详解IO多路复用
1 概述
常见的IO模型有五种,IO多路复用模型是其中之一。
- 阻塞式IO
- 非阻塞式IO
- IO多路复用
- 信号驱动式IO
- 异步IO
其中前四种都是同步IO
1.1 什么是IO?
IO:Input/Output,即数据的读取(接收)/写入(发送)操作,针对不同的数据存储媒介,大致可以分为网络 IO 和磁盘 IO 两种。在 Linux 系统中,为了保证系统安全,操作系统将虚拟内存划分为内核空间和用户空间两部分。因此用户进程无法直接操作IO设备资源,需要通过系统调用完成对应的IO操作。
举例说明,一个网络数据输入操作包括两个不同的阶段:
- 等待数据准备好
- 从内核空间向用户空间复制数据
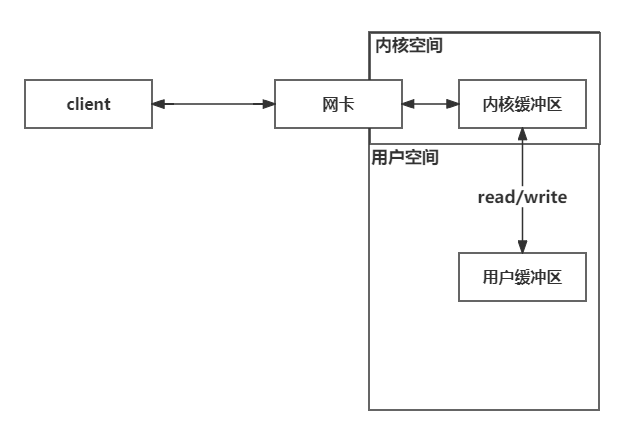
1.2 什么是缓冲区?
应用层的 IO 操作基本都是依赖操作系统提供的 read 和 write 两大系统调用实现。但由于计算机外部设备(磁盘、网络)与内存、CPU 的读写速度相差过大,若直接读写涉及操作系统中断,因此为了减少 OS 频繁中断导致的性能损耗和提高吞吐量,引入了缓冲区的概念。根据内存空间的不同,又可分为内核缓冲区和进程缓冲区。操作系统会对内核缓冲区进行监控,等待缓冲区达到一定数量的时候,再进行 IO 设备的中断处理,集中执行物理设备的实际 IO 操作,通过这种机制来提升系统的性能。至于具体什么时候执行系统中断(包括读中断、写中断)则由操作系统的内核来决定,应用程序不需要关心。
1.3 什么是同步/异步?什么是阻塞/非阻塞?
首先要消除一个错误的思想:同步就是阻塞,异步就是非阻塞。(这是错误的!)
-
阻塞/非阻塞
关注的是用户态进程/线程的状态,它要访问的数据是否就绪,进程/线程是否需要等待。
阻塞 IO指的是需要内核 IO 操作彻底完成后才返回到用户空间执行用户程序的操作指令。
非阻塞 IO(Non-Blocking IO,NIO) 指的是用户进程不需要等待内核 IO 操作彻底完成,即可返回用户空间执行后续指令。与此同时,内核会立即返回给用户一个 IO 状态值。
阻塞是指用户进程一直在等待,而不能做别的事情;非阻塞是指用户进程获得内核返回的状态值就返回自己的空间,可以去做别的事情。
-
同步/异步
关注的是消息通信机制(内核与应用程序的交互)。
同步 IO是指用户空间(进程或者线程)是主动发起 IO 请求的一方,系统内核是被动接收方。
异步 IO则反过来,系统内核是主动发起 IO 请求的一方,用户空间是被动接收方。异步只需要关注IO操作完成的通知,并不主动读写数据,由操作系统内核完成数据的读写。
同步和异步最大的区别就是被调用方的执行方式和返回时机。同步指的是被调用方做完事情之后再返回,异步指的是被调用方先返回,然后再做事情,做完之后再想办法通知调用方(此时数据已 ready,调用方可以直接使用)。
