问题一
Q:统计一个主机群组里,值为A的某个监控项的个数,函数应该怎么写?
A:参考:
https://www.zabbix.com/documentation/6.0/zh/manual/config/items/itemtypes/calculated/aggregate。

Q:文档示例没有类似的,可以写个范例吗?
A:count函数只能针对单一主机,count_foreach聚合函数只能统计监控项名称及主机/主机群组匹配的,采集值的个数;所以要做这种统计只能是调zbx的api获取到取值列表后,在api调用脚本里进行统计了。
问题二
Q:怎么监控交换机端口down,up状态并且告警啊,这个怎么设置啊?
A:交换机直接套用内置的网络设备模板就会监控端口状态且内置up/down的触发器的。
问题三
Q:大佬们为啥我的Ballooned memory老是监控不到数据?

A:在vCenter中,虚拟机的Balloon内存是一种机制,旨在通过回收未使用的虚拟机内存来释放物理主机上不再需要的内存。 Ballooning利用安装在虚拟机中的VMware工具(VMTools),并使用该工具在虚拟机中运行一个服务,该服务通过透明地从虚拟机内存中删除页面来回收空闲内存。如果虚拟机內存减少意外,balloon也会释放虚拟机持有的内存页。
Balloon技术可有效帮助管理员更好地管理资源,在虚拟机与物理主机之间优化内存的分配和使用。若您想取消Balloon技術,可以选择禁用VMTools中的这个组件。
问题四
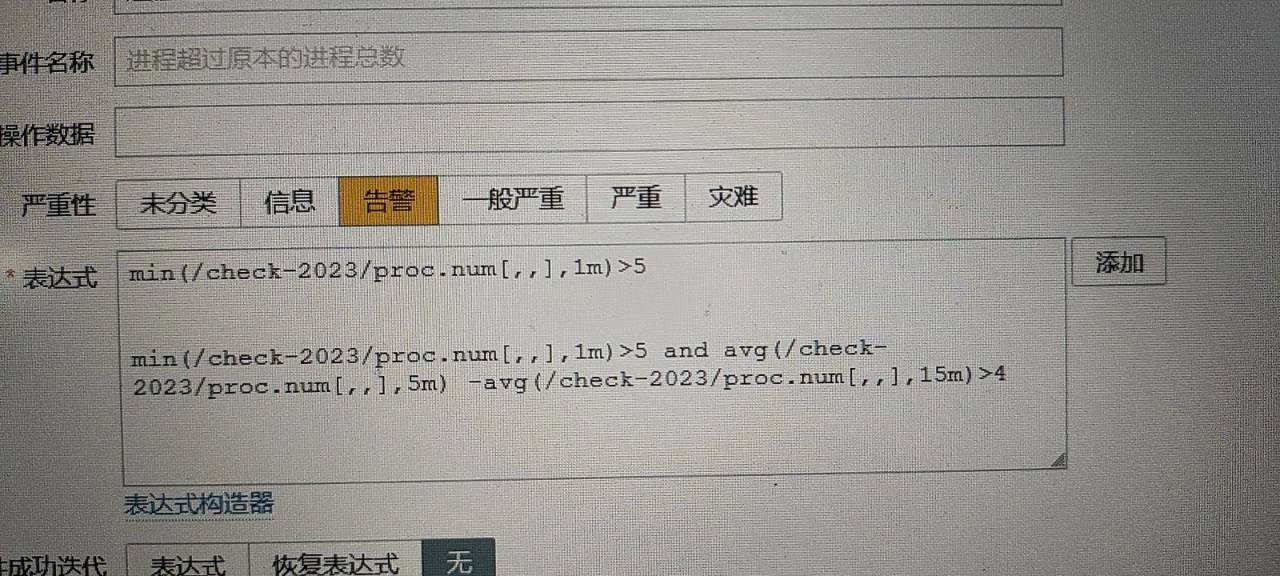
Q:进程数触发器怎么弄呀?进程数大于本身的百分之五就告警,测试了没效果。
A:看下你的触发器表达式怎么写的?
Q:这两种都试过,没效果。

