MapReduce
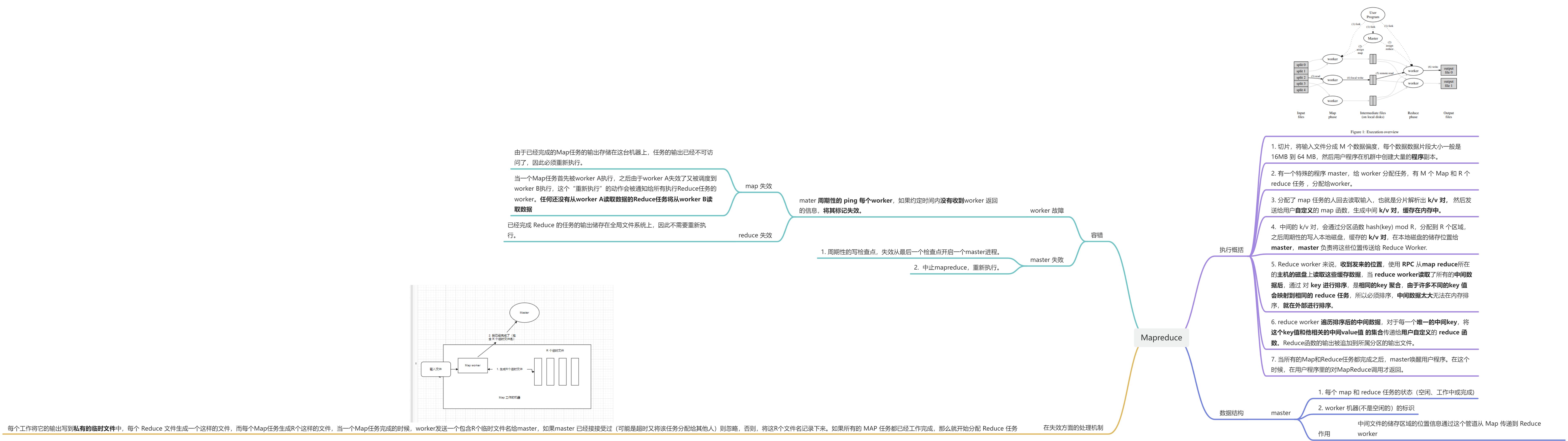
实验
干嘛
实现一个分布式的 MapReduce, 由两部分组成,master 和 worker。一个master,多个worker。在本机运行,worker 和 master 用 rpc 通信。每个worker 向 master 索要任务,从一个或多个文件读取任务的输入,执行任务,并将任务的输出写入一个或更多文件。如果超时(10s)将工作分配给其他worker
注意的一些点:
-
输出文件名 必须是
mr-out-%v -
map -> file -> reduce ,这个 file 里面存储数据的格式需要注意
-
如果一个分配的任务 工作的时长 > 超时时间,更改状态为 未分配,重新给其他人分配
-
当 worker 发现 请求不了任务,套接字关闭,则退出(master 工作完毕)。
-
前提:我们不需要考虑,map工作完成后,map 宕机的情况,解释:因为我们是在本机,如果map完成工作,我们
master会将他输出的临时文件 重命名为 正式文件。 -
worker 对于 master 的rpc调用只有两条
- 请求任务
我们可以发现只需要只有两种类型 map,reduce然后请求返回的请求实体,
map: 有多少个 reduce, 因为他要输出的文件切片; 当前的任务编号([0,m)),然后输入文件名。
reduce: 输入文件名,当前任务编号([0,r)).
- 提交任务
map 和 reduce 都需要将自己的 临时输出文件名传回,还有自己的 任务编号,以供 master 将该任务标记为 已 完成,并且将 临时输出文件 转正。
master 需要维护:
- 每个map或者 reduce 工作状态
- 开始时间(以提供后面判断是否超时,或者需要重新分配)
- 输出文件 (将传回的临时文件名 重命名后的文件名)
- 任务状态 (完成,已分配,未分配)。
- map 任务全部是否完成的标志(用于判断是否开始分配给reduce),reduce是否全部完成的标志(用于判断是否结束)
- 输入的文件列表。
// 类型
type TaskType uint
const (
NoAssign TaskType = iota // 表示没有分配任务 worker 就睡1秒
MapTask
RedTask
)
type taskStatus uint
const (
UnAssigned = iota
Assigned
Finished
)
type TaskStatus struct {
Type TaskType
Index int // 第几个任务
Status taskStatus
StartTime time.Time
//如果是 map 的话就是 Files[0]
// 如果是reduce的话就是 这个切片
Files []string // 输出输入文件表
// 如果是提交,就是提交的临时文件名
}
// 和工人通话的唯一通道
func (c *Coordinator) Talk(args *TalkReq, resp *TalkResp) error {
}
type Coordinator struct {
// Your definitions here.
lock sync.RWMutex
inputFiles []string //map 输入文件表
nReduce int //多少个 reduce 任务
// 维护 map reduce 任务的转台
mapTask []TaskStatus
mapFinish bool //如果map完成我们就开始分配 reduce
mapOutput [][]string // map 的中间输出文件名
redTask []TaskStatus
redFinish bool // 如果 reduce 完成我们就可以结束了
// 因为我们是提交后重命名,如果放在worker 中,我们可能出现 一起重命名,最好的方式是文件名传送给 master 让其执行原子操作(lock)
redOutput []string // reduce 的中间输出文件名
}
// 初始化 方便理解各字段的含义
func MakeCoordinator(files []string, nReduce int) *Coordinator {
var err error
logFile, err = os.OpenFile("/home/zsj/mit/6.824/src/main/logs/master.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