阻塞和非阻塞关注的是调用方进程状态,而同步与异步更关注调用双方进程通信方式。
举例说明:
场景:小明去新华书店买《三体》
- 如果书店没有,就一直等待,直至书店有了书之后才走。(同步阻塞)
- 如果书店没有,先离开书店;然后每天都去书店逛一次,直到书店有货了,买了就走。(同步非阻塞)
- 如果书店没有,留下电话;书店有货时,老板打电话通知他,他再去书店买书。(信号驱动IO,同步非阻塞)
- 如果书店没有,留下地址;书店有货时,老板直接把书送到家。(异步非阻塞)
对应于程序:用户进程调用系统调用
用户进程对应小明,内核对应书店老板,书对应数据,买书就是 一个系统调用,而内核拷贝数据到进程这个过程近似于老板送书到小明手中。同时可以看到,同步都是小明主动去书店买书,而异步是老板将书送到小明家中。
2 五种IO模型
2.1 (同步)阻塞式IO
同步阻塞IO(Blocking IO) 指的是用户进程(或线程)主动发起,需要等待内核 IO 操作彻底完成后才返回到用户空间的 IO 操作。在 IO 操作过程中,发起 IO 请求的用户进程处于阻塞状态。
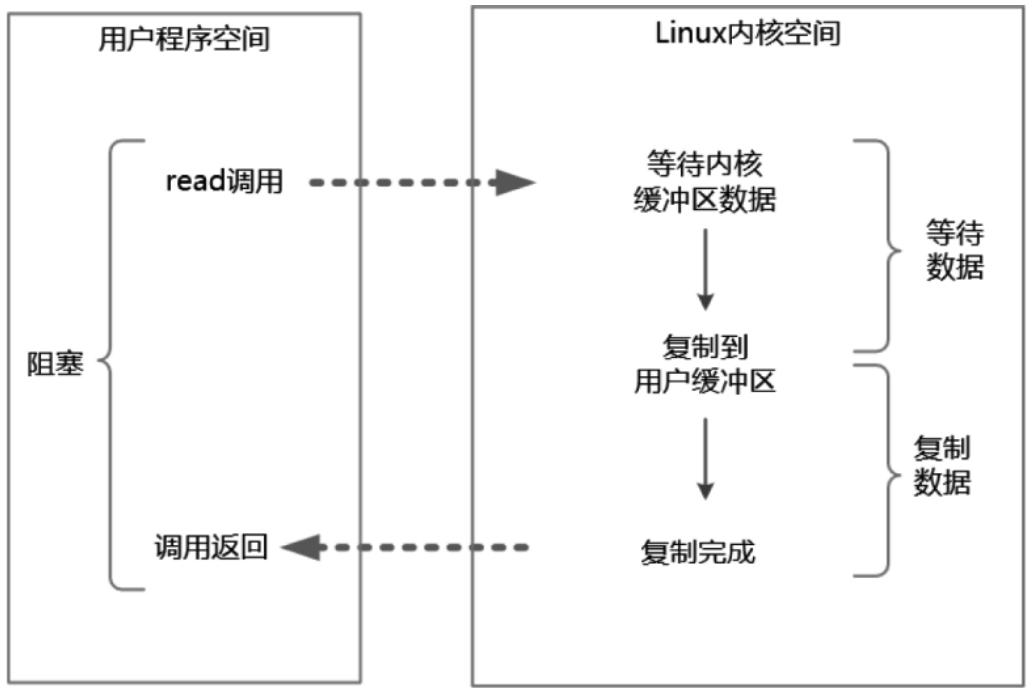
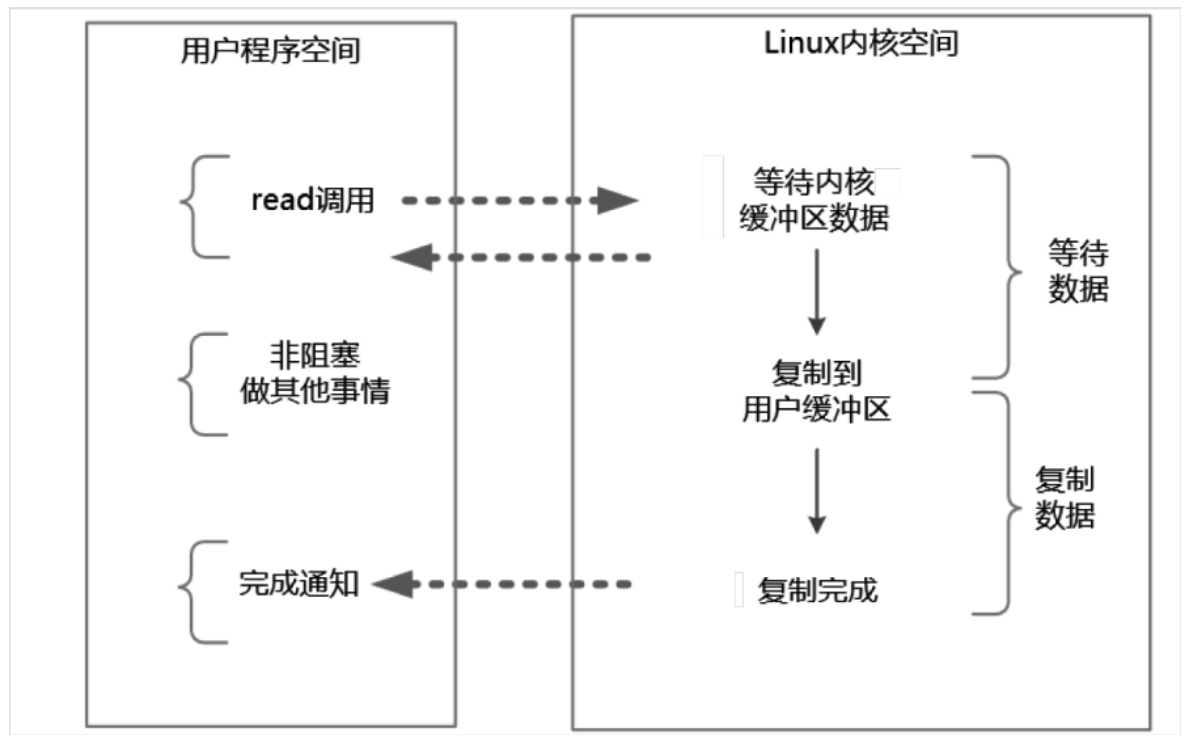
2.2 (同步)非阻塞IO
同步非阻塞IO(Non-Blocking IO,NIO) 指的是用户进程主动发起,不需要等待内核 IO 操作彻底完成就能立即返回用户空间的 IO 操作。在 IO 操作过程中,发起 IO 请求的用户进程处于非阻塞状态。
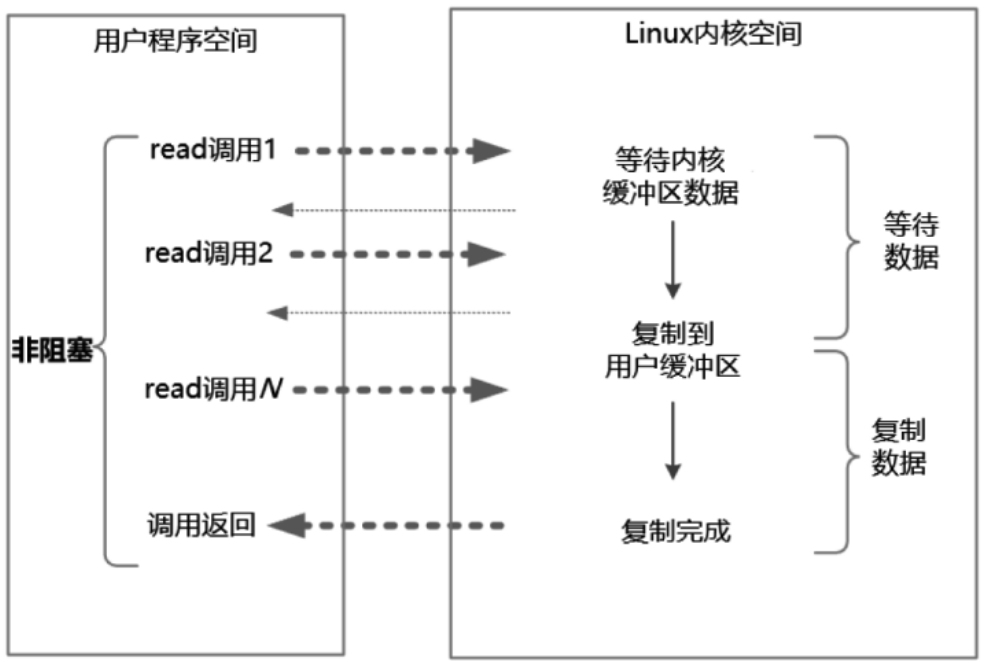
- 当数据 Ready 之后,用户线程仍然会进入阻塞状态(也就是上图”复制数据这个过程“),直到数据复制完成,并不是绝对的非阻塞。
- NIO 实时性好,内核态数据没有 Ready 会立即返回,但频繁的轮询内核,会占用大量的 CPU 资源,降低效率。
2.3 IO多路复用
IO 多路复用(IO Multiplexing) 实际上就解决了 NIO 中的频繁轮询 CPU 的问题,并且引入一种新的 select 系统调用。
复用 IO 的基本思路就是通过 select 调用来监控多 fd(文件描述符),来达到不必为每个 fd 创建一个对应的监控线程的目的,从而减少线程资源创建的开销。一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核就能够将文件描述符的就绪状态返回给用户进程(或者线程),用户空间可以根据文件描述符的就绪状态进行相应的 IO 系统调用。
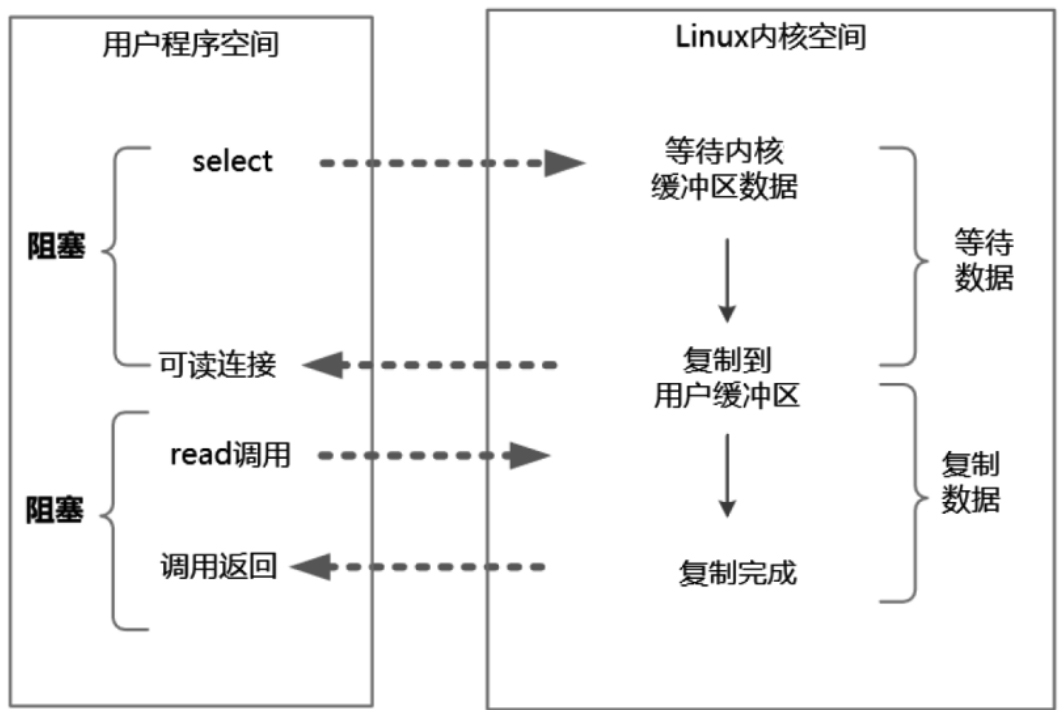
