操作系统的进程调度算法
-
什么是进程调度
- Linux 是一个多任务操作系统,支持的任务同时运行的数量远远大于 CPU 的数量
- 进程调度 就是指【怎样安排】某一个时刻CPU运行【哪个进程】
-
进程调度类型
-
非抢占式调度 Nonpreemptive
- 一旦把处理机分配给某进程后,进程就会一直运行,直到该进程【完成】】或【阻塞】时才会把 CPU 让给其他进程
- 主要用于【批处理系统】 和 某些对【实时性要求不严】的实时系统
-
抢占式调度 Preemptive
- 暂停某个正在执行的进程,将已分配给该进程的处理机重新分配给另一个进程
- 系统同样是把处理机分配给优先权最高的进程,在其执行期间出现了另一个其优先权更高的进程
- 进程调度程序就停止当前进程的执行,重新将处理机分配给新到的优先级最高的进程
- 主要用于比较严格的【实时系统】中
-
-
算法分类
-
先来先服务调度算法(FCFS,first come first served,非抢占式)
- 按照作业/进程到达的先后顺序进行调度 ,即:优先考虑在系统中等待时间最长的作业
- 重点:排在长进程后的短进程的等待时间长,不利于短作业/进程,长进程得到CPU就执行完成了,不利于短进程
- 比如 进程一响应慢,进程二/三/四响应快,那进程一先到,其他本来很快搞定的但是没被调度到导致效率慢
-
短作业优先调度算法(SJF, Shortest Job First,非抢占式)
- 预计执行时间短的进程优先分派处理机,短进程/作业(要求服务时间最短)
- 在实际情况中占有很大比例,为了使得它们优先执行,对长作业不友好
- 重点:缩短进程的等待时间,提高系统的吞吐量
- 比如 进程一响应慢,进程二/三/四响应快,那同等时间下,更多短进程任务完成了,吞吐量也上去了
-
高响应比优先调度算法(HRRN,Highest Response Ratio Next,非抢占式)
- 在每次调度时,先计算各个作业的优先权:优先权=响应比=(等待时间+要求服务时间)/要求服务时间
- 因为等待时间与服务时间之和就是系统对该作业的响应时间,所以 优先权=响应比=响应时间/要求服务时间
- 选择优先权高的进行服务需要【计算优先权信息,增加了系统的开销】是介于FCFS和SJF之间的一种折中算法
-
时间片轮转调度算法(RR,Round-Robin,抢占式)
- FCFS 的方式按时间片轮流使用CPU 的调度方式,让每个进程在一定时间间隔内都可以得到响应
- 由于高频率的进程切换,会增加了开销,且不区分任务的紧急程度
-
优先级调度算法(**Priority cheduling ** ,有抢占式和非抢占式)
-
根据任务的紧急程度进行调度,高优先级的先处理,低优先级的慢处理
-
通常使用【动态优先级】,如果高优先级任务很多且持续产生,那低优先级的就可能很慢才被处理
- 优先级因素:进程的等待时间、已使用的处理机时间或其他资源的使用情况
-
分类
- 非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
-
-
多级反馈队列调度算法(Multilevel Feedback Queue,抢占式)
- 多级:表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短
- 高优先级队列中已没有调度的进程,则调度次优先级队列中的进程
- 对同个队列中的各个进程,按照时间片轮转法调度
- 比如
- Q1,Q2,Q3三个队列,在Q1中没有进程等待时才去调度Q2,只有Q1,Q2都为空时才会去调度Q3
- 队列的时间片为N,假如Q1中的作业经过N个时间片后还没有完成,则进入到Q2队列,以此类推
- 反馈:表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列
- 多级:表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短
-
总结
- 一个好的调度算法考虑以下几个方面
- 公平-保证每个进程得到合理的CPU时间
- 高效- 使CPU保持忙碌状态,总是有进程在CPU上运行
- 响应时间 -使交互用户的响应时间尽可能短
- 周转时间:使批处理用户等待输出的时间尽可能短
- 吞吐量-使单位时间内处理的进程数量尽可能多
- 不同系统和版本支持的调度算法不一样
- UNIX采用动态优先队列调度
- BSD采用多级反馈队列调度
- Windows采用抢先多任务调度
- 一个好的调度算法考虑以下几个方面
-
解决方案应用
- 内容爬取解析平台,区分大站点和小站点
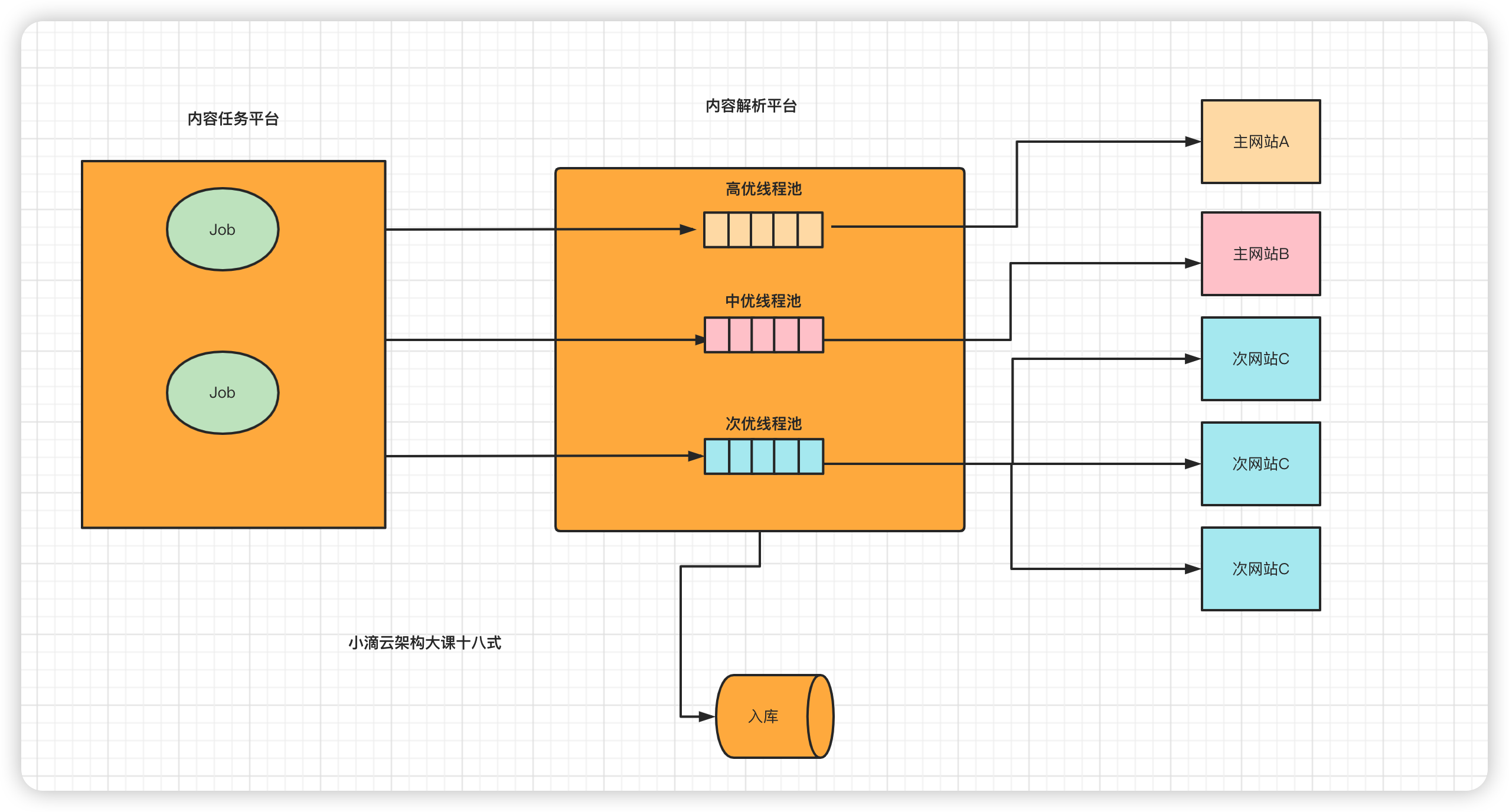
- 负载均衡算法:nginx / feign / dubbo...
深入理解CPU
CPU基础理论
内核态和用户态
-
什么是内核
- 是一组应用程序,这类程序能够控制所有硬件及计算机活动
- 内核抽象计算机内部硬件资源,并统一管理对外提供支持,内核操作 = 计算机硬件操作