panic(err)
}
log.SetOutput(logFile)
log.Println("================================Start Working==================================")
// files 的长度就是 map 工作任务的个数
nMap := len(files)
c := Coordinator{
lock: sync.RWMutex{},
inputFiles: files,
nReduce: nReduce,
mapTask: make([]TaskStatus, nMap),
mapOutput: make([][]string, nMap),
redTask: make([]TaskStatus, nReduce),
redOutput: make([]string, nReduce),
}
for i := 0; i < nMap; i++ {
c.mapTask[i] = TaskStatus{
Type: MapTask,
Index: i,
Status: UnAssigned,
Files: []string{files[i]},
}
c.mapOutput[i] = make([]string, nReduce) // 在这就初始话把
for j := 0; j < nReduce; j++ {
//map任务产生的文件的名字格式为: mr-output-(MapID)-(ReduceID)
c.mapOutput[i][j] = fmt.Sprintf("/home/zsj/mit/6.824/src/main/mr-output/map-%v-%v", i, j)
log.Println("map temp:", c.mapOutput[i][j])
}
}
for i := 0; i < nReduce; i++ {
c.redTask[i] = TaskStatus{
Type: RedTask,
Index: i,
Status: UnAssigned,
}
c.redOutput[i] = fmt.Sprintf("/home/zsj/mit/6.824/src/main/mr-tmp/mr-out-%v", i)
}
go c.checkTimeOut()
// Your code here.
c.server()
return &c
}
学到的
库函数
package plugin
// Plugin is a loaded Go plugin.
type Plugin struct {
pluginpath string
err string // set if plugin failed to load
loaded chan struct{} // closed when loaded
syms map[string]interface{}
}
// Open opens a Go plugin.
// If a path has already been opened, then the existing *Plugin is returned.
// It is safe for concurrent use by multiple goroutines.
func Open(path string) (*Plugin, error) {
return open(path)
}
// Lookup searches for a symbol named symName in plugin p.
// A symbol is any exported variable or function.
// It reports an error if the symbol is not found.
// It is safe for concurrent use by multiple goroutines.
func (p *Plugin) Lookup(symName string) (Symbol, error) {
return lookup(p, symName)
}
// A Symbol is a pointer to a variable or function.
//
// For example, a plugin defined as
//
// package main
//
// import "fmt"
//
// var V int
//
// func F() { fmt.Printf("Hello, number %d\n", V) }
//