2.4 信号驱动IO
当进程发起一个 IO 操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用 IO 读取数据。
2.5 异步IO
异步IO(Asynchronous IO,AIO) 指的是用户空间的线程变成被动接收者,而内核空间成为主动调用者。在异步 IO 模型中,当用户线程收到通知时,数据已经被内核读取完毕并放在用户缓冲区内,内核在 IO 完成后通知用户线程直接使用即可。而此处说的 AIO 通常是一种异步非阻塞 IO。
3 IO多路复用
IO多路复用是一种同步IO模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出CPU。IO是指网络 IO,多路指多个TCP连接(即 socket),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。
IO 多路复用的三种实现方式:select、poll、epoll
举例说明:
假设你是一名老师,让30个学生完成一道题目,并检查他们的结果是否正确,现在有以下几种情况:
- 按顺序逐个检查,先检查A,然后B,之后C、D...这中间如果有学生卡住,后面的学生都会被耽搁
- 找来30个助教,每个助教负责检查一个学生
- 站在讲台上,那个学生写完了举手示意,谁举手就去检查谁
上述场景1对应传统单线程socket模型,缺点非常明显:同时只能处理一个客户端的请求,多余的请求可以通过队列的方式保存起来,后续一次遍历处理。但如果处理某个请求时阻塞了,那么后续所有请求的处理都会阻塞。
上述场景2对应传统多线程socket模型,一般都是通过主线程阻塞等待客户端连接,每个客户端连接创建新的工作线程来处理请求的方式实现。当并发量不是很大时,这种处理方式还可以使用。一旦并发量很大,频繁创建的线程会带来巨大的资源消耗以及上下文切换消耗。
上述场景3就可以理解为I/O多路复用技术︰将客户端对应socket的fd(文件描述符)注册到select或poll或epoll上,当socket流就绪时,select线程就会执行:轮询找到就绪的socket,将它返回给应用,执行相应流处理。
从这里也就可以看出,IO多路复用技术的核心是减少服务端线程的创建,通过使用较少线程处理所有请求的方式提高整体效率。
3.1 select机制
底层使用bitmap(位图)标识fd
// 相关函数
#include <sys/select.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
// nfds 所有监听的fd,数值最大的一个+1
// readfds 读事件集合
// writefds 写事件集合
// exceptfds 异常事件集合
