机器学习编译是一个 process,把机器学习的开发转到部署。
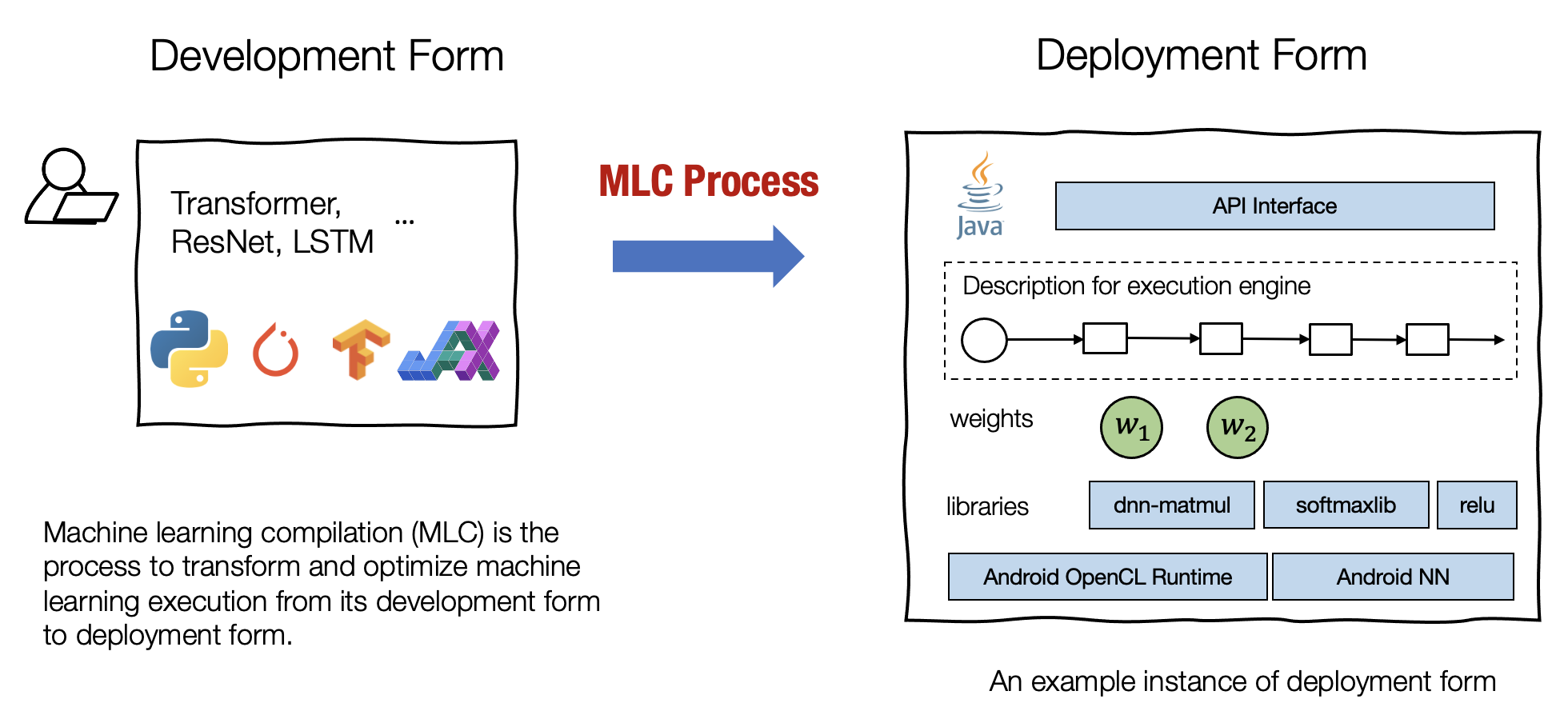
机器学习编译的目标
-
Integration and Dependency Minimization. 集成与最小化依赖.
部署应用需要集成必要的元素,我们希望部署应用的时候尽可能减小应用的大小。
-
Leverage Hardware Native Acceleration. 利用硬件原生加速.
利用硬件原生特性加速开发和部署速度,可以构建调用原生加速库(如 CUDA、CuDNN)的部署代码或利用原生指令(如 TensorCore)的代码。
-
Optimization in General. 通用优化.