// may be loaded with the Open function and then the exported package
// symbols V and F can be accessed
//
// p, err := plugin.Open("plugin_name.so")
// if err != nil {
// panic(err)
// }
// v, err := p.Lookup("V")
// if err != nil {
// panic(err)
// }
// f, err := p.Lookup("F")
// if err != nil {
// panic(err)
// }
// *v.(*int) = 7
// f.(func())() // prints "Hello, number 7"
type Symbol interface{}
plugin可以查询到符号表的东西,类似于将ELF表读入内存,解析,然后将地址翻译为 函数指针。
具体用法 看第 42 行
// Golang program
// demostrating how to use strings.FieldsFunc() Function
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
myFunc := func(c rune) bool {
fmt.Println(string(c),unicode.IsNumber(c))
return !unicode.IsNumber(c)
} // 如果满足则删除
// When a number is encountered,
// the FieldsFunc() method separates the string
// and returns all non-numbers.
fmt.Printf("The Fields are: %q\n",
strings.FieldsFunc("This018is92a6shot179on89Golang864string34FieldFunc", myFunc))
}
=========
T false
h false
i false
s false
0 true
1 true
8 true
i false
s false
9 true
2 true
a false
6 true
s false
h false
o false
t false
1 true
7 true
9 true
o false
n false
8 true
9 true
G false
o false
l false
a false
n false
g false
8 true
6 true
4 true
s false
t false
r false
i false
n false
g false
3 true
4 true
F false
i false
e false
l false
d false
F false
u false
n false
c false
The Fields are: ["018" "92" "6" "179" "89" "864" "34"]
sed -i 's/\r//' one-more.sh
Lab 2A
投票
如何判别自己当前是否投过了 ?
最初,我使用了voteTerm标识当前是否投票,最后移除原因有下:
更新场景 只有 投票的时候
那么问题来了, 什么时候认为这张票可以投,也就是
- 这轮
term比当前的term大 - 这轮
term我们已经投给他了
逐个来看
-
当我们发现 自己 过时,自己的
term会更新,在这个时候,我们将voteFor -> NULL然后进行投票 -
前提: 当
rpc的term小于 自己的term会 直接拒绝 -
当前
term = curTerm( 因为 自己过时 会进行1的处理逻辑,如果我们VoteFor == NULL就只有一种情况 ( 如果有rpc失败(网络原因不是没有获取到票)重试操作, 那么返回的rpc可能丢包,那么这轮选举会出现重复给同一个人的情况):前面更新(这个需要结合最开始的情况),那么投给他,更新VoteFor。
if rpc 过时 {
return false
}
if 自己过时 {
改变 VoteFor, 更新任期
}
投票逻辑
解释 term:voteFor
- 从开始来看,
0:-1 - 超时 获取 投票,
1:me(其他人收到后,会先执行 **过时 **的处理逻辑)
后来这个任期内有人的投票请求** 晚 **一步到来,那么发现当前任期内已经投票,所有不能投了。
那么问题来了?
- 投票之后的处理逻辑