- 是计算机资源的最大管理者,比如:CPU进程管理、内存管理、文件系统管理、网络接口管理等
-
什么是内核态和用户态
- 操作系统把进程的运行空间分为内存分两个区域
- 内核空间(kernel space) ,只有内核程序访问, 也叫进程内核态,可以直接访问内存、硬盘等资源
- 用户空间(user space),专门给应⽤程序使⽤,也叫进程用户态, 只能访问受限的用户资源,
- 其实就是CPU的两种工作状态:内核态和用户态,权限高和权限低
- 程序最终编译、解释成一条一条的 CPU 指令,然后指令都是 CPU 都在执行
-
那为啥要分 内核态和用户态?搞那么复杂,变态?
-
目标:提高操作系统的稳定性及可用性,确保和平稳定
-
在 CPU 的所有指令中,有些指令是非常危险的,如果错用将导致系统崩溃,比如申请-释放内存、杀进程等
-
如果所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加
-
CPU 将指令分为特权指令和非特权指令:
- 常规将CPU 将特权等级分为 4 个级别:Ring0~Ring3
- Linux 系统只使用了【 Ring0 和 Ring3 】
- 进程运行在 Ring3 级别时称为运行在用户态,CPU 可以执行部分指令
- 运行在 Ring0 级别时称为运行在内核态,CPU 可以执行任何指令
- Linux 系统只使用了【 Ring0 和 Ring3 】
- 常规将CPU 将特权等级分为 4 个级别:Ring0~Ring3
-
CPU处于空间什么态,实际上代表的是当前 CPU 正在执行什么级别的指令
-
-
比如
-
在古代,老王是一个国家安全负责人
- 和平年代:发号施令 军队做些简单的 事情,只有部分命令的权限
- 战火年代:发号施令 军队做些全部的 事情,没有约束,全部权限都有
-
-
什么时候会从用户态切换到内核态
- 用户态的程序需要向操作系统申请更高权限的操作时,就通过【系统调用】向内核发起请求
- 系统调过程中,会发生CPU的上下文切换,CPU 寄存器会先保存用户态的状态,然后加载内核态相关内容
- 系统调用结束之后,CPU 寄存器要恢复原来保存的用户态,继续运行进程
- 所以一次系统调用,发生两次 CPU 上下文切换
- 操作系统把进程的运行空间分为内存分两个区域
中断和上下文切换
-
什么是 操作系统的【中断】
-
类似java开发中的【监听器Listener】【发布-订阅】功能
-
介绍
- CPU在执行【当前程序】时系统出现了【某种信号】使得CPU必须停止当前程序,去执行【另一段程序】来处理的紧急事务
- 处理结束后CPU再返回到原先暂停的程序继续执行,这个过程就称为中断
-
分类
- 内部中断:指令执行时由CPU主动产生
- 外部中断:系统外部设备引发的程序中断
-
例子
- 1个CPU,系统里面有A、B、C任务处理,那CPU什么时候处理哪个任务?进程调度大家能想到
- 假如根据【基于时间片的优先级调度算法】时间到后,就发一个【信号】告诉CPU处理下个任务,信号就是【中断】
- 还有 系统需要接收网络数据、键盘输入、鼠标点击等,系统总不可能一直监听着
- 合理的解决办法:数据包来到之后通知CPU处理器,然后CPU再对任务做处理
-
-
Linux 是一个多任务操作系统
-
支持的任务同时运行的数量远远大于 CPU 的数量
-
CPU运行程序,每个任务运行之前,CPU 需要知道在哪里加载和启动任务
-
这些信息存储-依赖CPU 寄存器和程序计数器
-
寄存器是 CPU 里面空间小但速度极快的内存,程序计数器存储 CPU 正在执行的或下一条要执行指令的位置
-
好比:小滴课堂老王-同时有5个项目正在开发,轮流切换
-
-
什么是cpu的上下文切换
- cpu寄存器和程序计数器是cpu在运行任务前依赖的环境,也叫cpu上下文
- cpu的上下文切换先把前一个任务的cpu上下文保存起来【下次才知道任务从哪里加载+运行】
- 再加载新任务的上下文到寄存器和程序计数器进行运行任务,每次切换 在【保存和恢复】上下文耗时几十纳秒 或 微秒
- 1μs【微秒】 = 1000ns【纳秒】
-
cpu的上下文切换的场景
- 【系统调用切换】
- 即内核态和用户态的切换,一直是同一个进程在运行,不切换进程
- 一次系统调用的过程发生两次cpu上下文切换,切换过去,切换回来
- 【进程上下文切换】
- 每个cpu都维护了一个就绪队列,存放活跃进程,根据情况进行调度
- 进程是由内核来管理和调度的,进程的切换只能发生在【内核态】
- 比如你用【网易云听着歌、玩着英雄联盟】因为现在电脑多CPU多核心配置好,所以感觉不到切换
- 【线程上下文切换】
- 进程是资源拥有的基本单位,线程是调度的基本单位,当进程只有一个线程的时候,可以认为进程就等于线程
- 前后线程同属于一个进程,切换时虚拟内存资源不变
- 上下文切换时需要保存的是线程私有数据,比如栈和寄存器
- 同进程内的线程切换,要比多进程间的切换消耗更少的资源,所以开发中用多线程代替多进程的原因
- 【中断上下文切换】
- 快速响应硬件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件
