SigNoz号称自己是开源领域的Datadog,基于OpenTelemetry做了一套可观测性方案。夜莺从V6版本开始,也希望做全栈可观测性方案,巧了,大家目标一致,今天我们一起来对SigNoz做个初步了解,看看其产品设计如何,也帮大家未来选型做参考。
1. SigNoz介绍
SigNoz is an open-source application performance monitoring tool that helps you monitor your applications and troubleshoot problems. SigNoz uses distributed tracing to gain visibility into your software stack.
SigNoz是一个开源的应用性能监控工具,帮助您监控应用程序并解决问题。SigNoz使用分布式跟踪来获得对软件堆栈的可见性。
点评:上面这个英文介绍是从其官网摘录的,从这个介绍中,我第一感受是SigNoz更侧重分布式链路追踪。
With SigNoz, you can do the following:
- Monitor application metrics such as latency, requests per second, error rates
- Monitor infrastructure metrics such as CPU utilization or memory usage
- Track user requests across services
- Set alerts on metrics
- Find the root cause of the problem by going to the exact traces which are causing the problem
- See detailed flame graphs of individual request traces
使用SigNoz,您可以做下面这些事情:
- 监控应用程序指标,如延迟、每秒请求、错误率
- 监控基础设施指标,比如CPU利用率或内存使用率
- 在多个服务之间追踪用户请求
- 在指标上设置警报
- 通过转到出问题的trace来找到问题的根本原因