- 什么时候该发起一轮投票
投票之后的处理逻辑
当我们投票成功之后,我们需要将身份转变为 候选人,更新term,并重置选举计时器。
什么时候该发起一轮投票?
前提:
- 心跳
<<选举超时时间。( 保证我们没有收到多次心跳之后才会发起 投票) - 并且接受者如何知道是合法心跳的条件
rpc term >= curTerm( 当前没有日志,lab2b 会记录日志这个变量对合法的影响)
选举超时时间之后。
如何更新选举超时时间
leader的合法rpc- 成功投票
- 发起投票
实验遇到的困难:
困扰两天。
实验的时候
会一直发现,有三个机器
假设 term:leader
1:0 断开
重新选举 得到 2:1,将 1:0 加入,1:0无法正确认识到自己过期,
思考过程:
- 发现在 长达
500ms之内都没有rpc请求的发送- 排查是否是
P太少,无法并行?runtime.MAXPROCS(8)侥幸成功几次,发现失败 - 增加心跳检测频率 -> 失败
- 观看学生指导,发现问题
0断开时,还在处于心跳发送,这时的rpc会超时( 也就是 无法在该选举的时间点 发起选举请求)0无法接受, 新leader也会等待0``rpc的回复。
- 排查是否是
解决办法:
func election(){
... 前置逻辑
go func(){
// 发送请求
// 失败
// 增加超时
}
}
总结:
rpc超时, 没有在规定的时间内获取到请求, 然后没有在特地的时限内完成指定动作( 选举超时就要选举 )
踩过的坑
- 投票任期的浅理解导致新增字段
voteTerm - 没有考虑
rpc超时 leaderop新起goroutine引入cond, 来唤起操作 。 导致代码丑陋且难以维护。
总结:
Raft
- 如何处理 脑裂
- 过期
term - 如果出现这轮
term的脑裂,这个需要比较日志。lab2b会给出解释
- 过期
- 如何进行 选举
- 超时, 获取 一半以上人的同意
- 逻辑时钟
term
Lab 2b
有点小难
任务目标
在lab2a的基础上面引入日志
- 应用日志(
applyCh) - 维护日志(
[]log) - 传递日志(
appendRpc) - 选举限制 (比较日志任期以及索引)
问题
- 如何应用日志
利用 applyCh 传入,test_test.go会利用map来记录每个提交的 command
func (cfg *config) nCommitted(index int) (int, interface{}) { // 检查这个索引处有多少个人提交
count := 0
var cmd interface{} = nil
for i := 0; i < len(cfg.rafts); i++ {
if cfg.applyErr[i] != "" {
cfg.t.Fatal(cfg.applyErr[i])
}
cfg.mu.Lock()
cmd1, ok := cfg.logs[i][index] // 获取 command
cfg.mu.Unlock()
if ok {
if count > 0 && cmd != cmd1 {
cfg.t.Fatalf("committed values do not match: index %v, %v, %v",
index, cmd, cmd1)
}
count += 1
cmd = cmd1
}
}
return count, cmd
}
- 如何发送
通过 append rpc,当我们commit Index更新时,我们会利用Cond来通知另外一个G来消费,并且更新当前最后一个更新的索引,这里还要注意,commit Index会减少( 下面的问题会解释)。
- 日志 index 对于以前 选举的影响 有哪些
- 比较候选人的日志是否比自己的新 , 比自己旧,那么就不投票
term相同,比较 index
term 不同,比较term
// 比较 rpc 请求的日条目是否比自己的新,或者一样新
// 返回true 代表可以给他投票
func (rf *Raft) compareLogL(args *RequestVoteArgs) bool {
// 日志条目的比较
lastIndex := rf.log.lastLogIndex()
if args.LastLogTerm != rf.log.entryAt(lastIndex).Term {
return args.LastLogTerm > rf.log.entryAt(lastIndex).Term
}
// term 相等比较
return args.LastLogIndex >= lastIndex
}
问题描述