- 打断其他进程时,就需要保存该进程状态,这样在设备事件结束后,就可以从原来的状态恢复
- 比如老王挪了下鼠标,按了下键盘,CPU就必须中断正在执行的程序,转而去响应这些硬件的事件
- 【系统调用切换】
平均负载与使用率
平均负载
- CPU平均负载
-
单位时间内 系统处于【可运行状态】和【不可中断状态】的平均进程数,就是平均活跃进程数,和 CPU 使用率并没有直接关系
- 可运行状态
- 正在使用 CPU 或者正在等待 CPU 的进程
- 用 ps aux命令看到的,处于 R 状态(Running 或 Runnable)的进程
- 不可中断状态
- 正处于内核态关键流程中的进程,且流程不可打断的,
- 比如 等待硬件设备的 I/O 响应,为了保证数据的一致性,进程向磁盘读写数据时,在得到磁盘响应前是不能被其他进程或者中断打断的
- ps aux命令中 D 状态 的进程 Uninterruptible Sleep
[root@iZwz90pegu9budx5tk4ruyZ ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 10933 0.0 0.0 0 0 ? S 11月17 0:05 [kworker/u8:2]
root 10976 0.0 0.0 157320 6028 ? Ss 17:44 0:00 sshd: root@pts/0
root 10988 0.0 0.0 115544 2048 pts/0 Ss+ 17:44 0:00 -bash
root 11303 0.2 0.0 157320 6024 ? Ds 17:46 0:00 sshd: root@pts/1
root 11347 0.0 0.0 155472 1872 pts/1 R+ 17:46 0:00 ps auxroot 21456 0.2 2.6 5574940 204168 ? Sl 9月03 300:57 java -jar -Dfile.encoding=UTF-8 agent.jar -s https://server-agent.g
root 27670 0.1 0.1 813512 10552 ? Ssl 11月03 31:11 /usr/local/share/aliyun-assist/2.2.3.349/aliyun-service
root 32475 0.0 0.0 0 0 ? R 11月20 0:03 [kworker/3:0] - 可运行状态
-
| PS中常见STAT状态 | 描述 |
|---|---|
| D | 无法中断的休眠状态(通常 IO 的进程) |
| R | 正在运行,或在队列中的进程 |
| S | 处于休眠状态 |
| T | 停止或被追踪; |
| Z | 僵尸进程 |
| < | 优先级高的进程 |
| n | 优先级较低的进程 |
| L | 有些页被锁进内存 |
| s | 进程的领导者(在它之下有子进程) |
| l | 多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads); |
| + | 位于后台的进程组 |
-
如何查看平均负载 uptime
- load average后的3个数字就分别代表着1分钟,5分钟,15分钟的CPU平均负载
- 查看服务器总的逻辑cpu个数【cat /proc/cpuinfo| grep "processor"| wc -l】
- 如果平均负载为2,那在2个CPU核数时则刚好利用,如果是4个CPU核数,则有50%的空闲
[root@iZwz90pegu9budx5tk4ruyZ ~]# uptime 17:49:46 up 80 days, 15:20, 1 user, load average: 0.00, 0.02, 0.05-
分析
-
1,5,15分钟的数值相差不大,说明负载很平稳
-
如果 1 分钟的值远小于 15 分钟的值,说明系统最近 1 分钟的负载在降低,而过去 15 分钟内却有很大的负载
-
如果 1 分钟的值远大于 15 分钟的值,最近 1 分钟的负载在增加,平均负载接近或超过了 CPU 的个数,意味着系统正在 发生过载的问题,持续的长时间则说明出现了问题需要优化
-
在一个单核CPU 系统平均负载为 1.80,0.90,5.48
- 在过去 1 分钟内,系统有 80% 的超载,而在 15 分钟内,有 448% 的超载,从整体趋势来看,系统的负载在降低
-
- load average后的3个数字就分别代表着1分钟,5分钟,15分钟的CPU平均负载
使用率
-
CPU使用率
-
CPU 非空闲态运行的时间占比,反映 CPU 的繁忙程度,和平均负载不一定完全一致
-
生产系统的 CPU 总使用率不要超过 70~80%
-
比如
- 单核 CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%
