原文:https://itnext.io/keda-kubernetes-based-event-driven-autoscaling-48491c79ec74
Event-driven computing is hardly a new idea; people in the database world have used database triggers for years. The concept is simple: whenever you add, change, or delete data, an event is triggered to perform a variety of functions. What’s new is the proliferation of these types of events and triggers among applications in other areas like Auto scaling, Auto-remediation, Capacity Planning etc. At its core, event-driven architecture is about reacting to various events on your systems and acting accordingly.
Autoscaling (in one or other way a kind of automation) has become an integral component in almost all the cloud platforms, microservices aka containers are not an exemption. In-fact containers known for flexible and decoupled design can best fit in for auto-scaling as they are much easier to create than virtual machines.
Why Autoscaling????
Scalability is one of the most important aspects to consider for modern container based application deployments. With the advancement of container orchestration platforms, it has never been easier to design solutions for scalability. Kubernetes-based event-driven autoscaling, or KEDA (built with Operator Framework), as the tool is called, allows users to build their own event-driven applications on top of Kubernetes. KEDA handles the triggers to respond to events that happen in other services and scales workloads as needed. KEDA enables a container to consume events directly from the source, instead of routing through HTTP.
KEDA works in any public or private cloud and on-premises, including Azure Kubernetes Service and Red Hat’s OpenShift. With this, developers can also now take Azure Functions, Microsoft’s serverless platform, and deploy it as a container in Kubernetes clusters, including on OpenShift.
This might look simple but assume a busy day with massive transactions and will it be really possible to manage the number of applications (Kubernetes Deployments) manually as shown below???
KEDA will automatically detect new deployments and start monitoring event sources, leveraging real-time metrics to drive scaling decisions.
KEDA
KEDA as a component on Kubernetes provides two key roles:
- Scaling Agent: Agent to activate and deactivate a deployment to scale to configured replicas and scale back replicas to zero on no events.
- Kubernetes Metrics Server: A metrics server exposing multitude of event related data like queue length or stream lag which allows event based scaling consuming specific type of event data.
Kubernetes Metrics Server communicates with Kubernetes HPA (horizontal pod autoscaler) to drive the scale out of Kubernetes deployment replicas. It is up to the deployment to then consume the events directly from the source. This preserves rich event integration and enables gestures like completing or abandoning queue messages to work out of the box.
Scaler
KEDA uses a “Scaler” to detect if a deployment should be activated or deactivated (scaling) which in-turn is fed into a specific event source. Today supports multiple “Scalers” with specific supported triggers like Kafka (trigger: Kafka Topics), RabbitMQ (trigger: RabbitMQ Queues) and have many more to come.
Apart from these KEDA integrates with Azure Functions tooling natively extending Azure specific scalers like Azure Storage Queues, Azure Service Bus Queues, Azure Service Bus Topics.
ScaledObject
ScaledObject is deployed as a Kubernetes CRD (Custom Resource Definition) which brings the functionality of syncing a deployment with an event source.
Once deployed as CRD the ScaledObject can take configuration as below:
As mentioned above different triggers are supported and some of the examples are shown below:
Event Driven Autoscaling in Action — On-Premises Kubernetes Cluster
KEDA as Deployment on Kubernetes
RabbitMQ Queues Scaler with KEDA
RabbitMQ is a message-queueing software called a message broker or queue manager. Simply said; It is a software where queues can be defined, applications may connect to the queue and transfer a message onto it.
In the example below a RabbitMQ Server/Publisher is deployed as a ‘statefulset’ on Kubernetes:
A RabbitMQ consumer is deployed as a deployment which accepts queues generated by the RabbitMQ server and simulates performing.
Creating ScaledObject with RabbitMQ Triggers
Along with the deployment above, a ScaledObject configuration is provided which will be translated by the KEDA CRD created above with installation of KEDA on Kubernetes.
Once the ScaledObject is created, the KEDA controller automatically syncs the configuration and starts watching the rabbitmq-consumer created above. KEDA seamlessly creates a HPA (Horizontal Pod Autoscaler) object with required configuration and scales out the replicas based on the trigger-rule provided through ScaledObject (in this case it is queue length of ‘5’). As there are no queues yet the rabbitmq-consumer deployment replicas are set to zero as shown below.
With the ScaledObject and HPA configuration above KEDA will drive the container to scale out according to the information received from event source. Publishing some queues with ‘Kubernetes-Job’ configuration below which produces 10 queues:
KEDA automatically scales the ‘rabbitmq-consumer’ currently set to ‘zero’ replicas to ‘two’ replicas to cater the queues.
Publishing 10 queues — RabbitMQ Consumer scaled to two replicas:
Publishing 200 queues — RabbitMQ Consumer scaled to forty (40) replicas:
Publishing 1000 queues — RabbitMQ Consumer scaled to 100 replicas as maximum replicas set to 100:
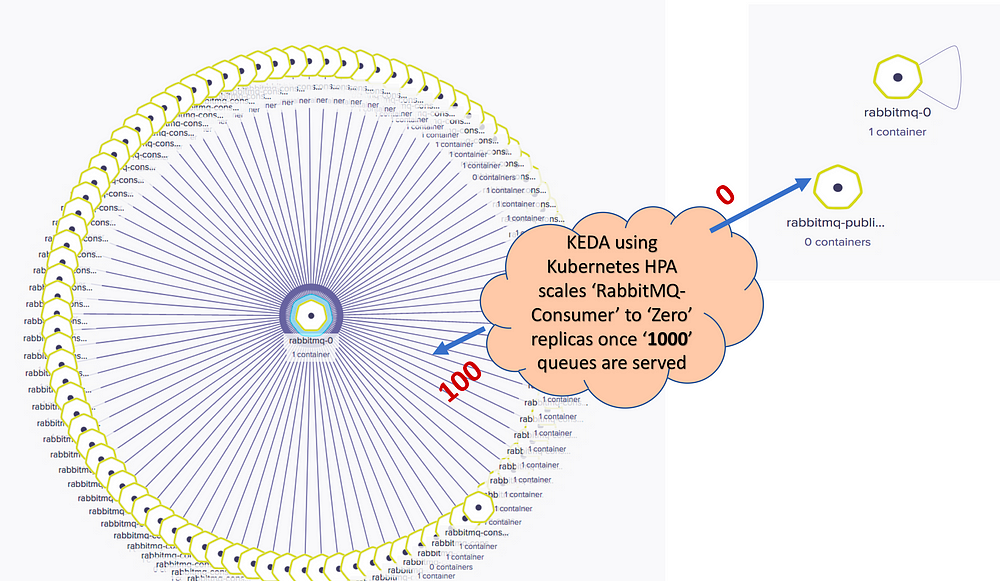 Scale to : 100 — Scale down: 0
Scale to : 100 — Scale down: 0
KEDA provides a FaaS-like model of event-aware scaling, where Kubernetes deployments can dynamically scale to and from zero based on demand and based on intelligence without loosing the data and context. KEDA also presents a new hosting option for Azure Functions that can be deployed as a container in Kubernetes clusters, bringing the Azure Functions programming model and scale controller to any Kubernetes implementation, both in the cloud or on-premises.
KEDA also brings more event sources to Kubernetes. KEDA has a great potential to become a necessity in production grade Kubernetes deployments as more triggers continue to be added in the future or providing framework for application developers to design triggers based on the nature of the application making autoscaling as an embedded component in application development.
标签:Based,Kubernetes,queues,RabbitMQ,event,scaling,ScaledObject,KEDA From: https://www.cnblogs.com/panpanwelcome/p/17516719.html