers,params=params).text
soup=BeautifulSoup(html,'html.parser')
li_list = soup.find_all('li',{'class','categoryem'})
for li in li_list:
get_video_url(li)
def get_video_url(li):
name = li.find('div',{'class':'vervideo-title'}).text+'.mp4'
# 抓包ajax
id_num = str(li.find('a')['href']).split('_')[1]
ajax_url = 'https://www.pearvideo.com/videoStatus.jsp?'
params = {
'contId': id_num,
'mrd': str(random.random())
}
ajax_headers = {
"User-Agent": ua.random,
# 加了之后不会显示视频下架
'Referer': f'https://www.pearvideo.com/video_{id_num}'
}
dic_obj = requests.get(url=ajax_url, params=params,
headers=ajax_headers).json()
video_url = dic_obj["videoInfo"]['videos']["srcUrl"]
# 注意这里不能直接上id,需要转化
# 此处视频地址做了加密即ajax中得到的地址需要加上cont-,并且修改一段数字为id才是真地址
# 真地址:"https://video.pearvideo.com/mp4/third/20201120/cont-1708144-10305425-222728-hd.mp4"
# 伪地址:"https://video.pearvideo.com/mp4/third/20201120/1606132035863-10305425-222728-hd.mp4"
secret = video_url.split('/')[-1].split('-')[0]
video_url = video_url.replace(str(secret), f'cont-{id_num}')
dic = {
'name': name.replace('"','”').replace(",",","),
'url': video_url,
}
urls.append(dic)
urls=[]
for i in range(4):
search_video(i)
#协程
async def get_video_data(dic_):
url_ = dic_['url']
print(url_, '正在下载.....')
async with aiohttp.ClientSession() as session:
async with await session.get(url_,headers=headers) as response:
video_data=await response.read()
video_path = f'./{dic_["name"]}'
with open(video_path, 'wb') as fp:
fp.write(video_data)
print(dic_['name'], '下载成功!!!!!')
tasks=[asyncio.ensure_future(get_video_data(url)) for url in urls]
loop=asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
其他方法
selenium
当然以上抓包操作都能用selenium替代,但这里就略过了。
参考
https://www.cnblogs.com/qianhu/p/14027192.html
标签:url,random,li,ajax,video,站学,id,抓包 From: https://www.cnblogs.com/xianmasamasa/p/16741830.html