// timeout 最长阻塞时间,NULL表示永久阻塞
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
一般使用步骤:
- 创建监听集合:fd_set
- 初始化监听集合:FD_ZERO
- 增加监听:FD_SET
- 调用select函数:进程陷入阻塞,当监听的所有fd,有任何一个就绪,select解除阻塞
- fd_set从监听集合变为就绪集合,使用FD_ISSET判断某个fd是否就绪
示例代码:
// 用两个管道实现两个进程的全双工通信
#include <stdio.h>
#include <sys/select.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n");return -1;}}
#define ERROR_CHECK(ret,num,msg) {if(ret == num){perror(msg);return -1;}}
int main(int argc, char *argv[])
{
// ./client 1.pipe 2.pipe
ARGS_CHECK(argc,3);
int fdw = open(argv[1],O_WRONLY);
ERROR_CHECK(fdw,-1,"open fdw");
int fdr = open(argv[2],O_RDONLY);
ERROR_CHECK(fdr,-1,"open fdr");
printf("chat established!\n");
char buf[4096] = {0};
fd_set rdset;//创建监听集合
while(1){
FD_ZERO(&rdset);//初始化监听集合
FD_SET(STDIN_FILENO,&rdset);//监听stdin
FD_SET(fdr,&rdset);//监听2.pipe管道的读端
select(fdr+1,&rdset,NULL,NULL,NULL);
// 第一个参数 监听集合中最大的fd再+1
// 第二个参数 由于读阻塞的监听集合
// 第三、四个参数 写阻塞和异常阻塞的监听集合均为空
// 第五个参数 最长等待时间 NULL表示永久等待
// 当select就绪了以后,rdset就成为了就绪集合
// 检查某个具体的文件描述符是否在就绪集合当中
if(FD_ISSET(STDIN_FILENO,&rdset)){
// 说明stdin有数据
memset(buf,0,sizeof(buf));
ssize_t sret = read(STDIN_FILENO,buf,sizeof(buf));
// 当sret为0时,说明本端退出
if(sret == 0)