- 双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,总体 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%
-
Linux的 top 命令查看 CPU 使用率(核心指标,不常用的忽略)
-
us(user): CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙,值高则cpu使用率高
-
sy(sys):CPU 在内核态运行的时间百分比(不包括中断),内核态 CPU 越低越不忙,值高则cpu使用率高
-
id(idle):CPU 处于空闲态的时间占比,CPU 会执行一个特定的虚拟进程,名为 System Idle Process
- 值高的话,则说明CPU比较空闲,
-
wa(iowait)
- CPU 在等待 I/O 操作完成所消耗的时间,该指标越低越好,高表示可能 I/O 存在瓶颈,用 iostat 命令进一步分析
-
hi(hardirq):CPU 处理硬中断所花费的时间,由外设硬件(如键盘控制器、硬件传感器等)发出的中断信号,快速执行
-
si(softirq): CPU 处理软中断所花费的时间,由软件程序(如网络收发、定时调度等)发出的中断信号,延迟执行
-
st(steal): CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景,指标过高的话,检查下宿主机或其他虚拟机是否异常
top - 18:12:32 up 80 days, 15:43, 3 users, load average: 0.02, 0.07, 0.06 Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie ———————————————————————————————————————————————————————————————————————————————— %Cpu(s): 0.5 us, 0.3 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ———————————————————————————————————————————————————————————————————————————————— KiB Mem : 7733012 total, 192788 free, 1142076 used, 6398148 buff/cache KiB Swap: 0 total, 0 free, 0 used. 6284820 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12303 root 10 -10 140108 14068 6716 S 1.7 0.2 1917:38 AliYunDun 1561 root 20 0 5573112 211120 6888 S 0.7 2.7 287:39.33 java 10518 root 20 0 20.4g 124080 23984 S 0.7 1.6 37:57.16 node /app/.outp 2329 root 20 0 1954676 41920 10204 S 0.3 0.5 217:56.93 dockerd-current 10463 root 20 0 326888 50712 21144 S 0.3 0.7 23:02.56 node -
-
-
CPU使用率和平均负载区别
-
【CPU平均负载】指单位时间内活跃进程数,包括正在使用 CPU 的进程,还包括等待 CPU和 等待 I/O 的进程
- 【可运行状态】和【不可中断状态】的平均进程数
-
【CPU使用率】是单位时间内CPU繁忙情况的统计
-
区别说明
-
CPU 密集型进程,使用大量 CPU运算 会导致平均负载升高,这个场景这两者是一致的;
-
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
- CPU 的效率要远高于磁盘,磁盘读写请求过多就会导致大量 I/O 等待
- 进程在 CPU 上访问磁盘文件,CPU 会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候CPU会切换到其他进程或者空闲
- 任务会转换为 不可中断睡眠状态,当这种读写请求过多会导致不可中断睡眠状态的进程过多,导致CPU负载高,利用率低的情况
-
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
-
-
拓展
- CPU密集型应用也叫计算密集型,表示该任务需要大量的运算,没有阻塞CPU一直全速运行
- 对视频进行高清解码、机器学习和深度学习的模型训练等
- IO密集型应用 程序需要大量I/O操作,大部分的时间是CPU在等IO (硬盘/内存) 的读写操作
- CPU使用率低,但等待IO 也会导致平均负载升高
- 例如:数据库交互,文件上传下载,网络数据传输