更新 commit idx 出错, 具体来说就是 **5 **个点
选出 一个leader4,然后断开 1,2,3
都先 append 一个 命令
0 【4】 在一个网络分区,所以 不会更新 commit idx (2 < [ 5 / 2 + 1 = 3 ]
【1】 2,3 在一个, 50个 cmd提交, commit idx -> 51
断开2
【1】3 在一个分区50 cmd不提交,断开 1,3 恢复 4,0,2
现在 4,0,2 在一个,2 的 term最新,所以会当选为leader
【2】,0,4
现在我们来梳理一下所有的信息
|
| term | commit index | log entries count |
| --- | --- | --- | --- |
| 2 [leader] | 3 | 51 (term: 2) | 51(term: 2) |
| 0 | 3 | 1 (term: 1) | 51(term: 1) |
| 4 | 3 | 51( term: 1) | 51(term: 1) |
出现问题, 4 更新了 commmit index -> 51, 说明我们 接受 日志的时候,在判断 prevLogIndex 以及 prevLog Term出错,
正常情况
发现 prevLogIndex的日志存在,但是该索引位置下的term != pervLogTerm, 说明 之前的日志不相同,reply.Success = false,立即返回。

解析
判断日志是否连续出错。

出现这种情况,也就是我们无法保证前面日志 leader 与 follower 一致,会立即返回
leader收到后, 知道可能是日志不连续,会将 nextLogIndex递减,然后重试,直至一致

涉及到的论文
为什么使用日志?
从状态机的视角来看待, 执行程序,相当于 **寄存器,内存 的信息发生 转变,比如 fork,就复制了当前的状态(当前除了进程私有状态pid等 ),redis的持久化从而利用了这个状态 **,使得不阻塞命令的执行来进行之久化。
再比如,tcp的状态转移图,从 closed -> syn_sent:当前状态为 closed 且 发生了 发送 syn的 动作 之后,状态转变为 syn_sent.
当前状态 发生动作 转变为 另一个状态
日志就是一个一个的动作,我们可以根据这个动作,在当前状态上进行转变,从而到达一个新状态。
目的
保证日志的一致性,也就是 服务端接受客户端的命令,通过 一致性通信保证大多数服务 **最终 **以相同的顺序来应用日志,就算发生故障,
那么如何进行日志复制呢?
通过 rpc 请求,其中会包含日志条目。
// 收到命令
// 追加日志( 自己的 )
// 发送 AppendEntriesRpc 给其他所有人( 除了自己 )
如何保证相同的顺序呢?
涉及到 5.3 日志复制。
首先了解,怎么记录日志。
type (
Log struct {
logs []LogEntry
}
LogEntry struct {
Term int
Command interface{}
}
)
为什么还要记录日志的 任期呢?
其实这个就相当于时间一样( 前面提到的逻辑时钟 ),可以检查出当前的日志是否不一致。

这块非常值得品鉴。
如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
得益于一个 term只有一个 Leader( 选举会将 term++ ), 并且这个 Leader 只会在一个 位置 存储一个日志
最开始的时候都是 Follower, 只能通过选举来 成为 Leader,但 Leader 的选举 只有 投票只有获得一半以上的票数才能成功,
节点投票的限制起了作用(保证了不重复在同一个任期选举):
- 一个
term只能投一票 ,但可以重复投给在该term投过的人 - 不会投过
term比自己小的人
选举的操作 将任期 + 1, 。
最开时候的 Leader 在该 term 一定是唯一的,如果出现网络分区,那么说明 他们会开始新的选举,term 会增加,与当前 term 无关。
如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
不妨从最初的状态来理解,刚开始 所有的服务器状态都相同,然后在rpc包含一些信息
type AppendEntriesArgs struct {
Term int // leader’s term
LeaderId int // so follower can redirect clients
PrevLogIndex int // index of log entry immediately preceding new ones
PrevLogTerm int //term of prevLogIndex entry
Entries []LogEntry // log entries to store (empty for heartbeat may send more than one for efficiency)
LeaderCommit int // leader’s commitIndex
}
Term: 用来判断当前 rpc 请求是否过期,过期 就会拒绝。
PrevLogIndex, PrevLogTerm: 红色框是当前 rpc 请求中包含的,黑色箭头就是 所谓的 PrevLog。这两个信息就是描述这个日志的。