{
printf("bye~\n");
break;
}
write(fdw,buf,strlen(buf));
}
if(FD_ISSET(fdr,&rdset)){
// 说明管道有数据
memset(buf,0,sizeof(buf));
ssize_t sret = read(fdr,buf,sizeof(buf));
// 当sret为0时,说明对方已经关闭了
if(sret == 0){
printf("peer exit!\n");
break;
}
printf("buf = %s\n", buf);
}
}
close(fdr);
close(fdw);
return 0;
}
底层原理:
// fd_set的底层,实际就是用的 位图 这个数据结构
typedef __kernel_fd_set fd_set;
#undef __FD_SETSIZE
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
首先看数组的大小:sizeof(long) 如果是64位计算机系统,则占8个字节,所以这个数组就是(1024/(8*8)) = 16个元素。由此可知fd_set实际上是一个16个元素的long数组,用位存储的思想可以存放16 * 8 * 8 = 1024个文件描述符。
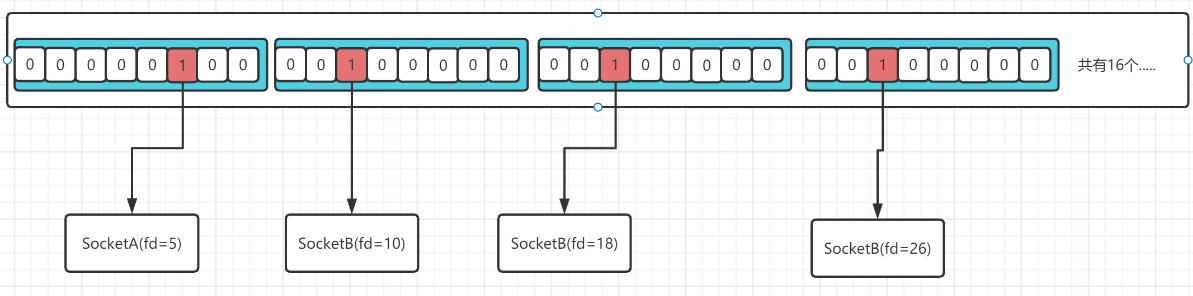
好处:节省空间,可以用更小的空间存储更多的映射关系。
select机制说白了也是要借助底层驱动的支持,即当有事件发生时能够触发事件回调。由硬件层通知到我们的内核态,然后由内核态通知到我们的应用态的一个过程。
以fd_set为例,每次都要从用户态拷贝至内核态(select函数就是做的这个工作),同时还要在内核态进行循环遍历,然后把有事件的响应的文件描述符fd_set返回,又要从内核态拷贝至用户态。用户态拿到这个有事件的文件描述符返回,还要针对返回的描述符进行遍历,才能知道哪个文件描述符对应的socket可写可读,总共经历了两次遍历,两次拷贝,所以说为什么select在文件描述符比较多的情况,效率为什么是低下的原因。
select的优点:
- select是最古老的IO复用的API,所以是支持跨平台的。而epoll是Linux内核独有的IO复用。
select的缺点:
- 单个进程可监视的fd数量被限制,默认是1024。
- 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
- 在大量文件描述符的情况下,每次在内核中轮询扫描所有文件描述符,会导致系统效率下降。
3.2 poll机制
底层使用链表存储fd
基本原理与select一致