- 当线程进行 I/O 操作 CPU 空闲时,启用其他线程继续使用 CPU,提高 CPU 的使用率
- 老王没干太多活,时间光在5个项目中来回启动切换,导致老王【压力大】但是对公司来说【利用率低】没产出
- CPU密集型应用也叫计算密集型,表示该任务需要大量的运算,没有阻塞CPU一直全速运行
-
性能诊断 命令与案例
【全局命令】mpstat
- 全称 Multiprocessor Statistics,多核 CPU 性能分析程序,实时查看每个 CPU 的性能指标和全部 CPU 的平均性能指标
- 场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 格式
mpstat [-P {|ALL}] [ <时间间隔> ] [ <次数> ]比如mpstat -P ALL 2 3每隔2秒出一个报告数据,共出具3次 - 参数说明
| 参数 | 说明 |
|---|---|
| -P | 指定监控哪个CPU,范围是[ 0 ~ (N-1)], ALL表示监控所有CPU都监控 |
| internal | 两次采样的间隔时间 |
| count | 总采样次数 |
- 显示信息(参数很多,只关注重点,不要想一口吃掉全部)
| 字段 | 说明 |
|---|---|
| CPU | 全部CPU 和 某个CPU,从0开始。 下面每一行项加起来就是100% |
| %usr-- | 用户态所使用 CPU时间的百分比,CPU使用率 |
| %nice | nice值为负进程的CPU时间,即使用 nice 命令对进程进行降级时 CPU 的百分比 |
| %sys-- | 内核态所使用 CPU时间的百分比,CPU使用率 |
| %iowait-- | CPU 在等待 I/O 操作完成所消耗的时间,高表示可能 I/O 存在瓶颈 |
| %irq | 用于硬中断的 CPU 百分比 |
| %soft | 用于软中断的 CPU 百分比 |
| %steal | 虚拟机强制CPU 等待的时间百分比(基本很少关注) |
| %guest | 虚拟机占用CPU时间的百分比(基本很少关注) |
| %gnice | CPU运行niced guest虚拟机所花费的时间百分比(基本很少关注) |
| %idle-- | CPU空闲且系统没有未完成的磁盘I/O请求的时间百分比; CPU使用率低,iowait高,idle低的话可能是等待IO |
【全局命令】vmstat
-
全称是 Virtual Meomory Statistics(虚拟内存统计)的缩写,是对系统整体的情况进行统计,不细化到某个进程,是宏观命令
-
格式:
vmstat [选项] [时间间隔[次数]](参数很多,记住常用的即可)vmstat n每隔n秒后输出一行信息, 一般会加个 -w 进行加宽显示,比如vmstat -w 1vmstat -SM指定单位显示,默认KB,M表示是MBvmstat -t带上时间戳信息- 更多参数信息
vmstat -h或man vmstat
-
实时查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等
- 和mpstat命令有交集,都是可以看出cpu使用率,在内核态、用户态等
#用户态占比高 stress --cpu 8 --timeout 600s #内核态占比高 stress --io 8 --timeout 600s- Linux里面很多分析工具都是有交集的,但主要用途有差别
-
上下文切换和中断的合理范围:没啥CPU负载的时候也有每秒1万次内,不过也取决cpu的性能,
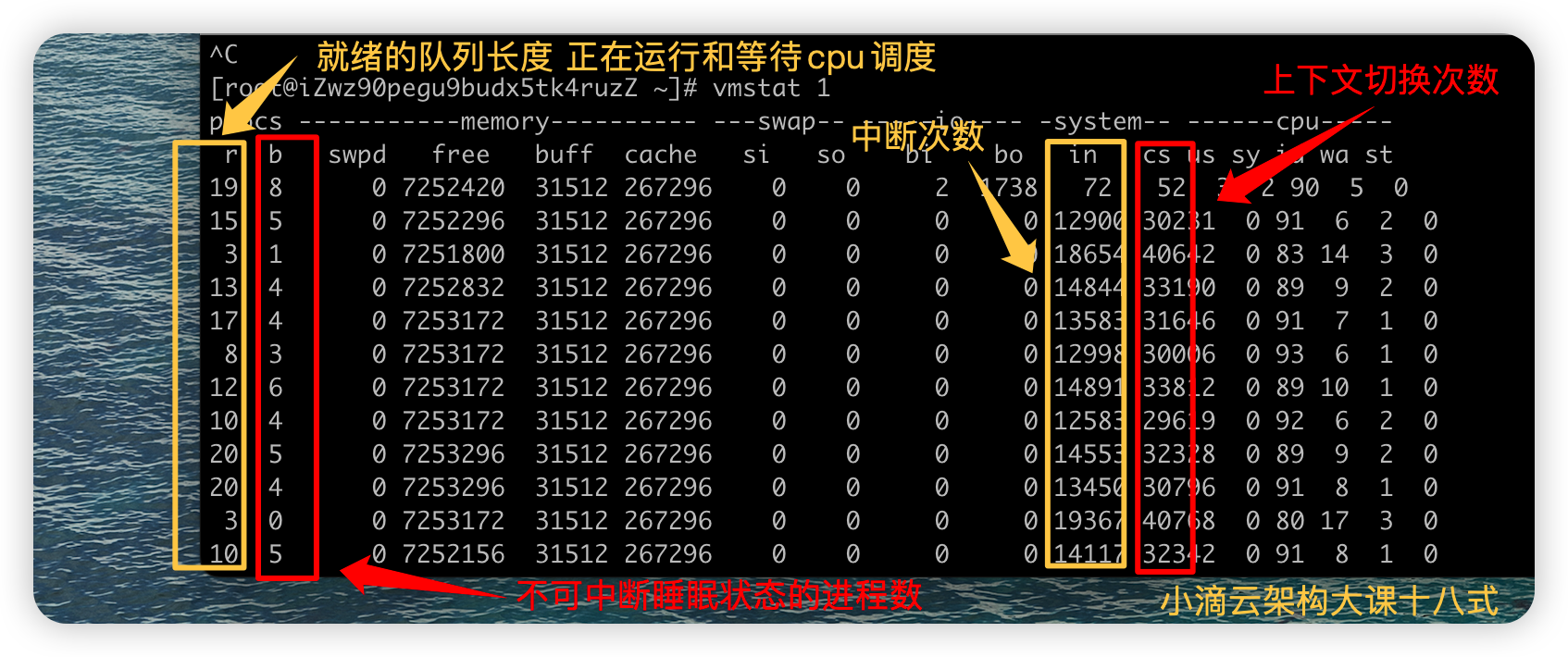
| 字段 | 说明 |
|---|---|
| r | r (runnning or runnable)就绪队列的长度,包括 正在运行和等待CPU的进程数 |
| b | b (Blocked) 处于不可中断睡眠状态的进程数,stress --io 或者 --hdd 即可产生 |
| swpd | 虚拟内存使用情况,单位KB |
| free | 空闲内存空间,单位KB |
| buff | 缓冲的内存空间 ,单位KB |
| cache | 缓存的内存空间,单位KB |
| si | 从磁盘中交换至内存的数据量,单位KB,数值越大代表内存和磁盘之间的转换越频繁,系统的性能越差 |
| so | 从内存中交换到磁盘中的数据量,单位KB,数值越大代表内存和磁盘之间的转换越频繁,系统的性能越差 |
| bi | 从块设备中读入的数据的总量,单位是块,值越大代表系统的 I/O 越繁忙 |
| bo | 写到块设备的数据的总量,单位是块,值越大代表系统的 I/O 越繁忙 |
| in | (interrupt) 每秒中断的次数 |
| cs | (context switch) 每秒上下文切换次数, 会浪费较多的cpu资源 比如我们调用系统函数,数值应该越小越好 |
| us | 在用户态进程所使用 CPU时间的百分比,CPU使用率 |
| sy | 在内核态进程所使用 CPU时间的百分比,CPU使用率 |