一些通用的优化,通常涉及:
- minimize memory usage. 减小内存或显存占用.
- improve execution efficiency. 加速训练/推理.
- scaling to multiple heterogeneous nodes. 更好的可扩展性.
机器学习编译的关键要素

其实就两个:
- 张量(Tensor):Tensor 是执行中最重要的元素。可以用来表示神经网络模型的输入、输出和中间结果,一般用多维数组表示。
- 张量函数(Tensor functions):涉及 tensor 的计算序列称为张量函数。可以是一个算子(op)或者端到端的计算过程。
例子:
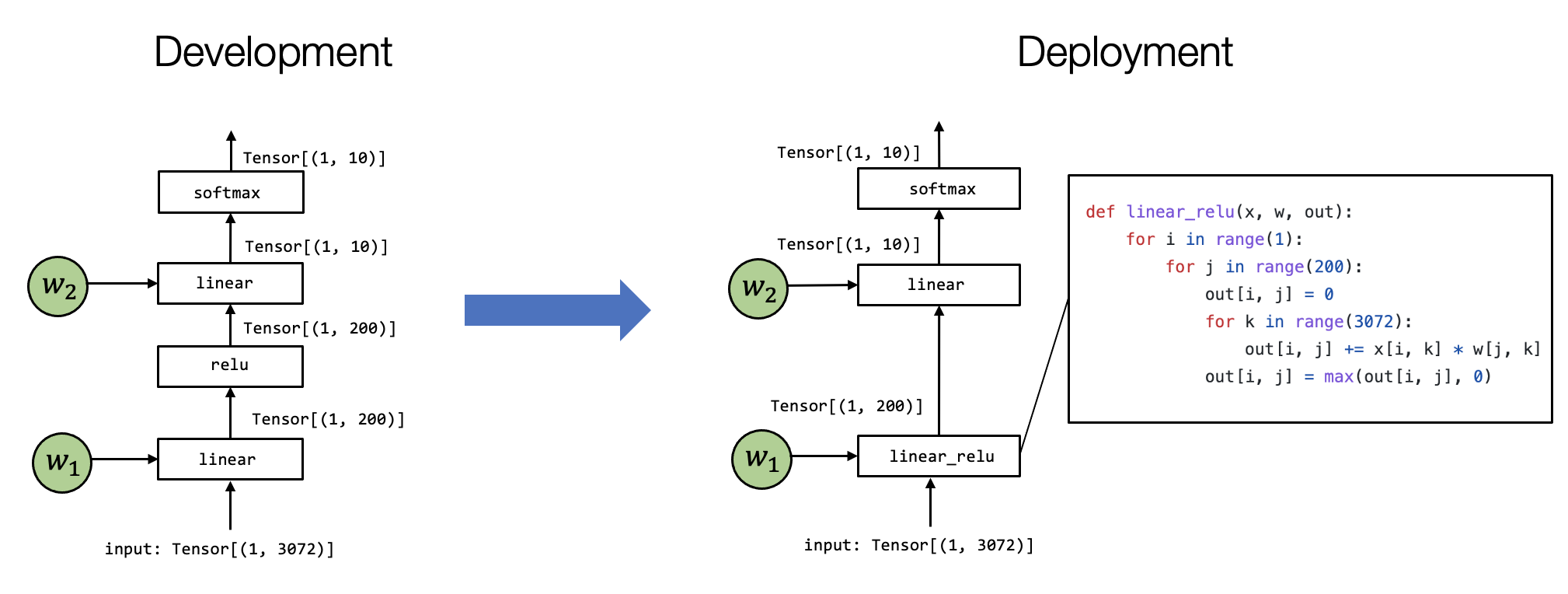
上图的输入、中间结果、输出都是各种 tensor,只不过 shape 不同。
涉及到的 linear、relu 这些 op 会定义如何接受特定的输入并计算。
有时候机器学习编译还会涉及左图到右图的转换过程,可以看到 linear 算子和 relu 算子被融合成了一个 linear_relu 算子,这个过程叫算子融合(operator fusion)。
标签:机器,linear,学习,编译,概述,算子,Tensor From: https://www.cnblogs.com/linrj/p/17573092.html