- 查看单个请求trace的详细火焰图
点评:上面的介绍是SigNoz声称自己可以做到的事情,但是程度如何还未可知,不同的可观测性产品通常都说自己可以观测到软件的健康状况、可以定位根因,但真正用起来就会发现,要么数据不全,要么做得太浅,基本都只是把可观测性三大支柱的数据简单筒仓式罗列,真正好用的没几个。所以这样的宣传语看看就好,具体好不好用,还是要真正的去用一下才知道。
2. SigNoz架构
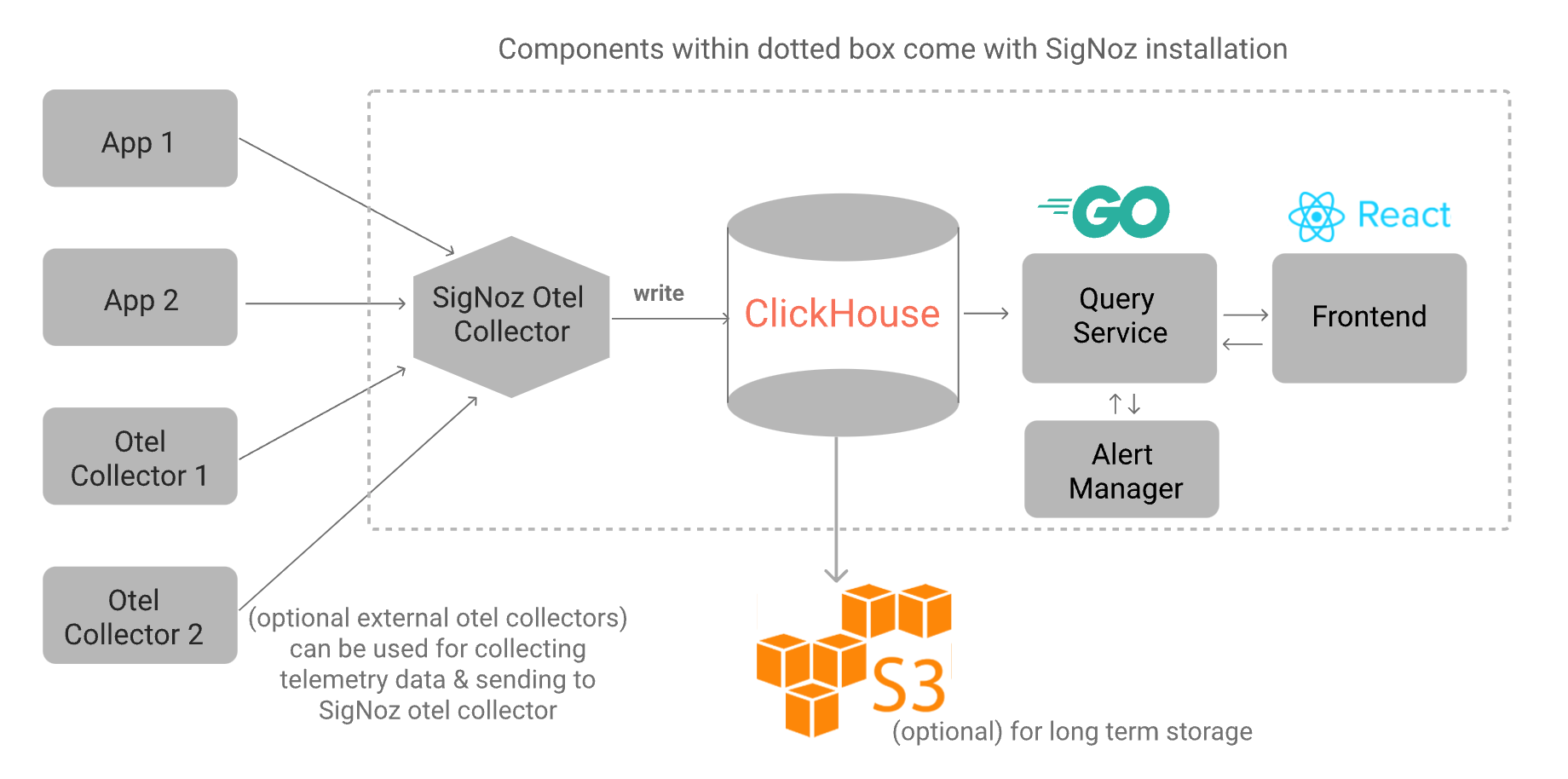
这个架构很清晰,SigNoz自身不提供采集器,完全复用 OpenTelemetry 的能力,不过 Otel Collector 这块它在架构图里冠以 SigNoz,不知道是否对社区的 Collector 做了二次开发,存储使用 ClickHouse,SigNoz 自己用 Go 开发了 Query Service 组件和 Alert Manager 组件,前端使用 React 开发。
从数据流上来讲,应用程序埋点推送监控数据给 Otel Collector,Otel Collector 对数据做初步处理,之后直接写入 ClickHouse,写入链路就算完事了。