这样 接受的人会判断 这个 PrevLogIndex处我们是否有日志呢?如果没有
可能是
- rpc 丢失
- 只是丢了而已
- 网络分区
[1,2] [3,4,5] 两个分区 提交的命令数量可能不一样,这个时候,就出现 log 的数量不一样,进而在网络流畅之后,出现日志的 缺失

如果有呢?进而判断是否日志的 term 是否相等
得益于第一个条件
相等 -》 同一个领导 + 领导只会在一个索引处放置一个日志
进而,从最开始,一只追加,保证了日志的 “连续性”。

不妨针对图中所有情况是怎么出现的 (结合这幅图)
很简单就是rpc 没有到来(丢失或者延时)
b) 失联了
c)
d) term 6 leader 断开链接, 重新选举出来
e)term 4 的leader
f) term = 2
如何更新 commit index
next
优化 rejectIndex
如果发现term不相等,那么将xterm设置
如果发现term对,但是 index 不想等, 那么设置 xindex 为当前term的第一个
如果发现没有prevlogindex,设置xlen
Lab 2c
提交地址
任务目标
- 清除什么东西需要持久化
- 在这些状态改变的时候,需要将状态持久化(应该是一个接口),当机器重启的时候,会去读取这些日志
- 写
persist以及 repersist ,
什么是需要持久化的呢
- 当前任期
- 给谁投票
- 日志
特别指出
在响应 rpc 之前 更新到可靠存储上面
实验本身的持久化不难,因
需要了解持久化的状态有哪些。
Term
Vote
Log
那么实验的难点在哪呢?
- 将以前的细节放大化
- 需要优化 日志不匹配时的 后退
- 以及自己写的死锁 。。。
日志加速回溯
核心就是 如何找到第一个满足日志追加要求的。
接受者

领导人
- 传回来 confictLen 那么就从 更改 nextIdx = conflictLen
- 如果发现有 Xterm
- 包含Xterm, 那么就找到该Term的最后一个日志记录发送
- 不包含,那么就将 nextIndex = conflictIndex
心酸历程
写 perisist 只需要10分钟不到,但是找之前写好的bug花了我足足两天,期间错误的出现十分怪异。
文件夹是打印的错误日志
发现错误
是这样子的,说明我们没有在没有在固定时间内选出合理的 leader,所以我断定是** 心跳频率太短,以及选举超时的时间不够长**所导致的。
事实证明,我想法过于天真,我发现无论怎么改上面的参数,都只会降低错误的频率,还会出现 提交不一致的错误( 这是重点,这是个坑。。。。。)
改变方向
我将目光聚集到 选举的处理
- rpc 请求
- 选举超时的设置
- 选举失败的处理
首先我们看 2(因为2 在lab2a 时踩过一次坑)
重温,什么时候该重新设置选举超时呢?
- leader 的合法rpc
- 发起选举时
- 投票给别人
目光聚集到 1 (因为 2, 3 的含义十分强硬,只有 1 的合法不好理解)
首先看我当时的处理代码

在我看来,只有成功让我追加到日志,就是合法的。
这样处理真的对吗?
返回假就一定不合法嘛?
不一定
- 自己当前过期,这个leader合法嘛?
- 如果日志冲突,合法嘛?
这两条其实都是合法的,参考学生指导这条语句。
自己的理解
接受者发现自己过期 所进行的动作 并不能 说明 leader 不合法。这个时候应该更新心跳时间,所以我这个 更新心跳时间有可能因为 日志不连续 而没有进行。从而因为 回退不及时 导致重新开始选举。
转变
更改后发现,还是没有处理完这个bug。
那么究竟是什么原因,我发现重试的选举十分多,中间有10s都在选举失败,那么问题聚焦在选举失败的处理上面。


这是我们处理,这里的操作只有等待一个随机时间。这里的问题就是 所以节点在同一时间点发起选举(虽然这个区间是 [200,300] ms但是我的ticker是 time.Sleep [200,300] ms ,很有可能大于这个时间点,所以都超时了),并没有等随机时间.