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd
{
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
fds:文件描述符数组。
events:POLLIN/POLLOUT/POLLERR
nfds:监控数组中有多少文件描述符需要被监控。
timeout 毫秒级等待
-1:阻塞等,#define INFTIM -1 Linux中没有定义此宏
0:立即返回,不阻塞进程
>0:等待指定毫秒数,如当前系统时间精度不够毫秒,向上取值。
函数返回值:满足监听条件的文件描述符的数目。
示例代码:
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
pollfds[i].events = POLLIN;
}
sleep(1);
while(1){
puts("round again");
poll(pollfds, 5, 50000);
for(i=0;i<5;i++) {
// 与select不同的地方,有数据会将revents置位
if (pollfds[i].revents & POLLIN){
pollfds[i].revents = 0; // 这里还会恢复为0,所以每次while进来不需要重新设置pollfd(可以重用)
memset(buffer,0,MAXBUF);
read(pollfds[i].fd, buffer, MAXBUF);
puts(buffer);
}
}
}
优点:
- 支持数目较大,不受限制:poll()函数支持的文件描述符数量没有 select() 函数的限制,因此可以更灵活地适应各种环境和场景;
3.3 epoll机制
int epoll_create(int size);
int epoll_create1(int flags);
- size参数告诉内核这个epoll对象处理的事件大致数量,而不是能够处理的最大数量
- 在现在的linux版本中,这个size函数已经被废弃(但是size不要传0,会报invalid argument错误)
- 内核会产生一个epoll 实例数据结构并返回一个文件描述符,这个特殊的描述符就是epoll实例的句柄,之后针对该epoll的操作需要通过该句柄来标识该epoll对象。
- 也就是创建红黑树的根节点
#include <sys/epoll.h>
//控制某个epoll监控的文件描述符上的事件:注册、修改、删除
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epfd:epoll_create函数返回的值
op:EPOLL_CTL_ADD/EPOLL_CTL_MOD/EPOLL_CTL_DEL