A:是不是已经触发过了,迭代这里如果是“无”的时候,告警是不会自动恢复的,也就不会重新触发了。
问题五
Q:Zabbix6.2.7怎么在页面批量更改模板?
A:主机管理,勾选需要调整的主机,下方“批量修改”按钮,然后“替换”链接模板。
问题六
Q:出现这个问题如何解决?我是按照这个方法进行尝试的,https://blog.csdn.net/qq_39626154/article/details/125679840,但是问题依旧。

A:mysql的数据库是么?建议对zabbix库做存储过程,表分区的操作。可参考文章优化表分区,取代zabbix管家的清理操作。https://blog.csdn.net/weixin_42123737/article/details/93736065。
问题七
Q:服务端server版本5.0.3,客户端:zabbix版本6.2.9系统windows server2012

{kind=link}

目前还是一直报告警,日志报这个,怎么处理?

A:agent版本不要大过server的版本,agent版本可以用5.0版本的小版本高于server的,但是如果使用5.2或者更高版本的时候,会出现这些奇怪问题(包括采集失败)。
问题八
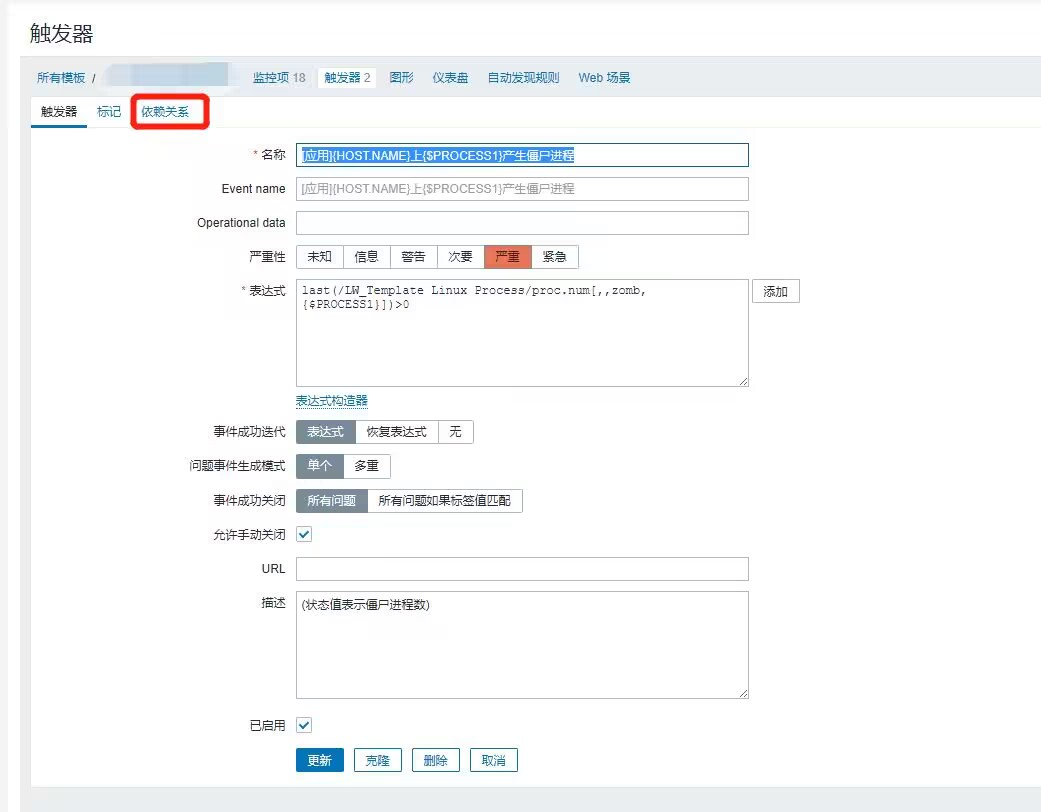
Q:监控项依赖项是什么意思?怎么配置的?
如果有多个触发器,A:CPU大于80%告警,B:CPU大于90%告警,那如果CPU是瞬时增长到90+的,就会两个触发器同时触发,为了避免这种情况,需要配置触发器A依赖于触发器B,当B触发时,A不会重复触发。配置的位置就是在 触发器配置页的这个位置。