查看了etcd的实现, 就恍然大悟了。

还没完呢
当我解决了这个问题,但是,新的问题出现了,

这里的问题,不经常出现,大概1/100,所以我必须重新插入更详细的信息在 follower 追加日志的时候


也就是说当处理日志冲突的时候出现了问题,他并没有 更新 commit index 导致那个 apply map ,在 key = 410( lab2b) 的时候存的是以前的旧值。

可以看出 commit index 的处理逻辑写错了。红色矩形是截断的日志,红色箭头代表原来的 commit index。
应该是 当 commit index > 截断后最后一条的日志时,应该回退,并且更新 last applied

终于完了
让我高兴了好长时间,但是又被我自己打脸了,因为我超时了( 10 min)中, go test panic了。
查看打印的堆栈信息,发现是全部都是在apply上面,我将目光聚集在此,

发现问题,在终止的时候因为拿了锁,导致其他处理 rpc 的一直在阻塞(这里使用的是 一把大锁保证)
解决之后,一切也该结束了。
总结
心态
- 没有什么是可信的,就算通过了测试,不能说明自己的代码是正确的,可能只是目前能跑通这个测试而已。
- 调试一定要耐心,做好持久战的准备。
Raft
- 更加了解日志匹配特性, 以及日志冲突的处理
- 实现了 日志加速回溯
- 对选举为什么要设置 重试时间 有了理解
Lab 2d
任务
- 实现
InstallSnapsnotRpc - 当日志冲突时可以发送照
快照代表着什么
当有了 快照以后,发送的时候需要做什么处理呢?
之前的判断是判断 nextIdx,但是当我们拥有了快照之后,需要判断的就不只是 nextIdx还有起点。
所以之前 lab2c的优化 xterm, xlen, xindex
就要加入起点这个判断因素了
首先
传送日志的时候,就是 日志是连续的,根据 nextidx 来判断
- nextidx < lastLogIndex && nextIdx >= FirstLogIndex
接受方判断
如果当前的日志没有,
那发送方可以直接发送快照,规定 xlen = 0,那么我们这个 xlen 其实就没有什么用了
问题来了
如果接受方的日志数最多,那么一定意味着大多数的节点也具有起日志(因为快照是根据commit index 来决定的)

总结
先行写个总结,有被日志索引难到,等我画画图,搞了一下午,发现对快照的传输不理解,应用快照的lastincludeIdex 含义不理解。

那我们应用的时候,应该这样,将0替换为快照,start = 0 -> lastincludeIndex
比如当前的是3 start = 1( 也就是 lastincludeIndex = 1)然后将日志截断
[lastincludeIndex - start : ] 这样我们就相当于 将 3 当作start了。

当我们获取到最后一条日志的时候,我们应该是 lastLogIndex = start + len(l.logs) - 1(除去start)
那么第一个日志就是 start + 1
如果接受日志的话
目前我们有 xterm,xindex,xlen
当
prevLogIndex = a,prevLogTerm = b
a < startLog ( xlen = rf.startLog)
说明我们的日志多,接受者应该从这个 start 开始发,也就是 next[idx] = startLogIndex
lastLogIndex > a >= startlog 说明我们包括
那么就可以继续之前的判断 设置 xterm, xindex
判断term
如果 lastLogIndex < a 说明我们的日志太短,让他发送快照就可以了 xlen = 0, xterm = 0, xindex = 0
如果我们接受到快照之后呢?
我们应该干什么?
- 接受者:
- 如果我们收到快照发现之前到没有 apply,那么我们直接将 apply 更新,也就是 两者最大值,并且更新commit Index
- 发送者:
- 对方回复后,更新 nextIdx,以及matchIndex 然后更新commitIdx
- 如果接受者发现他的 previndex
对于不一致的,快照基本就是加速覆盖

搞清楚之后就容易多了