Multiplexing
xv6 通过将 cpu 从一个进程切换到另一个进程来实现 multiplex(多路复用),进程的切换会在两种情形下发生:
- xv6 的 sleep 与 wakeup 机制在进程等待 IO 完成或者等待子进程退出又或者在
sleep系统调用中等待的时候切换进程。 - xv6 会周期性地强制切换进程,从而应对那些长时间切换而未
sleep的进程。
这个 multiplex 机制会让进程产生一种自己完全拥有 cpu 的错觉,就像 xv6 用虚拟内存和 page table 机制让进程觉得自己拥有完整的内存空间一样。
xv6 使用硬件定时器中断来保证 context switch(上下文切换)。
Code: Context switching
用户进程之间的切换步骤如下图所示:
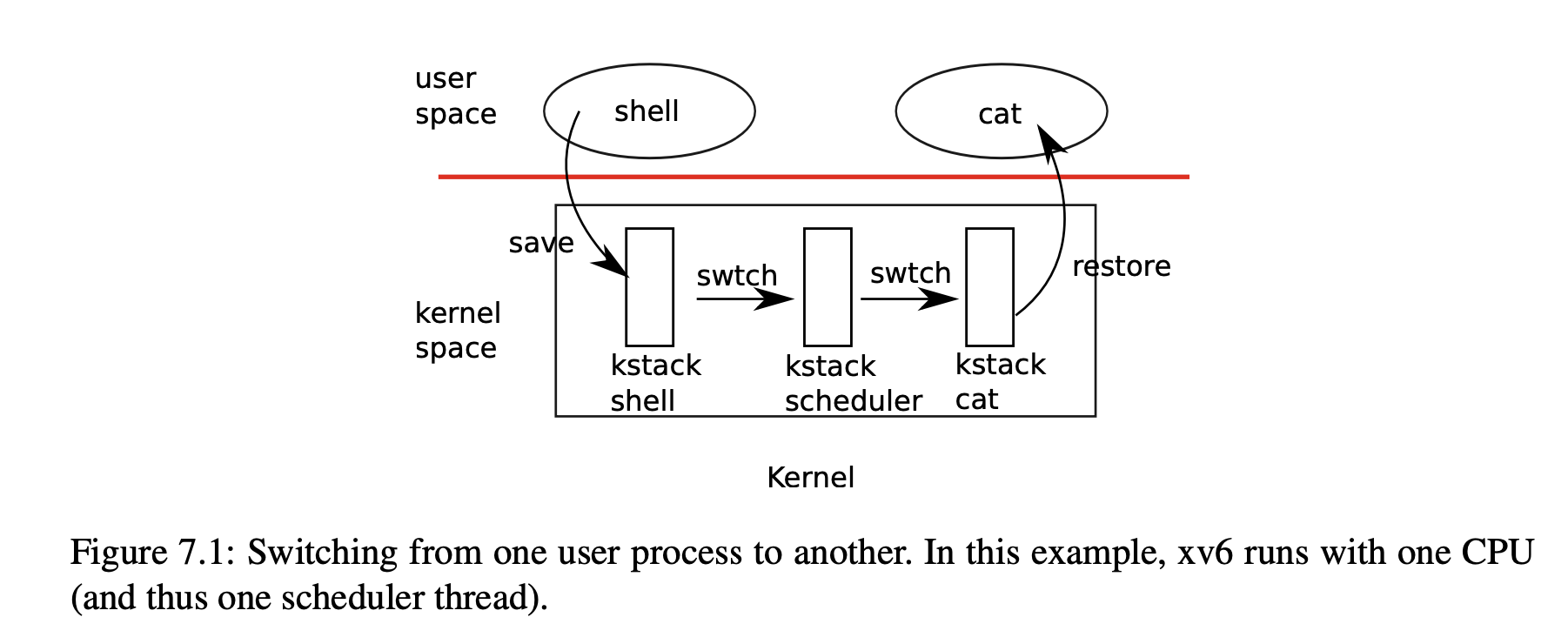
用户进程之间的切换其实会经过两次 context switch,以上图为例,第一次是从 shell 用户进程的 kernel thread 切换到 cpu 的 scheduler thread;第二次从 cpu 的 scheduler thread 切换到新用户进程(例如 cat)的 kernel thread。
在 xv6 中,我们可以认为每个用户进程,包含一个内核线程与一个用户线程,然后每个 cpu 包含一个 scheduler thread,schedular thread 工作在内核中,有只属于它的 kernel stack。
swtch 执行为内核线程切换的保存和恢复工作。swtch 的主要工作就是保存和恢复 riscv 的寄存器,又被称为上下文。
当一个进程要让出 cpu 时,该进程的内核线程会调用 swtch 来把该进程的 context 保存起来,并返回到 scheduler 线程的 context,每个 context 都包含于 strcut context。 context 结构体可能是 struct proc 的成员或者 struct cpu 的成员( scheduler 线程)。
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
swtch 函数实际上是利用汇编实现的,它接受两个参数 struct context *old 和 struct context *new,将当前寄存器保存在 old,中然后从 new 中加载内容到当前寄存器,然后 return。
用户进程要让出 cpu,切换到 scheduler 线程,会经历 usertrap => yield => sched => swtch 的过程,swtch 把当前进程的上下文保存在 p->context 中,从 cpu->context 加载当前 cpu 的 scheduler 线程的 context。
swtch 只会保存 callee-saved 寄存器(这里 sched 是 caller, swtch 是 callee)。swtch 不保存 pc,而是保存 ra 寄存器(ra 寄存器存放了 swtch 调用结束后应该返回到的地址,可以理解为 swtch 语句的下一条语句)。
scheduler 的 context 是在 scheduler 线程调用 swtch 的时候被保存在 cpu->context 的。
进程切换的流程可以这么理解,进程 a 调用 swtch,将进程 a 的 context 保存在 proca->context(包括进程 a 的 ra 寄存器),从 cpu->context 中加载 context,由于 context 中包含了 ra 寄存器,而 swtch 函数的最后一条指令就是 ret,因此会跳转到 ra 寄存器的地址处继续执行,这里应该就是执行 scheduler 函数中的 c->proc = 0,由于 scheduler 本身是个死循环,c->proc = 0 的下一个语句就是一个新的 for 循环,就又会执行到 swtch,将 scheduler 线程的 context 保存在 cpu->context 中,然后从 procb->context 中加载 context(包括进程 b 的 ra 寄存器),然后跳转到进程 b 的 ra 寄存器的地址处继续执行(这里类比进程 a,就是进程 b 调用的 swtch 语句的下一条语句),这里从结果来看,就是让进程 b 会从系统调用或者中断响应中退出,继续执行它的本职工作。
Code: Scheduling
scheduler 的实现如下:
void scheduler(void) {
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for (;;) {
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
我们可以发现,在调用 swtch 时,xv6 持有 &p->lock,但是这个锁,会在 scheduler 线程中被解锁
彼此之间有意识地通过线程传递 cpu 控制权的进程有时候也被称作协程(coroutines),sched 和 scheduler 就可以看作是彼此的协程。
标签:uint64,context,swtch,Thread,cpu,scheduler,进程,S081,MIT From: https://www.cnblogs.com/zwyyy456/p/17567672.htmlThere is one case when the scheduler’s call to swtch does not end up in sched. allocproc sets the context ra register of a new process to forkret (kernel/proc.c:508), so that its first swtch “returns” to the start of that function. Forkret exists to release the p->lock; otherwise, since the new process needs to return to user space as if returning from fork, it could instead start at usertrapret.