| id | 空闲 CPU 的百分比,在Linux 2.5.41之前,这部分包含IO等待时间 |
| wa | 等待 I/O 的 CPU 时间百分比 |
| st | 被虚拟机所盗用的 CPU 百分比(基本很少用) |
【局部命令】pidstat
- 实时查看进程的 CPU、内存、I/O 、上下文切换等指标
- 格式
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]比如pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次 - 输出排序 pidstat -u | sort -k 8 -r
- sort 排序
- 指定排序用哪一列,下面的例子中是第8列:%CPU
- -r : 倒序
- 参数说明
| 参数 | 说明 |
|---|---|
| -u | 默认的参数,显示各个进程的cpu使用统计,监控cpu,pidstat 和 pidstat -u -p ALL 是等效的 |
| -r | 显示各个进程的内存使用统计,监控内存 |
| -d | 显示各个进程的IO使用情况,监控硬盘 |
| -p | 指定进程号,比如 pidstat -p 5 |
| -w | 显示每个进程的上下文切换情况 |
| -t | 显示选择任务的线程的统计信息外的额外信息 |
- 默认显示信息
| 字段 | 说明 |
|---|---|
| PID | 进程ID |
| %usr | 进程在用户态所使用 CPU时间的百分比,CPU使用率 |
| %system | 进程在内核态所使用 CPU时间的百分比,CPU使用率 |
| %guest | 进程在虚拟机占用cpu的百分比(基本很少关注) |
| %wait | 进程等待cpu 的时间百分比, 进程处于就绪队列中的状态等待CPU调度运行的百分比【新版才有】 |
| %CPU | 进程占用cpu的百分比,和top命令一样 等于 用户态CPU+内核态 CPU,如果要区分cpu哪个态多则用pidstat,不包括 %wait |
| CPU | 处理进程的cpu编号 |
| Command | 当前进程对应的命令 |
【压测工具】 stress
- 多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测
- 参数说明
| 参数 | 说明 |
|---|---|
| --timeout | 指定运行多少秒 |
| --cpu N | 产生多个处理sqrt()函数的CPU进程,每个进程高频的计算随机数的平方根,模拟 CPU 计算密集型场景 |
| --io N | 产生多个处理sync()函数的磁盘I/O进程,每个进程高频调用 sync(),刷内存缓冲区到磁盘,模拟 I/O 密集型场景 |
| -vm N | 每个进程高频调用内存分配 malloc() 和 内存释放 free() 函数 |
| --vm-bytes | 指定 malloc() 时申请内存的字节数,默认256MB |
| --hdd N | 产生N个高频执行write和unlink函数的进程 (创建/写入/删除 文件) , 属于磁盘IO进程 |
| --hdd-bytes | 每个 hdd worker进程写的byte数,默认1G |
-
pidstat 查看进程IO使用情况,显示各活动进程的IO使用统计
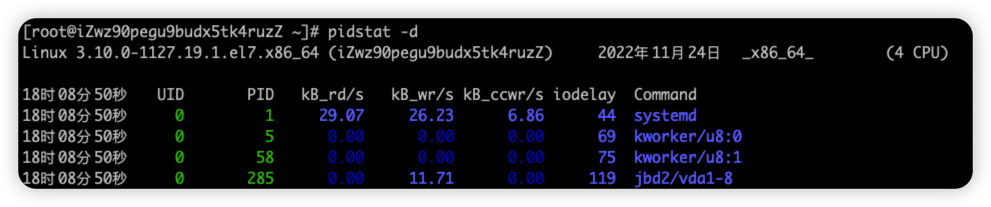
字段 说明 PID 进程ID kB_rd/s 每秒从磁盘读取的KB kB_wr/s 每秒写入磁盘KB kB_ccwr/s 每秒进程被取消向磁盘写的数据量(以kB为单位) iodelay 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间 Command 当前进程对应的命令
【压测工具】 sysbench
-
是一款开源的多线程性能测试工具,模拟线程上下文切换过多场景等
-
可以执行CPU/内存/线程/IO/数据库等方面的性能测试
-
常用命令
sysbench --threads=32 --time=300 threads run32 个线程持续运行 5 分钟,多线程压测
模拟CPU密集型应用
-
需求一 :模拟CPU密集型应用,系统是4核
- 终端一 模拟两个 CPU核的使用率 100%,对2个cpu 进行压力测试 持续600s
stress --cpu 2 --timeout 600 - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 5 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 5
- 终端一 模拟两个 CPU核的使用率 100%,对2个cpu 进行压力测试 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是2,高负荷可以到4