fd:将哪个文件描述符以op的方式加在以epfd建立的树上
event:告诉内核需要监听的事情。
struct epoll_event
{
uint32_t events;
epoll_data_t data;
};
typedef union epoll_data
{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
//等待所监控文件描述符上有事件的产生
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
events:用来存内核得到事件的集合(这里是个传出参数)
maxevents:告知内核这个events有多大,这个maxevents的值不能大于创建epoll_create时的size
timeout:是超时时间
-1:阻塞
=0:立即返回,非阻塞
>0:指定毫秒
返回值:成功返回有多少文件描述符就绪,时间到时返回0,出错返回-1
示例代码:
struct epoll_event events[5];
int epfd = epoll_create(10);
...
...
for (i=0;i<5;i++)
{
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
ev.events = EPOLLIN;
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev);
}
while(1){
puts("round again");
nfds = epoll_wait(epfd, events, 5, 10000);
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
底层原理:
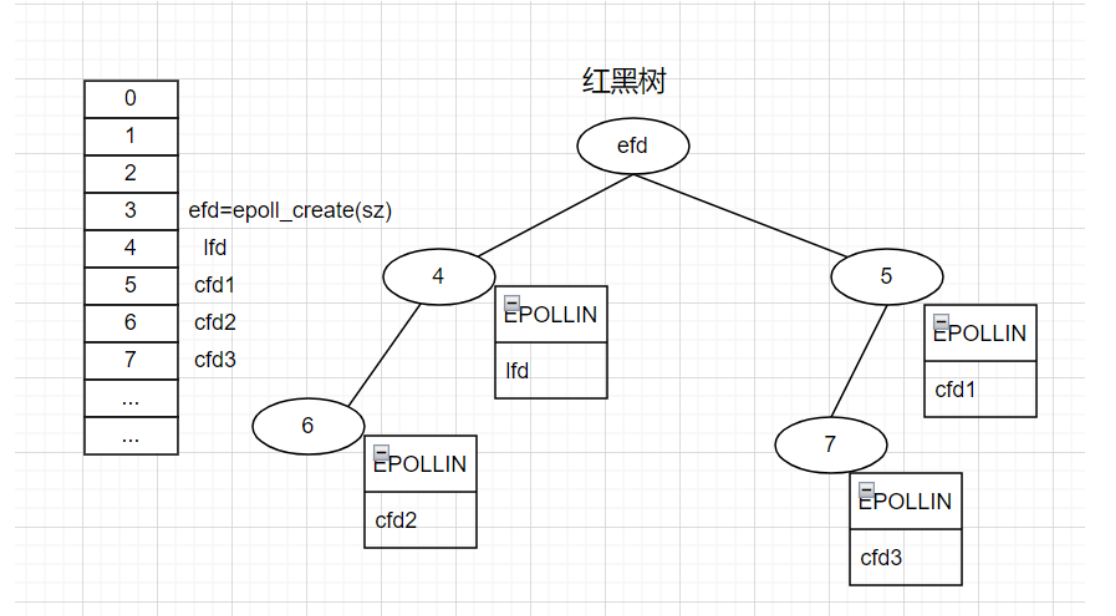
- 通过调用epoll_create,在epoll文件系统建立了个file节点,并开辟epoll自己的内核高速cache区,建立红黑树,分配好想要的size的内存对象,建立一个list链表,用于存储准备就绪的事件。(
epoll_create方法生成一个 epoll 专用的文件描述符epfd,epfd在用户态和内核态之间共享,避免了poll和select用户态和内核态文件描述符状态的拷贝) - 通过调用epoll_ctl,把要监听的socket放到对应的红黑树上,给内核中断处理程序注册一个回调函数,通知内核,如果这个句柄的数据到了,就把它放到就绪列表。
- 通过调用 epoll_wait,观察就绪列表里面有没有数据,并进行提取和清空就绪列表,非常高效。
水平触发LT(level trigger)和边缘触发ET(edge trigger)