问题九
1. 我要将一台主机内的HTTP服务(端口:9501)添加到Zabbix的主机监控项中,设置相关触发器,当服务不可用时发布严重警告通知。
2. 我在配置主机加了个接口端口9501 然后监控项我用了这个键值,service.info[tomcat8,state]服务是tomcat8。
3. 创建了触发器:但是我把服务关闭后他触发不了,当状态6停止触发,当状态0启动恢复,客户端防火墙我入站添加了9501端口
我哪里没设置到还是哪里设置错了吗?

A:接口里的客户端端口是指向agent用的,这里的端口只能填agent的监听端口,你如果同时想要监听9501端口,你需要加一个监控项 net.tcp.listen[9501],而不是加主机接口
{kind=link}
问题十
Q:Zabbix最大的一个缺点应该就是没有合并报警这个功能,在极端的情况下会出现报警风暴。这个需要怎么解决?
A:Zabbix确实没有合并报警的功能,但是可以通过以下几种方式来解决报警风暴的问题:
1. 调整阈值:适当调整阈值可以避免短时间内频繁触发报警。
2. 报警延时:可以设置报警延时,在一定时间内多次触发报警只会发送一次报警通知。
3. 集中管理:通过集中管理和配置,可以避免重复的监控项和触发条件,从而减少报警次数。
4. 联动其他系统:可以将Zabbix与其他系统集成,比如运维管理系统、短信通知系统等,实现更加智能化的报警管理。
5. 自定义脚本:通过自定义脚本实现合并报警功能,当多个报警同时触发时,将它们合并成一个报警信息发送。
需要注意的是,在调整报警设置时,要根据实际情况进行设置,不要将阈值设置得过高或过低,以免导致监控不到位或误报警情况的发生。
问题十一
Q:0 C: D:: Disk write request responses are too high (write > 0.02s for 15m),磁盘写入请求响应太高(15m时写>0.02s),怎么优化呢?

A:优化磁盘写入请求的响应时间需要考虑以下几个方面:
1.硬件方面:使用更快的硬盘,例如固态硬盘(SSD)或高速RAID阵列。同时确保使用的硬盘驱动程序是最新版本。
2.软件方面:对于Windows系统,可以使用性能监视器和资源监视器来确定哪些进程正在大量写入磁盘,并尝试停止或减少它们的活动。同时确保所有软件都是最新版本,因为更新可能包括优化磁盘操作的代码。
3.清理无用数据:清理机器上文件、日志等无用信息,以释放磁盘空间,避免磁盘读写频次过多。
4.分析磁盘使用情况:使用工具来分析磁盘的使用情况。例如,可以使用Windows预设的性能监视器或者第三方监测工具来分析磁盘的使用情况,在分析基础上可以系统压缩存储或转移数据,以避免写请求太频繁。
以上是一些常见的优化方法,通过综合应对,即可降低磁盘写请求响应时间过高的问题。
问题十二
Q:zabbix5.0监控vmware 监控虚拟机指标没有内存使用率,大家怎么解决这个问题?
A:加可计算项的监控项去算,但是这个使用率大致上拿不到准确值的, VC层面看到的使用率和实际虚机内部系统的使用率是有出入的。
问题十三
Q:假如说我有4000个MIB的OID要登录到zabbix,有啥可行性的方案吗?
A:模板制作基本都是堆时间去人工制作模板做出来的,或者参考github上的mib2zabbix项目自动生成。
更多zabbix技术资料,可以持续关注乐维社区
标签:触发,触发器,报警,主机,虚拟机,196,Zabbix,监控,坐诊 From: https://blog.51cto.com/lwops/6522606{kind=link}