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- CPU的两个核在用户态使用率是100%,两个核数空闲的,总的CPU使用率是50%,% iowait 为0,不存在io瓶颈
- sqrt()函数的 CPU进程是在用户态,所以是%usr升高,而%sys没啥变化
-
局部
-
pidstat: 对进程和任务的使用情况进行,发现stress进程对2块cpu使用率过高,导致CPU平均负载增加
-
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程,包括压测4个核
-
CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高
-
-
模拟CPU密集型应用
-
需求二:模拟CPU密集型应用,系统是4核
- 终端一 模拟四个IO进程, 持续600s
stress --io 4 --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 5 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 5
- 终端一 模拟四个IO进程, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
- 全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,内核态CPU使用率%sys 比较高,iowait也有一定数值
- 局部
- pidstat: 对进程和任务的使用情况进行,发现stress进程对cpu使用率比较高,导致CPU平均负载增加
- %wait有一定数值,但是不高,使用
pidstat -d查看 没太多磁盘读写,但是有iodelay
- 全局
模拟IO密集型应用
-
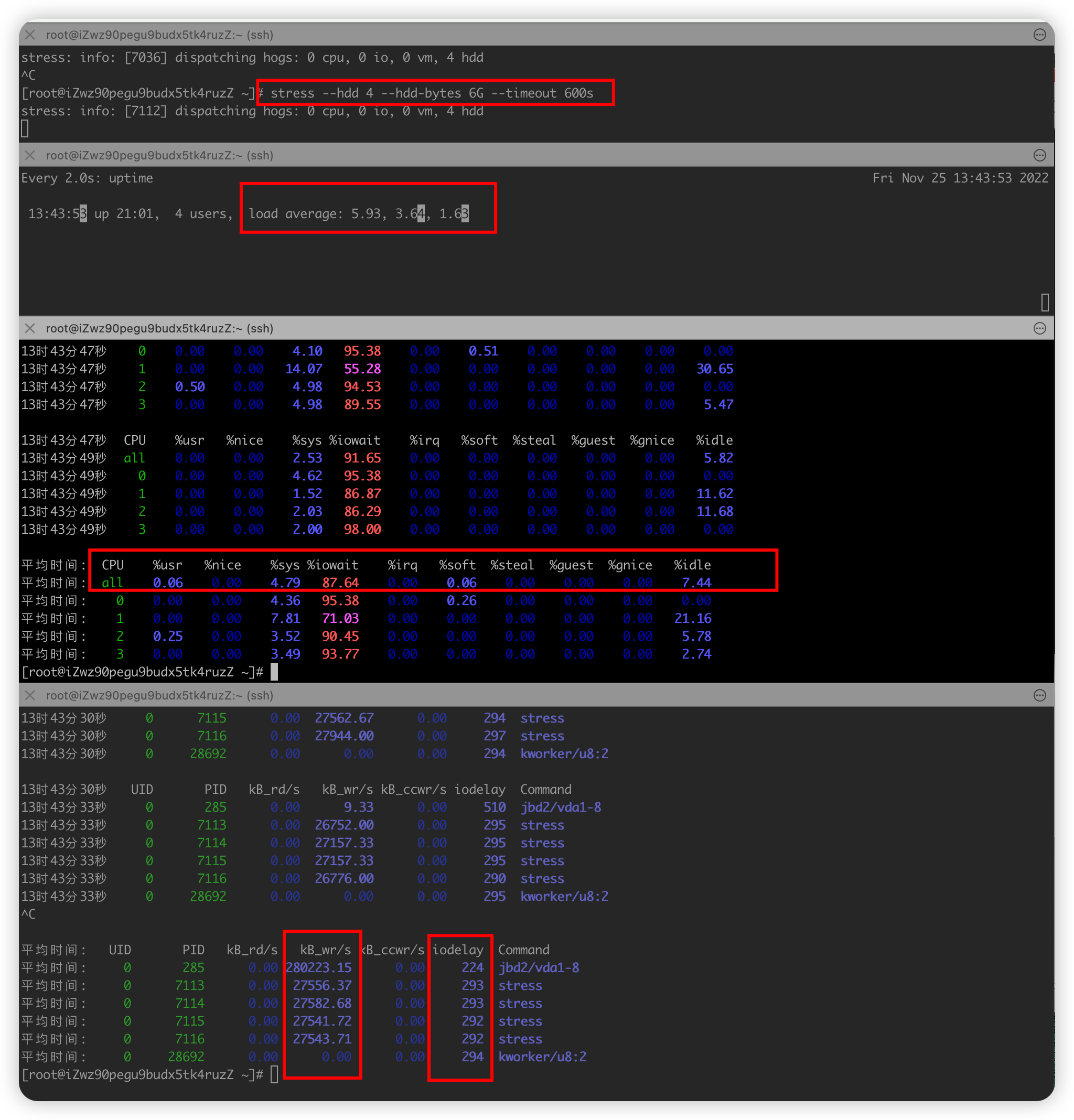
需求三 :模拟IO密集型应用,系统是4核
- 终端一 模拟两个磁盘IO进程, 持续600s
stress --hdd 2 --hdd-bytes 6G --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 2 3每隔2秒出一个报告数据,一共出具3次 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次
- 终端一 模拟两个磁盘IO进程, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,但是CPU使用率没啥变化,iowait大于50%值比较高
- 一直在等待IO处理,说明进程是IO密集型,进程频繁进行IO操作,导致系统平均负载很高,而CPU使用率不高
-
局部
- ps aux 里面stat字段D的状态一般是I/O出现了问题,说明进程在等待I/O,比如 磁盘I/O,网络I/O或者其他
- pidstat : 对进程和任务的使用情况进行,发现stress进程对cpu使用率不高,但CPU平均负载高
- pidstat -u
- pidstat -d
- 举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
- CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高,则可能IO瓶颈
-
模拟多进程调度应用
-
前言
-
CPU密集型进程,使用大量CPU会导致平均负载高,此时cpu使用率也高
-
I/O密集型进程, 等待I/O导致负载升高,但CPU使用率不一定高
-
大量进程等待CPU调度也会导致平均负载升高,CPU使用率也会比较高
-
-
需求四 :大量等待CPU的进程调度 导致平均负载升高,CPU使用率也会比较高,系统是4核
- 终端一 模拟8个进程,也可以更多, 持续600s
stress --cpu 8 --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 2 3每隔2秒出一个报告数据,一共出具3次 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次
- 终端一 模拟8个进程,也可以更多, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
- 再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU
-
局部
- pidstat : 对进程和任务的使用情况进行,发现%wait高,说明cpu不够用在等待cpu调度上花费了不少时间
- 结论:8个进程在竞争4个cpu,每个进程等待cpu的时间达到50%(%wait),超出cpu计算能力的进程,导致了负载变高
- pidstat -u CPU情况,默认
- pidstat -d 磁盘IO情况 , 基本很低
- 举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