前端和 Alert Manager 对 ClickHouse 的查询会统一发给 Query Service,Query Service 会把 HTTP 请求转换为 ClickHouse 的 TCP 查询语句。
点评:链路追踪的 Span 数据存入 ClickHouse 这种列存存储,是越来越多公司的做法,长期数据扔到 S3 节省成本,也没毛病。对于日志数据,也有越来越多公司尝试存入 ClickHouse,SigNoz 显然也是把日志存入了 ClickHouse。不过,指标也存入 ClickHouse 的做法未必妥当,指标的标签是不固定的,但是 ClickHouse 是固定 Schema 的,难道直接扔到 Map 字段了?开源社区里指标的存储,笔者还是觉得 VictoriaMetrics、Thanos 是更好的选择。
3. SigNoz安装
最简单的安装方式是 Docker compose:
git clone -b main https://github.com/SigNoz/signoz.git && cd signoz/deploy/
docker-compose -f docker/clickhouse-setup/docker-compose.yaml up -d笔者是 Macbook M1,可以正常运行:

我这只是初步测试尝试,所以直接使用 Docker compose 在笔记本运行了,生产环境运行的话,重点要关注 ClickHouse 的部署。
之后浏览器访问:http://localhost:3301/就可以看到 SigNoz 的登录页面了,随便输入用户名密码就可以登录了。第一个用户默认进来就是Admin。
4. SigNoz功能初体验
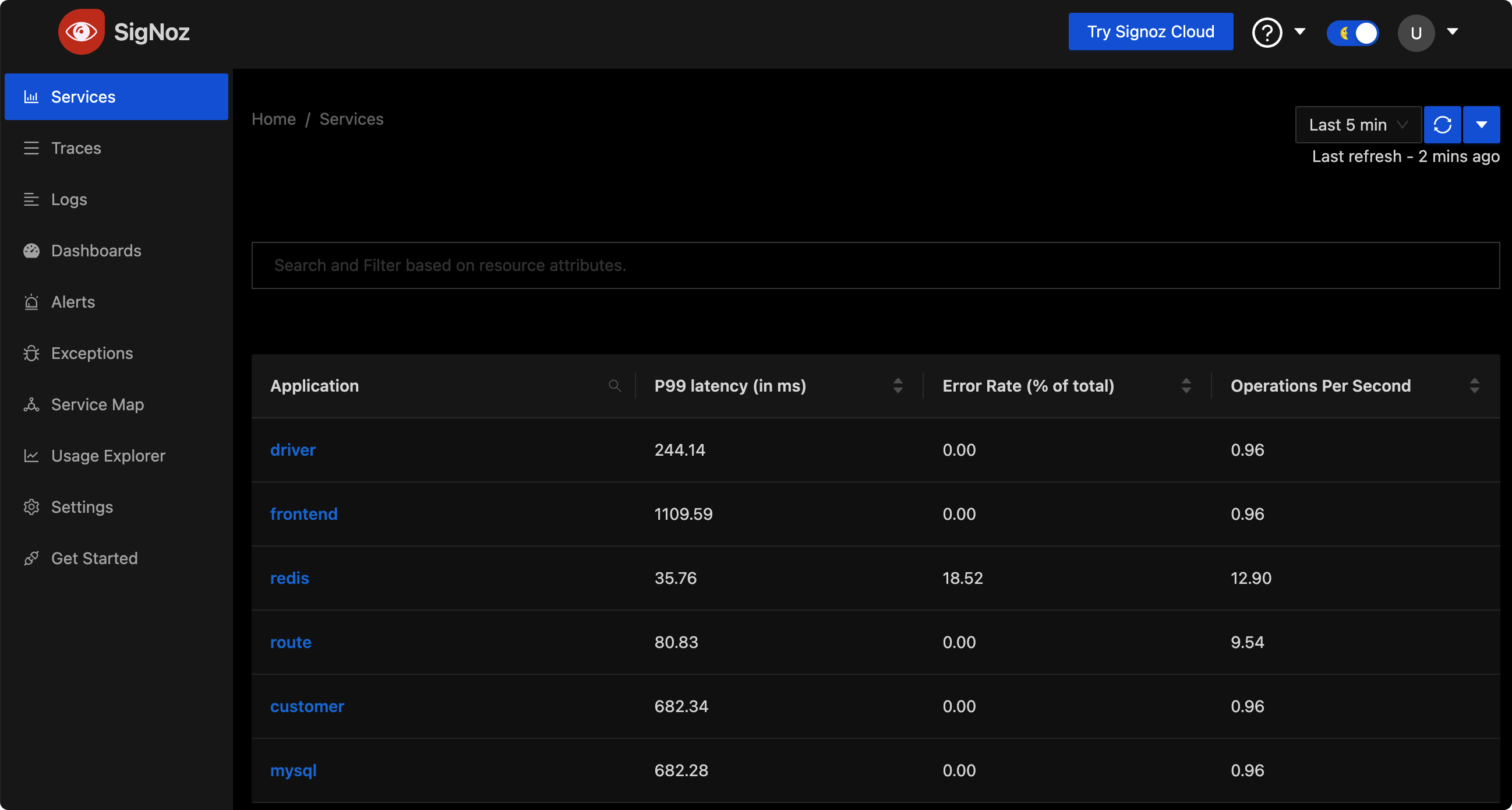
左侧菜单可以看出 SigNoz 的核心功能,我们挨个看一下。首先是 Services,即服务列表,即接入链路追踪系统的那些微服务,会展示每个服务的 P99 延迟、错误率、每秒请求数,显然是符合 RED 方法论的。上图截图就是这个页面。
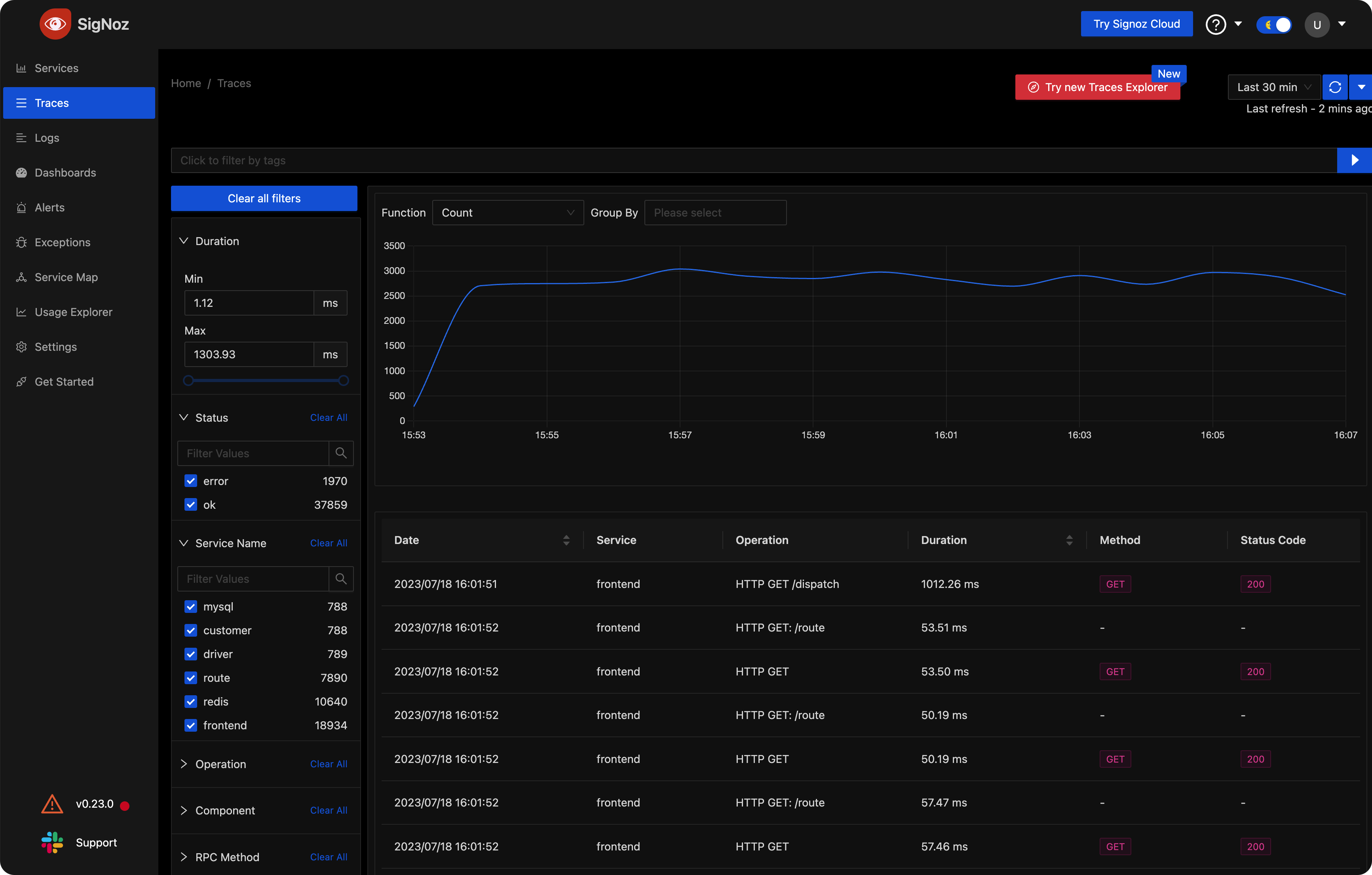
Traces 菜单,是展示近期所有 Span,可以通过 Service Name、Operation、Status、Duration 等做筛选,如图:
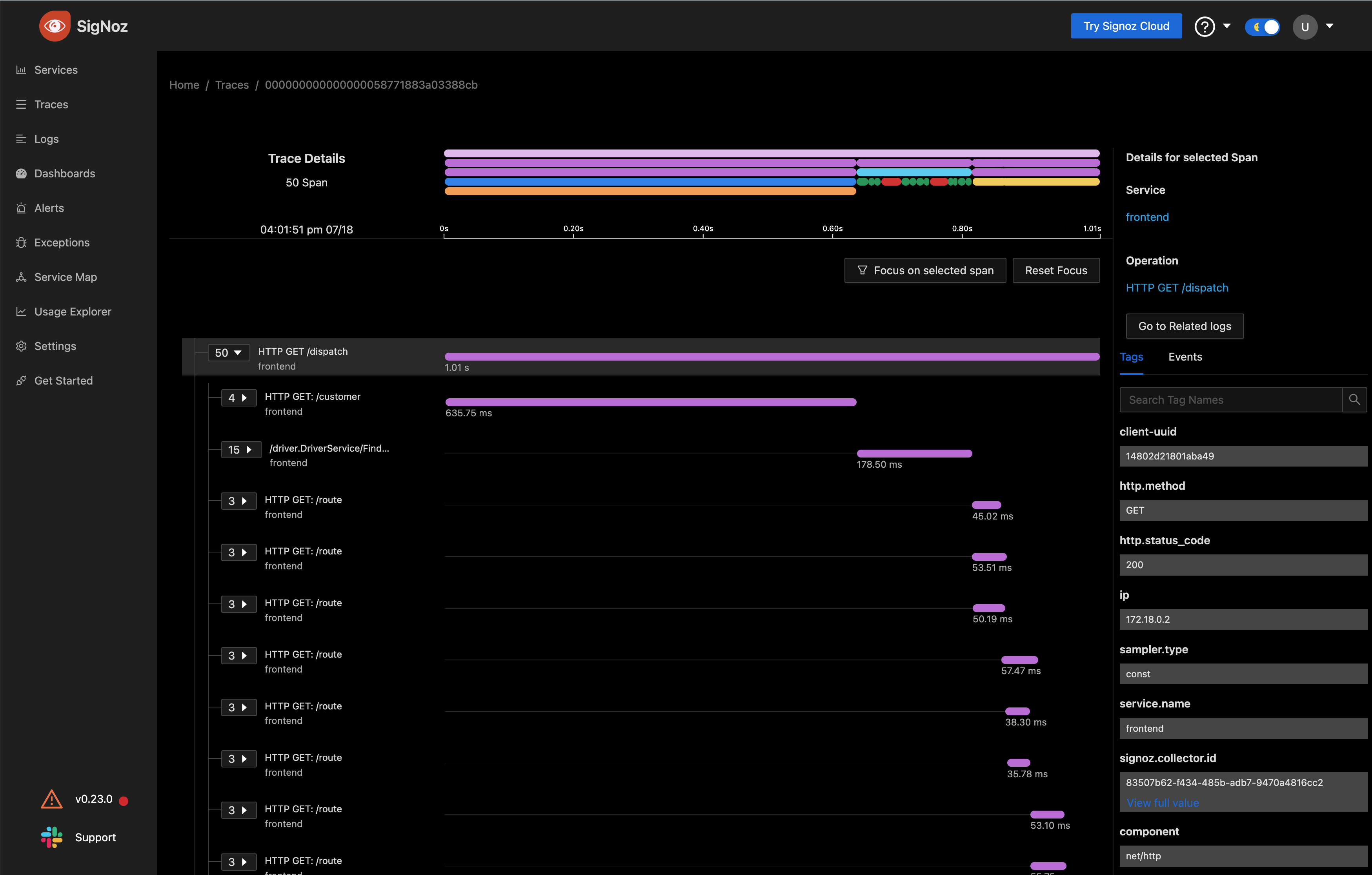
点击某个 Span,可以跳转到相关的那个 Trace 的瀑布流图:
点评:以上功能其实都是 Trace 功能,相关竞品有 Skywalking、Zipkin、Jaeger 等。看起来 SigNoz 主打的也是 Trace,后面还有一个拓扑图的菜单,也是 Trace 相关的。只是简单看这些页面,感觉也基本够用。能够检索链路信息,也能根据 Trace 数据生成基本的 Metrics 数据,如果再能够从日志里跳转到 Trace,那就更好了(没有看到这个打通)。
Logs 菜单,是展示日志。当前效果图如下:
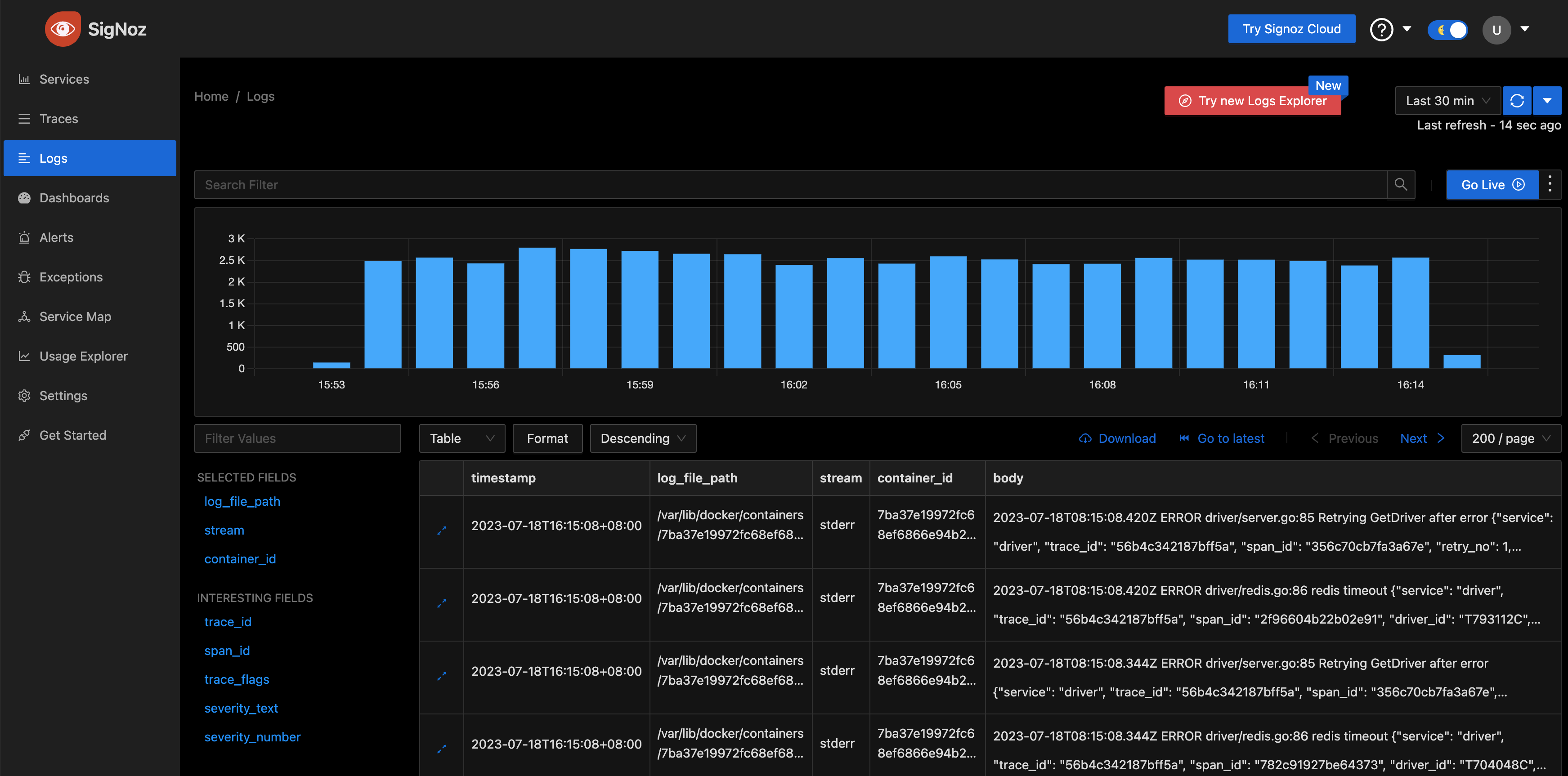
点击某个日志行,可以看到日志详情,日志体没有做字段拆解,可能还是需要引入 logstash 之类的组件才可以:
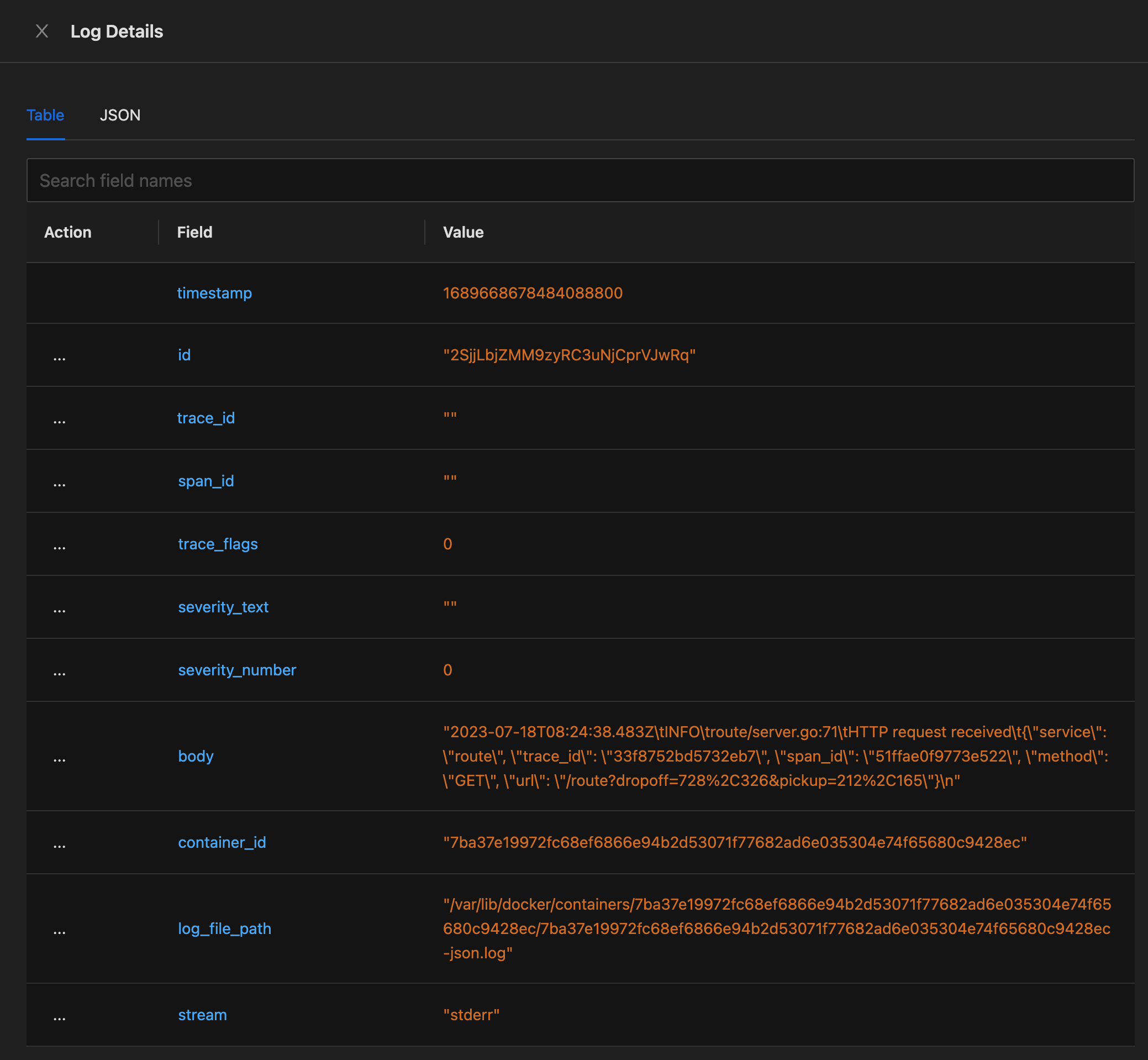