3.4 epoll与select、poll的对比
1.用户态将文件描述符传入内核的方式
- select:创建3个文件描述符集并拷贝到内核中,分别监听读、写、异常动作。这里受到单个进程可以打开的fd数量限制,默认是1024
- poll:将传入的struct pollfd结构体数组拷贝到内核中进行监听(不受数量限制了)
- epoll:执行epoll_create会在内核的高速cache区中建立一颗红黑树以及就绪链表(该链表存储已经就绪的文件描述符)。接着用户执行的epoll_ctl函数添加文件描述符会在红黑树上增加相应的结点
2.内核态检测文件描述符读写状态的方式
- select:采用轮询方式,遍历所有fd,最后返回一个描述符读写操作是否就绪的mask掩码,根据这个掩码给fd_set赋值
- poll:同样采用轮询方式,查询每个fd的状态,如果就绪则在等待队列中加入一项并继续遍历
- epoll:采用回调机制。在执行epoll_ctl的add操作时,不仅将文件描述符放到红黑树上,而且也注册了回调函数,内核在检测到某文件描述符可读/可写时会调用回调函数,该回调函数将文件描述符放在就绪链表中
3. 找到就绪的文件描述符并传递给用户态的方式
- select:将之前传入的fd_set拷贝传出到用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断
- poll:同select方式
- epoll:epoll_wait只用观察就绪链表中有无数据即可,最后将链表的数据返回给数组并返回就绪的数量。内核将就绪的文件描述符放在传入的数组中,所以只用遍历依次处理即可。这里返回的文件描述符是通过mmap让内核和用户空间共享同一块内存实现传递的,减少了不必要的拷贝
3.5 总结
- select和poll的动作基本一致,只是poll采用链表来进行文件描述符的存储,而select采用fd标注位来存放,所以select会受到最大连接数的限制,而poll不会。
- select、poll、epoll虽然都会返回就绪的文件描述符数量。但是select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
- select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多。
- epoll的边缘触发模式效率高,系统不会充斥大量不关心的就绪文件描述符
- select、poll都需要将有关文件描述符的数据结构拷贝进内核,最后再拷贝出来。而epoll创建的有关文件描述符的数据结构本身就存于内核态中,系统调用返回时利用mmap()文件映射内存加速与内核空间的消息传递:即epoll使用mmap减少复制开销。