-
模拟CPU上下文切换应用
-
需求五 :大量线程进行上下文切换,导致平均负载升高,CPU使用率也会比较高,系统是4核
- 终端一 模拟32个线程进行压测, 持续300s
sysbench --threads=32 --time=300 threads run - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三
vmstat -w 1查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等- 和mpstat命令有交集,都是可以看出cpu使用率,在内核态、用户态等
- 终端四
pidstat -w查看运行中的进程和任务上下文切换情况统计,显示各活动进程的上下文切换情况统计pidstat -t -p pid显示进程里面的线程的统计信息pidstat -wt 1组合命令,查看进程里面具体线程的上下文切换情况
- 终端一 模拟32个线程进行压测, 持续300s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
-
uptime(全局) :运行1分钟后,4个核的CPU负载是比较高
-
mpstat(全局) :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用
mpstat -P ALL 2 2,持续观察, 每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
- 再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU
-
vmstat (全局) :系统总的上下文切换情况,就绪队列里面的线程数,不可中断睡眠状态的进程数等
vmstat -wt 1发现:上下文切换次数和中断次数数值比较高
-
-
局部
- pidstat -u 2 2: 对进程和任务的使用情况进行,发现CPU使用率接近100%,前面知道是大量上下文切换导致
-
pidstat -wt 2 2查看哪个进程大量占据上下文切换,到进程里面的具体线程,大量上下文切换,导致了负载变高-
pidstat -u CPU情况
-
pidstat -d 磁盘IO情况
-
pidstat -t 显示进程里面的线程的统计信息
-
pidstat -w 进程上下文切换情况,查看是哪种上下文切换占比高
- 如果没加 -t则是进程上下文切换,和vmstat的数据不一样,所以推断出是进程内部的大量线程切换导致
- 加 -t 发现 nvcswch 高,大量线程抢夺CPU资源导致
平均时间: UID PID cswch/s nvcswch/s Command 平均时间: 0 9 25.44 0.00 rcu_sched 平均时间: 0 30139 0.00 64.84 stress 平均时间: 0 30140 0.00 65.09 stress 平均时间: 0 30153 0.50 0.00 pidstat- cswch/s 每秒自愿上下文切换(voluntary context switches)的次数
- 进程获取不了所需要的资源导致的上下文切换
- 比如 出现 I/O问题瓶颈、内存等系统资源不足,会发生自愿上下文切换
- nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数
- 进程由于调度算法,时间片已到等原因,被系统【强制调度】发生上下文切换
- 比如 大量进程再抢夺CPU资源时,会发生非自愿上下文切换,CPU出现了瓶颈
-
-
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
-
深入理解内存
深入理解磁盘和IO
深入理解计算机网络
其他
如何使用管道符连接命令?
在Linux或Unix系统中,管道符(|)被用来将一个命令的输出作为另一个命令的输入,从而实现命令之间的连接,形成一个管道。
下面是一个简单的例子:
ls -l | grep ".txt"
在这个例子中,ls -l命令被用来列出当前目录下的所有文件和目录,其结果被传递到grep ".txt"命令,后者会从中筛选出包含".txt"的行。
这样,你就可以将多个命令连接起来,形成一个复杂的命令。例如:
ps aux | grep "python" | wc -l
在这个例子中:
ps aux命令被用来列出所有的进程;grep "python"命令从中筛选出包含"python"的行;wc -l命令计算这些行的数量。
因此,整个命令的结果就是正在运行的包含"python"的进程的数量。
总的来说,管道符(|)是一个非常强大的工具,可以帮助你连接各种命令,实现复杂的功能。使用时,你只需要将一个命令的输出通过管道符传递给另一个命令即可。
标签:负载,操作系统,CPU,IO,进程,使用率,cpu From: https://www.cnblogs.com/youngleesin/p/17558057.html