点评:初步体验下来,没有 ELK 的体验好,比如 Kibana 页面可以看到不同维度信息的 Top 视图,这才是可观测性产品应该提供的能力。只是提供基础数据还远远不够,把数据的特征展示出来,进而帮助用户建立观点洞察,最终形成 actionable insights,才是可观测性产品的核心价值所在。我看 SigNoz 也提供了 Cloud 产品,不知道是否做的更多一些,一些更牛的功能放到 Cloud 也是不错的商业决策。毕竟,全职研发人员有收入了才能反哺开源社区。
其他功能,比如 Dashboards、Alerts,在笔者看来还非常初级,Dashboards 还是 Grafana 做得更好一些,Alerts 这块则是 Nightingale 做得更好一些。
权限这块,SigNoz 分为 Admin、Editor、Viewer 三种角色,分别对应不同的权限,比如 Viewer 就只能看,不能操作,Editor 则可以做日常操作,Admin 则是最高权限,可以做所有操作。这块没有看到数据权限的控制,比如告警规则,没有更多分组划分,比如云平台的告警规则我想单独分组,单独一拨人管理,电商业务的告警规则单独分组,单独一拨人管理,目前看 SigNoz 是做不到的。
5. 总结
本文对 SigNoz 做了初探,不深入,导致有些评价可能有所偏颇,仅供参考。整体来看,如果使用 SigNoz 做 Trace,是可以尝试的,如果做日志方案,还是 ELK 方案更成熟,不过 ElasticSearch 日志存储成本比较高,如果只是存近期数据用于排障,ElasticSearch 是很好的选择,如果想存很久的数据,SigNoz 用 ClickHouse 存储,成本会低很多。Metrics 方面,不建议使用 SigNoz,Metrics 的成熟方案太多了,比如 Prometheus、InfluxDB、VictoriaMetrics 等,SigNoz 这块还是太初级了。不管大家用什么监控系统,最终的告警降噪、值班OnCall还是希望在一个平台解决,这块笔者还是推荐 FlashDuty。
今天就到这里,感谢大家阅读,欢迎大家留言评论,如果有公司把 SigNoz 用起来了,也欢迎分享使用感受,一起学习,交流进步。
标签:Datadog,Trace,开源,SigNoz,日志,数据,ClickHouse From: https://www.cnblogs.com/ulricqin/p/17568861.html